






DeepSeek-V2和DeepSeek-V3背后实现更快推理的关键架构创新
作者使用ChatGPT创建的图片。
这是我们新系列"DeepSeek-V3解析"的第一篇文章,我们将尝试揭开DeepSeek开源的最新模型DeepSeek-V3 [1, 2]的神秘面纱。
在这个系列中,我们旨在涵盖两个主要主题:
-
DeepSeek-V3的主要架构创新,包括MLA(多头潜在注意力)[3]、DeepSeekMoE [4]、无辅助损失的负载均衡[5]以及多token预测训练。
-
DeepSeek-V3的训练,包括预训练、微调和强化学习对齐阶段。
本文主要聚焦于多头潜在注意力,这一技术首次在DeepSeek-V2的开发中提出,随后也被应用于DeepSeek-V3。
本系列有3篇文章,请在站内搜索:
-
DeepSeek-V3解析1:多头潜在注意力
-
DeepSeek-V3解析2: DeepSeekMoE
-
DeepSeek-V3解析3: 无辅助损失的负载均衡
目录:
-
背景: 我们从标准MHA开始,解释为什么在推理阶段需要Key-Value缓存,MQA和GQA如何尝试优化它,以及RoPE的工作原理等。
-
多头潜在注意力: 对MLA的深入介绍,包括其动机、为什么需要解耦RoPE,以及其性能。
背景
为了更好地理解MLA,并使本文自成一体,在深入MLA细节之前,我们将在本节回顾几个相关概念。
仅解码器Transformer中的MHA
请注意,MLA的开发是为了加速自回归文本生成的推理速度,因此我们在这种情况下讨论的MHA是针对仅解码器Transformer的。
下图比较了用于解码的三种Transformer架构,其中(a)显示了原始"Attention is All You Need"论文中提出的编码器和解码器。其解码器部分随后被[6]简化,形成了(b)中显示的仅解码器Transformer模型,该模型后来被用于许多生成模型,如GPT [8]。
如今,大型语言模型更常选择(c)中所示的结构以实现更稳定的训练,将归一化应用于输入而非输出,并将LayerNorm升级为RMS Norm。这将作为我们在本文中讨论的基线架构。
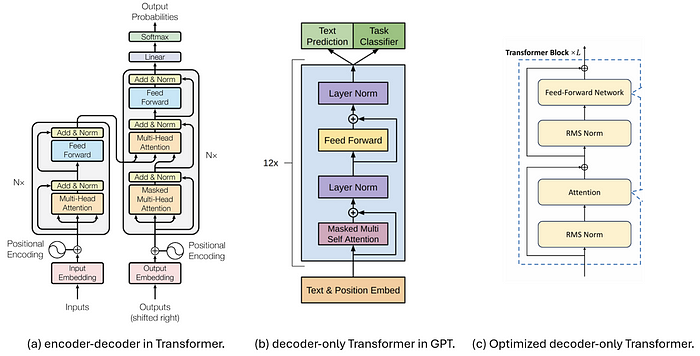
图1. Transformer架构。(a) [6]中提出的编码器-解码器。(b) [7]中提出并在GPT [8]中使用的仅解码器Transformer。(c) (b)的优化版本,在注意力之前使用RMS Norm。[3]
在这种情况下,MHA的计算在很大程度上遵循[6]中的过程,如下图所示:
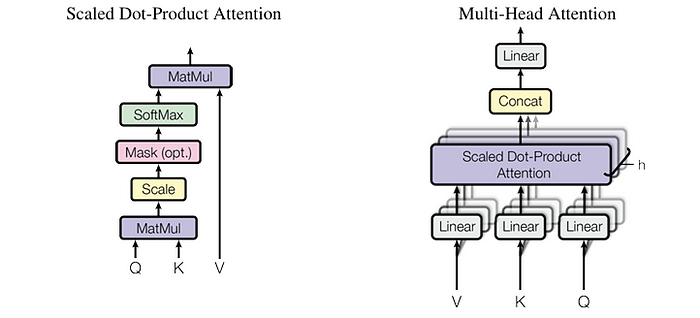
图2. 缩放点积注意力与多头注意力的比较。图片来自[6]。
假设我们有n_h个注意力头,每个注意力头的维度表示为d_h,那么连接后的维度将是(n_h · d_h)。
给定一个有l层的模型,如果我们将该层中第t个token的输入表示为h_t,维度为d,我们需要使用线性映射矩阵将h_t的维度从d映射到(h_n · d_h)。
更正式地说,我们有(方程来自[3]):
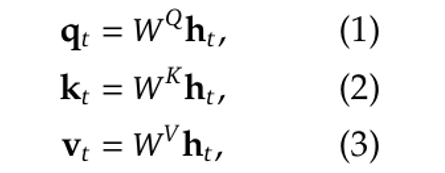
其中W^Q、W^K和W^V是线性映射矩阵:
![]()
经过这样的映射后,q_t、k_t和v_t将被分成n_h个头来计算缩放点积注意力:
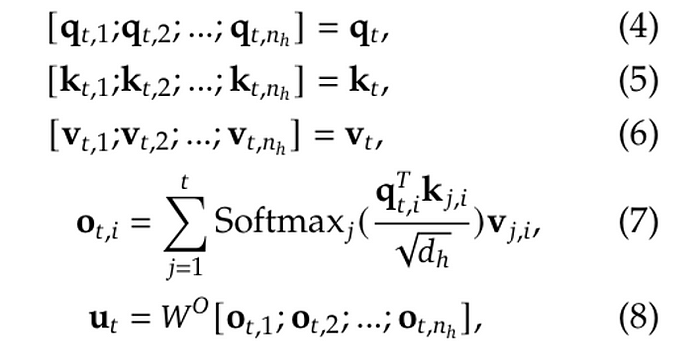
其中W^O是另一个投影矩阵,用于将维度从(h_n · d_h)反向映射到d:
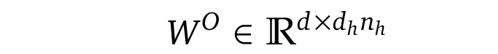
请注意,上述方程(1)到(8)描述的过程仅针对单个token。在推理过程中,我们需要为每个新生成的token重复这个过程,这涉及大量重复计算。这导致了一种称为Key-Value缓存的技术。
Key-Value缓存
顾名思义,Key-Value缓存是一种旨在通过缓存和重用先前的keys和values来加速自回归过程的技术,而不是在每个解码步骤重新计算它们。
请注意,KV缓存通常仅在推理阶段使用,因为在训练中我们仍需要并行处理整个输入序列。
KV缓存通常实现为一个滚动缓冲区。在每个解码步骤中,只计算新的查询Q,而存储在缓存中的K和V将被重用,因此注意力将使用新的Q和重用的K、V来计算。同时,新token的K和V也将被附加到缓存中以供后续使用。
然而,KV缓存实现的加速是以内存为代价的,因为KV缓存通常随批量大小 × 序列长度 × 隐藏大小 × 头数而扩展,导致在有更大批量大小或更长序列时出现内存瓶颈。
这进一步导致了两种旨在解决这一限制的技术:多查询注意力和分组查询注意力。
多查询注意力(MQA)与分组查询注意力(GQA)
下图显示了原始MHA、分组查询注意力(GQA)[10]和多查询注意力(MQA)[9]之间的比较。
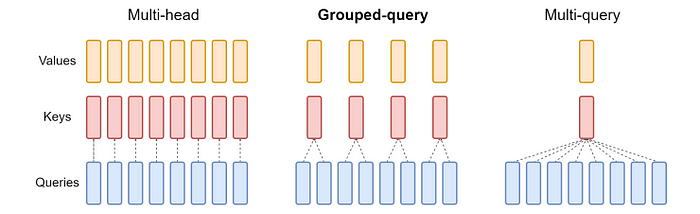
图3. MHA [6]、GQA [10]和MQA [9]。图片来自[10]。
MQA的基本思想是在所有查询头之间共享单个key和单个value头,这可以显著减少内存使用,但也会影响注意力的准确性。
GQA可以被视为MHA和MQA之间的插值方法,其中单对key和value头仅由一组查询头共享,而不是所有查询。但这仍会导致比MHA更差的结果。
在后面的章节中,我们将看到MLA如何在内存效率和建模准确性之间寻求平衡。
RoPE(旋转位置嵌入)
我们需要提到的最后一个背景是RoPE [11],它通过使用正弦函数旋转多头注意力中的查询和key向量,直接将位置信息编码到注意力机制中。
更具体地说,RoPE在每个token处对查询和key向量应用位置相关的旋转矩阵,并使用正弦和余弦函数作为基础,但以独特的方式应用它们以实现旋转。
要了解是什么使它具有位置相关性,考虑一个只有4个元素的玩具嵌入向量,即(x_1, x_2, x_3, x_4)。
要应用RoPE,我们首先将连续维度分组成对:
-
(x_1, x_2) -> 位置1
-
(x_3, x_4) -> 位置2
然后,我们应用旋转矩阵来旋转每一对:
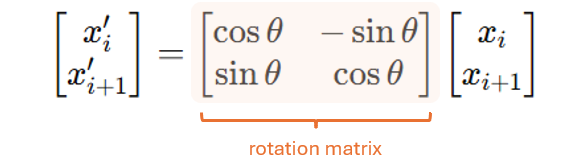
图4. 应用于一对token的旋转矩阵示意图。作者绘制。
其中θ = θ(p) = p ⋅ θ0,θ0是一个基频。在我们的4维玩具示例中,这意味着(x_1, x_2)将被旋转θ0,而(x_3, x_4)将被旋转2 ⋅ θ0。
这就是为什么我们称这个旋转矩阵为位置相关的:在每个位置(或每对),我们将应用一个不同的旋转矩阵,其中旋转角度由位置决定。
RoPE在现代大型语言模型中被广泛使用,因为它在编码长序列方面效率很高,但正如我们从上面的公式中看到的,它对Q和K都是位置敏感的,这使得它在某些方面与MLA不兼容。
多头潜在注意力
最后我们可以进入MLA部分。在本节中,我们将首先阐述MLA的高层思想,然后深入探讨为什么它需要修改RoPE。最后,我们将介绍MLA的详细算法及其性能。
MLA:高层思想
MLA的基本思想是将注意力输入h_t压缩成一个低维潜在向量,维度为d_c,其中d_c远低于原始的(h_n · d_h)。之后当我们需要计算注意力时,我们可以将这个潜在向量映射回高维空间以恢复keys和values。因此,只需要存储潜在向量,从而显著减少内存使用。
这个过程可以用以下方程更正式地描述,其中c^{KV}_t是潜在向量,W^{DKV}是压缩矩阵,将h_t的维度从(h_n · d_h)映射到d_c(这里上标D代表"下投影",意味着压缩维度),而W^{UK}和W^{UV}都是上投影矩阵,将共享的潜在向量映射回高维空间。

类似地,我们也可以将查询映射到一个潜在的低维向量,然后再将其映射回原始的高维空间:

为什么需要解耦RoPE
如前所述,RoPE是训练生成模型处理长序列的常见选择。如果我们直接应用上述MLA策略,那将与RoPE不兼容。
为了更清楚地看到这一点,考虑当我们使用方程(7)计算注意力时会发生什么:当我们将转置的q与k相乘时,矩阵W^Q和W^{UK}将出现在中间,它们的组合等同于将维度从d_c映射到d的单一映射。
在原始论文[3]中,作者将此描述为W^{UK}可以被W^Q"吸收",因此我们不需要在缓存中存储W^{UK},进一步减少内存使用。
然而,当我们考虑图(4)中的旋转矩阵时,情况就不是这样了,因为RoPE将在W^{UK}的左侧应用旋转矩阵,这个旋转矩阵最终会出现在转置的W^Q和W^{UK}之间。
正如我们在背景部分所解释的,这个旋转矩阵是位置相关的,意味着每个位置的旋转矩阵都不同。因此,W^{UK}不再能被W^Q吸收。
为了解决这个冲突,作者提出了他们称之为"解耦RoPE"的方法,通过引入额外的查询向量以及一个共享的key向量,并仅在RoPE过程中使用这些额外的向量,同时保持原始keys与旋转矩阵相对隔离。
MLA的整个过程可以总结如下(方程编号重用自[3]的附录C):
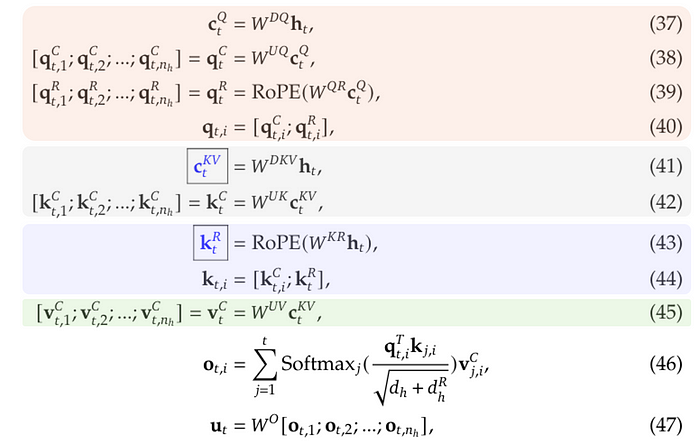
图5. MLA过程。作者根据[3]中的方程编辑的图像。
其中:
-
方程(37)到(40)描述了如何处理查询token。
-
方程(41)和(42)描述了如何处理key token。
-
方程(43)和(44)描述了如何使用额外的共享key进行RoPE,注意(42)的输出不参与RoPE。
-
方程(45)描述了如何处理value token。
在这个过程中,只有带蓝色框的变量需要被缓存。这个过程可以通过下面的流程图更清晰地说明:
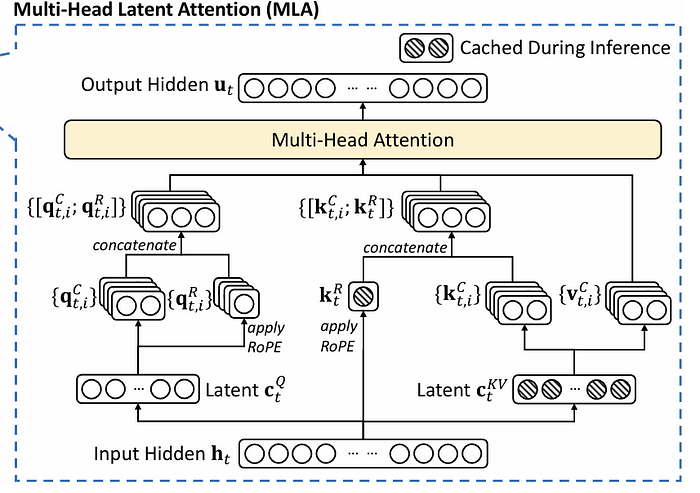
图6. MLA的流程图。图片来自[3]。
MLA的性能
下表比较了MHA、GQA、MQA和MLA在KV缓存所需的元素数量(每个token)以及建模能力方面的表现,展示了MLA确实能在内存效率和建模能力之间取得更好的平衡。
有趣的是,MLA的建模能力甚至超过了原始MHA。

表1 来自[3]。
更具体地说,下表显示了MHA、GQA和MQA在7B模型上的性能,其中MHA显著优于MQA和GQA。
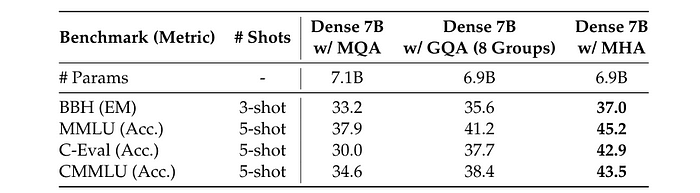
表8 来自[3]。
[3]的作者还对MHA和MLA进行了分析,结果总结在下表中,MLA整体上取得了更好的结果。
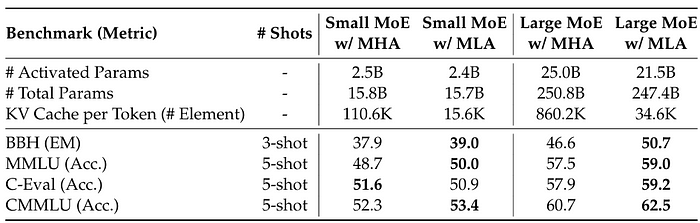
表9 来自[3]。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









