



 本文围绕Python函数展开,介绍了自定义函数的方法,包括函数参数、参数定义类型。提到函数内部使用全局变量的规则,以及内置关键字global可在函数体内修改全局变量,但工作中不建议使用。还讲解了函数递归、匿名函数lambda,并给出学生信息库案例。
本文围绕Python函数展开,介绍了自定义函数的方法,包括函数参数、参数定义类型。提到函数内部使用全局变量的规则,以及内置关键字global可在函数体内修改全局变量,但工作中不建议使用。还讲解了函数递归、匿名函数lambda,并给出学生信息库案例。
1、自定义一个函数
def name(args…):
do …
返回值
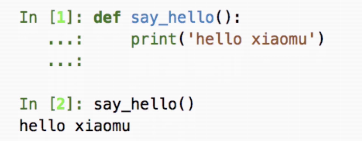
自己写一个函数实现首字符串的字母大写
 我写的:
我写的:
return代表了函数的结束,return语句之后的代码不会再执行
函数的参数

即使函数有默认参数值,但你在使用的时候还是赋予了新的值,那么会使用新赋予的值

一个代表元组,一个代表字典
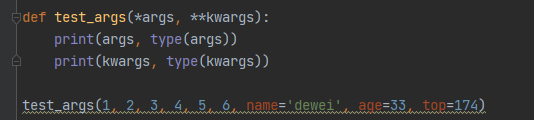

如何给这种函数传参:要用一个星号 两个星号来区分:
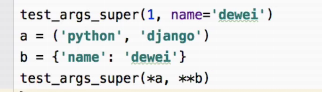



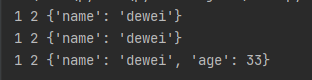
 最后一句会报错,当顺序发生变化时,要使用赋值传参
最后一句会报错,当顺序发生变化时,要使用赋值传参
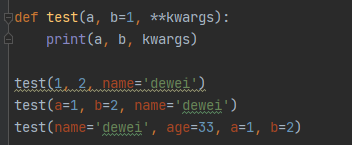
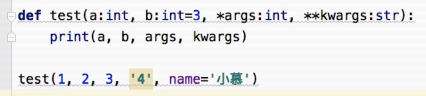
参数定义类型的方法

 后面的不会报错 因为函数不会进行参数验证 仅是写代码的参考
后面的不会报错 因为函数不会进行参数验证 仅是写代码的参考
 输出为:
输出为:![]()
 输出为:
输出为: ![]()
全局变量 局部变量
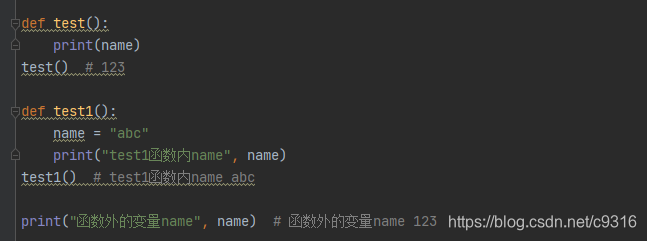
函数内部只能使用全局变量,不能修改全局变量的值,上面例子 test1()函数内 定义了局部变量,并没有修改全局变量

函数体内定义的name变量(局部变量),在函数体外无法使用
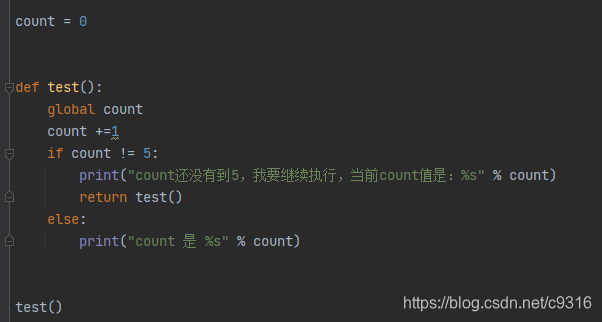
全局变量不能在函数体内修改,那要如何在函数体内修改使用呢?
内置关键字global
将全局变量可以在函数体内进行修改

工作中,不建议使用global对全局变量进行修改
 输出为:
输出为: ![]()
字典、列表类型 无需使用global 就能在函数体内进行修改使用
global仅支持 数字 字符串 空类型 布尔类型的声明
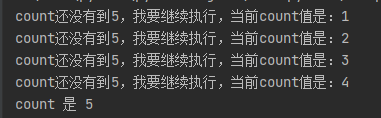
函数的递归
递归函数:一个函数不停的将自己反复执行

python中的匿名函数 lambda
lambda函数用来定义一个轻量化的函数,即用即删除,很适合需要完成一项功能,但是此功能只在此一处使用
 冒号后面的value 实际上是return value;简写了而已
冒号后面的value 实际上是return value;简写了而已
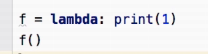
 输出为:1
输出为:1
 输出为: 1
输出为: 1
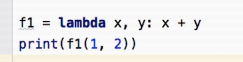 输出为:3
输出为:3
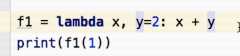 输出为:3 注意有必传参数和默认参数时,注意顺序:必传参数在前
输出为:3 注意有必传参数和默认参数时,注意顺序:必传参数在前
 输出为:False
输出为:False
 输出为:
输出为:![]()
案例:学生信息库
# coding: UTF-8
'''
学生信息库
'''
students = {
1: {
'name': 'dewei',
'age': 33,
'class_number': 'A',
'sex': 'boy'
},
2: {
'name': 'xiaomu',
'age': 20,
'class_number': 'B',
'sex': 'boy'
},
3: {
'name': 'xiaomei',
'age': 18,
'class_number': 'B',
'sex': 'girl'
},
4: {
'name': 'jack',
'age': 25,
'class_number': 'A',
'sex': 'boy'
},
5: {
'name': 'rose',
'age': 20,
'class_number': 'C',
'sex': 'girl'
},
}
# 定义一个方法 方便后面的方法调用 减少代码重复
def check_user_info(**kwargs):
if 'name' not in kwargs:
return '缺少学生姓名'
if 'age' not in kwargs:
return "缺少学生年龄"
if 'class_number' not in kwargs:
return "缺少学生班级"
if 'sex' not in kwargs:
return "缺少学生性别"
return True
def get_all_students():
for id_, value in students.items():
print('学号是:{}, 姓名是{}, 年龄是{}, 班级是{}, 性别是{}'.format(
id_, value['name'], value['age'], value['class_number'], value['sex']
))
return students
# get_all_students()
def add_student(**kwargs):
check = check_user_info(**kwargs)
if check != True:
print(check)
return
id_ = max(students) + 1
students[id_] = {
'name': kwargs['name'],
'age': kwargs['age'],
'sex': kwargs['sex'],
'class_number': kwargs['class_number']
}
add_student(name='小白', age=19, class_number='A', sex='boy')
def delete_student(student_id):
if student_id not in students:
print("该学生{}id不存在".format(student_id))
else:
user_info = students.pop(student_id)
print('学号是{}的{}同学信息已被删除'.format(student_id, user_info["name"]))
delete_student(1)
get_all_students()
def update_student(student_id, **kwargs):
if student_id not in students:
print("没有这个{}学号".format(student_id))
check = check_user_info(**kwargs)
if check != True:
print(check)
return
students[student_id] = kwargs
print("同学信息更新完毕")
update_student(2, name='木木', age=23, class_number="A", sex='boy')
get_all_students()
def get_user_by_id(student_id):
return students.get(student_id)
# print(get_user_by_id(3))
# 按个人信息搜索
def search_users(**kwargs):
values = list(students.values())
key = None
value = None
result = []
if 'name' in kwargs:
key = 'name'
value = kwargs['name']
elif 'sex' in kwargs:
key = 'sex'
value = kwargs['sex']
elif 'class_number' in kwargs:
key = 'class_number'
value = kwargs['class_number']
elif 'age' in kwargs:
key = 'age'
value = kwargs['age']
else:
print('没有发现搜索的关键字')
return
for user in values:
if user[key] == value:
result.append(user)
return result
print("----")
users = search_users(age=18)
print(users)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









