



 本文详细阐述了传输层的服务和协议,包括TCP和UDP的工作原理,端口的作用,TCP连接的建立与复用,以及TCP的可靠传输机制如慢开始、拥塞控制和流控制。重点讲解了TCP的特点、报文段结构、RDT协议和RTT管理,同时涵盖了TCP连接管理和拥塞控制算法如快速重传和RED。
本文详细阐述了传输层的服务和协议,包括TCP和UDP的工作原理,端口的作用,TCP连接的建立与复用,以及TCP的可靠传输机制如慢开始、拥塞控制和流控制。重点讲解了TCP的特点、报文段结构、RDT协议和RTT管理,同时涵盖了TCP连接管理和拥塞控制算法如快速重传和RED。
四、传输层
1.传输层服务
1.服务和协议
服务和协议的目的是让不同主机之间应用进程之间的逻辑通信。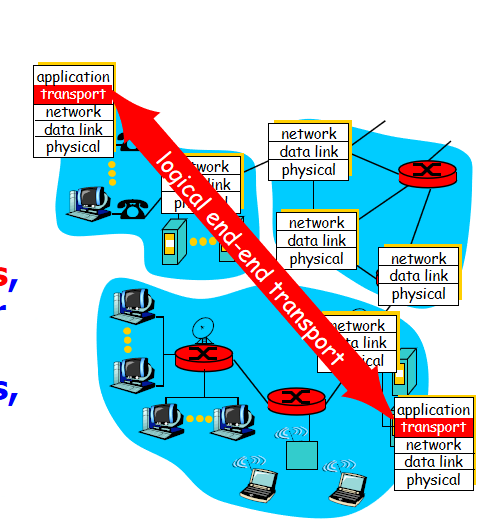
传输协议:TCP、UDP(运行于终端系统),可能使用多个协议。
发送端:应用层报文划分成分段(分解),向下交互给网络层
接收端:重组成报文,向上交付给应用层。
2.通信
运输层向它上面的应用层提供通信服务,它属于面向通信部分的最高层,同时也是用户功能中的最低层。
边缘部分主机使用核心部分时,只会用到TCP/IP下三层。
运输层为相互通信的应用进程提供了逻辑通信。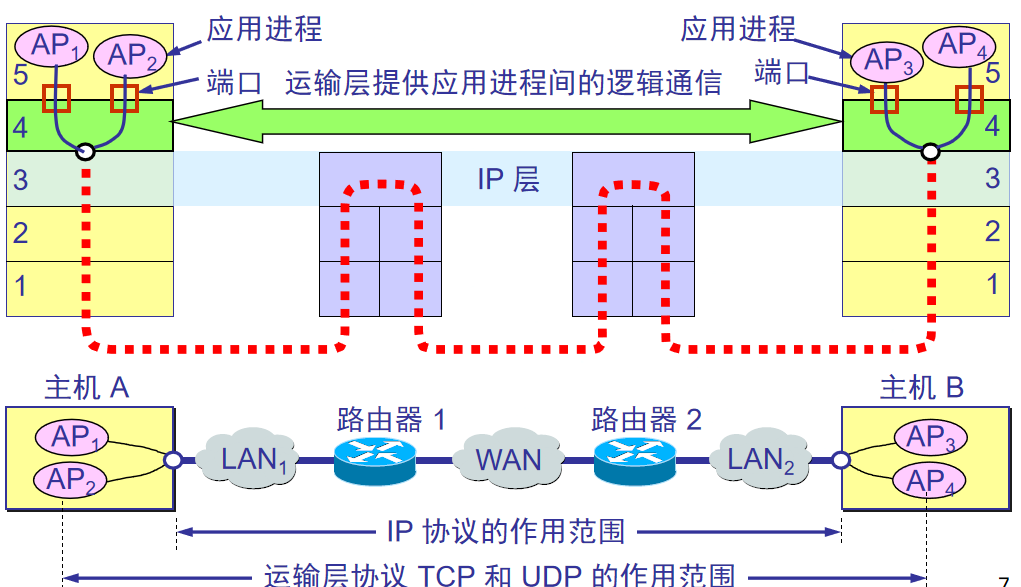
进程之间的通信:端到端的通信
传输层可以将一些信息组合到一块,发送方(复用),接收方(分用)
IP:主机接口到接口之间通信
传输层:端口到端口
传输层还要实现差错检测
3.TCP、UDP
协议:面向连接的TCP(传输控制协议),面向无连接的UDP(用户数据报协议)
TCP:可靠的、按序的交付(先发先到)、拥塞控制、流控制、连接的建立和拆除,对收到的报文进行确认(增加通信开销),三次握手(发送请求,回复应答,建立),让协议数据单元首部增加很多,全双工信道
UDP:不可靠、失序、不提供额外服务的拓展,收到报文不需要确认,某些情况更有效。
不提供:时延的保证,带宽的保证
TPDU传输协议数据单元:对等实体传输的最小单元,TCP报文段、UDP报文(或用户数据报)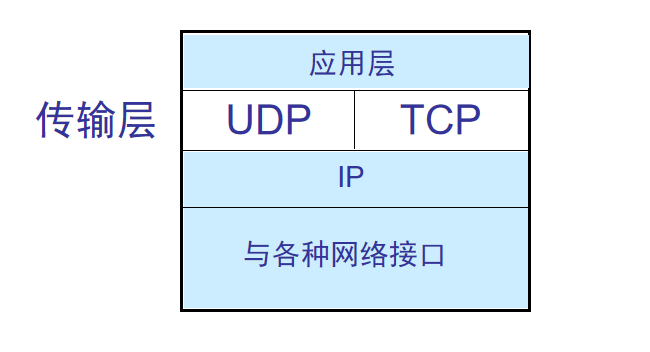
4.端口
进程是通过进程标识符标志(统一方法)。
使用协议端口号(端口port),只需要把报文交给目的主机的合适的端口就行,然后交给TCP
在协议栈层间的抽象的协议端口是软件端口。
路由器或交换机上的端口是硬件端口(接口)。
端口使用16位端口号进行标志,但是端口号只具有本地意义(不同计算机端口号之间没有关系)
三类端口:
a.熟知端口(0~1023):HTTP(80)、FTP(21)端口固定
b.登记端口(1024~49151):必须在IANA登记,避免重复
c.客户端口(短暂端口)(49152~65535):结束后可以供他人使用
5.TCP连接
TCP连接的端点不是主机也不是应用进程也不是传输层的协议端口。
连接的端口叫套接字socket(插口),实际上就是端口号拼接到IP地址后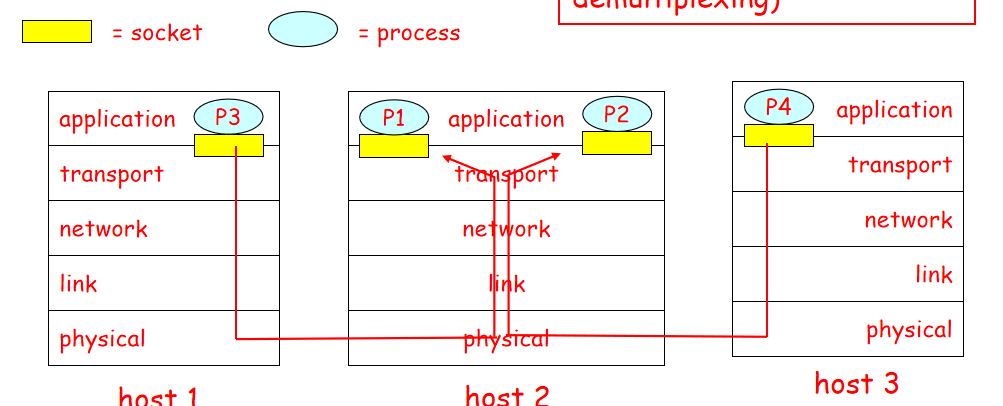
一条TCP连接对应两个套接字
2.复用Multiplexing和分解demultiplexing
主机通过源端口号和目的端口号 直接分配端口,数据部分就是应用层的报文部分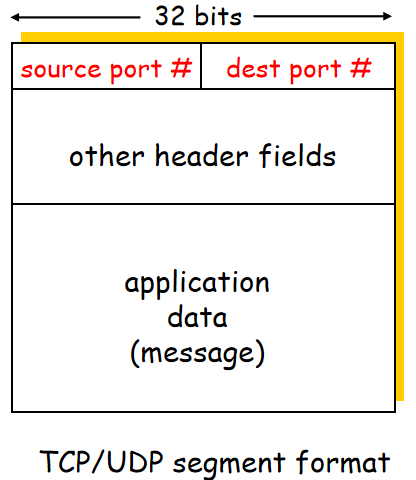
1.UDP套接字
传输层自动为UDP分配端口号,生成具有端口号的套接字,通过二元组(源端口号,目的端口号)标识。
目的主机收到UDP分段,检查目的端口号,直接定向送给端口号对应的socket。
DatagramSocket mySocket1
= new DatagramSocket(12534);
不同源IP和源端口有可能被定向到同样的端口上。(目的位置可能一样)
源地址:方便返回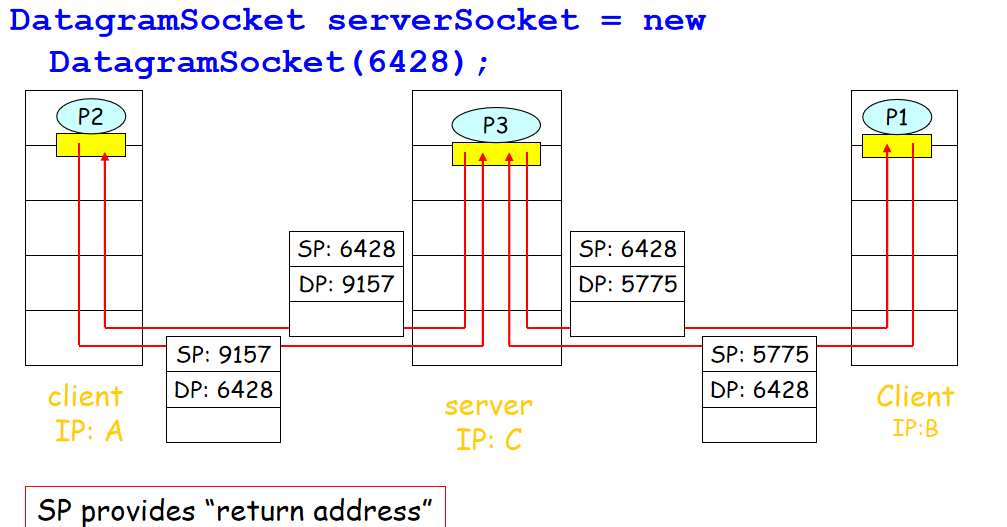
2.面向连接的分解(TCP)
4元组(源IP、源端口号、目的IP、目的端口号)
接收方通过4元组定向到适当的socket。
服务器主机Server host支持并行的套接字(都由4元组进行标识)。
Web服务器有不同的套接字(为客户提供的)
非持久的HTTP可以为每一个请求提供单独的套接字来区分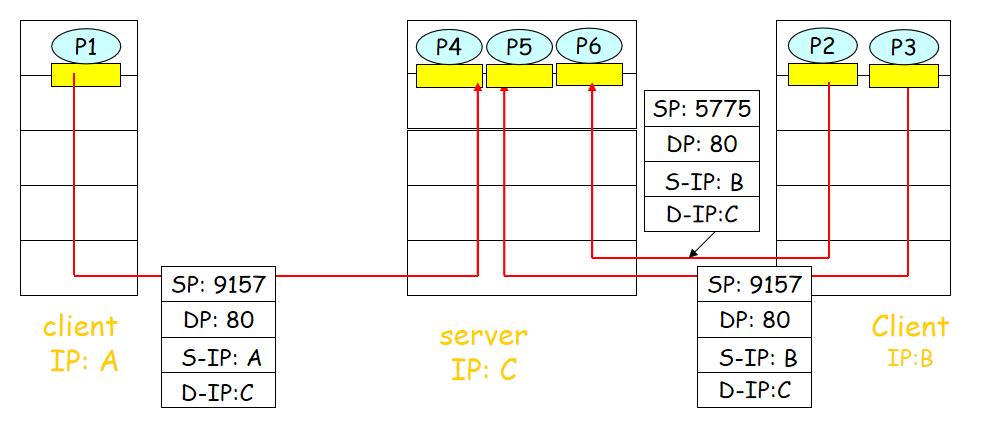
多线程Web服务器: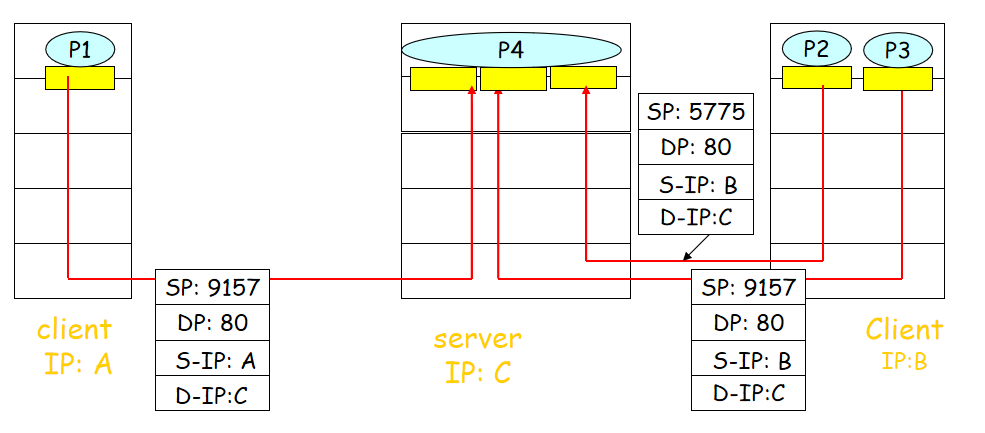
中间的一个进程对应3(多)个套接字,为每一个新的客户创建套接字,是一个轻量级的子线程。
3.UDP
UDP分段可能丢失,说不准谁先到
面向无连接(发送端和接收端没有握手handshaking(建立连接)),每个UDP分段是单独处理的。
用于流媒体(可容忍报文丢失、速率敏感)
应用:DNS、SNMP
实际上可以实现可靠数据传输(应用层可靠性方案限制:特定的确认重传机制、差错恢复机制)
格式: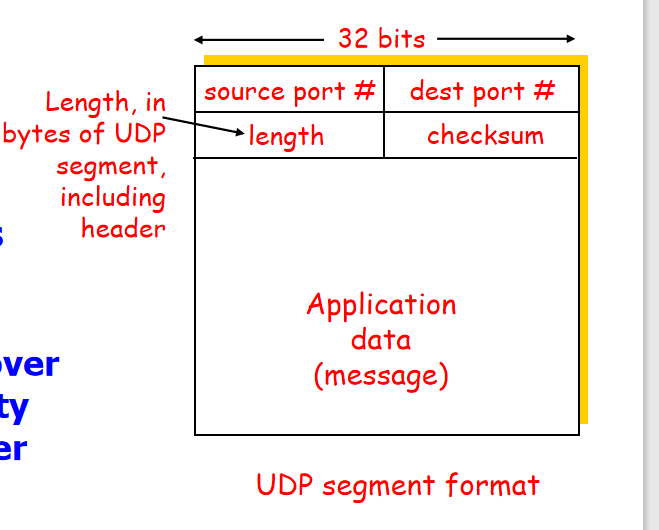
发送方UDP:添加收到报文的首部8字节,然后向下交付,不做处理。
接收方:网络层拿到UDP,直接去掉报头,向上一次性交付完整报文
所以应用层要给传输层发送合适大小报文
首部格式: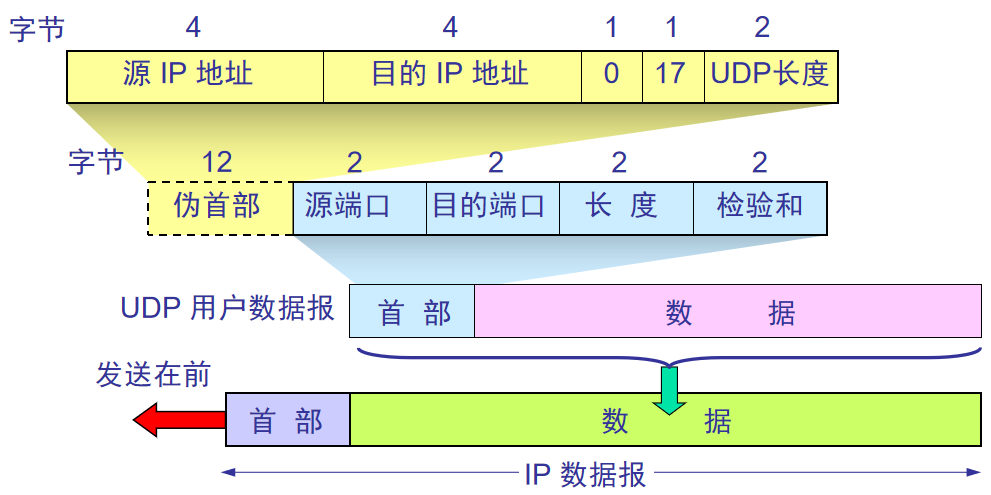
伪首部是计算校验和的临时内容,其他层都不会收到
UDP分用: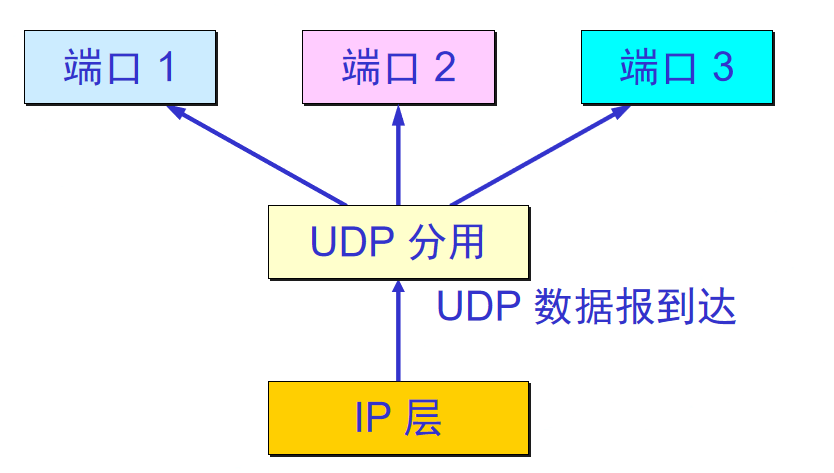
2.UDP校验和
找到传输分段里的错误
发送方:分段看成16bit的整数序列,计算反码和,结果放到字段中。
接收方:重新计算校验和,进行比较,相等就认为没错。
例子: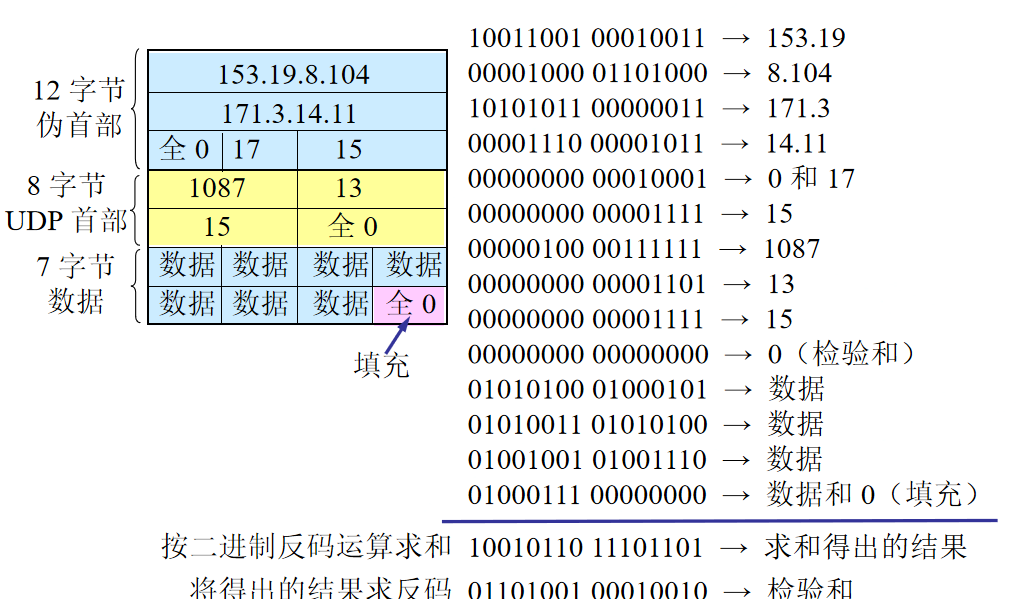
特殊情况:
最高位进位加到最后一位上
4.TCP特点
面向连接的传输层协议,只能有两个端点(点对点),可靠交付的服务,面向字节流
面向流: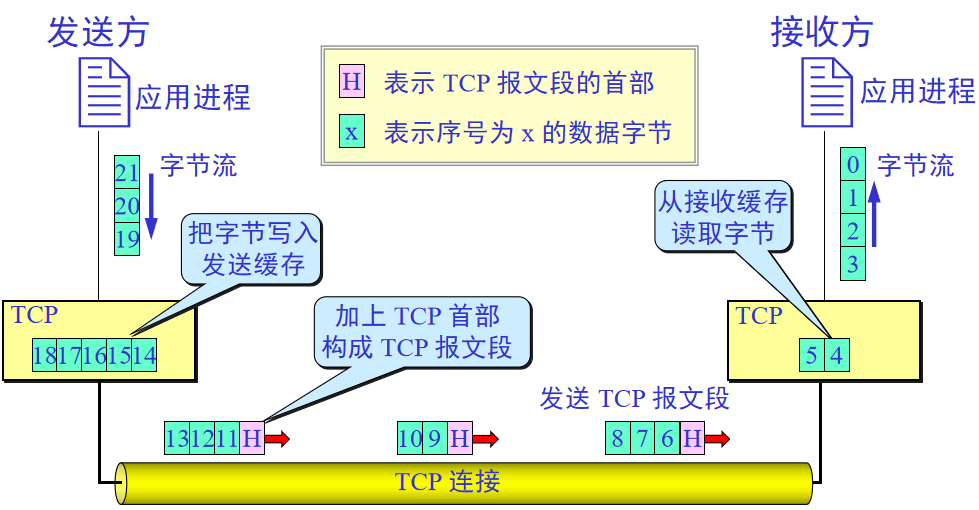
TCP连接是虚拟连接,对于TCP选择多少字节进行发送根据接收端性能,接收方给出窗口值(接收能力),UDP是应用进程限制大小,TCP可以将数据块分成短一点的或积累到足够字节再发送
TCP连接的是套接字
5.rdt
rdt协议:可靠数据传输协议
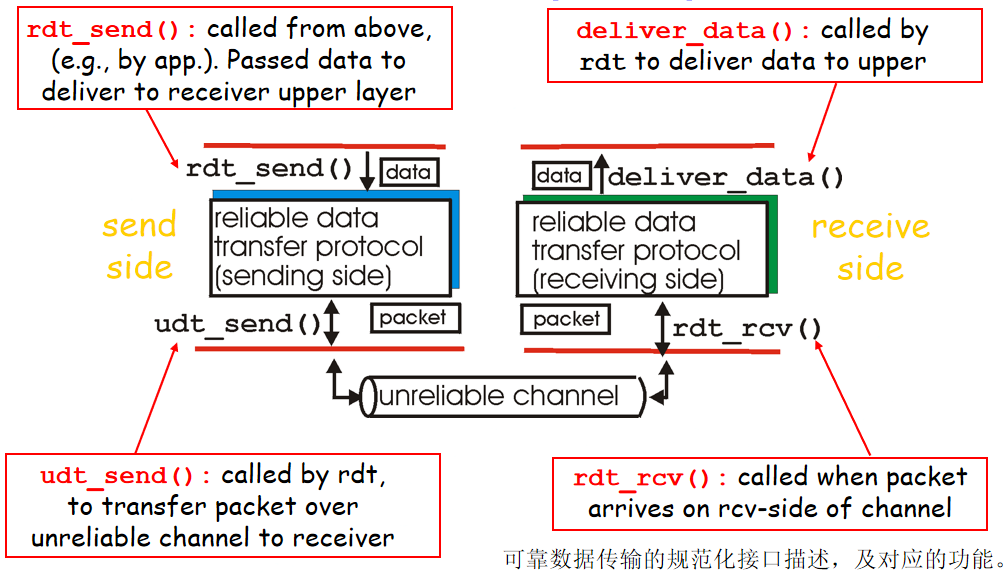
发送方调用的函数rdt_send:调用数据传输协议,交给接收方的应用进程
udt_send传输端报文发送到不可靠信道中传输给接收方
rdt_rcv:数据报到通道接收端
deliver_data:rdt将数据传送到上层(应用层)
使用FSM有限状态机描述发送、接收方状态(下一个状态由下一个事件确定)
rdt1.0:没有比特翻转、丢包。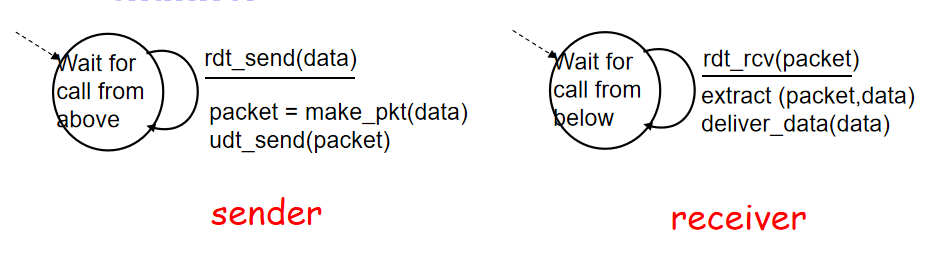
rdt2.0:可能比特翻转。
底层信道可能导致比特翻转,通过校验和检测比特错误。
错误的恢复:ACK肯定确认:发送方发送后,接收方要明确告诉发送方一致、NAK否定确认:收到出错
收到ACK后就继续发,否则重传
增加的机制:差错检测、接收方的反馈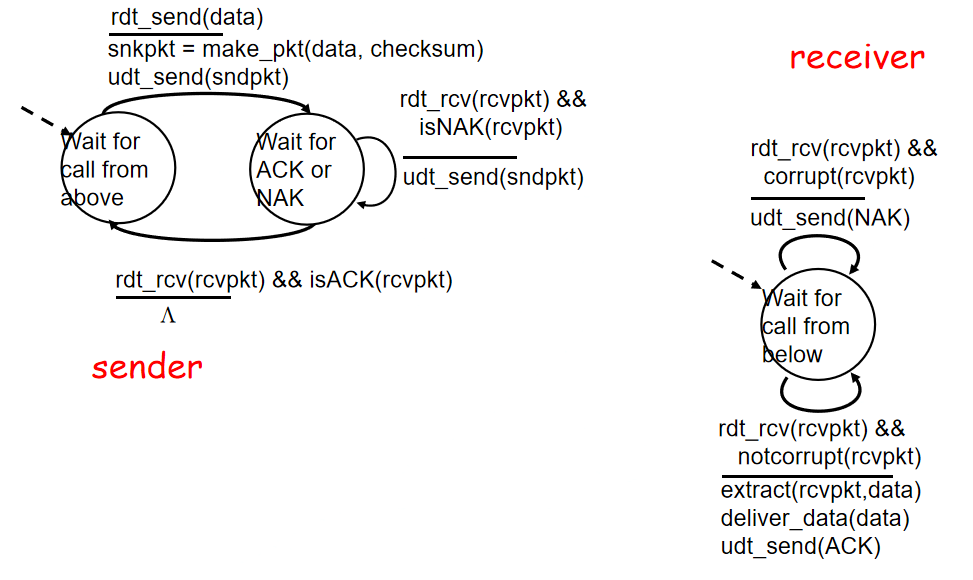
处理重复:出现混乱(不知道对应的确认是谁的),发送方要重传当前分组(分组里加序号),接收方直接忽略重复的分组
rdt2.1(了解):
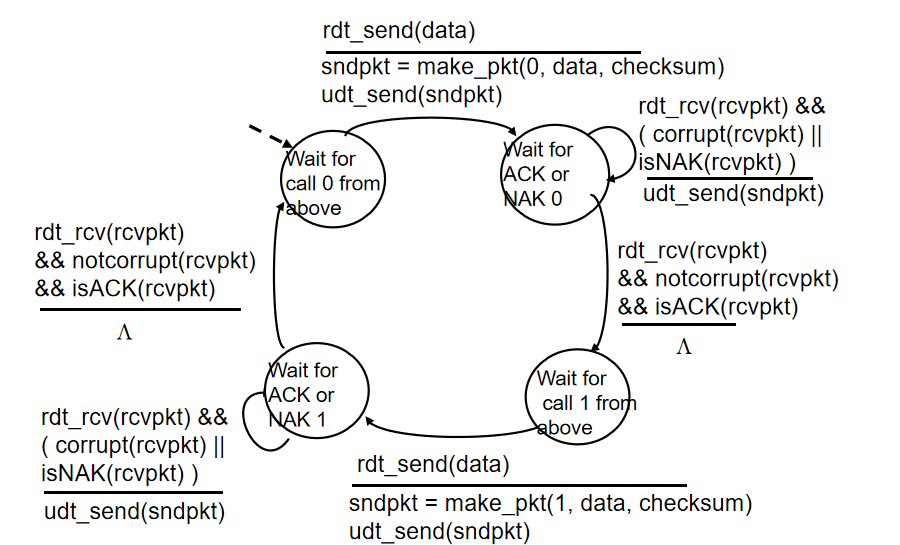
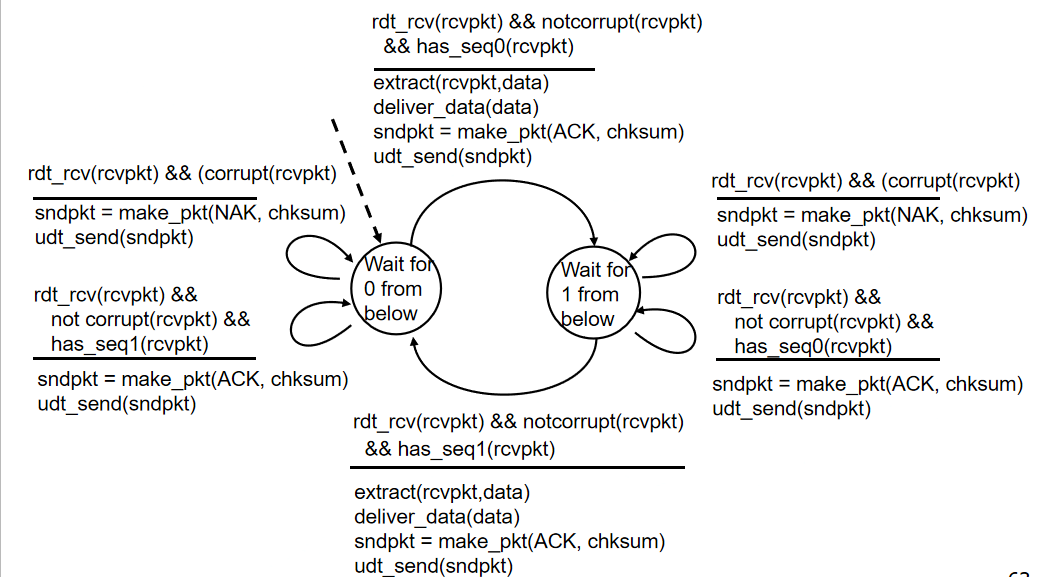
接收端检查是否是重复分组,并不知道最后一个确认被收到
rdt2.2:没有否定确认,只使用肯定确认
最后一个成功收到分组进行肯定确认,明确分组序号
发送端收到重复确认会重发分组
rdt3.0:允许比特错误和丢包
假设底层信道(一般信道)有丢失,发送方等待合理的时间,时间到了没收到确认才会实现重传(序号处理),接收端必须指明确认分组的序号,需要用倒计时的计时器来进行判定是否重传。
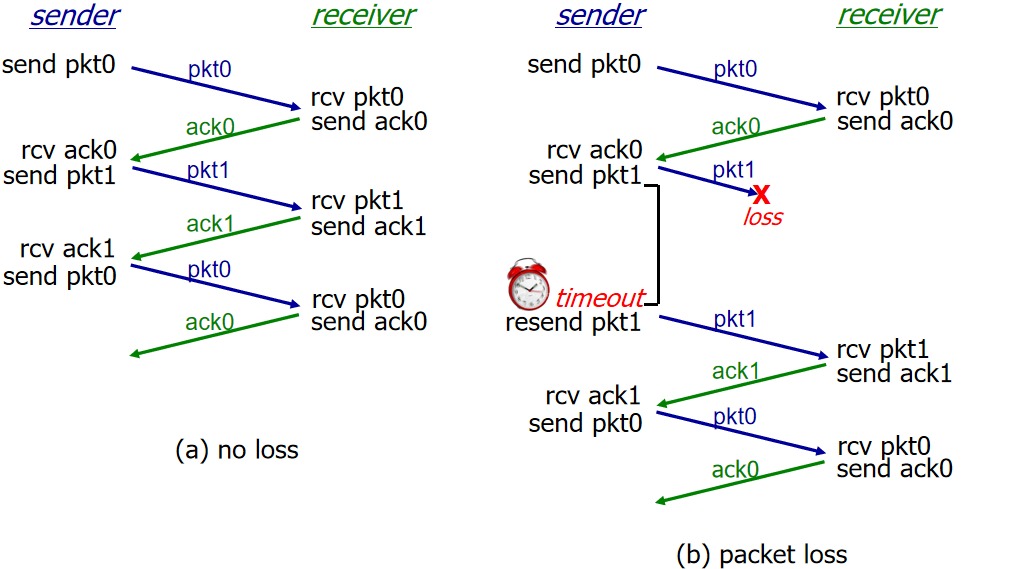
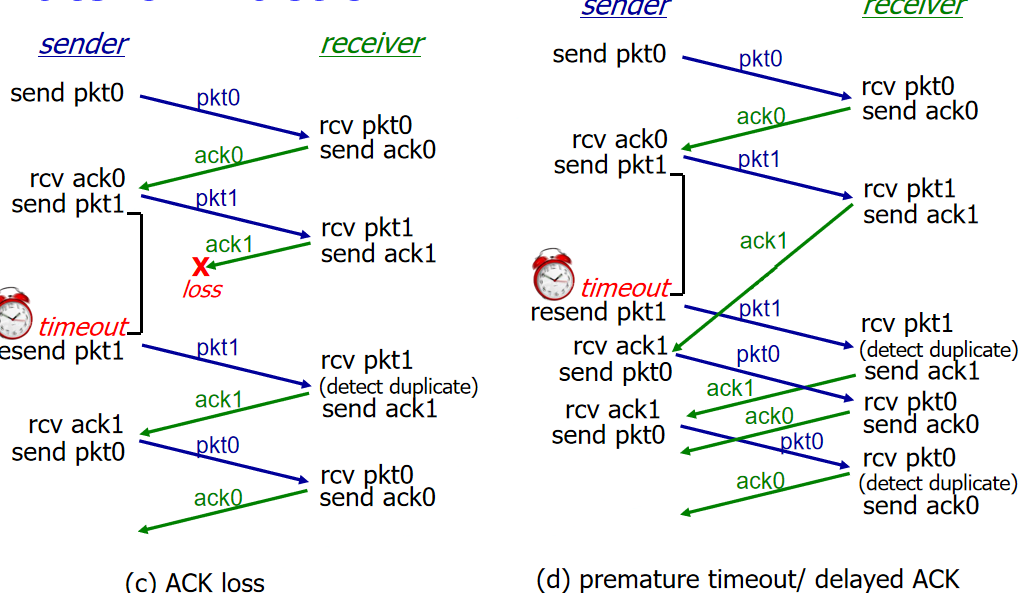
注意:
分组发完后需要进行保留(用于重传)、分组和确认需要编号、计时器时间需要长于往返时间
自动重传请求ARQ:重传是自动进行的,接收方不需要请求重传错误分组,但是信道利用率很低
流水线传输:连续发很多分组
连续的ARQ协议:
累计确认(接收方):对按序到达的最后一个分组发送确认(之前的所有都正确收到了)
Go-back-N:退回来重传已发送过的 N 个分组
TCP的具体实现:每一端都必须设有两个窗口(发送窗口、接收窗口),通过字节的序号进行控制,四个窗口是动态变化的,往返时间RTT不是固定的(特定算法估算)
6.TCP结构、可靠传输
1.概述
点到点连接,可靠按序的字节流(没有报文边界),流水线pipeline(设置窗口大小进行拥塞和流量控制),发送接收方都要有缓存,全双工通信,MSS最大报文长度(最大链路层帧长度决定MTU),面向连接(握手),流控制(不能发送太快)
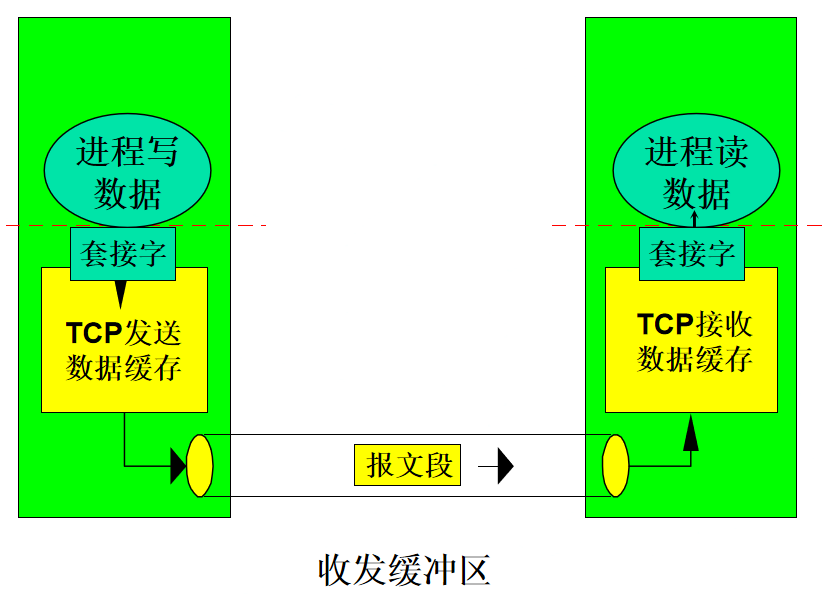
2.报文段结构
sequence number:序号字段(每个字节都要有编号),当前报文段数据里第一个字节的序号
acknowledge number:确认字段,期望收到对方的下一个报文段数据部分的第一个字节的序号
head len:4bit,头部长度(数据偏移),TCP报文段起始位置,4个字节为一个单位
保留位:6个0
URG:紧急字段,为1时,表示紧急指针字段有效(优先级高的数据)
ACK:ACK=1时确认号字段有效
PSH:尽快交付接收应用进程,不等缓存满
RST:复位,TCP连接严重错误,释放连接,然后再重新建立
SYN:表示这是一个连接请求或连接接受报文
FIN:释放连接(数据发送完毕)
窗口:设置发送窗口的大小
校验和:伪首部、首部、数据都要算
紧急指针:紧急数据有多少字节
选项字段:告诉对方TCP最大缓存是MSS个字节
其他选项:窗口扩大选项:3字节,一个字节表示移位S,窗口增大(16+S)
时间戳选项:占10 字节,其中最主要的字段时间戳值字段(4 字节)和时间戳回送回答字段(4 字节)
选择确认选项
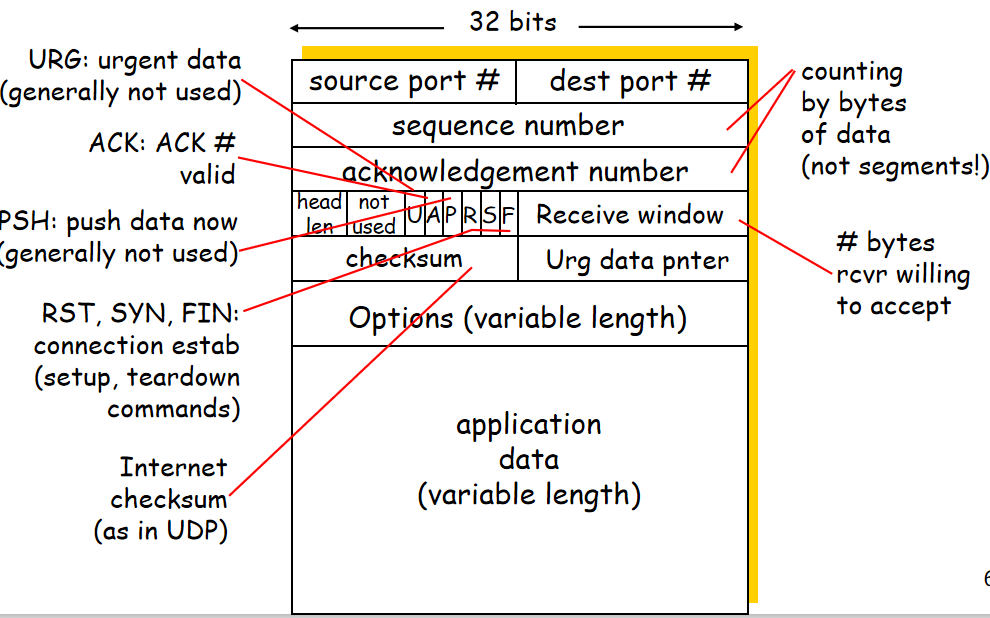
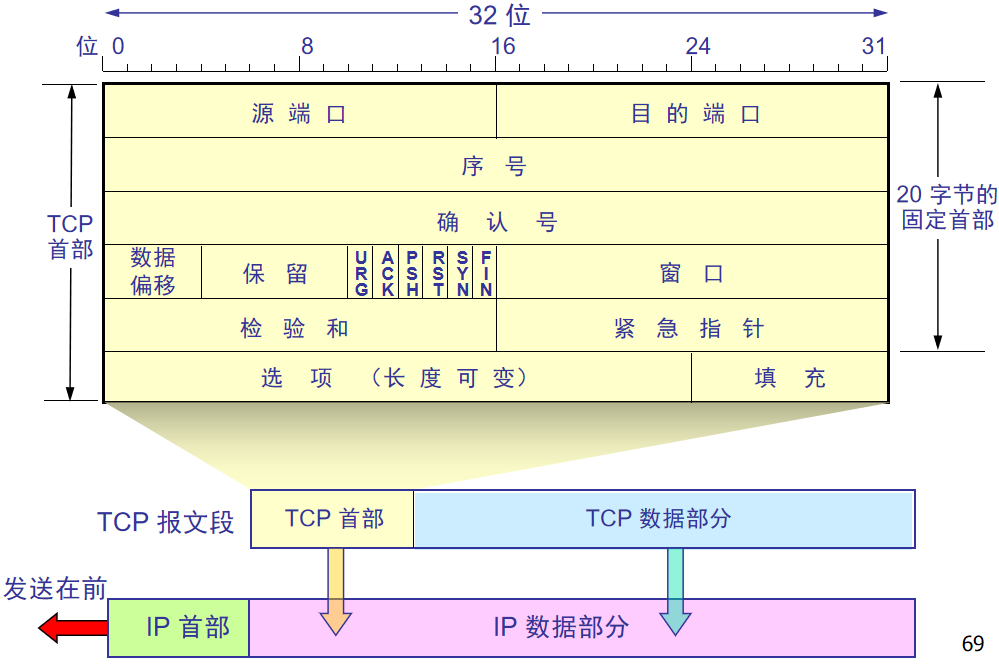
3.可靠传输
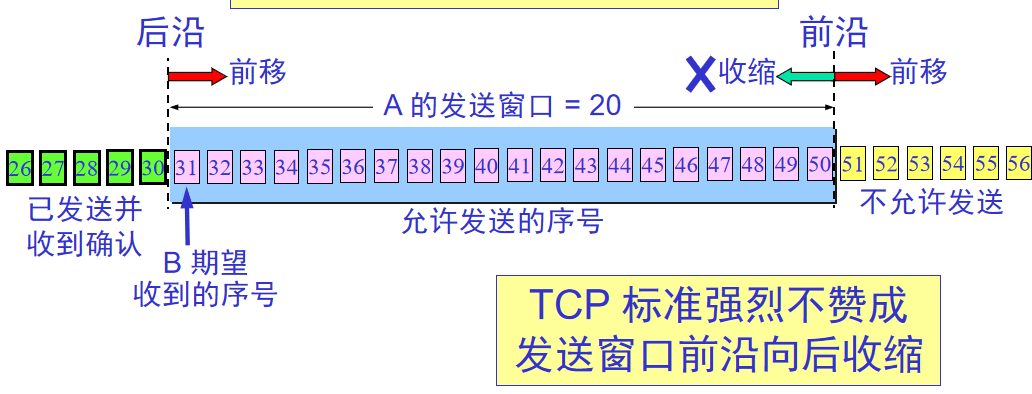
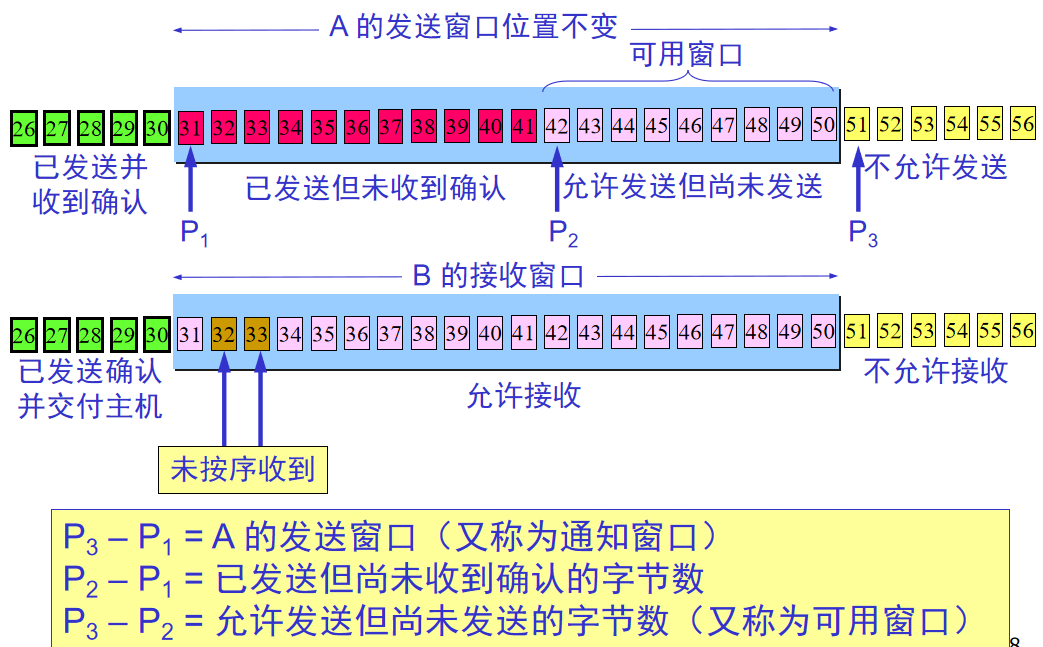
发送缓存: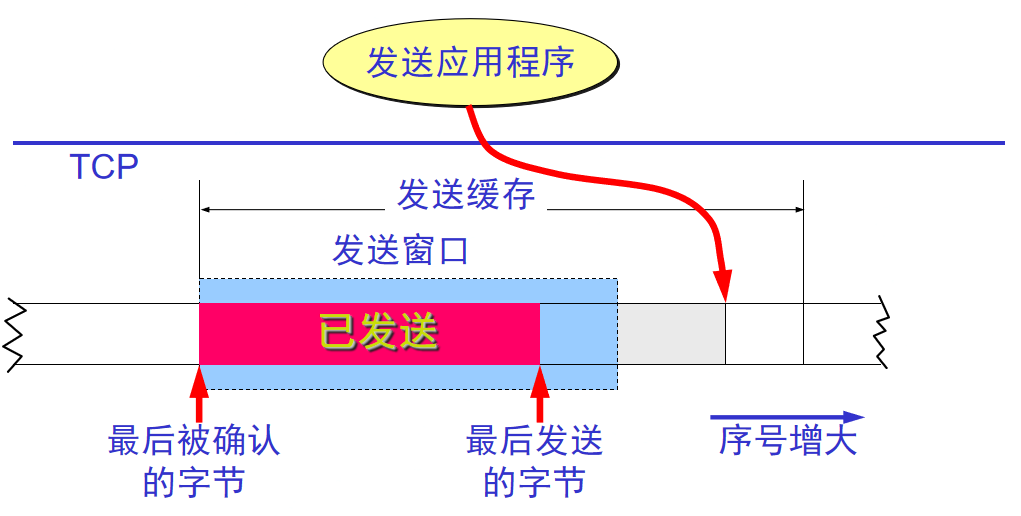
接收缓存: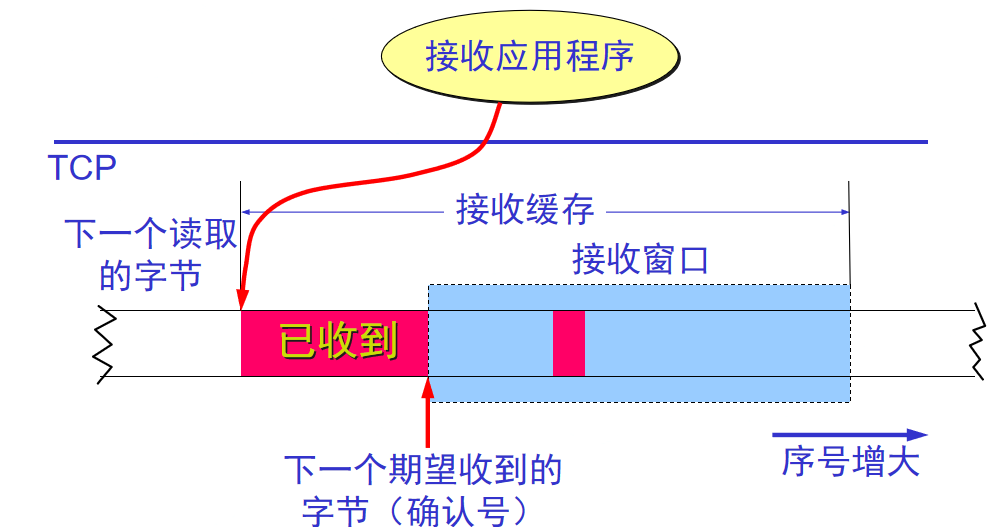
发送方窗口不一定和接收窗口一样大
不按时到达的数据会临时存放在接收窗口中,收到后在按序交付
接收方必须具有累计确认功能(减少开销)
重传:每发一个报文段,倒计时RTT,时间到没收到就重传
7.往返时延
由于 TCP 的下层是一个互联网环境,IP 数据报所选择的路由变化很大。因而运输层的往返时间的方差也很大。
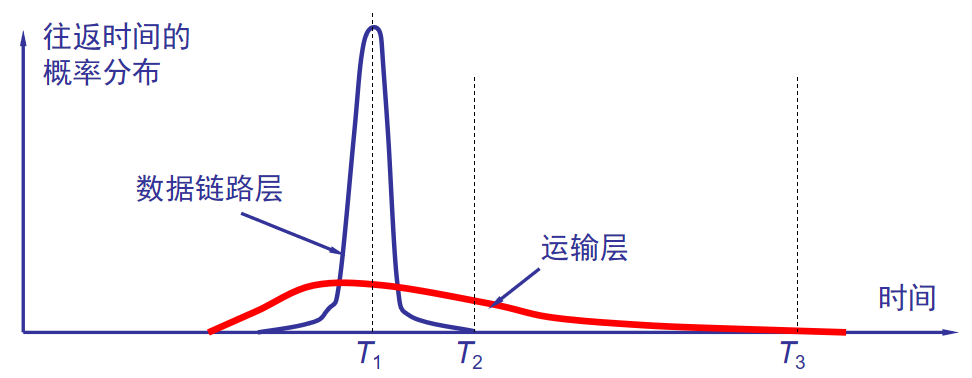
1.加权平均往返时间
RTTs是平滑的往返时间
计算公式:
第一次测量就直接将RTTs取为RTT
a接近于0,RTT值更新的比较慢。接近于1,RTT值更新快
推荐a值为1/8
2.超时重传时间RTO
一般要大于RTTs。
RTO=RTTS + 4*RTTD (偏差加权平均值)

RTTD第一次取RTT的一半,推荐值是1/4
3.RTT测量
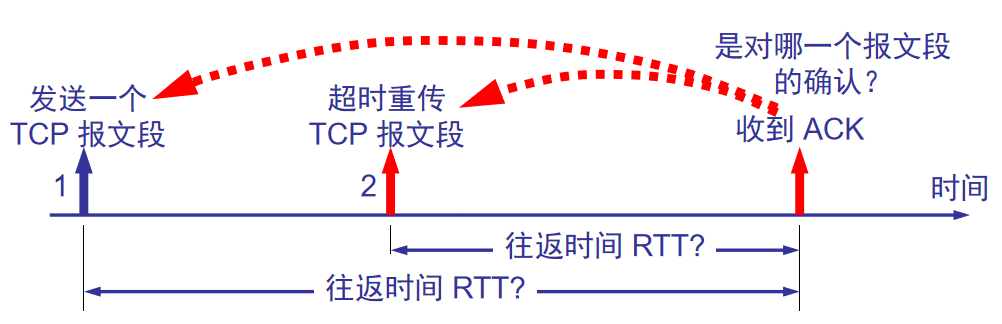
4.Karn算法
计算RTT时,只要发生重传就不采用之前的。
修正:报文段重传,就把RTO增大一点
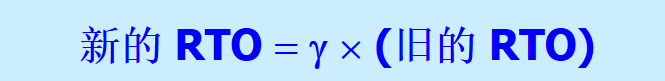
r一般取2
直到不进行重传才更新RTT和RTO
5.选择确认SACK
接收方接收不连续的两个字节,如果都在接收窗口之内,就先收下数据,然后告诉发送方不用发这些重复的。
例:
和前后字节不连续的每一个字节块都有两个边界:左边界L和右边界R
左边界指出字节块的第一个字节的序号,但右边界减1才是字节块中的最后一个序号。
6.RFC 2018的规定
如果要使用选择确认,那么在建立 TCP 连接时,就要在 TCP 首部的选项中加上“允许 SACK”的选项,而双方必须都事先商定好。
如果使用选择确认,那么原来首部中的“确认号字段”的用法仍然不变。只是以后在 TCP 报文段的首部中都增加了 SACK 选项,以便报告收到的不连续的字节块的边界。
由于首部选项的长度最多只有 40 字节,而指明一个边界就要用掉 4 字节,因此在选项中最多只能指明 4 个字节块的边界信息。
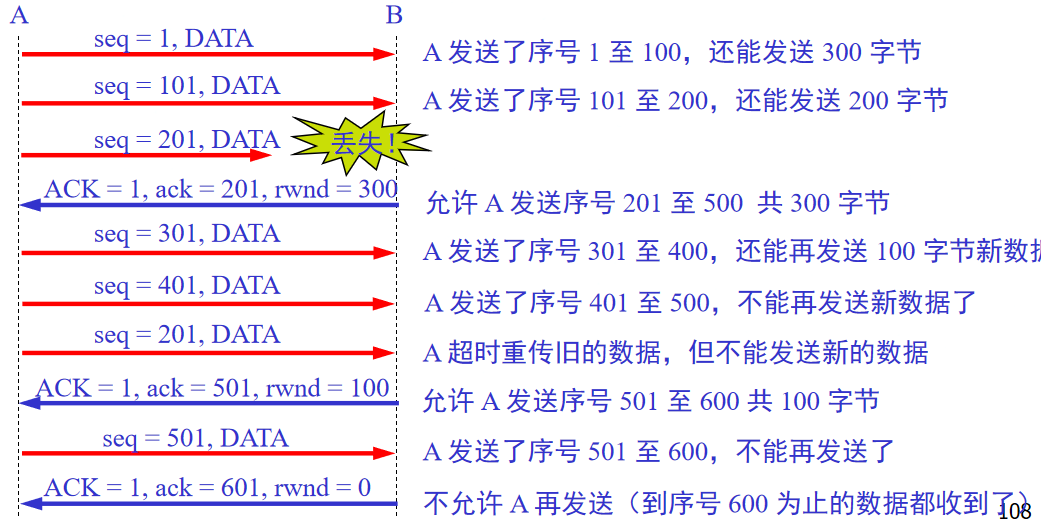
8.TCP流控制
接收端会有接收缓存(TCP数据(网络层获取的数据)和空余),应用进程从缓存里读取数据。
速度匹配服务speed-matching service:发送速率和接收方应用处理速度相匹配。
1.工作方式:
忽略失序分段,接收方告诉发送方能容纳多少数据,发送方决定接下来的发送量,发送方通过发送窗口大小和没确定数据的大小进行控制。
rwnd限制的是发送方的发送窗口
2.持续计时器persistence timer
死锁情况:启动发送方窗口丢失,接收方一直等待,发送方页一直等待
每个连接都要设置一个持续计时器。
TCP一方收到零窗口(rwnd=0)通知就启动计时器。
设置的时间到期,发送方就发送一个零窗口的探测报文,查看当前窗口是否需要修改。
如果接收的窗口仍是0,重置计时器。
3.发送时机
1.TCP维持变量(等于最大报文长度MSS),达到MSS就打包发出
2.发送方应用进程指明发送时机(TCP支持推送push操作)
3.发送方计时器到期就将缓存总数据发出(不能超过MSS)
9.拥塞控制
1.拥塞
拥塞的表现:1.分组丢失(路由器缓存溢出)2.网络延时变长
假设路由器无限缓存(不需要重传),拥塞后就会出现时延。C:链路容量
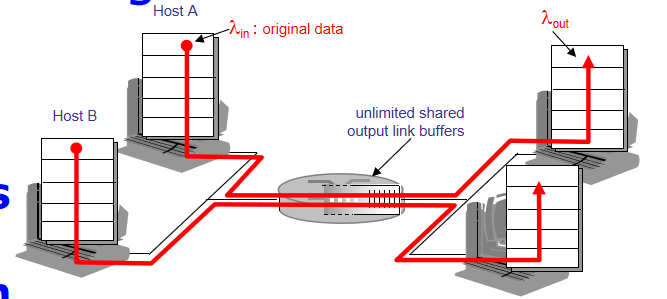
有限缓存 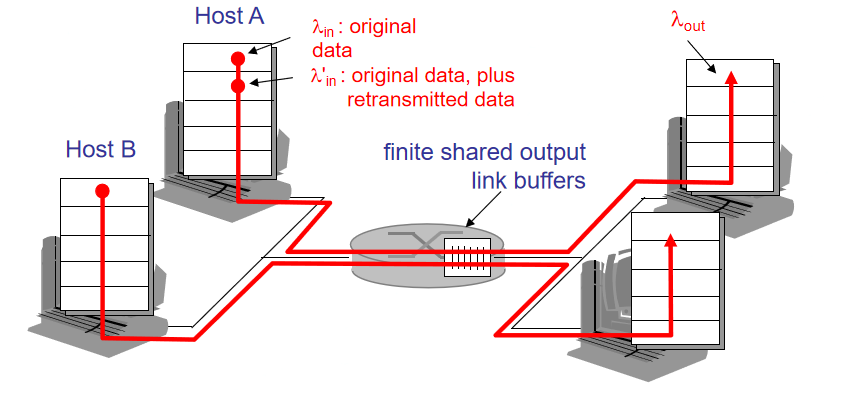
出现拥塞:资源需求总和>网络提供服务
2.与流量控制的关系
拥塞控制:网络能承受现有负荷的前提,是全局性的过程,涉及所有主机、路由器。
流量控制:发送端和接收端点对点通信量控制,通过抑制发送端速率。
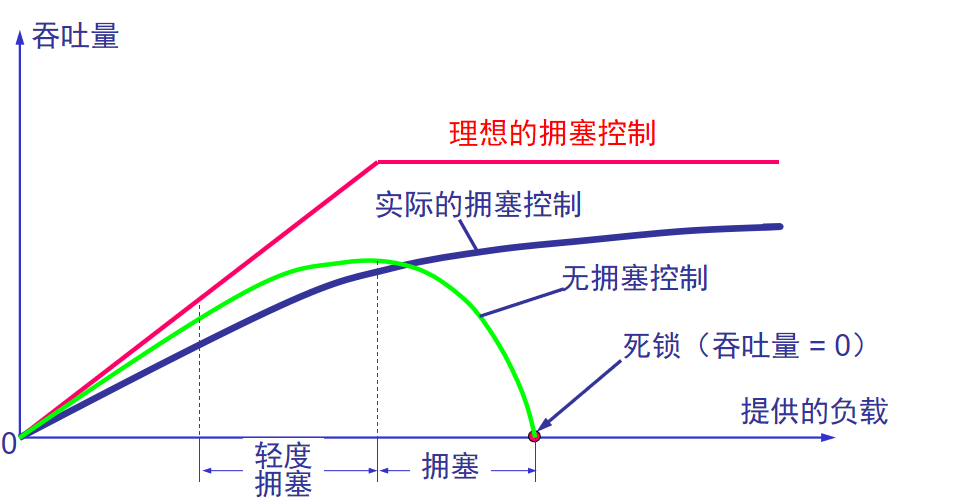
3.控制
分组的丢失是网络发生拥塞的征兆而不是原因。可能拥塞控制本身的报文会加剧拥塞。
开环控制:实现考虑清楚拥塞原因。(预防)
闭环控制:根据出现的情况解决。措施:检测网络系统(尽快找到出现位置)、将发生拥塞的信息传送到可控制的地方、调整网络运行。
4.控制方法
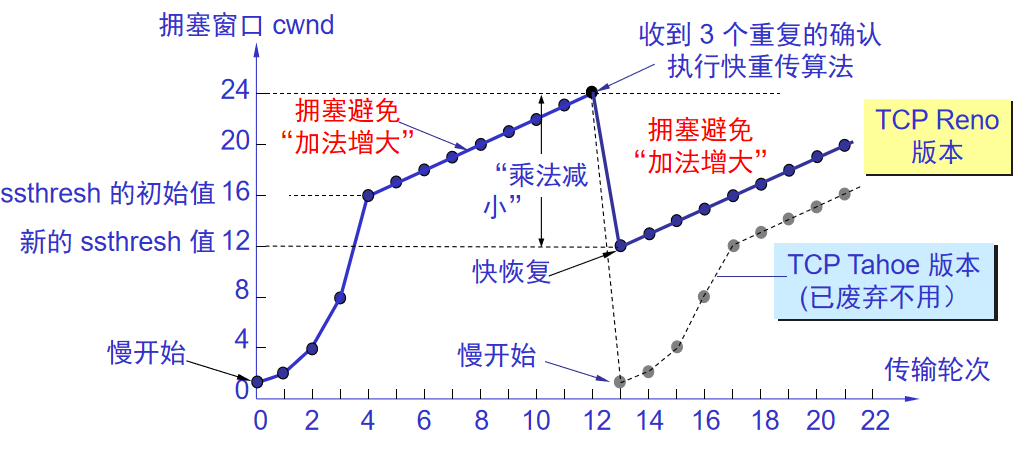
1.慢开始和拥塞避免
拥塞窗口:发送方来维持的状态变量。大小取决于当前拥塞情况(动态变化)。发送窗口=拥塞窗口大小。考虑流控制就要小于拥塞窗口( = min(拥塞窗口,接收窗口))。
控制拥塞窗口原则:没拥塞就增大(发送更多分组),出现就减少。
a.慢开始算法
设置拥塞窗口为cwnd = 1(=MSS)
收到新报文确认后,就将拥塞窗口+1,逐步增加
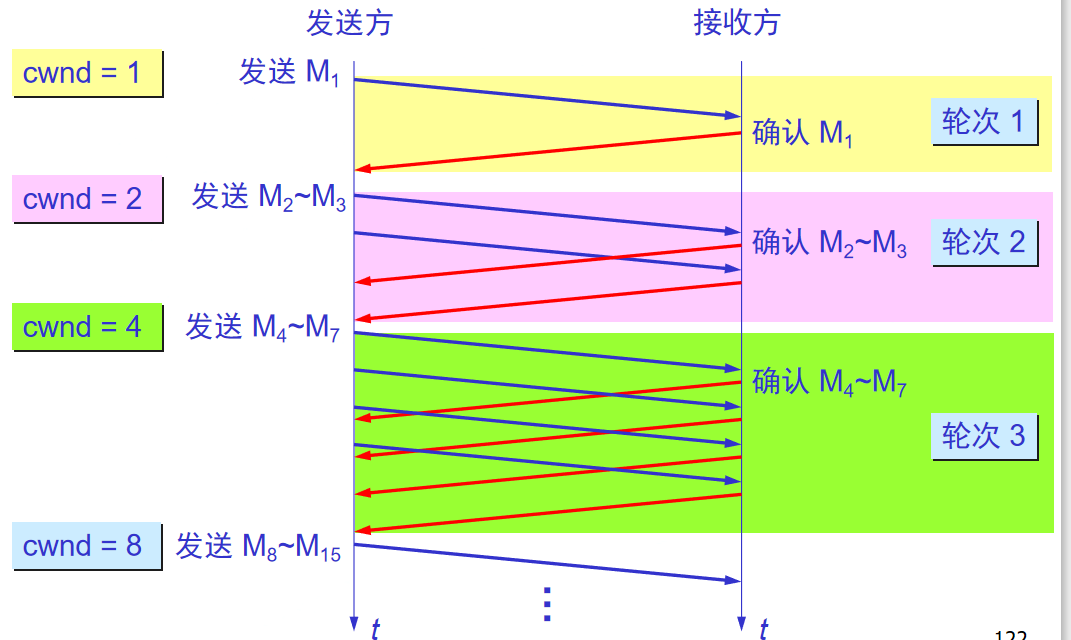
每经过一个传输轮次cwnd加倍。
一个传输轮次所经历的时间就是RTT。
传输轮次就是把允许的报文全发出去,到接收到最后一个报文确认
慢开始门限状态变量ssthresh:避免过大
小于就使用慢开始算法,大于就使用拥塞避免算法,等于都能使用。
b.拥塞避免算法
让拥塞窗口缓慢增大,经过一个RTT每次+1而不是加倍。
2.发生拥塞
如果出现拥塞(没按时收到确认)就将慢开始门限值设为发送窗口一半。cwnd = 1。
目的是减少网络中的分组数。
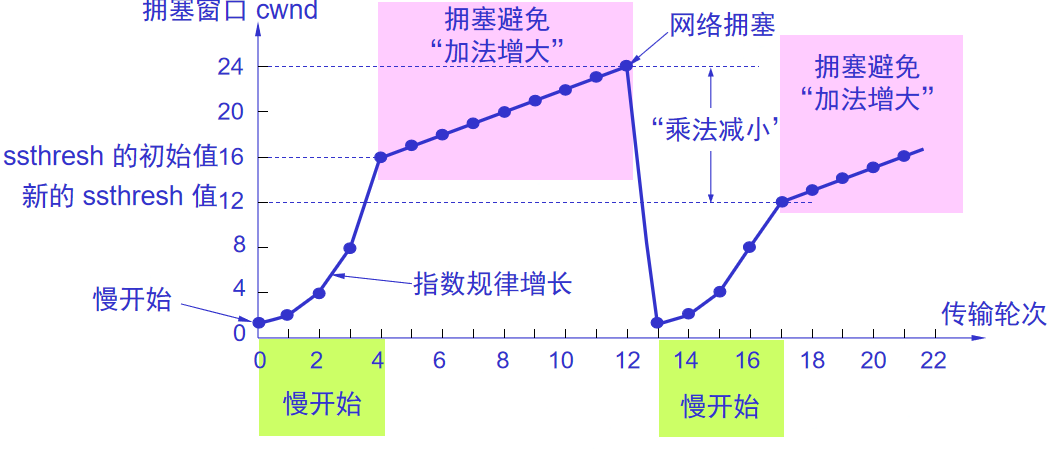
乘法减少:无论在什么阶段,只要出现超时(拥塞),门限值都减半。
加法增大:每次+1
3.快重传和快恢复
快重传算法:每收到一个失序的报文段,立即发出重复确认,让发送方知道有报文段没到。
发送方连收三个重传确认就重发(计时器到时也要发)
例:
快恢复算法:连续收到三个重传确认就执行乘法减少。但接下来不执行慢开始。由于发送方认为不一定拥塞,所以cwnd设置为门限减半后的数值,然后加法增大
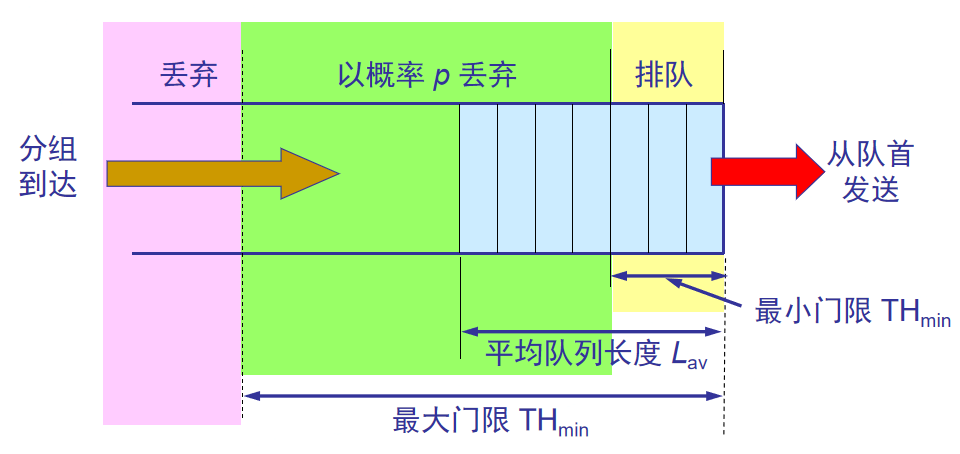
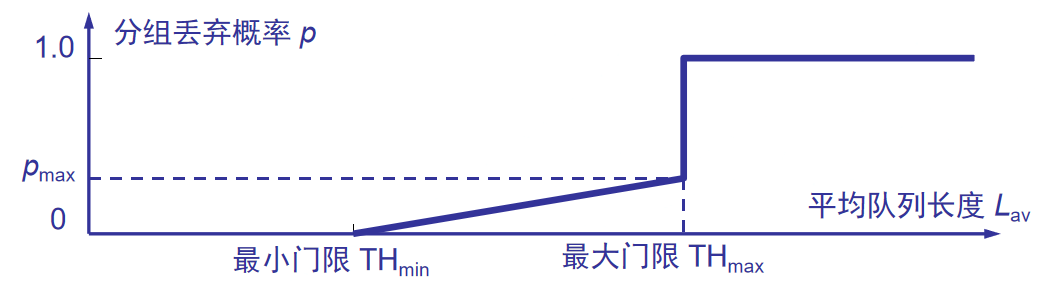
5.随机早期检测RED
使路由器的队列维持两个参数,即队列长度最小门限 THmin 和最大门限 THmax。
RED 对每一个到达的数据报都先计算平均队列长度 LAV。
若平均队列长度小于最小门限 THmin(数据报少),则将新到达的数据报放入队列进行排队。
若平均队列长度超过最大门限 THmax,则将新到达的数据报丢弃。
若平均队列长度在最小门限 THmin 和最大门限THmax 之间,则按照某一概率 p 将新到达的数据报丢弃。
10.TCP连接管理
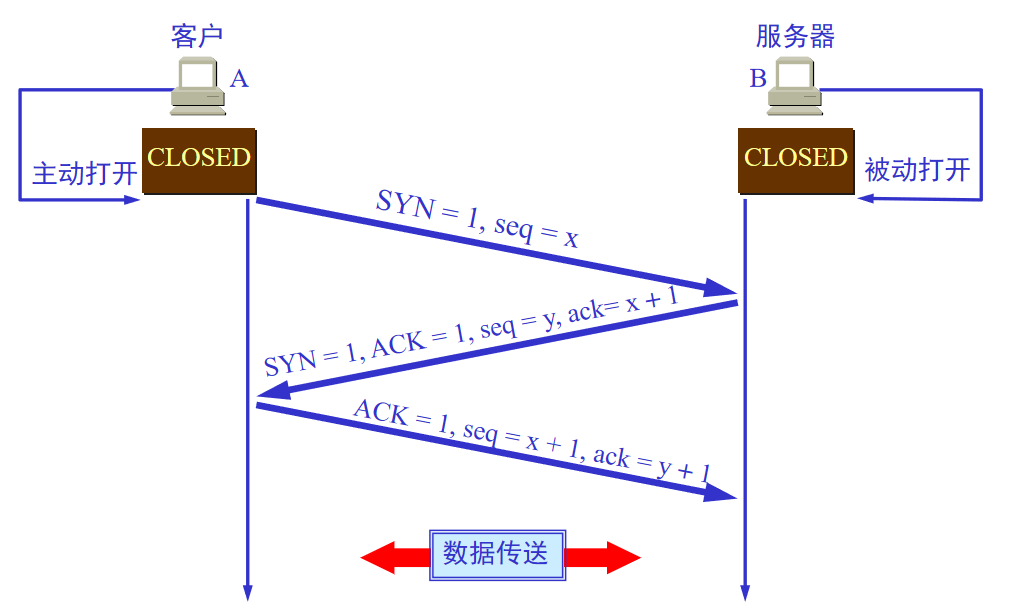
1.建立
三次握手:1.客户端向服务器发送SYN请求(初始化一个序号)2.服务器返回一个SYNACK(确认)3.传数据
seq=x:传输数据第一个字节的序号是x
2.释放
关闭连接:每一端都需要关闭连接,TCP段中有FIN命令
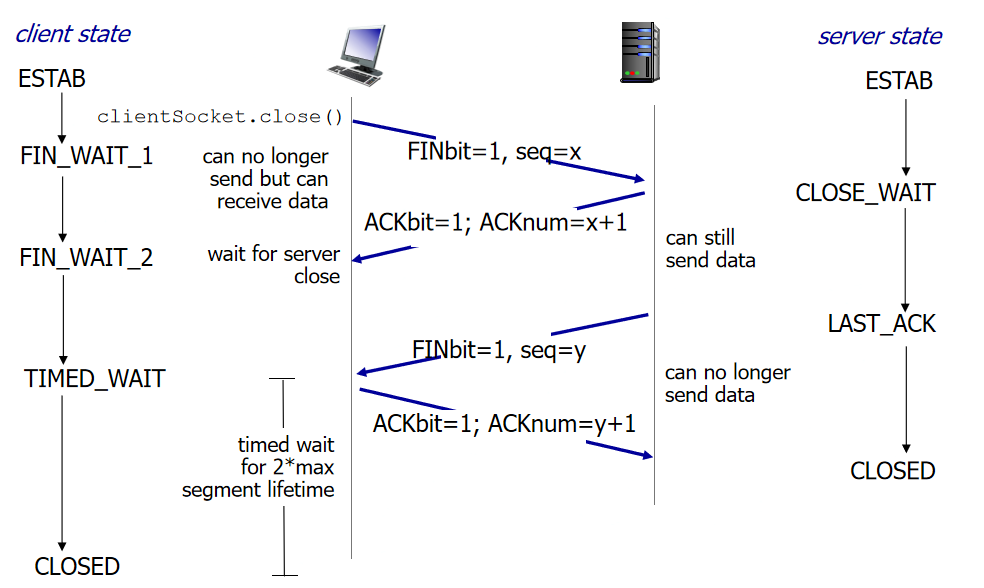
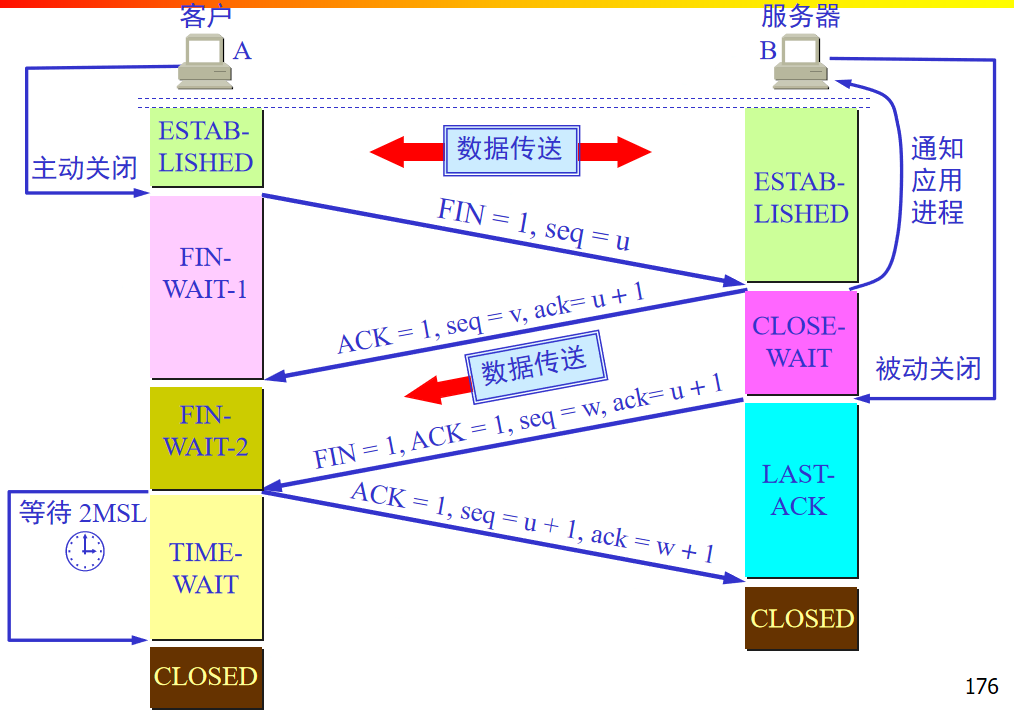
TCP释放必须等待大于等于2MSL时间才能释放掉。
3.传输
传输三个阶段:连接建立(知道对方存在,协商参数(最大报文长度,最大窗口,服务质量),传输实体资源(缓存大小,连接表))、数据传输、连接释放
TCP建立是客户服务器方式,发起连接的应用进程就是客户client,等待连接的是服务器server

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









