







 本文介绍了强大的文本分析工具awk,它在数据分析和生成报告方面功能强大。详细阐述了awk的调用方式,包括命令行、shell脚本等;介绍了常用内置变量、正则表达式、条件判断;还给出了操作实例,如print和printf函数使用、NF与$NF的应用及awk脚本编写。
本文介绍了强大的文本分析工具awk,它在数据分析和生成报告方面功能强大。详细阐述了awk的调用方式,包括命令行、shell脚本等;介绍了常用内置变量、正则表达式、条件判断;还给出了操作实例,如print和printf函数使用、NF与$NF的应用及awk脚本编写。
awk是一个强大的文本分析工具,相比于grep查找,sed编辑,awk在对数据分析并生成报告时,功能更为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
一. awk 调用方式
1.命令行
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
2. shell脚本
将所有的awk命令插入一个文件,使awk程序可执行,制定awk的解释器,相当于shell的首行: #!/bin/bash 换成:#!/bin/awk
3.将awk命令插入一个单独文件
awk -f awk-script-file input-file
其中 ,-f 选项加载awk-script-file中的awk脚本
二. 常用awk内置变量
$0 表示整个当前行
$1-$n 当前行的第n个字段
NF 当前记录中的字段个数,列数
NR 已读出的记录数,行号
FS BEGIN时定义分隔符
RS 输入的记录分隔符,默认为换行符
OFS 输出字段分隔符
ORS 输出记录分割符
三. awk 正则
^ 匹配行首 /^root/ 匹配所有以root开头的行
$ 匹配行尾 /root$/ 匹配所有以root结尾的行
. 匹配单个任意字符 /r..t/ 匹配字母r和任意两个字符,再以t结尾的行
* 匹配0个或多个前导字符 /r*t/ 匹配0个或多个r之后紧跟着t的行
+ 匹配1个或多个前导字符 /r+t/ 匹配1个或多个r之后紧跟着t的行
? 匹配0个或多个前导字符 /r?t/ 匹配1个或0个r之后紧跟着t的行
[] 匹配制定字符组内的任意一个字符 /^[abc]/ 匹配以字母a或b或c开头的行
[^] 匹配不在制定字符组内的任意一个字符 /^[^abc]/ 匹配不以字母a或b或c开头的行
() 子表达式组合 /(root)+/ 表示一个或多个root组合
| 或者 /(root)|B/ 匹配root或者B的行
\ 转义 /a\/\// 匹配a//
~,!~ 匹配,不匹配 $1 ~/root/ 匹配第一个字段包含root的记录
x{m} x重复m次 /(root){3}/ x可以表示字符串也可以表示单个字符
x{m,} x重复最少m次 /(root){3,}/ root加括号,表示匹配root 3次,rootrootroot
x{m,n} x重复m到n次 /(root){3,5}/ root不加括号,表示匹配roo再加上3个t,roottt
四. awk条件
1. 正则(模糊查找)
/正则/ 全行匹配
~/正则/ 某一列匹配
!~/正则/ 某一列不匹配
awk -F ':' '$1~/正则/{指令}' 文件
2. 字符数字(精确查找)
awk -F ":" '$1=="root"' /etc/passwd # = 赋值, == 判断
3. 逻辑判断
&& 且 || 或
提取uid大于有100,且小于500的用户
awk -F ':' '$3>100&&$3<500{print $1,$3}' /etc/passwd
五. 操作实例
1.print和printf
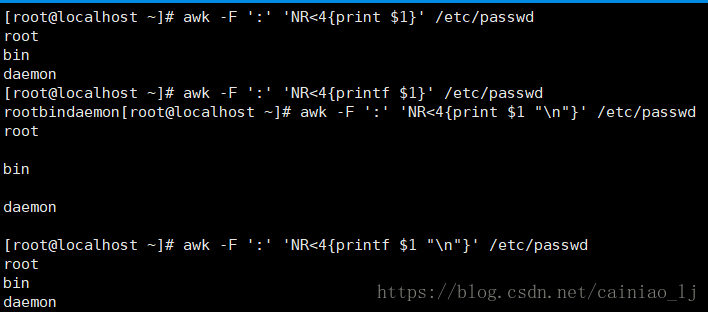
统计/etc/passwd:文件名,行号,列数,行内容
# awk -F ':' '{print "filename:" FILENAME ",linenum:" NR ",colum:" NF ",content:" $0'} /etc/passwd
filename:/etc/passwd,linenum:1,colum:7,content:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenum:2,colum:7,content:bin:x:1:1:bin:/bin:/sbin/nologin
filename:/etc/passwd,linenum:3,colum:7,content:daemon:x:2:2:daemon:/sbin:/sbin/nologin
可以使用printf替代print
# awk -F ':' '{printf("filename:%s,linenumber:%s,colum:%s,content:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的。
printf函数,可以格式化字符串,输出复杂时,printf可以使代码更易懂。
print默认带有换行符,printf没有
printf格式说明符
%c 打印单个ASCII字符
%d 打印一个十进制数
%f 打印一个浮点数
%s 打印一个字符串
#echo 'hello,awk' | awk '{printf "|%-20s|\n",$1}'
|hello,awk |
打印一个占20个格,向左对齐的字符串
#echo 'hello,awk' | awk '{printf "|%20s|\n",$1}'
打印一个占20个格,向右对齐的字符串
2. NF 与$NF
NF 表示记录行的列数
$NF 表示最后一列的值
awk '/Failed/{print $(NF -3)}' /var/log/secure
过滤系统登陆失败的IP,NF -3 就是倒数第四列的值
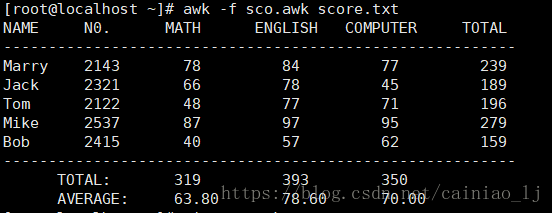
3. awk脚本
BEGIN{执行前的语句}
END{处理完所有的行之后执行的语句}
{处理每一行都要执行的语句}
假如有这么一个文件
#nl score.txt
1 Marry 2143 78 84 77
2 Jack 2321 66 78 45
3 Tom 2122 48 77 71
4 Mike 2537 87 97 95
5 Bob 2415 40 57 62
awk脚本如下:
#!/bin/awk
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME N0. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------------------\n"
}
{
math += $3
english +=$4
computer +=$5
printf "%-8s %-10d %-10d %-10d %-10d %-10d\n",$1,$2,$3,$4,$5,$3+$4+$5
}
END {
printf "---------------------------------------------------------\n"
printf " TOTAL:%10d %11d %10d \n",math,english,computer
printf " AVERAGE:%10.2f %11.2f %10.2f \n",math/NR,english/NR,computer/NR
}
执行结果

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









