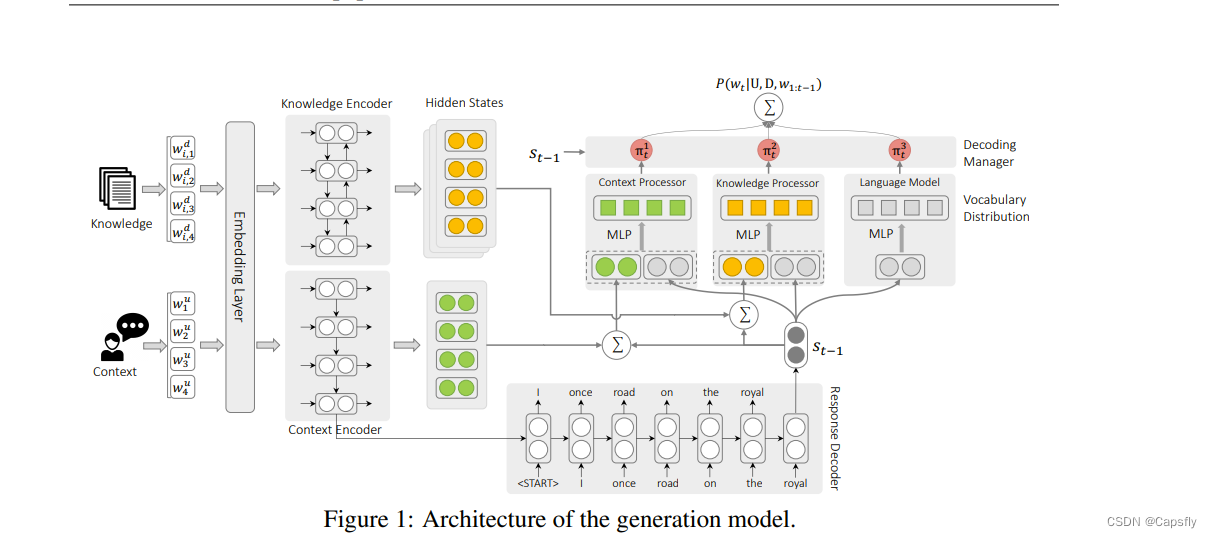
1.论文链接 https://arxiv.org/pdf/2002.10348.pdf 2.论文主要为了解决什么问题? 主要解决了在某些特定情况下(比如样本量很少),使用传统的DNN可能会overfit并且生成没有意义的回答 3.模型流程 dialogue context采用GRU编码,生成隐藏层序列 同时,根据已经产生的内容(RNN),选择一个词 根据context选择一个词 根据别的知识选择一个词,这几个综合考虑选择词 4.论文创新点 增加了模型的参数数量来减少需要的数据量 5.本论文可能能用到哪里? 医学检测上很多数据量也很少,可能能用到
 1294
2万+
7996
1294
2万+
7996



























 到【灌水乐园】发言
到【灌水乐园】发言






