




 本文介绍Elasticsearch中的高级查询技巧,包括排序、分页、布尔查询等,并详细解析映射(mappings)的概念及应用,帮助读者更好地理解和使用Elasticsearch。
本文介绍Elasticsearch中的高级查询技巧,包括排序、分页、布尔查询等,并详细解析映射(mappings)的概念及应用,帮助读者更好地理解和使用Elasticsearch。
💮目录
文章目录
进阶查询
sort排序
代码:
GET a1/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
desc是降序排序,asc是升序
结果如下:
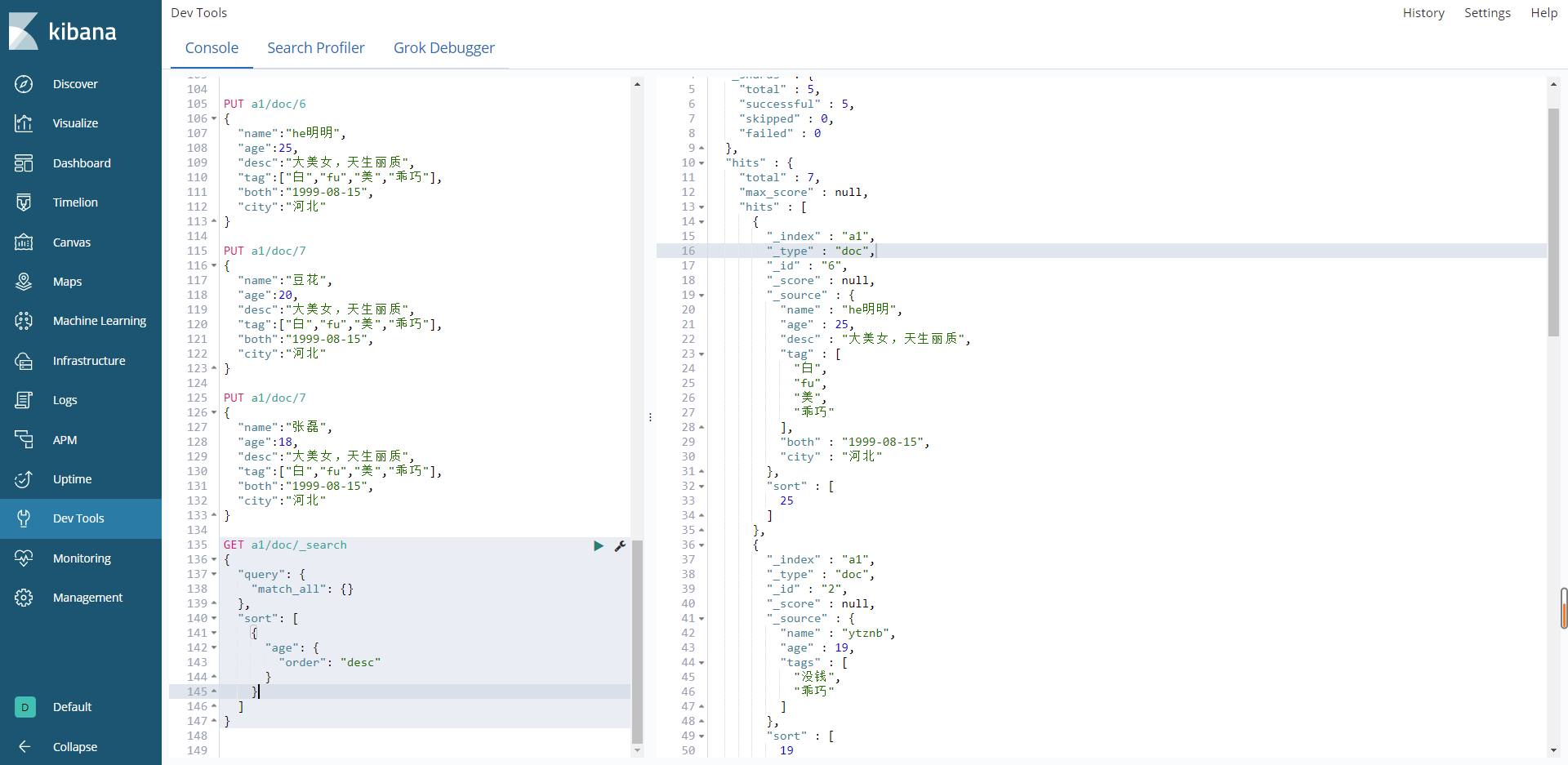
注意,并不是所有的数据类型都能排序!!!!!!!**
分页查询
随着数据量的不端增大,查询结果也展示的越来越长,很多时候我们仅仅只是查询几条数据,不用全部显示出来。这个时候就要用到分页查询了。
只要指定的数据量
这个代码的意思是从第0个开始给2个
GET a1/doc/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
布尔查询
查询city为河北的
# 查询city是河北的
GET a1/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"city": "河北"
}
}
]
}
}
}
结果: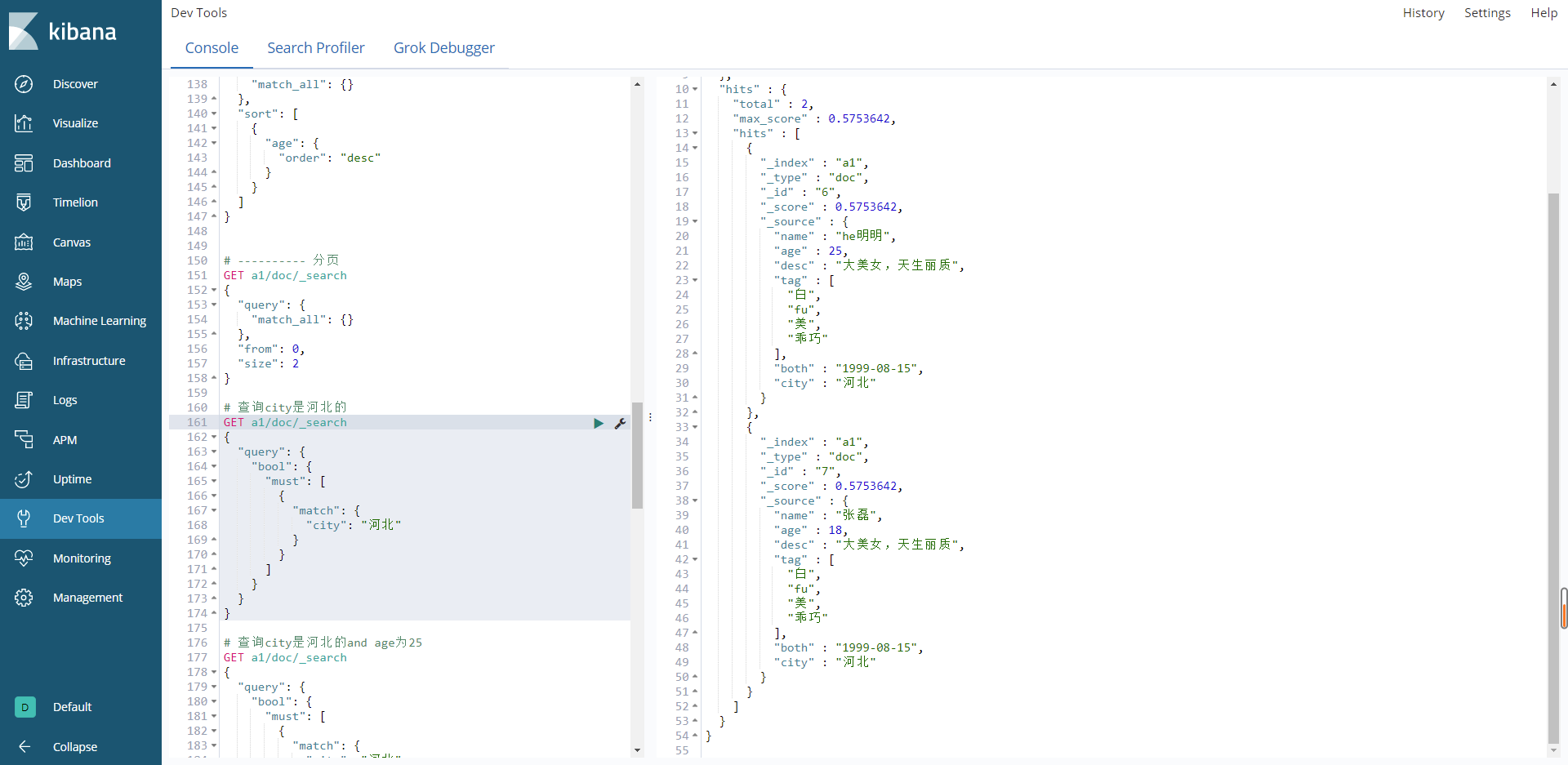
must关键字–and
查询city是河北的and age为25
# 查询city是河北的and age为25
GET a1/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"city": "河北"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
结果:
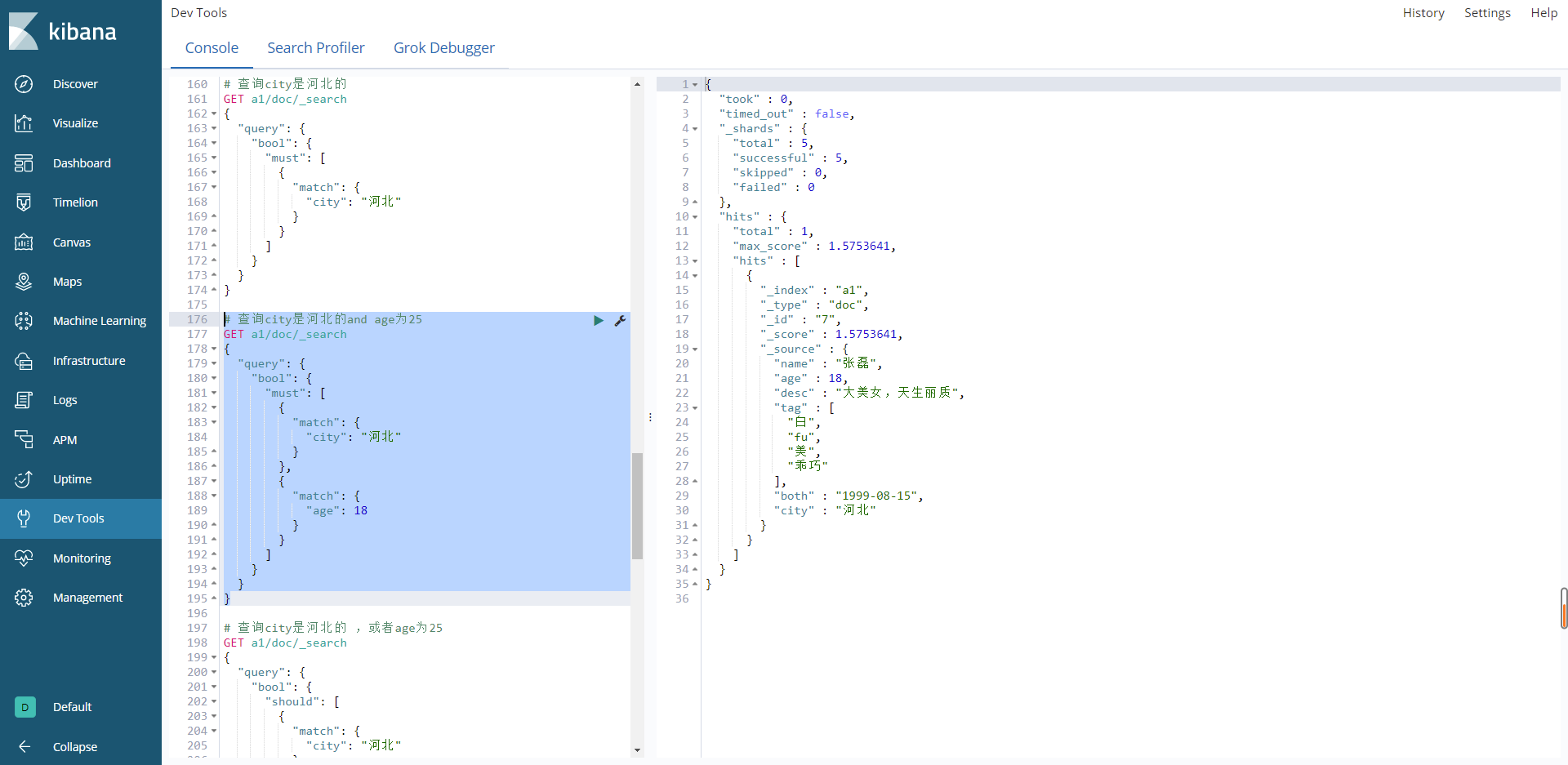
should关键字–or
查询city是河北的 ,或者age为25
# 查询city是河北的 ,或者age为25
GET a1/doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"city": "河北"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
结果:
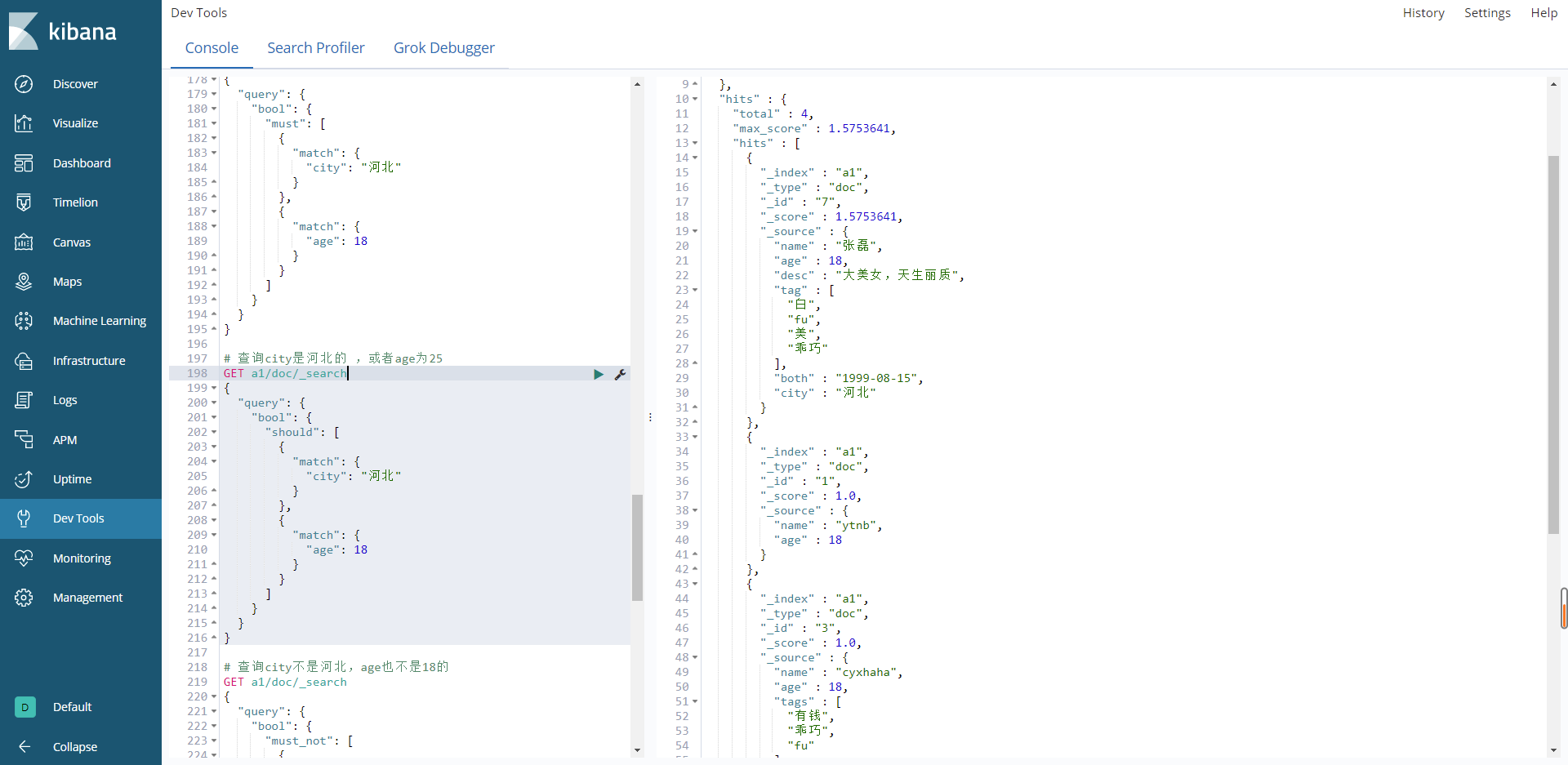
must_not关键字–not
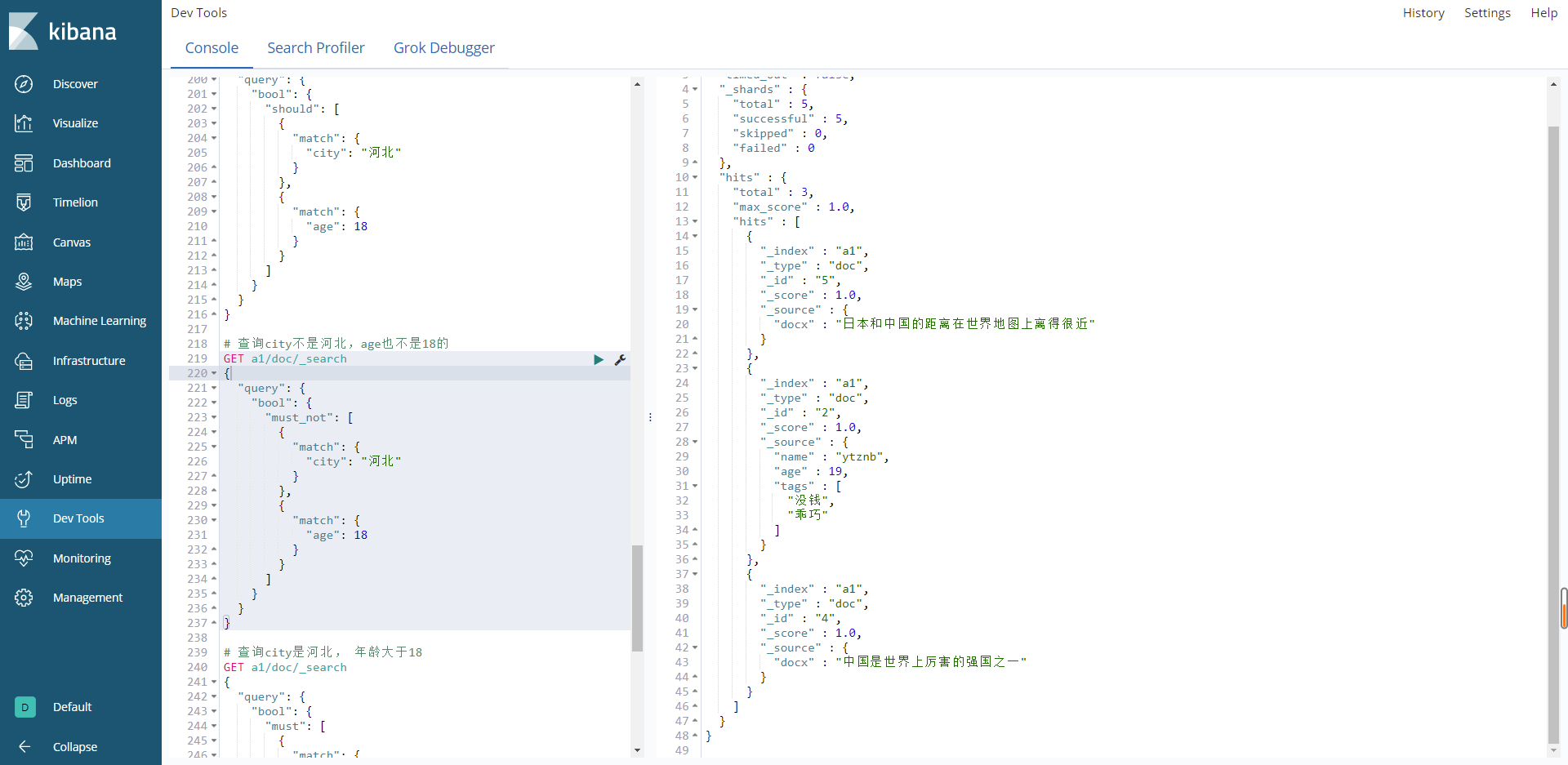
查询city不是河北,age也不是18的
GET a1/doc/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"city": "河北"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
结果:
filter关键字–大于小于
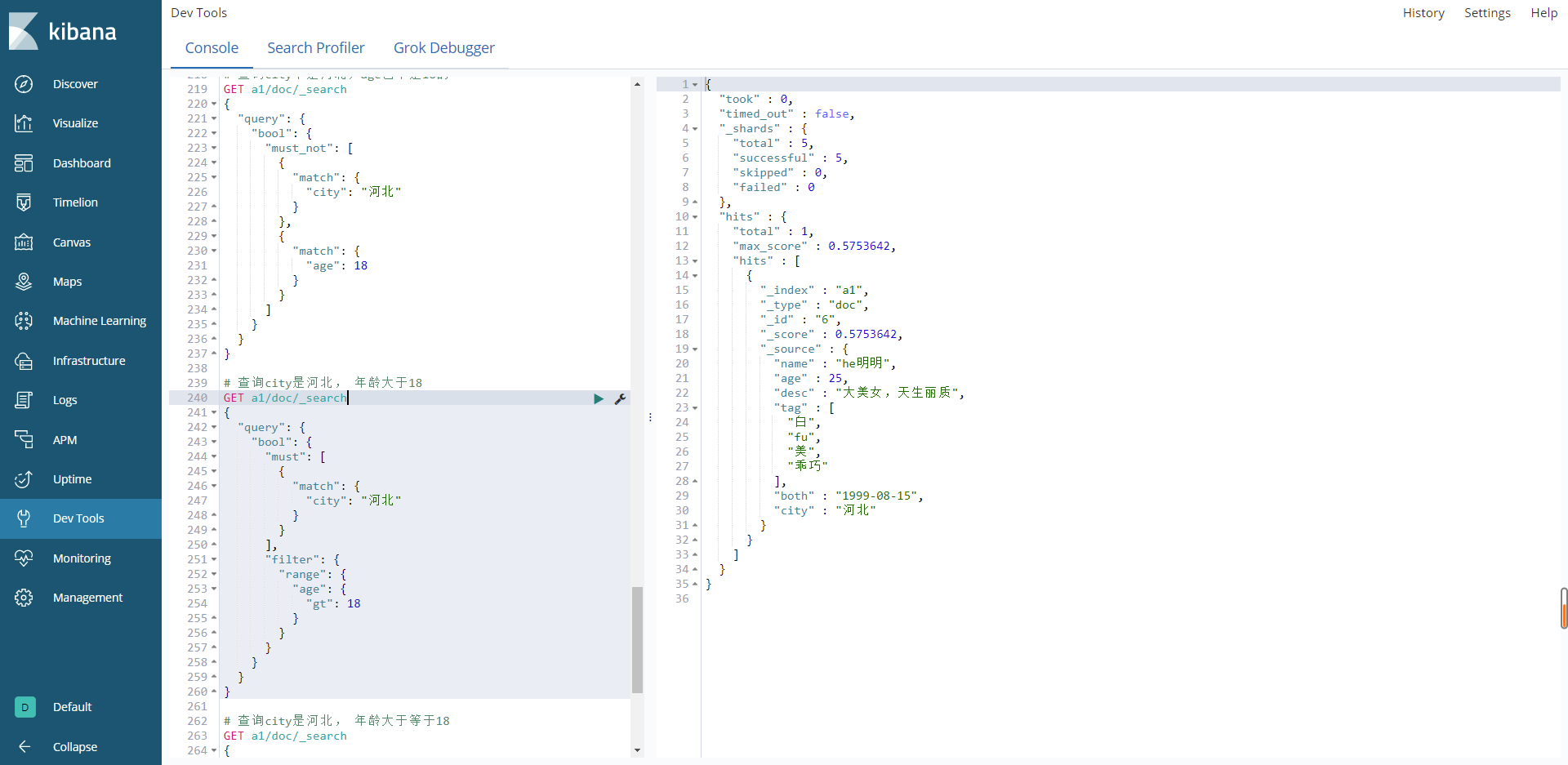
查询city是河北和年龄大于18
# 查询city是河北, 年龄大于18
GET a1/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"city": "河北"
}
}
],
"filter": {
"range": {
"age": {
"gt": 18
}
}
}
}
}
}
结果:
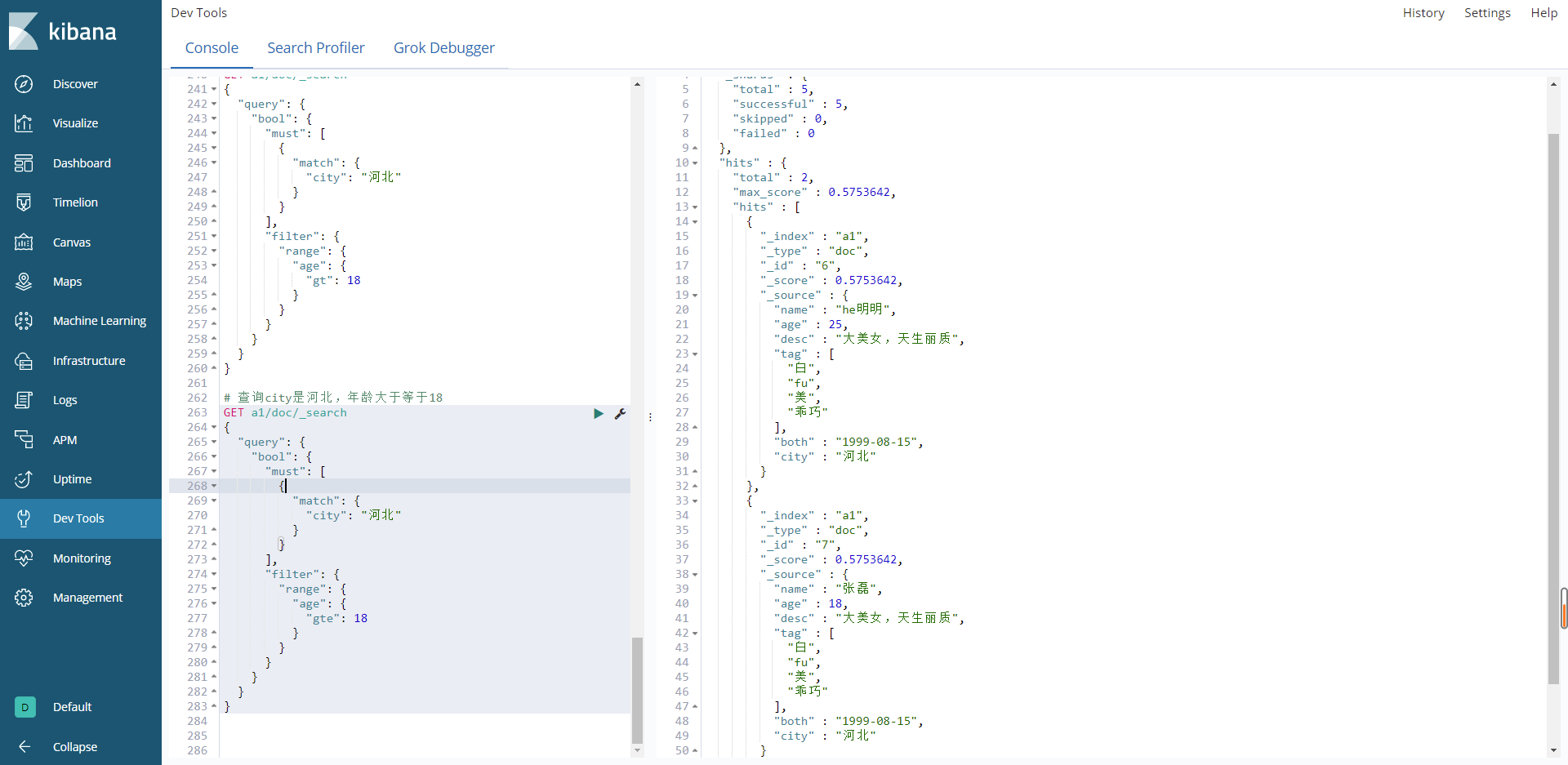
查询city是河北和年龄大于等于18
# 查询city是河北,年龄大于等于18
GET a1/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"city": "河北"
}
}
],
"filter": {
"range": {
"age": {
"gte": 18
}
}
}
}
}
}
结果:
小结:
must:与关系,相当于关系型数据库中的and。should:或关系,相当于关系型数据库中的or。must_not:非关系,相当于关系型数据库中的not。filter:过滤条件。range:条件筛选范围。gt:大于,相当于关系型数据库中的>。gte:大于等于,相当于关系型数据库中的>=。lt:小于,相当于关系型数据库中的<。lte:小于等于,相当于关系型数据库中的<=。
减少输出字段,结果过滤
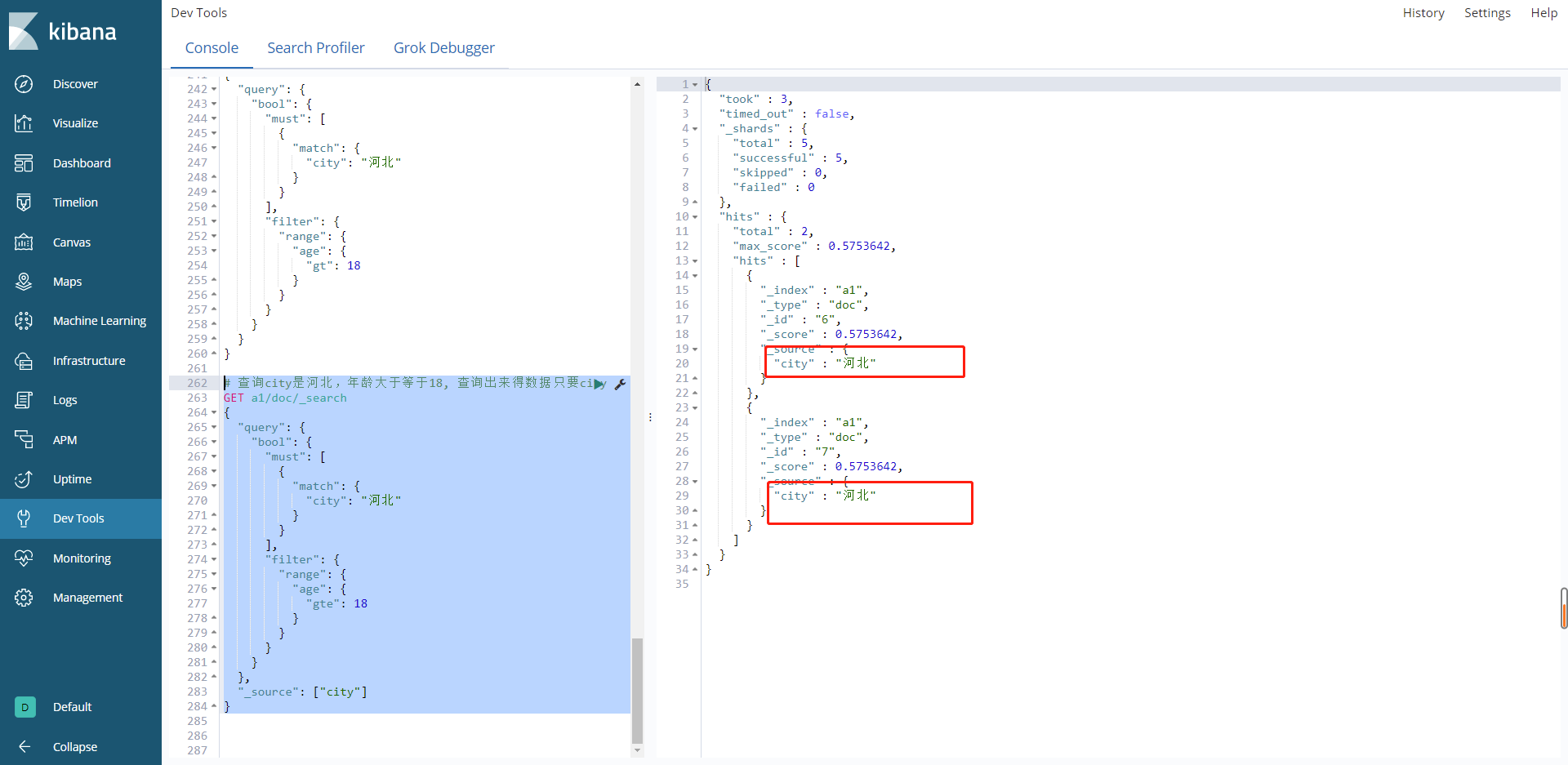
当我们在获取数据的时候,不太希望所有的数据都展示出来就像select name from user的sql语句一样,可以单独将name字段提取出来,这样个操作的代码是加上_source字段进行筛选。
# 查询city是河北,年龄大于等于18, 查询出来得数据只要city
GET a1/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"city": "河北"
}
}
],
"filter": {
"range": {
"age": {
"gte": 18
}
}
}
}
},
"_source": ["city"]
}
结果:
高亮查询
当我们想在搜索关键字的时候加高亮显示,我们就可以使用高亮查询,假设我们这里想在描述中查询带有丽质词语的数据,并且加上高亮
GET a1/doc/_search
{
"query": {
"match": {
"desc": "丽质"
}
},
"_source": ["desc"],
"highlight": {
"fields": {
"desc":{}
}
}
}
结果:
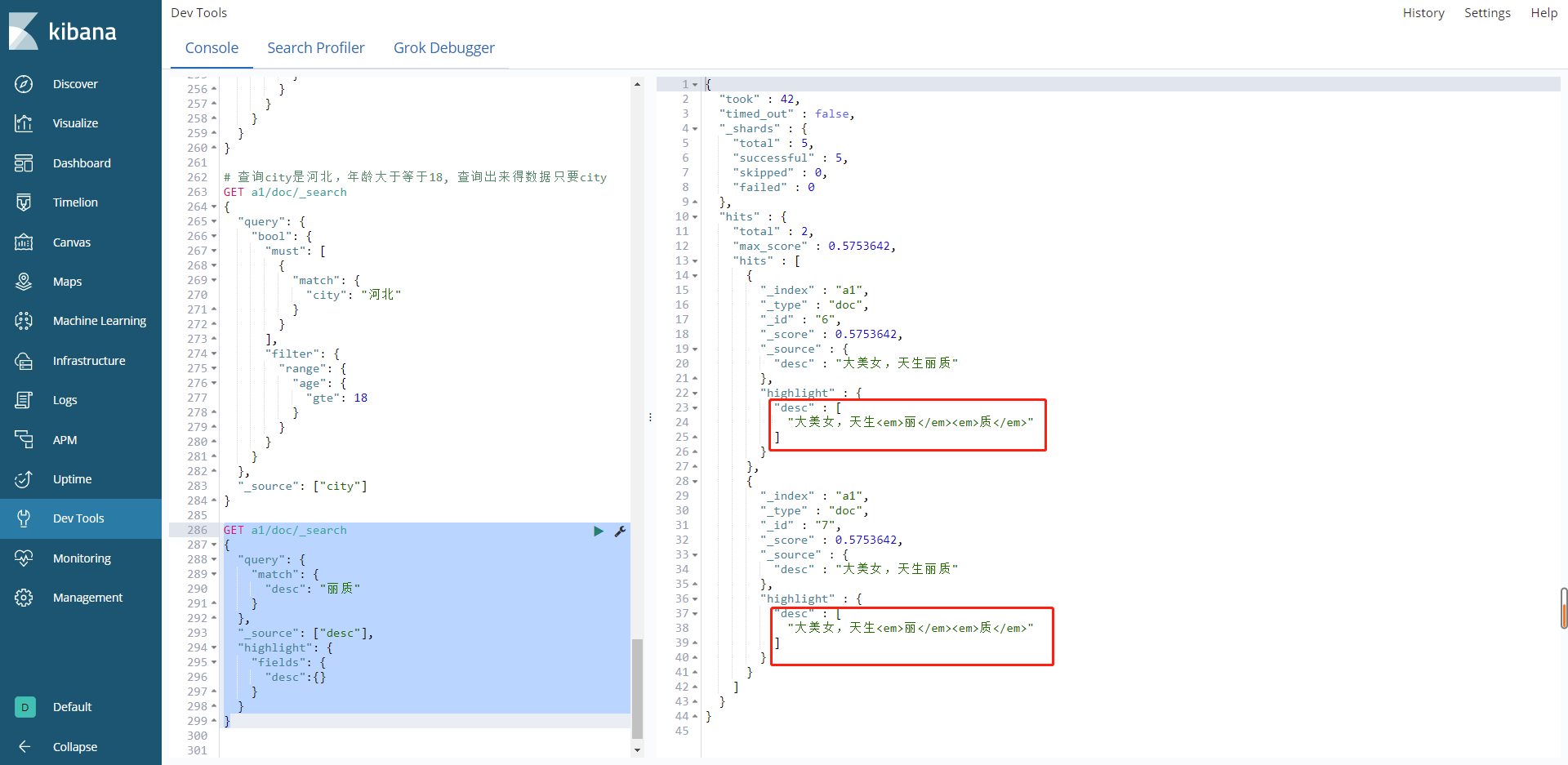
都给套上了<em></em>标签
自己加样式
要是想自己设定样式可以这么做:
GET a1/doc/_search
{
"query": {
"match": {
"desc": "丽质"
}
},
"_source": ["desc"],
"highlight": {
"pre_tags": "<b style='color :grenn'>",
"post_tags": "</b>",
"fields": {
"desc":{}
}
}
}
结果是:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









