




原子操作类
我们知道,当多线程同时对一个变量进行更新操作时,可能会出现线程安全性问题,通常我们可以使用synchronized、Lock来进行同步操作解决这个问题,但是这样程序性能会有所影响。JAVA1.5之后,JUC包中提供了一系列的原子操作类,提供了一种用法简单、性能高效、线程安全地更新变量的方式。
原子更新基本类型类
使用原子的方式更新基本类型,Atomic包提供了以下三个类
- AtomicInteger:原子更新整数类型
- AtomicBoolean:原子更新布尔类型
- AtomicLong:原子更新长整型
它们的原理类似,内部都是使用Unsafe来实现,我们以AtomicLong类为例讲解
首先,该类内部定义了Unsafe类实例、实际变量值、内存偏移量等成员变量
//获取Unsafe类实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
//存放变量value的内存偏移量
private static final long valueOffset;
//实际变量值
private volatile long value;
然后,我们来看下该类中的主要函数
递增或递减函数
//原子性递增1,返回递增后的值
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
//原子性递减1,返回递减后的值
public final long decrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, -1L) - 1L;
}
//原子性递增1,返回原始值
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
//原子性递减1,返回原始值
public final long getAndDecrement() {
return unsafe.getAndAddLong(this, valueOffset, -1L);
}
我们发现递增和递减函数都是通过调用Unsafe类的getAndAddLong方法来实现的,这个函数是原子性操作。我们来看下源码
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
该段代码逻辑为,先拿到当前变量的值,因为变量是Volatile的,所以拿到的是最新的值,然后对其+1后,使用CAS修改变量的值,循环设置直至成功。
CAS修改函数
public final boolean compareAndSet(long expect, long update) {
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}
同样地,内部也是调用了Unsafe的方法,Unsafe内部是一个native方法,是调用CPU指令实现的,当expect和内存中的value值一致时,更新成功返回true,否则返回false。
使用案例
例子:通过多线程使用AtomicLong来统计0的个数
public class AtomicDemo {
private static AtomicLong atomicLong=new AtomicLong();
private static Integer[] arrayA={0,1,2,3,0,5,6,0,56,0};
private static Integer[] arrayB={10,1,2,3,0,0,0,0,56,0};
public static void main(String[] args) throws Exception {
Thread threadA=new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<arrayA.length;i++){
if(arrayA[i]==0){
atomicLong.incrementAndGet();
}
}
}
});
Thread threadB=new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<arrayB.length;i++){
if(arrayB[i]==0){
atomicLong.incrementAndGet();
}
}
}
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
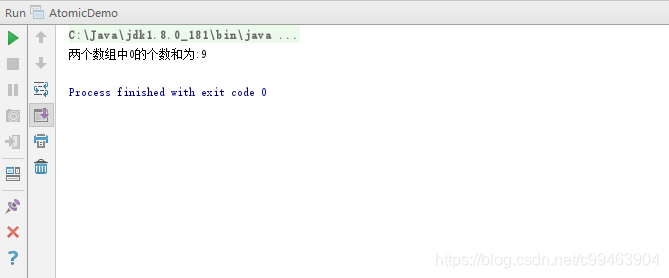
System.out.println("两个数组中0的个数和为:"+atomicLong.get());
}
}
Atomic包只提供了三种基本类型的原子操作类,那么其他基本类型呢?前面我们已经知道,Atomic包里面的类基本都是通过Unsafe类实现的,如果我们需要对其他基本类型进行操作,只需要自己实现即可。
原子更新数组类
- AtomicIntegerArray:原子更新整型数组里的元素
- AtomicLongArray:原子更新长整型数组里的元素
- AtomicReferenceArray:原子更新引用类型数组里的元素
我们这里以AtomicLongArray为例来讲解,看下它的常用方法
//将数组第i个元素设置为newValue,并返回旧值
public final long getAndSet(int i, long newValue) {
return unsafe.getAndSetLong(array, checkedByteOffset(i), newValue);
}
//进行CAS操作,如果第i个元素等于expect,则更新为update值
public final boolean compareAndSet(int i, long expect, long update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}
//将第i个元素+1
public final long getAndIncrement(int i) {
return getAndAdd(i, 1);
}
//将第i个元素-1
public final long getAndDecrement(int i) {
return getAndAdd(i, -1);
}
//以原子方式将第i个元素和delta相加
public final long getAndAdd(int i, long delta) {
return unsafe.getAndAddLong(array, checkedByteOffset(i), delta);
}
可以看到其内部原理和AtomicLong大同小异,都是通过调用Unsafe类进行CAS操作设置。
使用案例
public class AtomicArrayDemo {
static AtomicLongArray atomicLongArray=new AtomicLongArray(10);
public static void main(String[] args) throws InterruptedException {
Thread threadA=new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<1000;i++){
atomicLongArray.getAndIncrement(0);
}
}
});
Thread threadB=new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<1000;i++){
atomicLongArray.getAndDecrement(0);
}
}
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
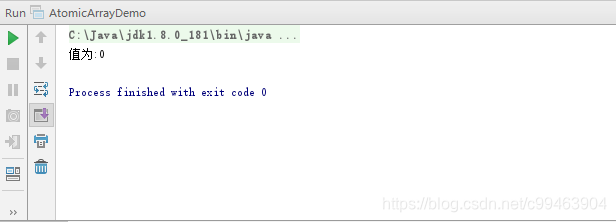
System.out.println("值为:"+atomicLongArray.get(0));
}
}
原子更新引用类型类
- AtomicReference:原子更新引用类型
- AtomicStampedReference:原子更新带有版本号的引用类型
- AtomicMarkableReference:原子更新带有标记位的引用类型
原子更新引用类型的类和前面的类原理都是高度类似的,原子更新引用类型类可以保证修改对象引用时的线程安全性,基本的内部原理可以参考上面的类。
这里我们要说重点说下ABA问题,一般来说,ABA问题发生的概率很小,即使发生了,多数情况下是没有什么影响的,比如只是做个简单的加减操作,即使它不断地被修改,但只要最后改回了期望值,对我就没有任何影响。但是,有一些其他复杂的情况,就必须考虑ABA问题。
例如:有一家蛋糕店,为了挽留客户,为VIP卡里余额小于20元的客户一次性赠送20元,每位客户仅能被赠送一次。接下来我们通过代码模拟一下。
public class ABADemo {
//给定一个初始值19
static AtomicInteger atomicInteger=new AtomicInteger(19);
public static void main(String[] args) {
//负责为用户充值线程
new Thread(){
@Override
public void run() {
//该层循环是为了不停的监控余额
while (true) {
while (true) {
Integer m = atomicInteger.get();
//当余额小于20时,充值20元,并跳出循环
if (m < 20) {
if (atomicInteger.compareAndSet(m, m + 20)) {
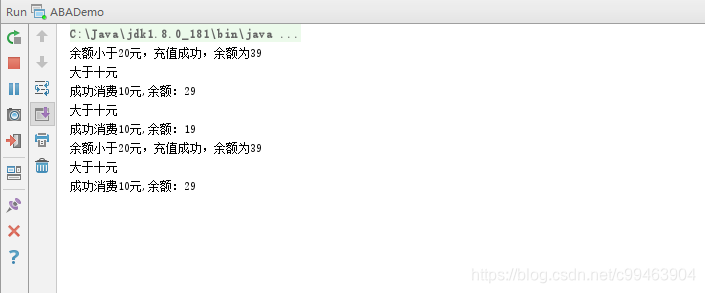
System.out.println("余额小于20元,充值成功,余额为" + atomicInteger.get());
break;
}
} else {
break;
}
}
}
}
}.start();
//用户消费线程
new Thread(){
@Override
public void run() {
//模拟用户消费三次
for (int i=0;i<3;i++) {
while (true) {
Integer m=atomicInteger.get();
//当余额大于10元时,进行消费,并跳出循环
if(m>10){
System.out.println("大于十元");
if(atomicInteger.compareAndSet(m,m-10)){
System.out.println("成功消费10元,余额:"+atomicInteger.get());
break;
}else {
break;
}
}
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
}
}
我们可以看到,账户被多次反复充值,不符合我们仅充值一次的要求。归其原因,就是因为只对数值进行判断。怎么解决呢?其实我们只需要给其再增加一个状态,来标记是否已经充值过就能很好的解决。我们曾经讲过,解决ABA问题可以添加标志来解决,而Atomic包中也为我们提供AtomicStampedReference类来为我们很好的解决这个情况。
AtomicStampedReference内部不仅维护了对象值,还维护了一个状态值(可以使用任意整数来表示状态值),当AtomicStampedReference对应的数值被修改时,还必须更改时间戳,这样当AtomicStampedReference设置值时,对象值和时间戳同时满足期望值才能成功写入。因此,即使对象值被重复修改,最后修改为原值,但是只要时间戳发生变化,同样不能更新成功。
AtomicStampedReference常用方法:
//获得当前对象引用
public V getReference() {
return pair.reference;
}
//获取时间戳
public int getStamp() {
return pair.stamp;
}
//CAS操作设置,参数依次为期望值,写入新值,期望时间戳,新的时间戳
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
//设置当前对象引用和时间戳
public void set(V newReference, int newStamp) {
Pair<V> current = pair;
if (newReference != current.reference || newStamp != current.stamp)
this.pair = Pair.of(newReference, newStamp);
}
我们用AtomicStampedReference来解决我们上面例子存在的问题。
public class StampDemo {
static AtomicStampedReference<Integer> atomicStampedReference=new AtomicStampedReference<>(19,0);
public static void main(String[] args) {
//充值
new Thread(){
@Override
public void run() {
Integer timestap=atomicStampedReference.getStamp();
while (true) {
while (true) {
Integer m = atomicStampedReference.getReference();
if (m < 20) {
if (atomicStampedReference.compareAndSet(m, m + 20,timestap,timestap+1)) {
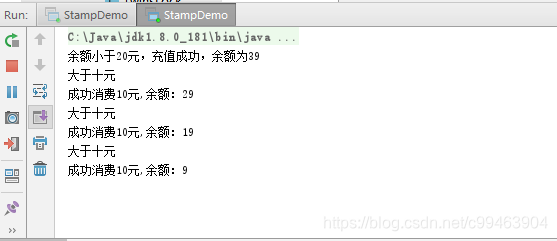
System.out.println("余额小于20元,充值成功,余额为" + atomicStampedReference.getReference());
break;
}
} else {
break;
}
}
}
}
}.start();
new Thread(){
@Override
public void run() {
for (int i=0;i<3;i++) {
while (true) {
Integer m=atomicStampedReference.getReference();
Integer timestap=atomicStampedReference.getStamp();
if(m>10){
System.out.println("大于十元");
if(atomicStampedReference.compareAndSet(m,m-10,timestap,timestap+1)){
System.out.println("成功消费10元,余额:"+atomicStampedReference.getReference());
break;
}else {
break;
}
}
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
}
}
原子更新字段类
Atomic还提供了原子更新字段类,如果需要原子更新某个类里的某个字段时,就需要使用原子更新字段类。原理一样,这里就不再细说。
- AtomicIntegerFieldUpdater:原子更新整型字段的更新器
- AtomicLongFieldUpdater:原子更新长整型字段的更新器
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
更快的递增递减原子类:LongAdder
前面讲过,AtomicLong通过CAS提供了非阻塞的原子性操作,它会在一个死循环内不断尝试修改直至成功。这就会带来一个问题,在高并发情况下大量线程会同时去更新一个原子变量,但是由于同时只有一个线程能够修改成功,这就会造成大量线程竞争失败后,通过无限循环不断进行自旋尝试CAS操作,白白浪费了大量CPU资源,造成性能下降。因此,JDK8新增了一个LongAdder类,来解决高并发下使用AtomicLong的缺点。
那么LongAdder是如何解决这个问题的呢?既然AtomicLong的性能瓶颈是由于大量线程去竞争一个变量更新而产生的,那么我们将一个变量分解成多个变量,不就解决了性能问题么?
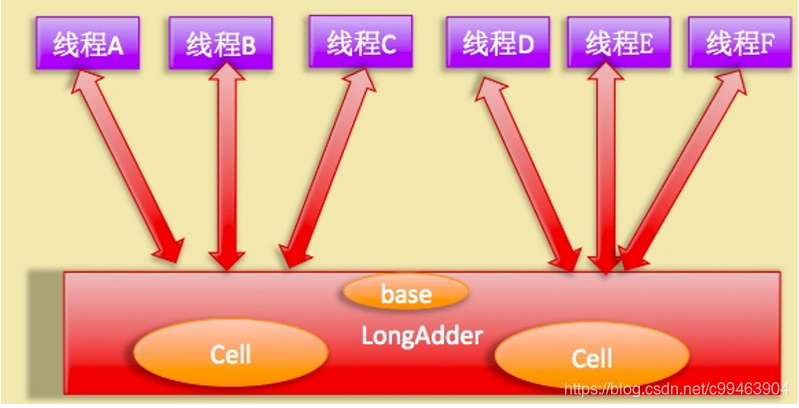
LongAdder设计思想就是这样的,如上图所示,使用LongAdder时,其在内部维护多个Cell变量,每个Cell里面有一个初始值为0的long类型变量,这样,在大量线程竞争情况下,竞争单个变量的线程数就会变少。并且,当多个线程在争夺同一个Cell原子变量时失败时,它并不是在当前Cell变量上一直自旋进行CAS操作重试,而是尝试在其他Cell变量上进行CAS尝试,这样就增加了当前线程重试CAS成功的可能性。最后,在获取LongAdder当前值时,会把所有Cell变量的value累加再加上base值返回。
LongAdder维护了一个延迟初始化的原子性更新数组(默认情况下Cell数组是null)和一个基值变量base。由于Cells占用的内存是相对比较大的,所以一开始并不创建,而是在需要时创建,也就是惰性加载。
当一开始判断Cell数组是null并且并发线程较少时,所有的累加操作都是对base变量进行的。保持Cell数组的大小为2的N次方,在初始化时Cell数组中的Cell元素个数为2,数组里面的变量实体是Cell类型,Cell类型是AtomicLong的一个改进,用来减少缓存的争用,解决伪共享问题。
LongAdder代码分析
首先,我们来看一下LongAdder的类图结构
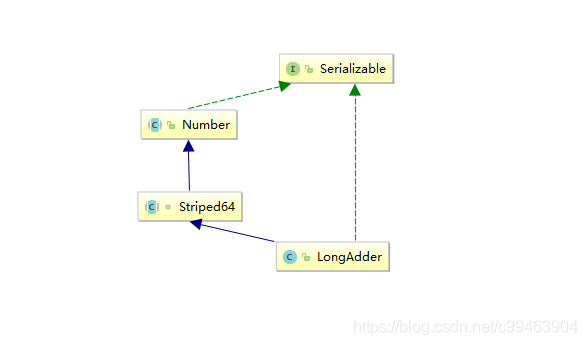
我们可以看到,LongAdder继承自Striped64类,在Striped64类内部维护着Cell[] cells、long base、int cellsBusy等变量。LongAdder的真实值是base的值和cells数组中所有cell元素value的累加,base是个基础值,默认为0。cellsBusy是个状态值,状态值只有0和1,当创建Cell元素时,扩容Cell数组或者初始化Cell数组时,使用CAS操作该变量来保证同时只有一个线程可以进行其中之一的操作。
我们先来看下Striped64类内的Cell构造
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
可以看到Cell的构造很简单,其内部维护一个被声明为volatile的变量,这里声明为volatile是因为线程操作value变量时没有使用锁,为了保证变量的内存可见性所以这样声明。cas方法通过CAS操作,保证了当前线程更新时被分配的Cell元素中value值的原子性,另外Cell类使用@sun.misc.Contended修饰来避免伪共享问题。
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
LongAdder的sum方法是返回当前的值,具体操作可以看到是累加cell数组的值再加上base值,由于计算总和时没有对Cell数组进行加锁,所以在累加过程中可能有别的线程对Cell数组中的值进行修改,也有可能对数组进行了扩容,所以sum返回的值并不是非常精确的。
public void reset() {
Cell[] as = cells; Cell a;
base = 0L;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
a.value = 0L;
}
}
}
reset方法为重置操作,把base置为0,如果Cell数组中有元素,把元素值置为0.
public long sumThenReset() {
Cell[] as = cells; Cell a;
long sum = base;
base = 0L;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null) {
sum += a.value;
a.value = 0L;
}
}
}
return sum;
}
sumThenReset是对sum的改造,该方法在使用sum累加base和Cell数组的值后,会将Cell数组里的元素值置为0,base置为0.这样,当多线程调用该方法时就会出现问题,比如第一个线程调用后清空了值,则后一个线程调用时累加的都是0.
下面我们主要看下add方法的实现。
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {//(1)
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 || //(2)
(a = as[getProbe() & m]) == null || //(3)
!(uncontended = a.cas(v = a.value, v + x))) //(4)
longAccumulate(x, null, uncontended); //(5)
}
}
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
首先看cells是否为null,如果为null则执行casBase方法在当前基础变量base上进行累加。如果cells不为null或者线程执行casBase方法的CAS操作失败了,则会继续向下执行,首先会将冲突标志uncontended设置为true,代码(2)会判断当前Cell数组是否为空,不为空时继续向下执行,代码(2)(3)是决定当前线程应该访问cells数组中的哪一个Cell元素,这个过程是通过getProbe() & m运算的,其中m是当前cells数组元素个数-1,getProbe()则用于获取当前线程中变量threadLocalRandomProbe的值,这个值一开始为0,在代码(5)里面会对其进行初始化。如果当前线程映射的元素存在则执行代码(4),使用CAS操作去更新分配的Cell元素的value值,如果当前线程映射的元素不存在或者存在但是CAS操作失败则执行代码(5)。
接下来我们重点研究一下longAccumulate方法的逻辑,这是cells数组初始化和扩容的地方。
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
//(6)初始化当前线程的变量threadLocalRandomProbe的值
int h;
//如果当前线程getProbe为0,则会给当前线程生成一个随机值
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
//cells数组已经被初始化
if ((as = cells) != null && (n = as.length) > 0) {//(7)
//取元素
if ((a = as[(n - 1) & h]) == null) { //(8)
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
//当前Cell存在,则执行CAS设置(9)
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
//当前Cell元素个数大于CPU个数(10)
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
//是否有冲突(11)
else if (!collide)
collide = true;
//如果当前元素个数没有达到CPU个数并且有冲突则扩容(12)
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//(13)为了能够找到一个空闲的Cell,重新计算hash值,xorshift算法生成随机数
h = advanceProbe(h);
}
//(14)初始化Cell数组
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
当每个线程第一次执行到代码(6)处时,会初始化当前线程变量threadLocalRandomProbe的值,我们上面讲过,这个值在计算当前线程应该被分配到cells数组的哪一个Cell元素时会被用到。
cells数组的初始化是在代码(14)处进行的,其中cellsBusy是一个标示,为0说明当前cells数组没有在被初始化或扩容,也没有在新建Cell元素,为1则说明cells数组在被初始化或扩容,或者当前在创建新的Cell元素,通过CAS操作来进行0或1的状态切换,这里使用了casCellsBusy方法。假设当前线程通过CAS设置cellsBusy为1,则当前线程开始执行初始化操作。可以看到初始化cells数组元素个数为2,然后使用h&1计算当前线程应该访问cells数组的哪个位置,也就是使用当前线程的threadLocalRandomProbe变量值&(cells数组元素个数-1),然后标示cells数组已经被初始化,最后重置cellsBusy标示。显然这里没有使用CAS操作,但是是线程安全的,因为cellsBusy是volatile类型,保证了变量的内存可见性,另外此时其他地方的代码没有机会修改cellsBusy的值,这里初始化cells数组里面的两个元素的值仍然为null。
cells数组的扩容是在代码(12)处完成的,cells扩容的条件是代码(10)(11)的条件都不满足的时候,具体就是当前cells数组的元素个数小于当前机器的CPU个数并且当前多个线程访问了cells中同一个元素,从而导致冲突使其中一个线程CAS失败时才会进行扩容操作。代码(12)处的扩容操作也是先通过CAS设置cellsBusy为1,然后才能进行扩容,假设CAS执行成功则将容量扩大为以前的两倍,并赋值cells元素到扩容后数组。扩容后cells数组除了包含复制过来的Cell元素,还包含其他新元素,这些元素的值目前还是null。
在代码(7)(8)处,当前线程调用add方法并根据当前线程的随机数threadLocalRandomProbe和cells元素个数计算要访问的cell元素下标,然后如果发现对应下标元素的值为null,则新增一个Cell元素到cells数组,并且在将其添加到cells数组之前要设置cellsBusy为1。
代码(13)处对CAS失败的线程重新计算当前线程的随机值threadLocalRandomProbe,以减少下次访问cells元素时的冲突机会。
LongAdder增强版:LongAccumulator
LongAdder是LongAccumulator的一个特例,LongAccumulator功能比LongAdder更强大。LongAdder只能进行加减操作,而LongAccumulator提供了自定义的函数操作。
我们看下LongAccumulator的构造函数,LongBinaryOperator是一个双目运算器接口,其根据输入的两个参数返回一个计算值(LongBinaryOperator接收2个long作为参数,并返回1个long型计算结果),identity则是初始值。
public LongAccumulator(LongBinaryOperator accumulatorFunction,
long identity) {
this.function = accumulatorFunction;
base = this.identity = identity;
}
public interface LongBinaryOperator {
long applyAsLong(long left, long right);
}
LongAccumulator相比于LongAdder,可以提供非0的初始值,LongAdder只能使用默认的0初始值。其他内部原理和LongAdder基本一样,可以自己去读下源码。
使用案例
public class LongAccumulatorDemo {
static LongAccumulator longAccumulator=new LongAccumulator(new LongBinaryOperator() {
@Override
public long applyAsLong(long left, long right) {
return left*right;
}
},2);
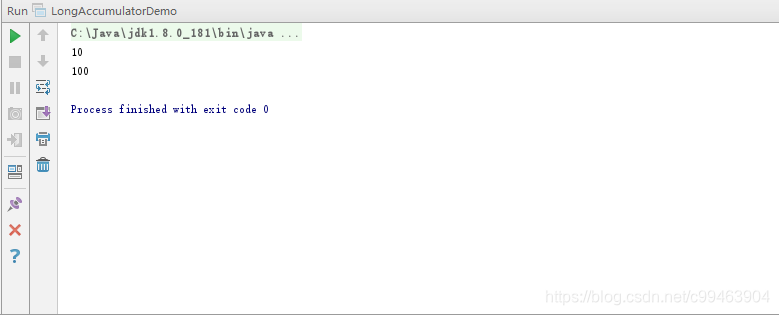
public static void main(String[] args) {
longAccumulator.accumulate(5);
System.out.println(longAccumulator.get());
longAccumulator.accumulate(10);
System.out.println(longAccumulator.get());
}
}

















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









