




 本文介绍了Canal的基本原理及其应用场景,Canal是一款由阿里巴巴开发的Java中间件,主要用于基于数据库增量日志解析,提供增量数据订阅及消费服务。文中详细阐述了Canal的工作流程,并解释了MySQL的binlog机制。
本文介绍了Canal的基本原理及其应用场景,Canal是一款由阿里巴巴开发的Java中间件,主要用于基于数据库增量日志解析,提供增量数据订阅及消费服务。文中详细阐述了Canal的工作流程,并解释了MySQL的binlog机制。
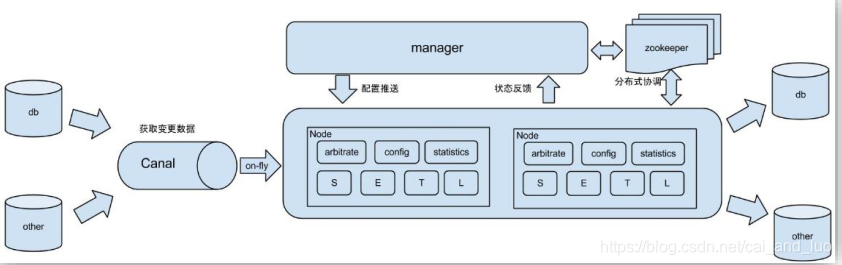
canal原理
1 什么是 canal
阿里巴巴 B2B 公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,
所以衍生出了同步杭州和美国异地机房的需求,从 2010 年开始,阿里系公司开始逐步的尝
试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
canal 是用 java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
目前, canal 主要支持了 MySQL 的 binlog 解析,解析完成后才利用 canal client 来处理
获得的相关数据。(数据库同步需要阿里的 otter 中间件,基于 canal) 。
2 使用场景
(1) 原始场景: 阿里 otter 中间件的一部分
otter 是阿里用于进行异地数据库之间的同步框架, canal 是其中一部分。
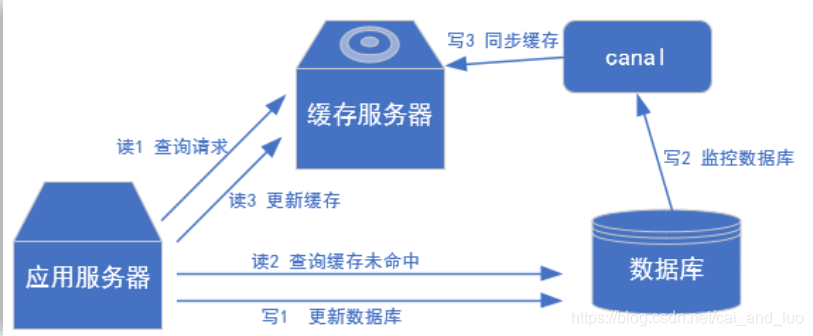
(2) 常见场景1:更新缓存
(3) 常见场景2:抓取业务数据新增变化表,用于制作拉链表。
(4) 常见场景3:抓取业务表的新增变化数据,用于制作实时统计。
3 canal 的工作原理
(1) MySQL 主从复制过程
➢ Master 主库将改变记录,写到二进制日志(binary log)中
➢ Slave 从库向 mysql master 发送 dump 协议,将 master 主库的 binary log
events 拷贝到它的中继日志(relay log
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









