




 超级会员免费看
超级会员免费看
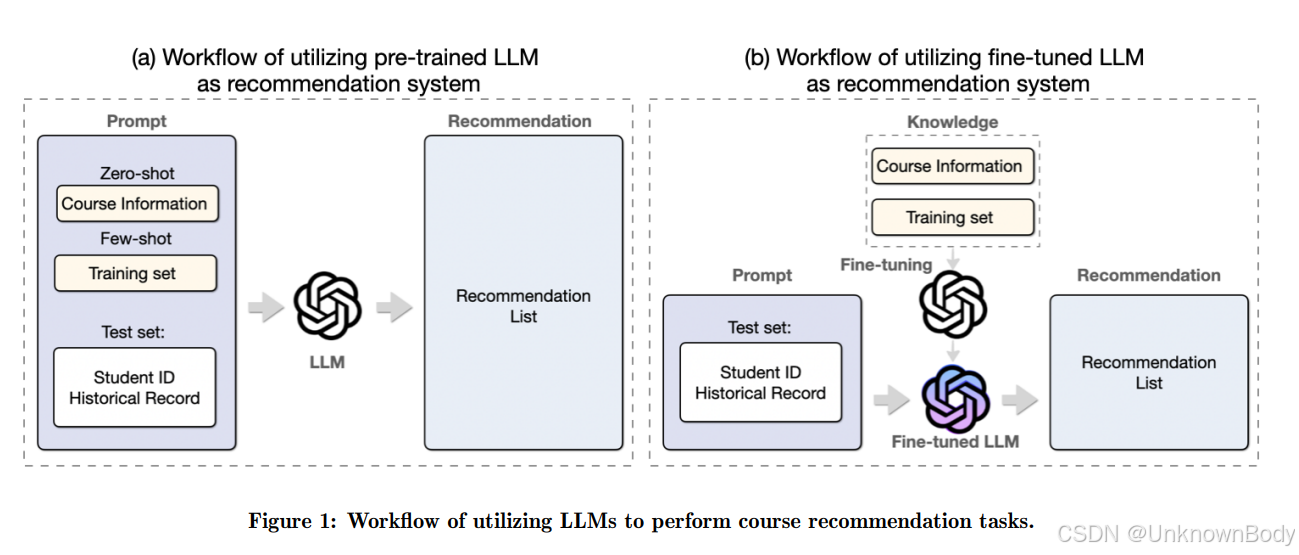
主要内容
- 研究背景:课程推荐系统在教育领域愈发重要,但传统推荐模型存在泛化性不足、需特定数据训练等问题,深度学习模型存在可解释性差的缺点。大语言模型(LLMs)在自然语言处理领域表现出色,在推荐系统中的应用逐渐受到关注,但在大规模开放在线课程(MOOCs)课程推荐方面的研究较少。
- 相关工作:介绍了课程推荐的多种方法,如基于内容的方法、矩阵分解技术、关联规则挖掘等,以及LLMs在推荐系统中的应用,包括直接使用基于提示的技术和作为组件增强传统推荐模型。
- 方法:探索两种将LLMs应用于课程推荐的方法。一是直接使用预训练的LLMs,基于提示生成推荐;二是微调LLMs,利用学生交互数据丰富其知识库后生成推荐。
- 评估:使用来自中国最大的MOOC网站之一学堂在线的MOOCCubeX数据集,选取多种传统推荐模型作为基线。采用准确率、覆盖率、新颖性等多种指标评估,将数据集按80%训练、20%测试划分,并随机抽取1000条记录评估。
- 结果:预训练LLMs在零样本提示设置下表现较差,少样本提示设置下表现较好,但总体仍不如传统推荐方法。微调后的LLMs在各种指标上均优于其他方法。在多样性和新颖性方面,随机模型覆盖率和基尼指数最高,但微调后的LLMs表现也较好。在冷启动场景下,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3365
3365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











