



正则表达式(规则表达式)
就是通过字符串定义规则,从规则去验证字符串是否匹配。
python中的正则表达式
使用re模块,通过match,search,findall三个方法来匹配
1.re.match(匹配规则,被匹配的字符串)
匹配成功返回匹配对象,匹配不成功返回空
match匹配是开头进行匹配,如果开头没有匹配到,忽略后面的内容:
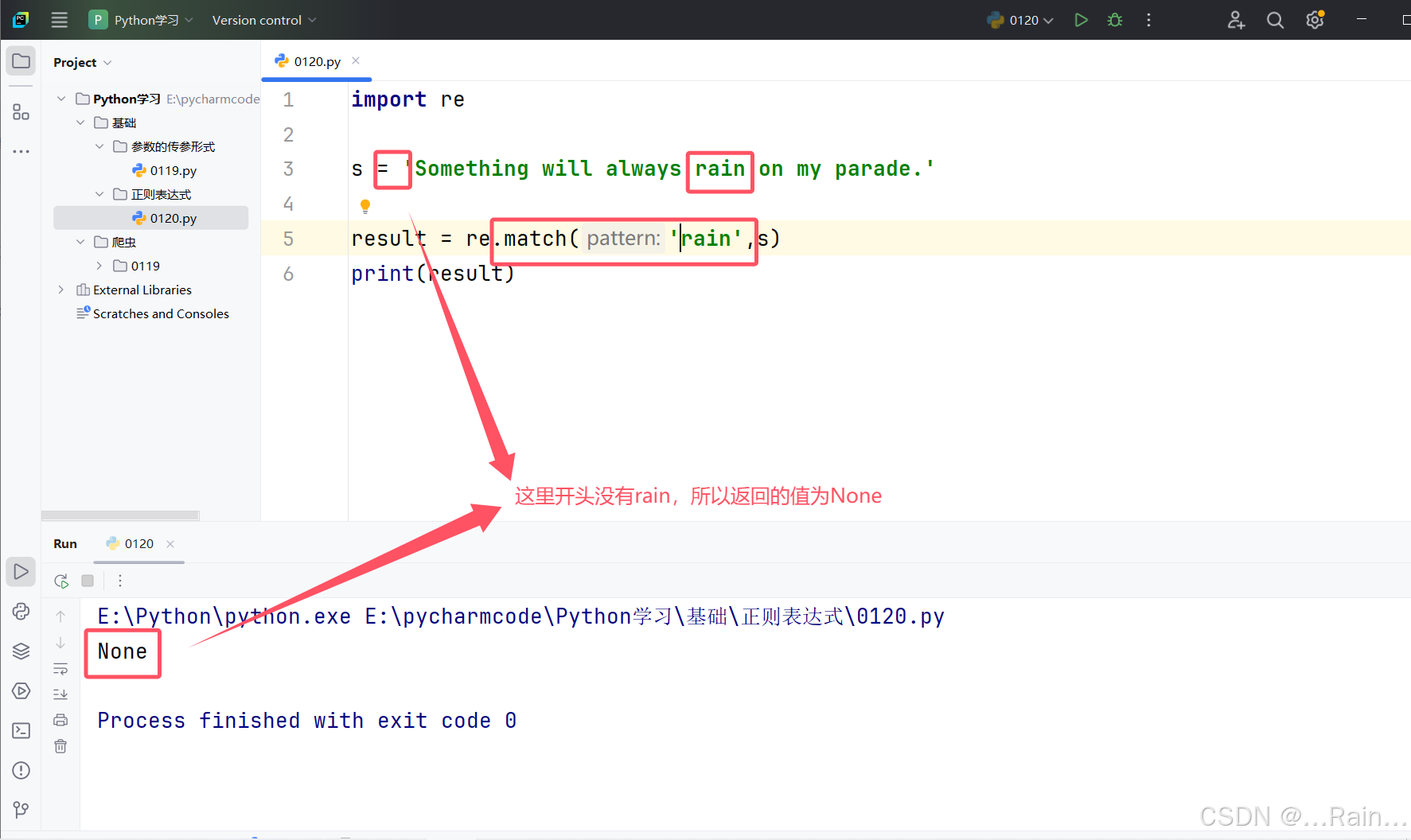
有返回值
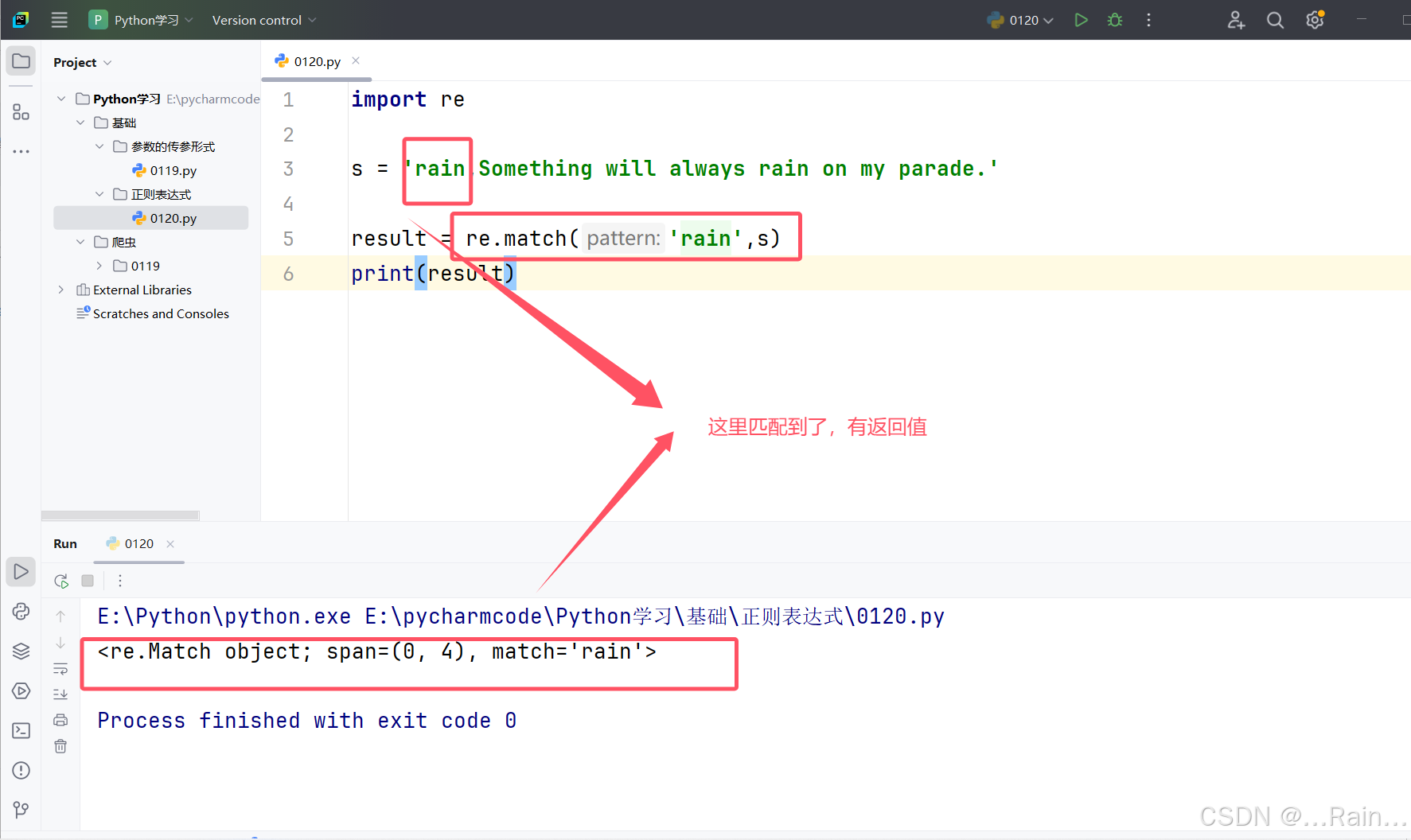 返回值的意义:<re.Match object; span=(0, 4), match='rain'>
返回值的意义:<re.Match object; span=(0, 4), match='rain'>
span表示的是匹配到的字符串下标为[0~4)这个范围
查看返回值用 变量名.group() group只适用于search和match(他们两个返回的是对象)
findall不适用(返回的是列表)
2.search(匹配规则,被匹配字符串)
搜索整个字符串,找出匹配的。从前到后,找到第一个后就停止。
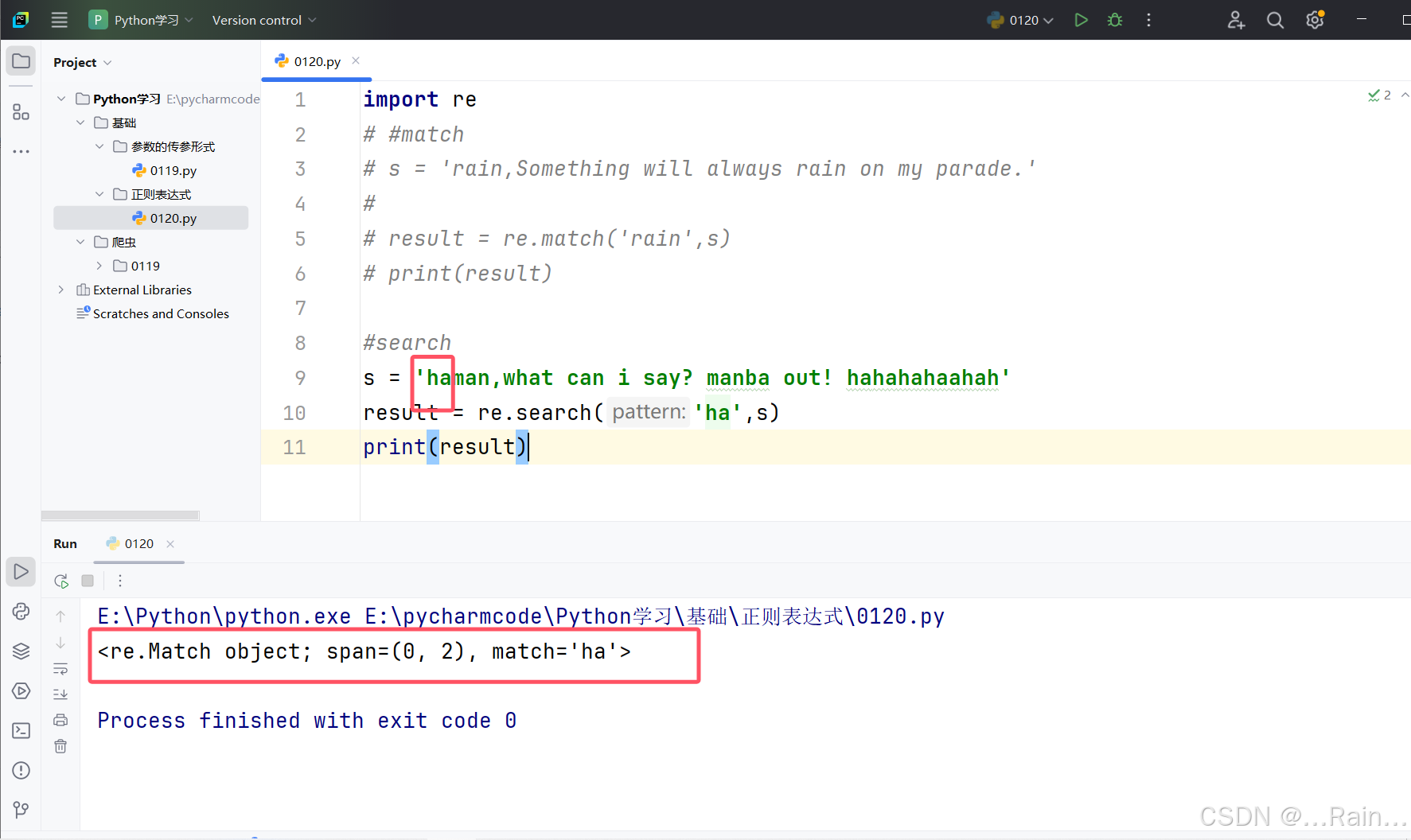
3.findall(匹配规则,被匹配字符串)
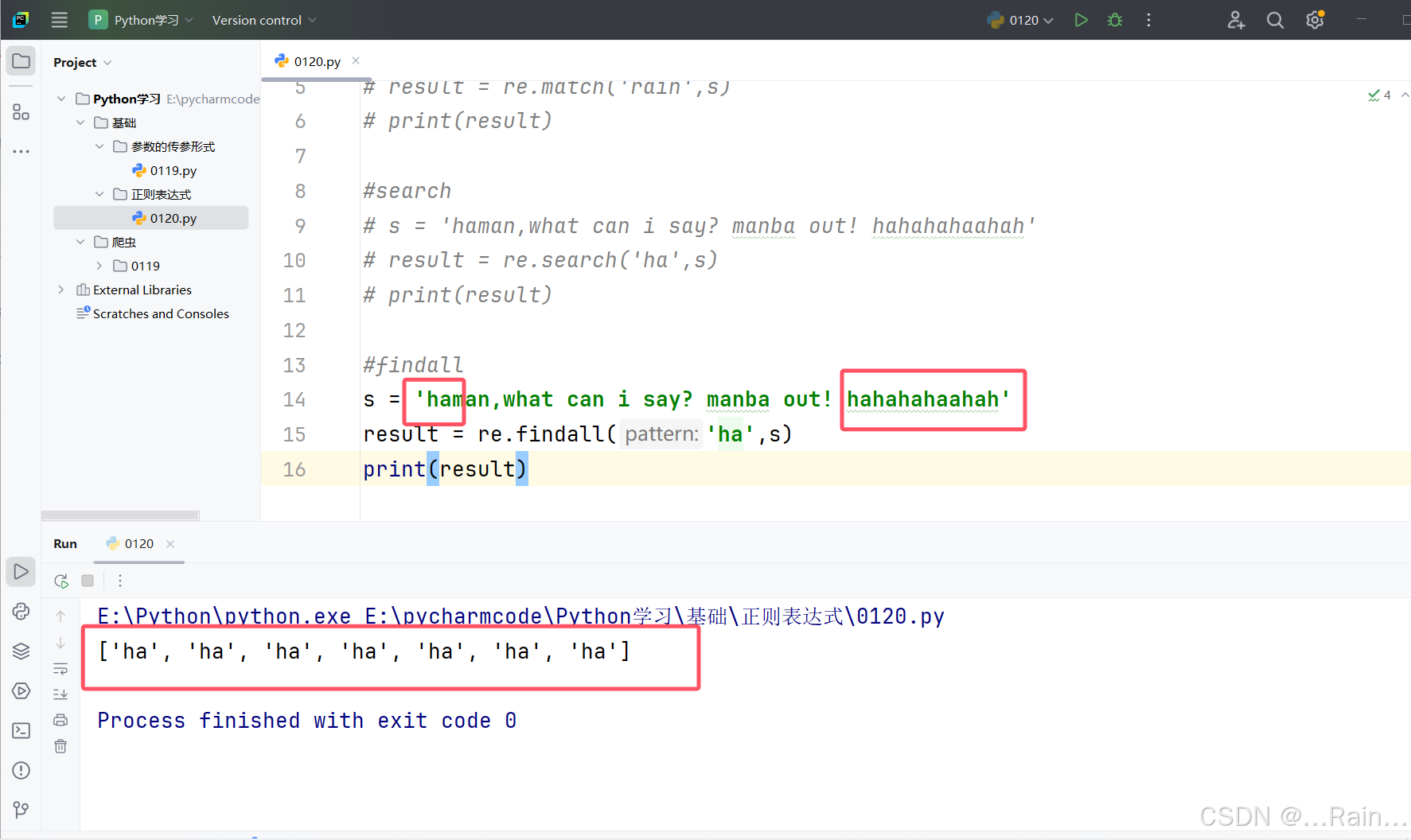
输出一个列表
元字符匹配
| . | 匹配任意1个字符(除了\n),\.匹配本身 |
| [ ] | 匹配[ ]中列举的字符 |
| \d | 匹配数字0~9 |
| \D | 匹配非数字 |
| \s |
匹配空白(空格,tab键) |
| \S | 匹配非空白 |
| \w | 匹配单词字符:a~z,A~Z,0~9, _ |
| \W | 匹配非单词字符 |
在转义字符前加r可以让转义字符\失效
数量匹配
| * | 匹配前一个规则的字符出现0次至无数次 |
| + | 匹配前一个规则的字符出现最少1次至无数次 |
| ? | 匹配前一个规则的字符出现0次或最多1次 |
| {m} | 匹配前一个规则的字符出现m次 |
| {m,} | 匹配前一个规则的字符最少出现m次 |
| {m,n} | 匹配前一个规则的字符出现m到n次 |
边界匹配
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
分组匹配
| | | 匹配左右任意一个表达式 |
| () | 将括号中的字符作为一个分组 |
多用就能记住,多来查看!


















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











