



研究背景
流量分类是识别网络中的不同的流量类型,能用于提供不同的QoS,提升QoE及网络规划和资源分配。当前的大多数网络应用HTTPS,无法直接看到应用层的内容,所以分类变得更加困难。传统的机器学习在ETC上效果不好,DL方法在ETC中表现更为优秀。
当前的DL方法性能依赖与架构和数据集。容易出现不同的架构,不同的数据集效果差距很大。这种情况可以归结为数据漂移 + 模型架构不合适,耗时耗力,依赖于专家的经验,基本都是试错法。
创新点
作者的做法是:设计了AutoML4ETC,用于自动设计高效的神经网络架构来进行加密流量分类。
他们定义了一个新的搜索空间,特别是针对早期分类的场景。(不用看完整的流量,只需要前面几个包就可以判断应用/服务)(早期分类)
AutoML4ECT找到的架构不仅准确,而且参数量少。(轻量化)
论文方法
论文的核心部分包括:1.搜索空间;2.搜索策略;3.子模型训练策略
1.搜索空间
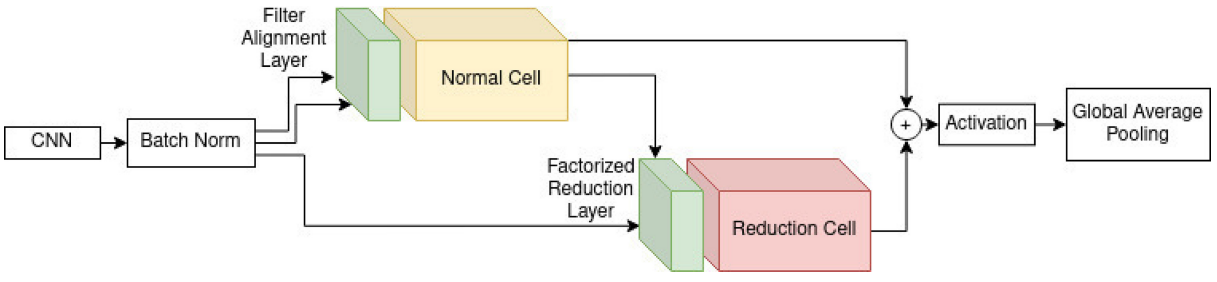
搜索空间包括:add、concatenate。连接:输入、输出之间的连接方式。层数:各种卷积。
首先,这种图是子模型的基本结构。作者定义每个子模型包括一个Normal Cell 和 Reduction Cell组成。这两个cell都是由搜索空间中积木搭建而成。此外,在每个cell之前都有预处理层。两种cell前面的预处理层不同,分别称为:Filter Alignment 层 和 Factorized Reduction 层。
Filter Alignment 层:对输入特征加一些“滤波器”。
Factorized Reduction 层:为了将特征图尺寸缩小。
其实这两个预处理层可以理解成一个是特征对齐,一个是下采样。
2.搜索策略
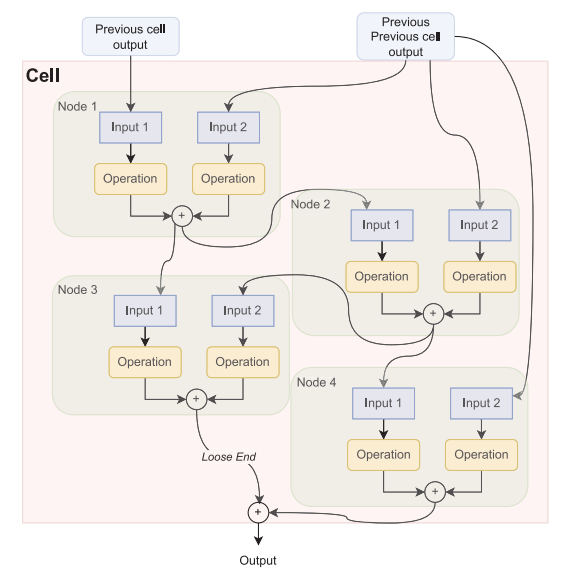
每个节点都有两个输入,如果是第一个节点,输入只能从cell的输入中选。如果不是,输入可以从前面的节点的输出里选。连接之后需要选择操作,候选包括:不做任何操作、pooling及可分离卷积。之后把Input1和Input2的结果相加,相加的结果就是该节点的输出,同时可以作为下个节点的输入。一个cell里的输出并不每个输出都会被后面的节点选择,对于这种情况,作者将这些节点的输出全部加到最后一个节点。
作者将搜索空间和搜索算法分离,实现自由组合,为了证明只要搜索空间设定的好,复杂的搜索策略并不一定能提高性能。
3.子模型训练策略
这个方法主要为了解决NAS训练非常耗时的问题。他给使用者提供了两种子模型训练策略:1完全训练:确保每个子模型都训练到足够多的epoch。2.部分训练:每个子模型只训练较少的epoch,之后根据当前表现较好的模型补完训练,表现差的就直接丢弃,节省时间。
实验部分
记录一下作者对数据的预处理部分:
1.先去除传输层安全协议(TLS)或快速UDP互联网连接协议(QUIC)头部之外的数据包有效载荷。随后根据数据包的五元组将相近的拼成同一个流。
2.若为TLS流,提取前3个TLS头部,TLS中的服务器指示(SNI)能被用做流标记类别,之后对其进行模糊处理,还有对TLS密码套件信息,IP地址都进行掩码处理。若为QUIC流,仅提取第一个ClientHello数据包,也对SNI头部进行类别标记,之后对其SNI头部及TLS密码套件信息头部进行模糊处理。
3.为了快速提取类别坐标,作者还通过访问每个服务类别的热门网站,从其域名中提取正则表达式,构建查找表。将SNI值与查找表中的正则表达式匹配,从而为流分配类别标签。

















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









