



有关NFS的相关文件,推荐如下几个博客地址,大家可以参考
NFS共享文件系统(将文件目录挂载到别的机器上)_nfs挂载-优快云博客
NFS数据共享(全面讲解使用教程) - AlexEvans - 博客园
什么是NFS
在 Linux 和其他操作系统中,有一种叫做 NFS(网络文件系统)的工具,它允许跨网络共享文件系统资源。通过使用 NFS,我们可以将多个客户端服务器的数据目录挂载到一个专门的数据服务器上,从而降低客户端服务器的负载,并提高它们的工作效率,同时集中管理数据可以带来其他好处,如数据备份和集中维护。
NFS(Network File System)是一种分布式文件系统协议,它允许计算机系统通过网络访问彼此的文件系统。NFS 是由 Sun Microsystems 在 1980 年代开发的,并且随着时间的推移,它已经成为了 Unix 和 Linux 系统间共享文件的标准方法之一
本次场景应用
一台应用程序服务器,需要通过文件上传的功能将数据传输到另一台Centos7文件系统服务器上
安装NFS软件包
sudo apt install nfs-common # Debian/Ubuntu
sudo yum install nfs-utils rpcbind -y # CentOS/RHEL
sudo dnf install nfs-utils # Fedora创建共享目录(挂载点)
sudo mkdir -p /path/to/shared_directory
sudo chmod -R 755 /path/to/shared_directory #让其他主机也可进行读写编辑NFS配置文件
sudo vi /etc/exports
/path/to/shared_directory *(rw,sync,no_root_squash,no_subtree_check)或者指定范围子网
sudo vi /etc/exports
/path/to/shared_directory 172.20.22.0/24(rw,sync,insecure,no_root_squash,anonuid=99,anongid=99)rw:表示客户端可以以读写模式访问共享目录。sync:表示所有文件系统操作都将同步执行,确保数据立即写入磁盘。no_root_squash:表示远程的 root 用户将具有与本地 root 用户相同的权限。默认情况下,root 用户会被 "squash"(降低权限),通常是变成匿名用户nfsnobody。no_subtree_check:表示 NFS 服务器不会检查共享目录的父目录权限,这可以提高性能,但可能降低安全性。anonuid=UID和anongid=GID:可以指定匿名用户的 UID 和 GID。
共享示例
# 共享目录 /data/share1 给整个 192.168.1.0/24 网络,只读模式
/data/share1 192.168.1.0/24(ro,sync,secure)
# 共享目录 /data/share2 给特定客户端 192.168.1.100,读写模式,并禁用 root 用户映射
/data/share2 192.168.1.100(rw,sync,no_root_squash)
# 共享目录 /data/share3 给所有客户端,读写模式,异步写入
/data/share3 *(rw,async,no_subtree_check)配置文件更改生效
sudo exportfs -ra
systemctl restart nfs-servershowmout使用,用于查询NFS服务器的共享目录
showmount -e <server>:显示服务器上的 NFS 共享目录。showmount -a <server>:显示 NFS 服务器的客户端信息和共享目录。
防火墙配置
firewall-cmd --zone=public --add-port=111/tcp --permanent
firewall-cmd --zone=public --add-port=2049/tcp --permanent
firewall-cmd --zone=public --add-port=20048/tcp --permanent
firewall-cmd --reload接下来重点:如何通过应用服务器程序进行文件分片上传
一般传输文件是将整个文件进行传递,可以这样子理解:如果文件大小是200MB,则传输过程就是整个文件进行传递。若中间出现网络问题,那么传输失败。且网速在比较慢的时候,效率也会比较低
文件分片上传是将整个文件按照一定大小的进行拆解,然后分成多个大小相同的小文件,把这些小文件进行上传。因此,下面我给大家分享一下文件分片上传如何实现,望能帮助大家。
NFS应用程序编码实现有两种:
- 通过文件挂载点方式,然后通过基本的IO操作即可完成数据的通信
- 通过nfs-client客户端(基于Java的开源包),然后完成数据的通信
程序设计思路
我们重点分享第二种方法,nfs-client客户端(基于Java的开源包)
POM依赖
<dependency>
<groupId>com.emc.ecs</groupId>
<artifactId>nfs-client</artifactId>
<version>1.1.0</version>
</dependency>我们先介绍一下编码步骤(思路),后面在附上完整的代码
原理图
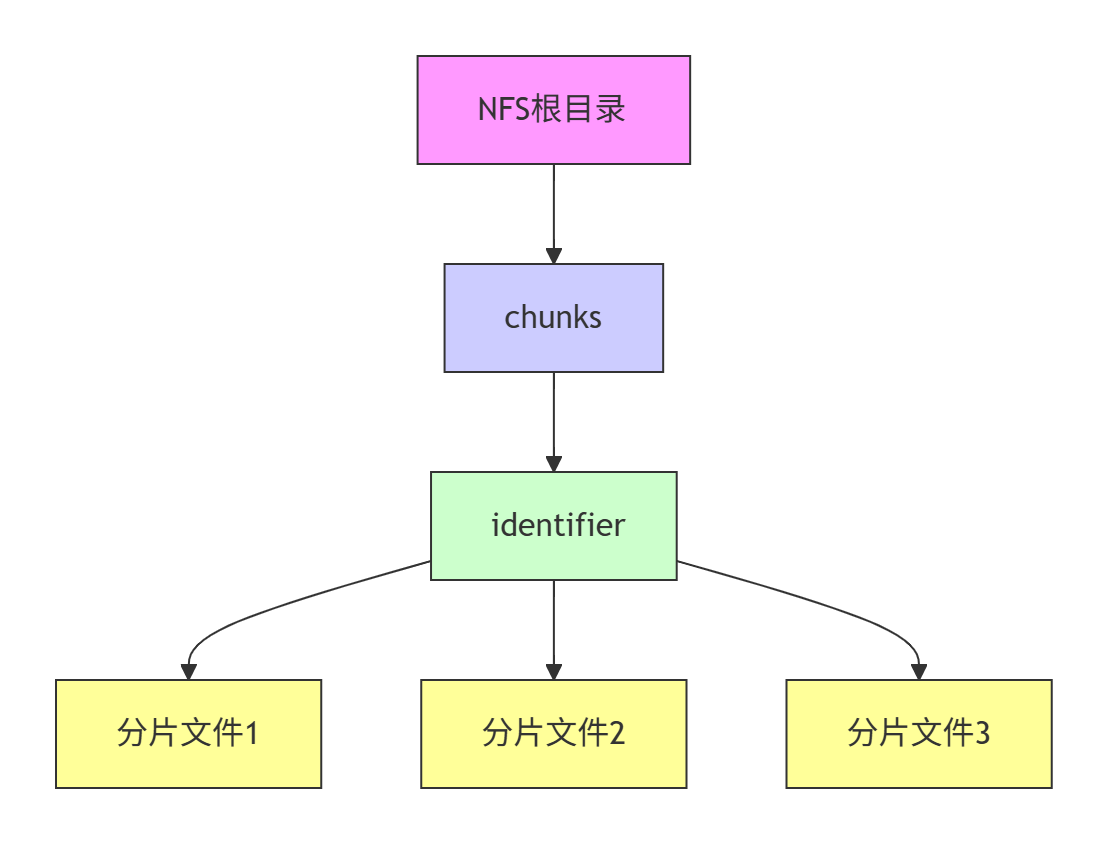
第一步:定义相关服务器的属性
// NFS服务器配置
private static final String NFS_SERVER = "172.20.22.159";
private static final String BASE_PATH = "/data/nginx/yktvideo";
private static final int UID = 99;
private static final int GID = 99;
// 目录常量
private static final String CHUNK_DIR = "chunks";
private static final String MERGED_DIR = "files";第二步:初始化nfs客户端
// 初始化NFS客户端(简单实现,实际应优化连接管理)
private static Nfs3 getNfsClient() throws IOException {
return new Nfs3(
NFS_SERVER,
BASE_PATH,
new CredentialUnix(UID, GID, null),
3
);
}第三步:目录权限属性设置
// 目录属性设置(与创建目录相同)
private static NfsSetAttributes createDirAttributes() {
NfsSetAttributes attrs = new NfsSetAttributes();
attrs.setMode(0777L);
attrs.setUid((long)UID);
attrs.setGid((long)GID);
return attrs;
}第四步:目录创建
注意:在目录创建时候,由于我们采用分片文件的方式进行上传,那么就会涉及到并发情况对目录的创建或是判断。这种情况会导致在并发环境下,多个线程可能同时检查目录是否存在,然后都尝试创建,导致其中一个线程在创建时会因为目录已被另一个线程创建而失败
可能会出现如下的程序500错误,这里我们需要记录这个程序错误
com.emc.ecs.nfsclient.nfs.NfsException: Error in NfsMkdirRequest serviceVersion:3 xid:798881163 usePrivilegedPort:false fileHandle:[1, 0, 7, 0, 43, -38, 13, 1, 0, 0, 0, 0, -27, -77, 74, -86, 25, -84, 67, 125, -127, -74, 89, 4, -112, 101, -16, 102] name:chunks attributes: [mode :511 uid: 99 gid: 99 size: null atime: timeSettingType:0, [seconds :0 nseconds: 0] mtime: timeSettingType:0, [seconds :0 nseconds: 0]] error code:NfsStatus:17所以,我们程序一定要有并发情况下的处理响应机制。比如:锁机制(下面的篇幅我会讲到)。但是如果程序没有锁机制情况,又如何处理。
虽然这个方案不需要锁机制,但在高并发场景下,您可以添加简单的重试逻辑
private static void ensureDirExistsWithRetry(Nfs3File dir) throws IOException {
int retryCount = 0;
while (retryCount < 3) {
try {
ensureDirExists(dir);
return;
} catch (IOException e) {
if (e.getMessage().contains("目录创建失败但报告已存在")) {
// 等待50ms后重试
Thread.sleep(50);
retryCount++;
} else {
throw e;
}
}
}
throw new IOException("目录创建重试失败: " + dir.getPath());
}如果你后面代码有锁机制,就直接使用 ensureDirExists 方法即可
// 创建目录,处理NFS3ERR_EXIST错误
private static void ensureDirExists(Nfs3File dir) throws IOException {
if(dir.exists()) return;
try {
dir.mkdir(createDirAttributes());
if (!dir.exists()) {
throw new IOException("目录创建失败: " + dir.getPath());
}
} catch (NfsException e) {
if (e.getStatus().getValue() == 17) {
if (!dir.exists()) {
throw new IOException("目录创建失败但报告已存在: " + dir.getPath());
}
return;
}
throw new IOException("NFS目录创建失败: " + dir.getPath());
}
}第五步:分片文件上传操作
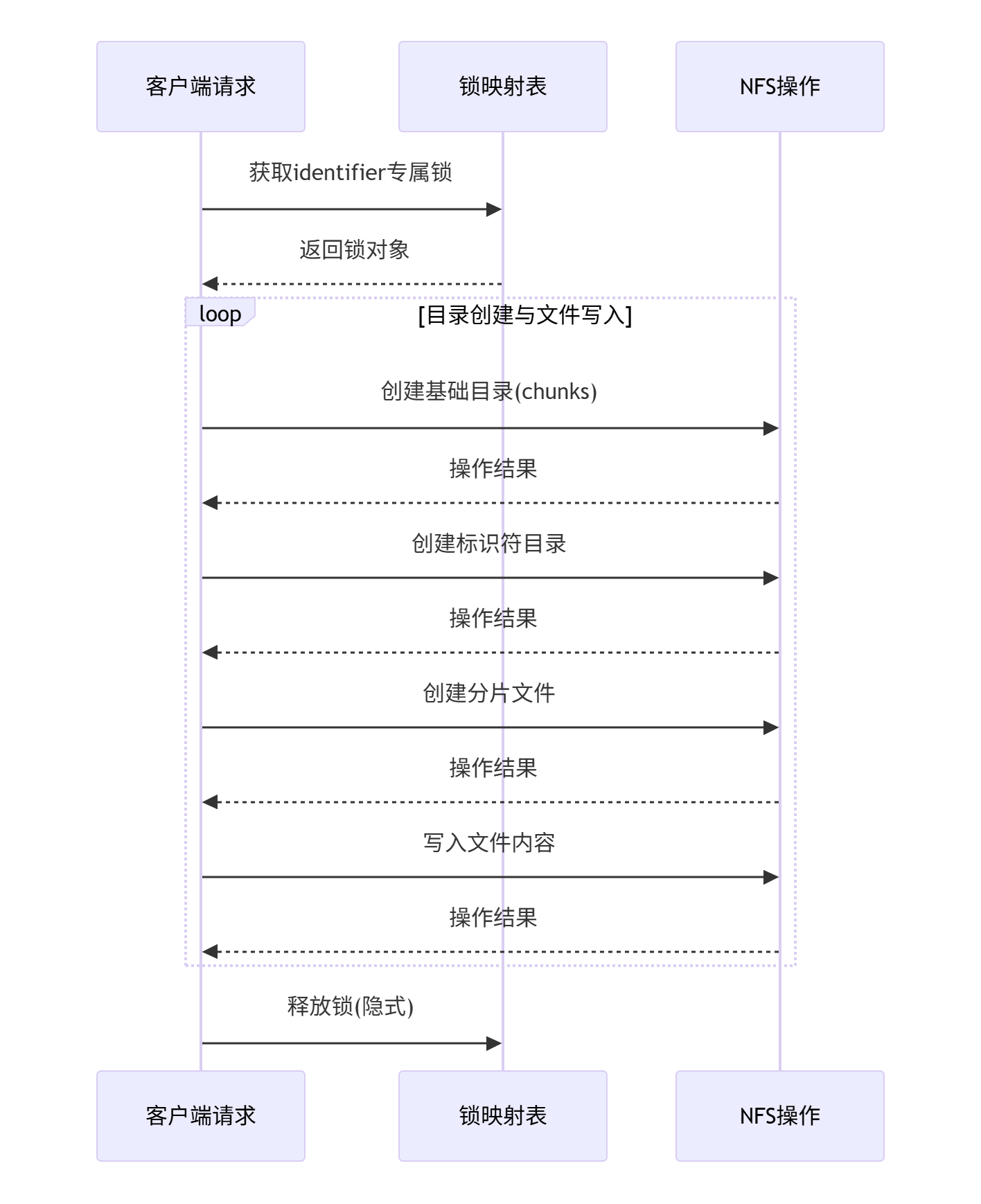
我们采用ConcurrentMap锁机制来确保每个identifier对应的目录只被创建一次。这里的关键是使用identifier作为锁的键,这样不同的identifier不会相互阻塞,而相同的identifier会通过锁确保只有一个线程执行目录创建。
具体步骤:
- 定义一个静态的ConcurrentMap来存储每个identifier对应的锁对象(或状态)。
- 在保存分片时,根据identifier获取一个专有的锁对象(使用ConcurrentMap的computeIfAbsent方法保证原子性)。
- 在同步块内,检查并创建目录(包括多级目录)。
- 然后写入分片文件。
// 保存分片文件
public static void saveChunk(Chunk chunk) throws IOException {
Nfs3 nfs = null;
String identifier = chunk.getIdentifier();
try {
nfs = getNfsClient();
// 创建 identifier 锁
Object dirLock = DIR_LOCK_MAP.computeIfAbsent(identifier, k -> new Object());
synchronized (dirLock) {
// 目录创建
String[] dirs = {CHUNK_DIR, identifier};
Nfs3File currentDir = new Nfs3File(nfs, "/");
for (String dir : dirs) {
currentDir = new Nfs3File(currentDir, dir);
ensureDirExists(currentDir);
}
// 创建分片文件
Nfs3File chunkFile = new Nfs3File(currentDir, String.valueOf(chunk.getChunkNumber()));
// 写入文件内容
try (OutputStream out = new NfsFileOutputStream(chunkFile)) {
out.write(chunk.getFile().getBytes());
}
// 验证文件写入
if (!chunkFile.exists() || chunkFile.length() == 0) {
throw new IOException("分片文件写入失败: " + chunkFile.getPath());
}
}
} finally {
if (nfs != null) nfs = null;
// 清理锁
// DIR_LOCK_MAP.remove(identifier);
}
}设计说明:
-
锁的获取:
- 使用
ConcurrentMap.computeIfAbsent方法为每个identifier获取一个锁对象。这个方法保证原子性,即多个线程同时调用时,同一个identifier只会创建一个锁对象。 - 在
synchronized(lock)块内,执行目录创建和文件写入操作,确保同一个标识符的多个分片在上传时,目录创建是串行的。
- 使用
-
目录创建流程:
- 从根目录(
/)开始,依次创建chunks和identifier目录。 - 使用循环逐级创建,每一级都调用
ensureDirExists方法。 ensureDirExists方法内部处理了NFS3ERR_EXIST错误,即使多个线程同时创建同一个目录,也能安全处理。
- 从根目录(
-
文件写入:
- 在锁的保护下,创建分片文件并写入数据。
- 写入后,可选地检查文件是否存在以及大小是否大于0,确保写入成功。
优势:
- 并发性能:不同
identifier的目录创建和文件写入可以并行进行,互不阻塞。 - 代码简洁:保留了原有的目录创建方式,易于理解和维护。
- 健壮性:处理了NFS协议特有的错误(NFS3ERR_EXIST),确保在并发创建目录时不会失败。
注意事项:
- 锁的范围:锁只针对同一个标识符的目录创建和文件写入。不同标识符的操作不受影响。
- 资源清理:由于Nfs3对象没有close方法,我们在finally块中将其置空,依赖GC回收。
- 锁的移除:为了节省内存,可以考虑在操作完成后从
identifierLocks中移除锁对象。但是要注意,在分片上传过程中,同一个标识符可能会多次调用saveChunk(每个分片调用一次),所以不能立即移除。如果担心内存泄漏,可以在一个较长时间没有使用该标识符后移除(比如使用定时任务或WeakReference)。不过,在大多数情况下,标识符的数量不会无限增长(因为文件上传完成后标识符就不再使用),所以暂时不处理也是可以的。
这个方案既保证了并发安全,又保留了原有的目录创建方式,同时通过锁机制避免了重复创建目录导致的NFS错误。
性能优化建议
虽然锁机制会增加少量开销,但在高并发环境下,可以通过以下方式优化:
- 锁范围最小化:只将必要的操作放入同步块
- 锁过期机制:添加定时清理长时间未使用的锁
- 性能监控:记录锁等待时间和操作耗时
- 连接池:实现NFS客户端连接池(如果支持)
这个方案完美结合了您原有的目录创建方式和锁机制的优势,既保证了高并发环境下的安全性,又保持了代码的简洁性和一致性。

















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









