



一、MySQL数据库的基本概述
1.1 MySQL数据库介绍
MySQL 的发展历史可以追溯到 1995 年,以下是 MySQL 的主要里程碑和发展阶段:
- 1995 年:MySQL 诞生:MySQL 由瑞典开发人员 Michael Widenius 和 David Axmark 创建。最初是为了用于自己的网站项目而开发的。
- 1996 年:首个公开发布版本:MySQL 1.0 在1996年发布,成为开源项目,并迅速获得了用户的关注。
- 2000 年:MySQL AB 公司成立:MySQL AB 公司成立,专注于 MySQL 数据库的开发、支持和商业服务。这一时期,MySQL 开始在企业领域取得一定的市场份额。
- 2001 年:MySQL 3.23 发布:MySQL 3.23 版本引入了一些重要的特性,包括支持 InnoDB 存储引擎和 ACID 事务。
- 2003 年:MySQL 4.0 发布:引入了更多的特性,包括子查询、视图等,进一步提升了 MySQL 的功能。
- 2005 年:MySQL 5.0 发布:引入了存储过程、触发器、视图等高级特性,使 MySQL 在企业级应用中更具竞争力。
- 2008 年:Sun Microsystems 收购 MySQL AB:Sun Microsystems 收购了 MySQL AB 公司,使 MySQL 成为 Sun 公司旗下的一部分。
- 2010 年:Oracle 收购 Sun Microsystems:Oracle 公司收购了 Sun Microsystems,从而拥有了 MySQL。这引发了一些关于 MySQL 的开源性质和未来发展的担忧。
- 2010 年:MariaDB 分支创建:由于对 MySQL 的未来发展担忧,MySQL 的创始人 Michael Widenius 创建了 MariaDB,作为 MySQL 的一个分支。
- 2013 年:MySQL 5.6 发布:引入了更多的优化和特性,包括 NoSQL 支持、全文搜索等。
- 2016 年:MySQL 8.0 发布:引入了 JSON 数据类型、Window Functions 等新特性,进一步提升了性能和功能。
- 2020 年:Oracle Cloud 上的 MySQL 8.0 发布:MySQL 8.0 在 Oracle Cloud 上发布,带来了更多云原生的特性和优化。
1.2 为什么要使用数据库
在数据库之前我们的数据一般是保存在内存中的(变量、数组、集合)。保存在内存中的数据存取效率确实非常高,但是有个缺点就是保存的数据量不大,并且随着程序的推出后者电脑关机,存储在内存中的数据也会随着消失。
后面学到了文件,发现数据可以保存在文件中,这样就可以实现数据的持久化保存,但是问题又来了,在操作数据时我们需要频繁的io操作,而这种操作方式效率不高,并且我们也不能在文件中保存海量数据,因为一旦文件比较大,对于数据的存取非常不方便。
这个时候,我们需要把数据保存在数据库中。
数据库有什么特点:
数据库保存的数据本质上还是以文件的形式存储的,所以能够做到持久化的存储数据。
由于数据库提供了一套完善的数据操作机制(sql语句)。所以在进行数据操作的时候,效率非常高。
1.3 数据库软件有哪些
数据库又称为存储数据的仓库。它是一个软件,能够帮助我们方便的管理数据。市面上有很多数据库软件:
Oracle 甲骨文公司的产品,是业界最流行的数据库产品之一。
SqlServer 微软的关系型数据库产品,它基于windows平台开发,在进行c# .net开发的时候,一般都会使用SqlServer。
DB2: IBM公司的产品
MySQL:开源组织的产品,小巧免费,适合中小企业。
上面说的这些数据库都是关系型数据库。所谓关系型数据库就是数据以表的形式存储(行 列)
也有非关系型数据库,这种数据库存储数据不再以表的形式存储数据(redis mongodb)。我们在学习的时候,我们使用mysql数据库来学习。
二、 MySQL系统架构
下图是MySQL 5.7 及其之前版本的逻辑架构示意图:

MySQL架构大致可分为一下四层:
- 连接层:跟客户端建立连接并验证权限。
- 服务层:包括查询缓存、解析器、优化器、执行器等,大多数MySQL核心业务功能都在这一层,涵盖了查询解析、优化、缓存以及所有的内置函数。所有的跨存储功能都在这一层实现,比如存储过程、触发器、视图等。
- 存储引擎层:负责MySQL中数据的存储与提取,与底层系统文件进行交互。
- 系统文件层:负责将数据库的系统文件和日志存储在文件系统上,并完成与存储引擎的交互,是文件的物理存储层。
2.1 连接层
系统(客户端)访问 MySQL 服务器前,做的第一件事就是建立 TCP连接。经过三次握手建立连接成功后, MySQL 服务器对 TCP 连接。 TCP 传输过来的账号密码做身份认证、权限获取。
用户名或密码不对,会收到一个Access denied for user错误,客户端程序结束执行。
用户名密码认证通过,会从权限表查出账号拥有的权限与连接关联,之后的权限判断逻辑,都将依赖于此时读到的权限。
TCP 连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。还会有个线程池,去走后面的流程。每一个连接从线程池中获取线程进行数据库操作,省去了创建和销毁线程的开销。
2.2 服务层
对SQL语句进行查询处理,与数据库文件的存储方式无关。
在服务层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化:如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。
如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
-
SQL接口 SQL Interface:接收用户的SQL命令,并且返回用户续约查询的结果
-
SQL的分析和优化 Parser 解析器: 在解析器中对SQL语句进行语法分析、语义分析。将SQL语句分解成数据结构并将这个结构传递到后续步骤。以后SQL语句的传递和处理就是基于这个结构的。 生成对应的语法树
(1) SQL Interface: SQL接口
-
接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT ... FROM就是调用SQL Interface
-
MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定义函数等多种SQL语言接口
(2) Parser: 解析器
-
在解析器中对 SQL 语句进行语法分析、语义分析。将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,那么就说明这个SQL语句是不合理的。
-
在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建语法树,并根据数据字典验证该客户端是否具有执行该查询的权限。创建好语法树后,MySQL还 会对SQl查询进行语法上的优化,进行查询重写。
(3) Optimizer: 查询优化器
-
SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个执行计划。
-
这个执行计划表明应该使用哪些索引进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。
-
它使用“ 选取-投影-连接 ”策略进行查询。例如:
SELECT id,name FROM student WHERE gender = '女';
这个SELECT查询先根据WHERE语句进行选取,而不是将表全部查询出来以后再进行gender过滤。 这个SELECT查询先根据id和 name进行属性过滤,将这两个查询条件投影,而不是将属性全部取出以后再进行过 连接起来生成最终查询结果。
(4) Caches & Buffers: 查询缓存组件
-
MySQL内部维持着一些Cache和Buffer,比如Query Cache用来缓存一条SELECT语句的执行结 果,如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、优化和执行的整个过 程了,直接将结果反馈给客户端。
-
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 。
-
这个查询缓存可以在 不同客户端之间共享。
-
从MySQL 5.7.20开始,不推荐使用查询缓存,并在 MySQL 8.0 中删除 。
2.3 存储引擎层
插件式存储引擎层( Storage Engines),真正的负责了MySQL中数据的存储和提取,对物理服务器级别 维护的底层数据执行操作,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。
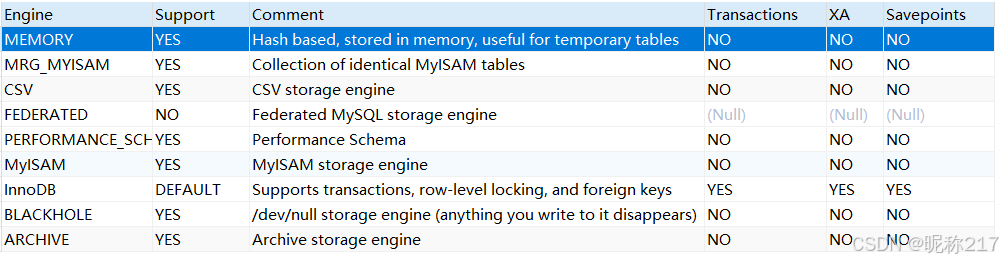
MySQL 8.0.25默认支持的存储引擎如下:
2.4 系统文件层
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在文件系统上,以文件的方式存在的,并完成与存储引擎的交互。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设备,但现代文件系统的实现使得这样做没有必要了。在文件系统之下,可以使用本地磁盘,可以使用 DAS、NAS、SAN等各种存储系统。
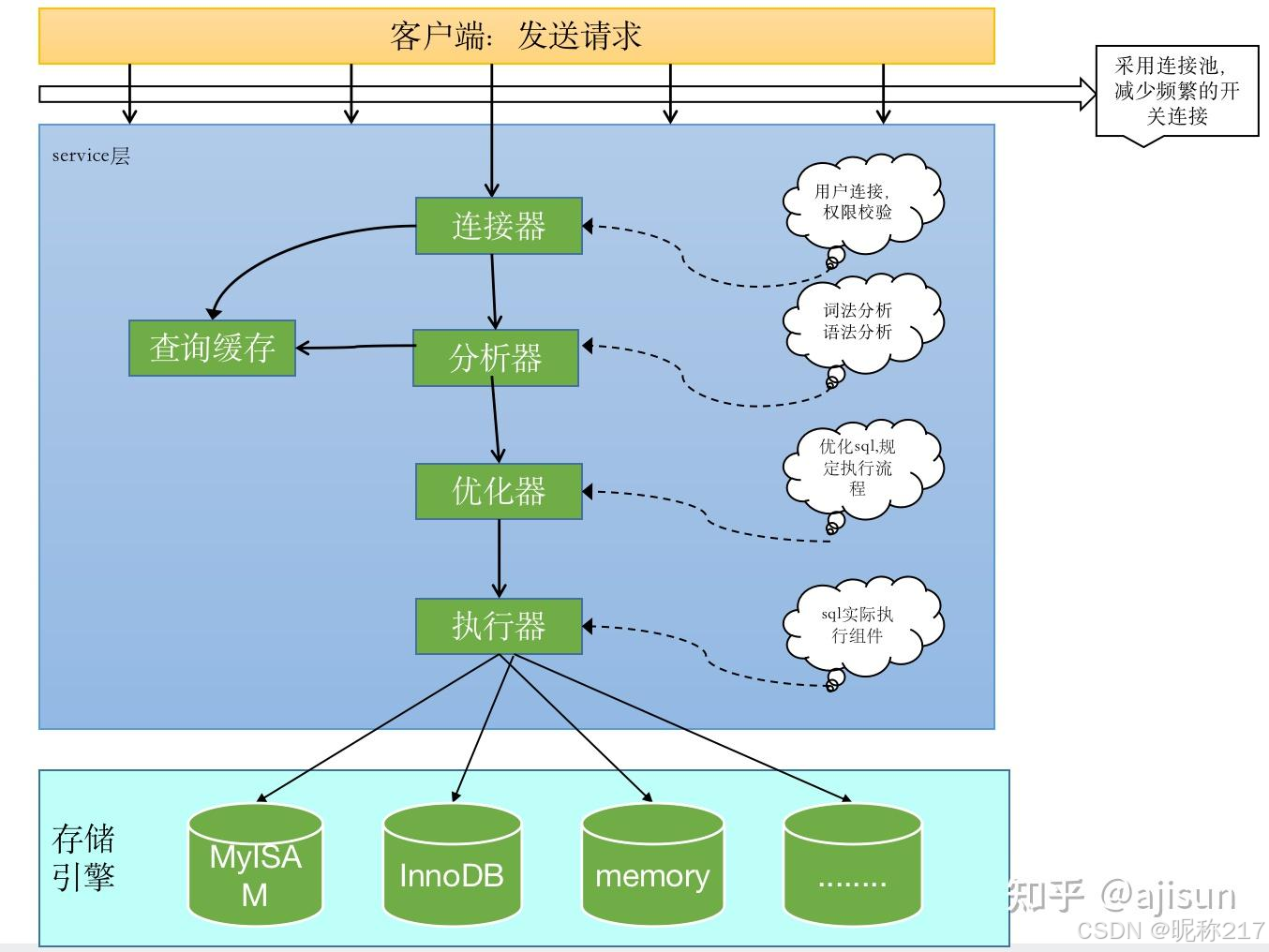
总结:SQL语句执行流程如下图:


















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









