




 本文提出MECT模型,基于多元数据(字、词、汉字结构)的双流Transformer,用于提升中文命名实体识别(NER)性能。通过汉字的部首等结构信息,模型在多个中文NER数据集上取得显著效果,尤其是在小规模和多类别数据集上。
本文提出MECT模型,基于多元数据(字、词、汉字结构)的双流Transformer,用于提升中文命名实体识别(NER)性能。通过汉字的部首等结构信息,模型在多个中文NER数据集上取得显著效果,尤其是在小规模和多类别数据集上。

©PaperWeekly 原创 · 作者 | 宁金忠
学校 | 大连理工大学博士生
研究方向 | 信息抽取
本篇论文发表于 ACL 2021,作者聚焦于中文 NER 任务。近些年来,在模型中引入词汇信息已经成为提升中文 NER 性能的主流方法。已有的中文 NER 词增强方式主要通过 lattice 结构在模型中引入词汇的边界信息和词嵌入信息。现如今我们使用的汉字从古老的象形文字演化而来,汉字中包含的偏旁部首等结构可以代表某些含义。因此,本文的作者提出在模型中融合进汉字的结构信息(例如部首等)。

论文标题:
MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition
论文链接:
https://aclanthology.org/2021.acl-long.121.pdf

中文词汇增强回顾
中文 NER 的词汇增强主要分为两条路线:
1. Dynamic Architecture:通过动态结构,在模型中注入词汇信息;
2. Adaptive Embedding:将词汇信息融合到 Embeding 中。
近些年来各大顶会上的中文 NER 词汇增强相关论文总结如下(参考博文 [1] ):

其具体实现方法总结为:
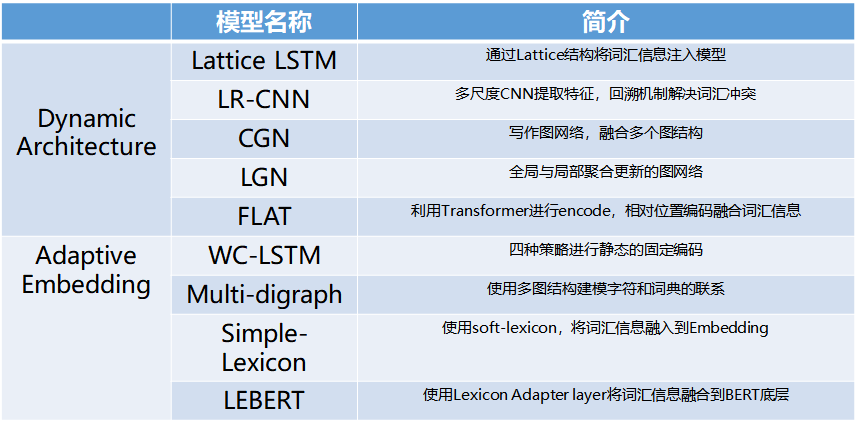 ▲ 词增强NER模型简介
▲ 词增强NER模型简介
已有的词增强 NER 模型的性能如下图所示:
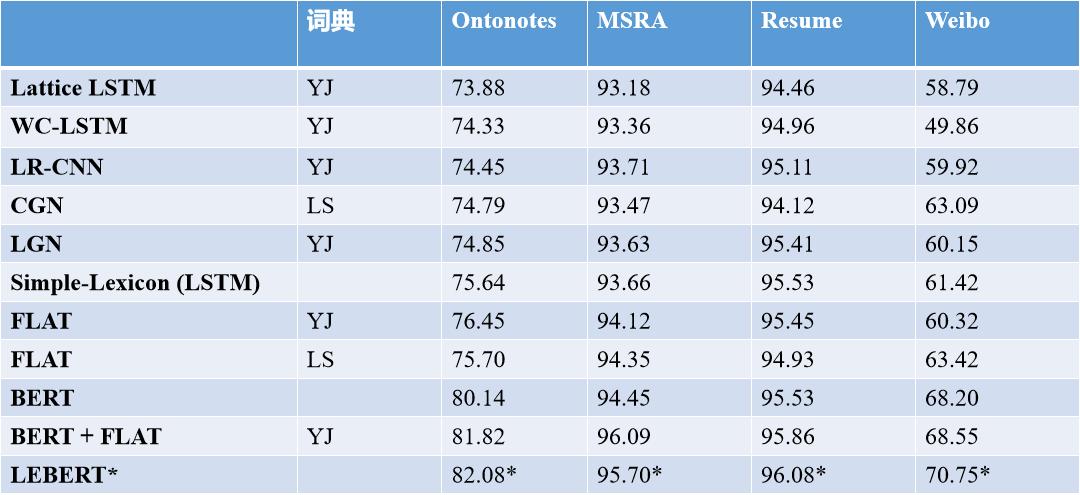
▲ 模型实验结果(表中LEBERT使用的词表和预训练词向量与其他模型不同,结果在此处仅做参考,详情见论文)

论文方法介绍
文中作者的主要贡献为:
在中文 NER 模型中使用了多元数据特征(字特征,词特征以及汉字的结构特征)。
提出了一种能够将字特征、词特征和部首特征结合的双流(two-st
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









