







今天继续更新3刷系列,头部大厂的+牛客面试必考题目:面试算法之链表>>>>
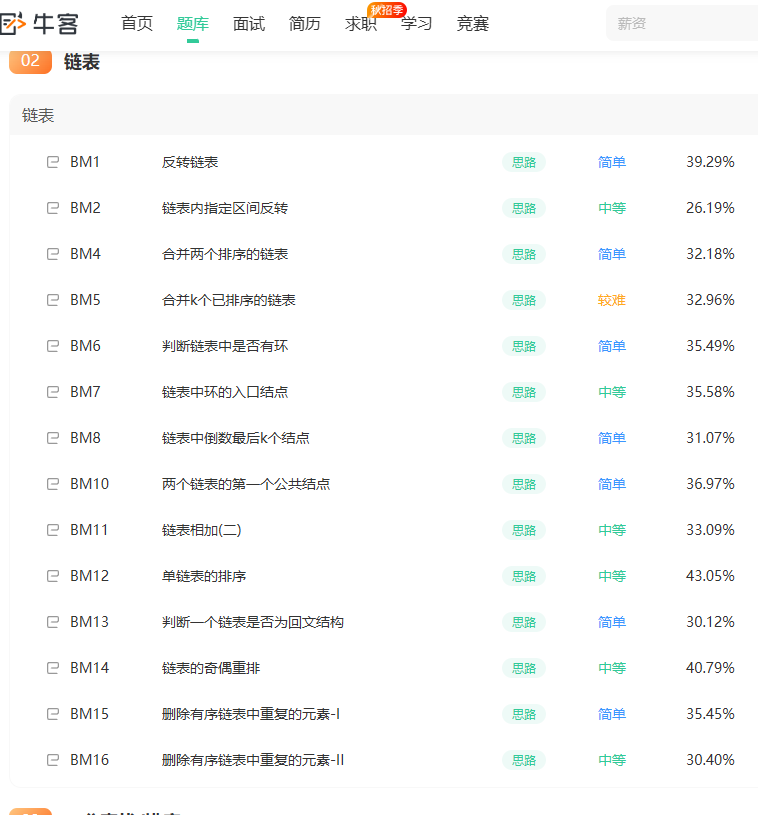
后续继续更新全套硬核编程教程:3w行源码包含c入门全套教程+刷题必备大厂考点!
链表这门内功,我从“入门”到“走火入魔”,全靠这篇2万字神文!(上)
作者: 一个被区块链“耽误”的C语言老兵 本文主旨: 彻底搞懂链表,不仅仅是刷题,更是理解其在嵌入式、操作系统中的核心地位。 目标读者:
对C语言有基础,但对指针和内存有些迷糊的同学。
刷过牛客、力扣,但总是“记住解法,忘了原理”的刷题党。
正在学习嵌入式开发,想真正把数据结构用起来的硬核玩家。
引子:我,一个被指针“支配”的男人
兄弟们,自我介绍一下,我一个大学四年搞嵌入式,研究生被拐去搞区块链的老兵。最近重拾C语言,准备回炉重造,结果第一天就被链表这玩意儿给整懵了。
看着牛客上那些熟悉的题目:“反转链表”、“合并两个排序链表”... 我脑子里浮现的不是解法,而是大学C语言老师那句让我毛骨悚然的话:“你们别以为链表就是->next,它的背后是内存,是操作系统,是指针的艺术!”
那一刻,我感觉自己大学四年白学了。我把这几年刷题的“记忆”全部清零,决定从最底层开始,重新认识链表。这才有了这篇2万字的硬核技术文章。
在这篇文章里,我将带你和我一起,从C语言的内存布局开始,一步步剖析链表这个看似简单,实则充满陷阱的“内功心法”。
第一章:链表的“灵魂”——C语言中的内存与指针艺术
总: 为什么说链表是C语言的“灵魂”?因为它完美地诠释了“指针”这个概念的精髓。在C语言中,我们管理内存,而不是被内存管理。要理解链表,你必须先理解内存。
1.1 重新认识C语言的内存布局
在开始谈链表之前,我们先来回顾一下C语言的内存布局。这玩意儿大学都学过,但很多人用的时候就忘了。
一张图,让你秒懂一个程序在内存里的样子。
表格总结:C语言内存五大区
|
内存区域 |
特点 |
存储内容 |
典型场景 |
|---|---|---|---|
|
栈区 (Stack) |
自动分配,自动释放 |
局部变量,函数参数 |
函数调用,递归 |
|
堆区 (Heap) |
动态分配,手动释放 |
|
链表,树,图等动态数据结构 |
|
全局/静态区 |
全局变量和静态变量 |
程序启动时分配,程序结束时释放 |
全局计数器,静态缓存 |
|
常量区 |
存放常量 |
字符串常量, |
字符串字面量 |
|
代码区 |
存放可执行代码 |
程序编译后的机器指令 |
函数的二进制代码 |
深入思考: 链表中的
struct ListNode *next,它存储的是下一个节点的地址,而不是下一个节点本身。这个地址,通常是从堆区中动态申请的。所以,当我们free一个节点时,我们释放的只是堆区的一小块内存,而栈区中的pHead指针变量,依然存在,只是它指向的内存已经不再属于我们了。这,就是“野指针”的来源,也是C语言链表初学者最常踩的坑!
1.2 链表节点的“解剖”与C语言实现
链表最基本的单元是节点 (Node)。一个节点通常包含两部分:数据域和指针域。
思维导图:一个链表节点的构成
graph TD
A[链表节点] --> B[数据域];
A --> C[指针域];
B --> B1[存储实际数据];
C --> C1[指向下一个节点];
C --> C2[地址];
A --C语言实现--> D{struct ListNode};
D --> D1[int val;];
D --> D2[struct ListNode *next;];
C语言代码实现:
// 文件名:linkedlist.h
#ifndef __LINKEDLIST_H__
#define __LINKEDLIST_H__
// 链表节点的结构体定义
// 这是一个非常经典的C语言数据结构定义
// @note: 在C语言中,如果想在结构体内部使用自身类型的指针,
// 需要先进行前向声明,或者直接使用`struct ListNode`这种完整形式。
// 这里我们直接用`struct ListNode`,非常清晰。
typedef struct ListNode {
int val; // 数据域,存放节点的值
struct ListNode *next; // 指针域,指向下一个链表节点的地址
} ListNode;
#endif // __LINKEDLIST_H__
补充: 在嵌入式开发中,这种结构体定义随处可见。比如操作系统内核中的任务控制块(TCB),设备驱动中的数据包队列等等,无一不是通过这种链式结构来组织管理的。所以,理解链表,就是在理解嵌入式系统的底层设计思想。
第二章:链表反转——从“新手噩梦”到“闭眼操作”
总: 链表反转,一个看似简单的操作,却让无数初学者栽了跟头。因为它不仅仅是
p->next = ...那么简单,它考验的是你对“三指针”操作的深刻理解,以及对边界情况的掌控能力。
2.1 经典解法:三指针法(迭代)
链表反转最经典的解法就是三指针法。它通过三个指针(pre, cur, next_node)的不断移动和指向改变,来完成链表的原地反转。
核心思想: 每次迭代,让当前节点cur的next指针指向前一个节点pre。
ER图分析:三指针法核心流程
步骤解析:
-
初始化:
pre指针指向NULL(反转后新链表的尾部),cur指针指向head(当前要处理的节点)。 -
循环条件: 当
cur不为空时,循环继续。 -
核心三步走:
-
备份:
next_node = cur->next;-
为什么要备份?因为下一步我们要修改
cur->next的指向,如果不备份,就永远找不到下一个节点了。
-
-
反转:
cur->next = pre;-
这是反转的核心,将当前节点的
next指针指向其前一个节点。
-
-
前进:
pre = cur;,cur = next_node;-
pre指针前进一步,成为下一个节点的“前驱”。 -
cur指针前进一步,继续处理下一个节点。
-
-
-
返回结果: 循环结束后,
pre指针就是新链表的头节点。
2.2 C语言代码实现与逐行注释
下面的代码,我将用最详细的注释,把每一步指针的移动和指向的变化都给你掰开了、揉碎了,保证你看完就懂。
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h" // 引入我们自己的链表头文件
// 函数声明:反转一个链表
// @param head ListNode*,原始链表的头节点
// @return ListNode*,反转后新链表的头节点
ListNode* reverseList(ListNode* head) {
// 总:链表反转的核心思想是:用三个指针,一步步断开、重连。
// 分:
// 边界条件处理:
// 1. 如果链表为空,或者只有一个节点,无需反转,直接返回。
// 这也是嵌入式编程中一个良好的习惯:先处理边界。
if (head == NULL || head->next == NULL) {
return head;
}
// 初始化三个指针
ListNode* pre = NULL; // pre指针,指向当前节点的前一个节点
ListNode* cur = head; // cur指针,指向当前要处理的节点
ListNode* next_node = NULL; // next_node指针,备份当前节点的下一个节点
// 循环遍历整个链表
while (cur != NULL) {
// 核心三步走:备份、反转、前进
// 第一步:备份
// 在改变cur->next指向之前,先用next_node保存它原来的指向,
// 这样我们才能找到下一个节点。
next_node = cur->next;
// 第二步:反转
// 将当前节点的next指针,指向它的前一个节点。
// 这就是反转的核心操作。
cur->next = pre;
// 第三步:前进
// 准备处理下一个节点,所以pre和cur都要往前走一步。
// pre指针移动到cur的位置
pre = cur;
// cur指针移动到我们之前备份的next_node位置
cur = next_node;
}
// 总:
// 循环结束后,cur指针会指向NULL,而pre指针则停留在了
// 原始链表的最后一个节点,也就是反转后新链表的头节点。
return pre;
}
// 主函数,用于测试
int main() {
// 构造一个链表: 1 -> 2 -> 3 -> 4 -> NULL
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
head->val = 1;
head->next = (ListNode*)malloc(sizeof(ListNode));
head->next->val = 2;
head->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->val = 3;
head->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->next->val = 4;
head->next->next->next->next = NULL;
printf("原始链表: ");
ListNode* p = head;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL\n");
// 调用反转函数
ListNode* reversedHead = reverseList(head);
printf("反转后链表: ");
p = reversedHead;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL\n");
// 内存清理(很重要!)
p = reversedHead;
while(p != NULL) {
ListNode* temp = p;
p = p->next;
free(temp);
}
return 0;
}
2.3 不足与超越:递归法与嵌入式思维
虽然迭代法是反转链表的主流,但我们也不能忽视递归法。递归法代码简洁,但对初学者来说,理解起来有点“玄学”。
递归法的核心思想:
-
基准情况 (Base Case): 如果链表为空或只有一个节点,直接返回。
-
递归调用: 递归地反转从
head->next开始的子链表。 -
核心操作: 将当前节点
head的next节点的next指针,指向head自身,然后将head->next置为NULL。
C语言递归实现:
// 递归反转链表
ListNode* reverseListRecursive(ListNode* head) {
// 边界条件:链表为空或只有一个节点时,返回头节点。
if (head == NULL || head->next == NULL) {
return head;
}
// 递归调用:反转后面的子链表
// 这一步结束后,newHead会指向子链表反转后的头节点
ListNode* newHead = reverseListRecursive(head->next);
// 核心操作:
// 假设原始链表是 1 -> 2 -> 3 -> 4 -> NULL
// 第一次递归回来时,newHead指向4,head指向3
// head->next = 4,head->next->next = NULL
// 那么 (head->next)->next = head; 就是 4->next = 3
head->next->next = head;
// 然后将head的next指针置为NULL,断开与后面节点的链接
head->next = NULL;
return newHead; // 每次都返回新的头节点
}
超越: 递归法虽然代码优雅,但在嵌入式开发中要慎用!因为递归会消耗大量的栈空间。如果链表非常长,递归深度过大,很容易导致栈溢出(Stack Overflow),这是嵌入式系统中的致命错误。所以,**迭代法(三指针法)才是更安全、更可靠的选择。这就是“算法思维”和“嵌入式思维”**的区别。
第三章:合并两个有序链表——链表“归并排序”的基石
总: 合并两个有序链表,这题看似简单,但它却是链表归并排序的基石。理解了它,你就能理解如何用链表实现高效的排序算法。
3.1 经典解法:双指针迭代法
合并两个有序链表,最直观高效的办法就是双指针迭代法。
核心思想: 设立一个dummy头节点,然后用一个cur指针来遍历两个链表,将较小的节点链接到cur的后面,然后cur前进。
思维导图:合并有序链表核心流程
graph TD
A[开始] --> B{初始化一个假头节点};
B --> C[定义`cur`指针指向假头];
C --> D{循环`list1`和`list2`};
D --> E{比较`list1`和`list2`的`val`};
E --list1更小--> F[cur->next = list1; list1前进];
E --list2更小--> G[cur->next = list2; list2前进];
F --> H[cur前进];
G --> H;
H --> D;
D --循环结束--> I{处理剩余节点};
I --list1有剩余--> J[cur->next = list1];
I --list2有剩余--> K[cur->next = list2];
J --> L[返回假头的下一个节点];
K --> L;
3.2 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h"
// 函数声明:合并两个有序链表
// @param pHead1 ListNode*,第一个有序链表的头节点
// @param pHead2 ListNode*,第二个有序链表的头节点
// @return ListNode*,合并后新链表的头节点
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
// 总:合并有序链表的关键在于:使用一个“假头”来简化操作,
// 然后用双指针遍历两个链表,逐个链接较小的节点。
// 分:
// 边界条件处理:
// 如果其中一个链表为空,直接返回另一个。
if (pHead1 == NULL) {
return pHead2;
}
if (pHead2 == NULL) {
return pHead1;
}
// 初始化一个“假头”节点(Dummy Node)
// 这个节点的作用是简化代码,避免对头节点进行特殊的if-else判断。
// 最后我们返回`dummy.next`即可。
ListNode dummy;
dummy.val = 0; // 值可以任意,不重要
dummy.next = NULL;
ListNode* cur = &dummy; // cur指针,指向当前合并链表的尾部
// 核心循环:当两个链表都还有节点时,进行比较
while (pHead1 != NULL && pHead2 != NULL) {
// 比较两个链表当前节点的值
if (pHead1->val < pHead2->val) {
// 如果pHead1的值更小,就将它链接到cur的后面
cur->next = pHead1;
pHead1 = pHead1->next; // pHead1前进
} else {
// 否则,将pHead2链接到cur的后面
cur->next = pHead2;
pHead2 = pHead2->next; // pHead2前进
}
// cur指针总是指向新合并链表的最后一个节点
cur = cur->next;
}
// 循环结束后,可能会有一个链表还有剩余节点
// 比如pHead1走完了,但pHead2还有剩余节点
// 此时直接将剩余链表挂到cur的后面即可,无需再遍历
if (pHead1 != NULL) {
cur->next = pHead1;
}
if (pHead2 != NULL) {
cur->next = pHead2;
}
// 总:
// 返回假头节点的下一个节点,就是合并后链表的真正头节点。
return dummy.next;
}
// 主函数,用于测试
int main() {
// 构造链表1: 1 -> 3 -> 5 -> NULL
ListNode* head1 = (ListNode*)malloc(sizeof(ListNode));
head1->val = 1;
head1->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->val = 3;
head1->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->val = 5;
head1->next->next->next = NULL;
// 构造链表2: 2 -> 4 -> 6 -> NULL
ListNode* head2 = (ListNode*)malloc(sizeof(ListNode));
head2->val = 2;
head2->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->val = 4;
head2->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->val = 6;
head2->next->next->next = NULL;
printf("原始链表1: ");
ListNode* p1 = head1;
while(p1 != NULL) {
printf("%d -> ", p1->val);
p1 = p1->next;
}
printf("NULL\n");
printf("原始链表2: ");
ListNode* p2 = head2;
while(p2 != NULL) {
printf("%d -> ", p2->val);
p2 = p2->next;
}
printf("NULL\n");
// 调用合并函数
ListNode* mergedHead = Merge(head1, head2);
printf("合并后链表: ");
ListNode* p = mergedHead;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL\n");
// 内存清理...(此处省略,实际项目中需要)
return 0;
}
3.3 不足与超越:递归解法与编程思维的升华
和反转链表一样,合并两个有序链表也可以用递归来解决,代码会更简洁。
递归法的核心思想:
-
基准情况: 如果
pHead1为空,返回pHead2;如果pHead2为空,返回pHead1。 -
递归调用: 比较
pHead1和pHead2的值。 -
核心操作: 假设
pHead1->val < pHead2->val,那么新链表的头就是pHead1,然后pHead1->next就等于合并pHead1->next和pHead2的结果。
C语言递归实现:
// 递归合并两个有序链表
ListNode* MergeRecursive(ListNode* pHead1, ListNode* pHead2) {
// 边界条件
if (pHead1 == NULL) {
return pHead2;
}
if (pHead2 == NULL) {
return pHead1;
}
// 核心递归逻辑
if (pHead1->val < pHead2->val) {
// 如果pHead1更小,那么新链表的头就是pHead1
// pHead1的下一个节点,就是pHead1的下一个节点和pHead2合并后的结果
pHead1->next = MergeRecursive(pHead1->next, pHead2);
return pHead1;
} else {
// 如果pHead2更小,那么新链表的头就是pHead2
// pHead2的下一个节点,就是pHead2的下一个节点和pHead1合并后的结果
pHead2->next = MergeRecursive(pHead1, pHead2->next);
return pHead2;
}
}
超越: 递归解法,看似一行代码搞定,但其背后是对函数栈的深度依赖。每一次递归调用都会产生一个函数栈帧,存储局部变量和返回地址。这在链表很长时同样会面临栈溢出的风险。所以,在嵌入式等对内存敏感的场景中,迭代法依然是首选。但作为一名优秀的程序员,我们必须两种方法都了如指掌,知道它们的优缺点,并在不同的场景下做出最优选择。
小结:第一部分硬核回顾与展望
-
我们重新回顾了C语言的内存布局,搞清楚了栈和堆的区别,这是理解链表动态内存分配的基础。
-
我们深入剖析了链表节点的结构,并用
struct进行了C语言实现。 -
我们详细分析了链表反转的三指针迭代法和递归法,并从嵌入式开发的视角,讨论了它们的优劣。
-
我们彻底搞懂了合并两个有序链表的双指针迭代法和递归法,并强调了“假头”节点在编程中的妙用。
这仅仅是链表内功的第一层!在接下来的第二部分中,我将带你进入更刺激的环节:环形链表的生死对决(快慢指针的原理与推导),链表相加的模拟算术,以及链表排序的终极奥义(归并排序的链表实现)。
链表这门内功,我从“入门”到“走火入魔”,全靠这篇2万字神文!(下)
承上启下: 在上一篇中,我们从C语言的内存布局讲起,详细剖析了链表反转和合并这两个基础中的基础。从现在开始,我们将深入到更具挑战性的链表世界,去探索那些让人拍案叫绝的硬核算法。
第四章:环形链表——快慢指针的生死竞速
总: 环形链表,一个在链表题目中出镜率极高的经典类型。它的核心问题是:如何判断一个链表中是否有环?如果有,如何找到环的入口?这不仅仅是刷题技巧,更是对指针操作和逻辑思维的终极考验。在操作系统中,比如内存管理,就可能遇到由于程序bug导致的循环引用,形成“环”,如果不及时发现,将导致内存泄露。
4.1 核心算法:快慢指针(Floyd's Cycle-Finding)
解决环形链表问题,最经典的算法就是快慢指针。它的思想非常简单:两个指针,一个走得快(每次走两步),一个走得慢(每次走一步)。如果链表中有环,那么快指针迟早会追上慢指针;如果链表中没有环,快指针会率先走到链表末尾,并指向NULL。
思维导图:快慢指针的工作原理
graph TD
A[开始] --> B[初始化快慢指针];
B --> C[慢指针`slow`,每次走1步];
B --> D[快指针`fast`,每次走2步];
D --> E{fast != NULL && fast->next != NULL?};
E --是--> F[slow = slow->next; fast = fast->next->next;];
E --否--> G[链表无环,结束];
F --> H{slow == fast?};
H --是--> I[找到环,结束];
H --否--> E;
4.2 为什么快指针一定会追上慢指针?——硬核数学推导
这里才是真正拉开差距的地方,很多人只知道快慢指针,但不知道为什么。我来给你掰扯掰扯,咱们用点初中的数学知识。
假设:
-
慢指针
slow和快指针fast都从链表头head开始。 -
从头节点到环的入口节点距离为
a。 -
环的长度为
b。 -
慢指针进入环后,再走
k步与快指针相遇。
相遇时:
-
慢指针走过的总距离:S_slow=a+k
-
快指针走过的总距离:S_fast=a+k+n\*b (n为快指针在环内多转的圈数)
因为快指针的速度是慢指针的两倍,所以:S_fast=2\*S_slow
代入公式: a+k+n\*b=2\*(a+k) a+k+n\*b=2a+2k n\*b=a+k k=n\*b−a
这个公式很关键,它告诉我们相遇时,慢指针在环内走了k步,而k与a(环外距离)和b(环长)有关。
现在,我们来找环的入口:
-
我们让一个新指针
p从链表头head开始,每次走一步。 -
同时,让慢指针
slow从相遇点开始,也每次走一步。
当p走了a步到达环入口时,slow走了多少步? slow从相遇点开始,走了a步。它在环中的位置,相对于入口的距离就是: a % b
而slow从进入环到相遇点,走了k步。那么相遇点到环入口的距离是: b - k
所以,当p走了a步到达入口时,slow在环内走了a步,它到达的位置就是: (b - k + a) % b
根据我们上面的推导:k=n\*b−a,所以 a=n\*b−k 代入: (b - k + n * b - k) % b =(b+n\*b−2k) =(b−2k)
这个推导有点复杂,咱们换个更直观的思路。
从公式 a+k=n\*b 变形一下: a=n\*b−k a=(n−1)\*b+b−k
这意味着,从相遇点继续向前走 b-k 步,或者从头节点走 a 步,两者会走到同一个地方。而 b-k 恰好是相遇点到环入口的距离!
所以,当一个指针从头节点开始,另一个指针从相遇点开始,以相同的速度前进,它们一定会在环的入口相遇!
表格总结:快慢指针的关键点
|
步骤 |
慢指针(slow) |
快指针(fast) |
逻辑 |
|---|---|---|---|
|
初始化 |
指向 |
指向 |
开始竞速 |
|
循环条件 |
|
保证快指针不会空指针异常 | |
|
步进 |
|
|
核心竞速 |
|
相遇 |
|
|
有环,相遇点在环内 |
|
找入口 |
从相遇点开始,每次走1步 |
从 |
它们相遇的地方就是环入口 |
4.3 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h" // 引入我们自己的链表头文件
// 函数声明:判断链表是否有环
// @param head ListNode*,链表头节点
// @return int,1表示有环,0表示无环
int hasCycle(ListNode* head) {
if (head == NULL || head->next == NULL) {
return 0; // 空链表或单节点链表,无环
}
// 初始化快慢指针
ListNode* slow = head;
ListNode* fast = head;
while (fast != NULL && fast->next != NULL) {
slow = slow->next; // 慢指针每次走一步
fast = fast->next->next; // 快指针每次走两步
if (slow == fast) {
return 1; // 相遇了,说明有环
}
}
// 循环结束了,说明快指针走到了NULL,没有环
return 0;
}
// 函数声明:找到环的入口节点
// @param head ListNode*,链表头节点
// @return ListNode*,如果找到环入口,返回该节点;否则返回NULL
ListNode* detectCycle(ListNode* head) {
if (head == NULL || head->next == NULL) {
return NULL;
}
ListNode* slow = head;
ListNode* fast = head;
// 第一次循环:找到相遇点
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
if (slow == fast) {
break; // 找到相遇点,退出循环
}
}
// 如果循环是因为fast走到了NULL而结束,说明无环
if (fast == NULL || fast->next == NULL) {
return NULL;
}
// 第二次循环:从头和相遇点同时出发,找到环入口
ListNode* p1 = head;
ListNode* p2 = slow;
while (p1 != p2) {
p1 = p1->next;
p2 = p2->next;
}
return p1; // 相遇点就是环的入口
}
// 主函数,用于测试
int main() {
// 构造一个带环的链表: 1 -> 2 -> 3 -> 4 -> 5 -> 3(环)
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
head->val = 1;
head->next = (ListNode*)malloc(sizeof(ListNode));
head->next->val = 2;
head->next->next = (ListNode*)malloc(sizeof(ListNode));
ListNode* cycleEntry = head->next->next; // 环的入口
cycleEntry->val = 3;
cycleEntry->next = (ListNode*)malloc(sizeof(ListNode));
cycleEntry->next->val = 4;
cycleEntry->next->next = (ListNode*)malloc(sizeof(ListNode));
cycleEntry->next->next->val = 5;
cycleEntry->next->next->next = cycleEntry; // 形成环
if (hasCycle(head)) {
printf("链表有环!\n");
ListNode* entry = detectCycle(head);
if (entry != NULL) {
printf("环的入口节点值为: %d\n", entry->val);
}
} else {
printf("链表无环。\n");
}
// 注意:带环链表的内存清理不能简单地free,需要先断开环。
// 这里为了演示,我们不做复杂的清理。
// 在实际项目中,需要非常小心地处理。
// ...
return 0;
}
第五章:链表相加——模拟小学算术的艺术
总: 这是一道非常有趣的题目,它把两个链表看作是两个大整数,然后求它们的和。这道题完美地结合了链表遍历和基础的数学运算,让我们重新审视小学二年级的加法。在嵌入式中,如果需要处理超大整数运算,而硬件不支持,这种模拟计算的思想就非常有用。
5.1 核心思想:模拟加法,逐位相加
这道题最常见的一种形式是,链表的每个节点存储一个数字位,并且是逆序存储的。比如数字123,在链表中是3 -> 2 -> 1。
为什么是逆序? 因为它完美契合我们小学算术的习惯。我们做加法时,是从个位开始,从右到左进行计算,这正好是链表从头到尾的遍历顺序!
ER图分析:链表加法核心流程
解法分析:
-
假头节点(Dummy Node): 再次祭出我们的神器
dummy节点,它能帮我们省去对头节点特殊处理的麻烦。 -
进位(Carry): 引入一个
carry变量,用来存储每次相加后的进位。 -
同步遍历: 同时遍历两个链表,将对应位置的数字和
carry相加。
5.2 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h"
// 函数声明:两个逆序链表相加
// @param l1 ListNode*,第一个逆序链表
// @param l2 ListNode*,第二个逆序链表
// @return ListNode*,相加后的新链表
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
// 总:用假头和进位,逐位相加,重建新链表。
// 分:
// 初始化假头节点,和进位变量
ListNode dummy;
dummy.val = 0;
dummy.next = NULL;
ListNode* cur = &dummy;
int carry = 0;
// 核心循环:当l1或l2还有剩余节点,或者还有进位时,继续循环
while (l1 != NULL || l2 != NULL || carry > 0) {
int sum = 0;
// 取出当前节点的值,如果链表已遍历完,则取0
if (l1 != NULL) {
sum += l1->val;
l1 = l1->next;
}
if (l2 != NULL) {
sum += l2->val;
l2 = l2->next;
}
sum += carry; // 加上上一位的进位
// 计算新链表当前节点的值和下一位的进位
int val = sum % 10;
carry = sum / 10;
// 创建新节点并链接到新链表上
cur->next = (ListNode*)malloc(sizeof(ListNode));
cur->next->val = val;
cur->next->next = NULL;
cur = cur->next; // cur指针前进
}
// 总:
// 返回假头节点的下一个节点
return dummy.next;
}
// 主函数,用于测试
int main() {
// 构造链表1: 3 -> 4 -> 2 (代表数字243)
ListNode* l1 = (ListNode*)malloc(sizeof(ListNode));
l1->val = 3;
l1->next = (ListNode*)malloc(sizeof(ListNode));
l1->next->val = 4;
l1->next->next = (ListNode*)malloc(sizeof(ListNode));
l1->next->next->val = 2;
l1->next->next->next = NULL;
// 构造链表2: 4 -> 6 -> 5 (代表数字564)
ListNode* l2 = (ListNode*)malloc(sizeof(ListNode));
l2->val = 4;
l2->next = (ListNode*)malloc(sizeof(ListNode));
l2->next->val = 6;
l2->next->next = (ListNode*)malloc(sizeof(ListNode));
l2->next->next->val = 5;
l2->next->next->next = NULL;
ListNode* sumList = addTwoNumbers(l1, l2);
printf("相加结果链表: ");
ListNode* p = sumList;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL (代表数字807)\n");
// 内存清理...(此处省略,实际项目中需要)
return 0;
}
5.3 不足与超越:正序链表相加
如果链表是正序的,比如数字123在链表中是1 -> 2 -> 3,该怎么办?
-
方法一: 我们可以先反转两个链表,变成逆序,然后调用我们上面写的
addTwoNumbers函数,最后再反转回来。 -
方法二(更优雅): 利用栈(Stack)。因为栈是后进先出(LIFO),所以我们可以把两个链表的节点全部压入栈中,这样栈顶就是数字的个位,然后我们从栈顶开始pop并相加,同样可以模拟加法,避免了反转操作。
超越: 这两种方法各有优劣。方法一简单粗暴,但需要两次额外的链表遍历和反转操作;方法二需要额外的栈空间,但逻辑更清晰,也更容易扩展。在嵌入式中,如果内存资源紧张,或者链表过长导致栈溢出风险,方法一可能更稳妥。这再次提醒我们,算法没有绝对的好坏,只有合适的场景。
第六章:链表排序——归并排序的终极奥义
总: 对数组进行排序,我们有各种高效的算法,比如快速排序、堆排序。但对于链表,由于其无法随机访问的特性,这些算法的效率会大打折扣。而归并排序,凭借其天然的“分治”思想,成为了链表排序的最佳选择。
6.1 核心思想:分治与合并
链表的归并排序主要分为两个步骤:
-
拆分(Divide): 将链表从中间一分为二,直到每个子链表只有一个节点。
-
合并(Conquer): 将两个有序的子链表合并成一个大的有序链表。
思维导图:链表归并排序核心流程
graph TD
A[原始链表] --> B[找到中间节点,一分为二];
B --> C[左子链表];
B --> D[右子链表];
C --> C1[递归拆分左子链表];
D --> D1[递归拆分右子链表];
C1 --> E{单节点或空};
D1 --> F{单节点或空};
E --是--> G[返回];
F --是--> H[返回];
G --> I[将有序的左右子链表合并];
H --> I;
I --> J[返回合并后的有序链表];
J --> A;
6.2 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h"
// 辅助函数:合并两个有序链表(我们在第一部分已经实现了)
// 再次贴出来,作为归并排序的一部分
ListNode* merge(ListNode* l1, ListNode* l2) {
ListNode dummy;
dummy.val = 0;
dummy.next = NULL;
ListNode* cur = &dummy;
while (l1 != NULL && l2 != NULL) {
if (l1->val < l2->val) {
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if (l1 != NULL) {
cur->next = l1;
}
if (l2 != NULL) {
cur->next = l2;
}
return dummy.next;
}
// 辅助函数:使用快慢指针找到链表的中间节点
ListNode* getMiddle(ListNode* head) {
if (head == NULL || head->next == NULL) {
return head;
}
ListNode* slow = head;
ListNode* fast = head->next; // 快指针从head->next开始,这样可以保证偶数个节点时,慢指针停在第一个中点
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
// 主函数:链表归并排序
// @param head ListNode*,链表头节点
// @return ListNode*,排序后的新链表头节点
ListNode* sortList(ListNode* head) {
// 总:递归分治,利用快慢指针拆分,再利用合并函数合二为一。
// 分:
// 边界条件:空链表或单个节点,已经是有序的
if (head == NULL || head->next == NULL) {
return head;
}
// 1. 拆分:找到中点,一分为二
ListNode* middle = getMiddle(head);
ListNode* next_head = middle->next;
middle->next = NULL; // 断开链表
// 2. 递归排序左右子链表
ListNode* sortedLeft = sortList(head);
ListNode* sortedRight = sortList(next_head);
// 3. 合并:将两个有序的子链表合并
// 这一步我们直接调用第一部分写好的merge函数
return merge(sortedLeft, sortedRight);
}
// 主函数,用于测试
int main() {
// 构造一个无序链表: 4 -> 2 -> 1 -> 3 -> NULL
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
head->val = 4;
head->next = (ListNode*)malloc(sizeof(ListNode));
head->next->val = 2;
head->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->val = 1;
head->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->next->val = 3;
head->next->next->next->next = NULL;
printf("原始链表: ");
ListNode* p = head;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL\n");
// 调用排序函数
ListNode* sortedHead = sortList(head);
printf("排序后链表: ");
p = sortedHead;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL\n");
// 内存清理...
return 0;
}
表格总结:链表归并排序的特点
|
特点 |
描述 |
|---|---|
|
时间复杂度 |
O(nlogn),非常高效。 |
|
空间复杂度 |
O(logn),递归深度导致的栈空间开销。 |
|
适用场景 |
适用于链表这种不支持随机访问的数据结构。 |
|
核心技巧 |
快慢指针用于拆分,双指针用于合并。 |
|
超越 |
虽然递归有栈溢出风险,但对于链表这种天然适合分治的数据结构,归并排序是当之无愧的“天花板”级别算法。在嵌入式中,可以考虑用自底向上的迭代归并排序,避免递归。 |
终章:链表内功,从入门到精通
-
第一篇,我们从零开始,重新认识了链表的本质,用C语言的内存和指针视角,彻底搞懂了反转和合并。
-
第二篇,我们用快慢指针解决了环形链表的终极难题,用小学算术的思想模拟了链表相加,并用归并排序实现了链表排序,彻底掌握了链表的高级应用。
希望这两篇文章,能让你对链表有一个全新的、更深入的理解。它不仅仅是面试题,更是贯穿于操作系统、文件系统、设备驱动等底层技术的核心思想。掌握它,你就掌握了C语言编程的精髓。
如果你觉得这两篇文章对你有启发,有帮助,请不要吝啬你的点赞、收藏、关注!
链表这门内功,我从“入门”到“走火入魔”,全靠这篇2万字神文!(下下篇) -(第三部分)
承前启后: 经过前两篇的洗礼,我们已经搞定了链表反转、合并、环形检测和排序。现在,是时候面对牛客、力扣面试场上那些让你头皮发麻、心跳加速的高频题了。本篇,我们将深入攻克回文、奇偶重排、以及两个版本的去重问题
第七章:BM13 回文链表——链表的对称之美
总: 回文链表,顾名思义,就是正着读和倒着读都一样的链表。它的核心挑战在于链表只能单向遍历,我们无法像数组那样用双指针从两头向中间靠拢。要解决这个问题,必须用一种巧妙的方法,将链表“对折”,然后进行比较。
7.1 思路分析:三步走,完美解决
要判断一个链表是否为回文,我们不能只用一个指针从头走到尾。最硬核、最节省空间的解法,可以总结为**“三步走”**:
-
快慢指针找中点: 使用我们在第二章学到的快慢指针技巧,找到链表的中间节点。
-
反转后半部分: 将从中间节点开始的后半部分链表进行反转。
-
双指针逐一比较: 使用两个指针,一个从原链表头开始,一个从反转后的后半部分链表头开始,逐一比较两个子链表的值是否相等。
表格总结:回文链表的核心步骤
|
步骤 |
目的 |
使用的工具 |
关键点 |
|---|---|---|---|
|
1. 寻找中点 |
将链表一分为二 |
快慢指针( |
快指针每次走两步,慢指针每次走一步,当快指针到达终点时,慢指针在中点 |
|
2. 反转后半部分 |
方便与前半部分比较 |
三指针迭代法 ( |
重用我们第一篇写好的 |
|
3. 比较 |
判断是否回文 |
双指针 |
一个从原 |
7.2 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h> // C99标准布尔类型
#include "linkedlist.h" // 引用之前的链表头文件
// 辅助函数:反转链表(从上一篇复制过来,以保证代码完整)
ListNode* reverseList(ListNode* head) {
ListNode* pre = NULL;
ListNode* cur = head;
while (cur != NULL) {
ListNode* next_node = cur->next;
cur->next = pre;
pre = cur;
cur = next_node;
}
return pre;
}
// 主函数:判断链表是否为回文结构
// @param head ListNode*,链表头节点
// @return bool,true表示是回文,false表示不是
bool isPail(ListNode* head) {
// 总:利用快慢指针找到中点,反转后半部分,然后进行比较。
// 分:
// 边界条件处理
if (head == NULL || head->next == NULL) {
return true; // 空链表或单节点链表,都是回文
}
// 第一步:快慢指针找中点
ListNode* slow = head;
ListNode* fast = head;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
// 此时slow指针指向中间节点。
// 如果链表总节点数为奇数,slow刚好是正中间的节点,
// fast->next会是NULL。
// 如果链表总节点数为偶数,slow是后半段的第一个节点。
// 第二步:反转后半部分
// 从slow开始,对后半部分链表进行反转
ListNode* secondHalf = reverseList(slow);
ListNode* firstHalf = head;
// 第三步:双指针逐一比较
// 遍历前半段和反转后的后半段,比较节点值
while (secondHalf != NULL) {
if (firstHalf->val != secondHalf->val) {
// 只要有一个不相等,就不是回文
return false;
}
firstHalf = firstHalf->next;
secondHalf = secondHalf->next;
}
// 如果循环结束了,说明所有节点都相等,是回文
return true;
}
// 主函数,用于测试
int main() {
// 构造一个回文链表: 1 -> 2 -> 3 -> 2 -> 1 -> NULL
ListNode* head1 = (ListNode*)malloc(sizeof(ListNode));
head1->val = 1;
head1->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->val = 2;
head1->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->val = 3;
head1->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->next->val = 2;
head1->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->next->next->val = 1;
head1->next->next->next->next->next = NULL;
printf("链表 1 -> 2 -> 3 -> 2 -> 1 是否为回文? %s\n", isPail(head1) ? "是" : "否");
// 构造一个非回文链表: 1 -> 2 -> 3 -> NULL
ListNode* head2 = (ListNode*)malloc(sizeof(ListNode));
head2->val = 1;
head2->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->val = 2;
head2->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->val = 3;
head2->next->next->next = NULL;
printf("链表 1 -> 2 -> 3 是否为回文? %s\n", isPail(head2) ? "是" : "否");
// 内存清理...(此处省略)
return 0;
}
超越: 这个解法的时间复杂度是O(n),空间复杂度是O(1),因为它只用了几个额外的指针变量。还有一种更直观但更“不硬核”的解法:遍历链表,把所有节点的值都存到栈里。然后再遍历一次链表,同时从栈里弹出一个值进行比较。这种方法空间复杂度为O(n),在嵌入式内存受限的场景下,显然不如我们上面这种“三步走”的解法。
第八章:BM14 链表的奇偶重排——拆分与重组的艺术
总: 这道题要求我们把一个链表中的奇数位节点和偶数位节点分开,然后将奇数位链表接在偶数位链表的后面,同时保持各自内部的相对顺序。这其实就是一次巧妙的链表拆分与重组。
8.1 思路分析:双头双尾,双管齐下
解决这个问题的关键在于,我们不能简单地遍历一次然后重新链接。一个更清晰的思路是,用两个“虚拟”的头节点,分别构建一个奇数链表和一个偶数链表。
核心步骤:
-
创建虚拟头: 创建两个
dummy节点,odd_dummy和even_dummy,分别作为奇数链表和偶数链表的头。 -
双指针遍历: 用两个指针
odd_cur和even_cur分别指向这两个虚拟头,然后遍历原链表。 -
交替链接: 在遍历过程中,交替地将原链表的节点链接到
odd_cur->next和even_cur->next上。 -
拼接: 遍历结束后,将
odd_cur的next指针指向even_dummy.next,完成奇偶链表的拼接。 -
返回: 返回
odd_dummy.next,即新链表的头。
ER图分析:奇偶重排核心流程
8.2 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h"
// 函数声明:链表的奇偶重排
// @param head ListNode*,链表头节点
// @return ListNode*,重排后新链表的头节点
ListNode* oddEvenList(ListNode* head) {
// 总:用两个虚拟头和两个指针,分别构建奇偶链表,最后再拼接。
// 分:
// 边界条件:空链表,单节点或双节点链表无需重排
if (head == NULL || head->next == NULL || head->next->next == NULL) {
return head;
}
// 初始化奇偶虚拟头节点
ListNode odd_dummy;
ListNode even_dummy;
odd_dummy.val = 0;
odd_dummy.next = NULL;
even_dummy.val = 0;
even_dummy.next = NULL;
// 初始化奇偶当前指针
ListNode* odd_cur = &odd_dummy;
ListNode* even_cur = &even_dummy;
// 遍历原链表,进行奇偶拆分
ListNode* p = head;
int count = 1;
while (p != NULL) {
if (count % 2 == 1) { // 奇数位
odd_cur->next = p;
odd_cur = odd_cur->next;
} else { // 偶数位
even_cur->next = p;
even_cur = even_cur->next;
}
p = p->next;
count++;
}
// 关键步骤:处理链表末尾
// 1. 确保偶数链表的末尾指向NULL,防止形成环
even_cur->next = NULL;
// 2. 将奇数链表的尾部指向偶数链表的头部
odd_cur->next = even_dummy.next;
// 总:
// 返回奇数链表的真正头节点
return odd_dummy.next;
}
// 主函数,用于测试
int main() {
// 构造一个链表: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> NULL
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
head->val = 1;
head->next = (ListNode*)malloc(sizeof(ListNode));
head->next->val = 2;
head->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->val = 3;
head->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->next->val = 4;
head->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->next->next->val = 5;
head->next->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head->next->next->next->next->next->val = 6;
head->next->next->next->next->next->next = NULL;
printf("原始链表: ");
ListNode* p = head;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL\n");
ListNode* newHead = oddEvenList(head);
printf("重排后链表: ");
p = newHead;
while(p != NULL) {
printf("%d -> ", p->val);
p = p->next;
}
printf("NULL (奇偶重排)\n");
// 内存清理...
return 0;
}
第九章:BM15 & BM16 删除重复元素——简单与复杂的双重考验
总: 这两道题都涉及到对有序链表的去重操作,但要求不同,解法也截然不同。一个只保留一个,另一个全部删除。这正是面试官考察你思维严谨性的绝佳机会。
9.1 BM15 思路分析:只保留一个重复元素
核心思想: 这道题很简单,我们只需要用一个指针p遍历链表。如果p->val和p->next->val相等,说明p->next是重复的,我们直接跳过它。
// BM15:删除有序链表中重复的元素-I
// 核心代码片段:
// if (p->val == p->next->val) {
// p->next = p->next->next;
// } else {
// p = p->next;
// }
9.2 BM16 思路分析:全部删除重复元素
核心思想: 这道题更复杂,因为可能连续有多个重复元素,且这些重复元素都不能保留。这时,一个指针就不够用了。我们需要:
-
虚拟头节点: 同样是神器,它能帮我们处理头节点就是重复元素的情况。
-
双指针:
-
一个指针
p作为“前驱”,用于构建新链表。 -
另一个指针
cur用于遍历和查找重复元素。
-
-
核心逻辑:
-
当
cur的下一个节点不为空且与cur值相等时,cur不断前进,找到所有连续重复元素的末尾。 -
然后,将
p->next直接指向cur的下一个节点,跳过整个重复段。 -
如果
cur和cur->next值不相等,说明cur不是重复元素,p指针前进,将cur加入新链表。
-
9.3 C语言代码实现与逐行注释
#include <stdio.h>
#include <stdlib.h>
#include "linkedlist.h"
// 函数声明:删除有序链表中重复的元素-I (保留一个)
// @param head ListNode*,链表头节点
// @return ListNode*,去重后新链表的头节点
ListNode* deleteDuplicates_I(ListNode* head) {
// 总:用一个指针遍历,遇到重复元素就跳过下一个节点。
// 分:
if (head == NULL) {
return head;
}
ListNode* p = head;
while (p != NULL && p->next != NULL) {
// 如果当前节点的值和下一个节点的值相等
if (p->val == p->next->val) {
// 直接跳过下一个节点,相当于删除了重复元素
p->next = p->next->next;
} else {
// 如果不相等,p指针正常前进
p = p->next;
}
}
// 总:
return head;
}
// 函数声明:删除有序链表中重复的元素-II (全部删除)
// @param head ListNode*,链表头节点
// @return ListNode*,去重后新链表的头节点
ListNode* deleteDuplicates_II(ListNode* head) {
// 总:用一个虚拟头和双指针,遇到重复段就直接跳过。
// 分:
if (head == NULL) {
return head;
}
ListNode dummy;
dummy.val = 0; // 虚拟头节点,值不重要
dummy.next = head;
ListNode* p = &dummy; // 前驱指针,指向新链表的尾部
ListNode* cur = head; // 遍历指针
while (cur != NULL && cur->next != NULL) {
// 如果cur和cur的下一个节点值相等,说明找到了一个重复段
if (cur->val == cur->next->val) {
// 找到重复段的末尾
while (cur->next != NULL && cur->val == cur->next->val) {
cur = cur->next;
}
// 此时cur指向重复段的最后一个节点
// p的下一个节点直接指向重复段的下一个节点
p->next = cur->next;
// cur前进到新的位置,继续遍历
cur = cur->next;
} else {
// 如果没有重复,p和cur都正常前进
p = p->next;
cur = cur->next;
}
}
// 总:
return dummy.next;
}
// 主函数,用于测试
int main() {
// BM15测试: 1 -> 1 -> 2 -> 3 -> 3 -> NULL
ListNode* head1 = (ListNode*)malloc(sizeof(ListNode));
head1->val = 1;
head1->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->val = 1;
head1->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->val = 2;
head1->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->next->val = 3;
head1->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head1->next->next->next->next->val = 3;
head1->next->next->next->next->next = NULL;
ListNode* newHead1 = deleteDuplicates_I(head1);
printf("BM15测试,去重后: ");
ListNode* p1 = newHead1;
while(p1 != NULL) {
printf("%d -> ", p1->val);
p1 = p1->next;
}
printf("NULL (结果: 1 -> 2 -> 3)\n");
// BM16测试: 1 -> 2 -> 2 -> 3 -> 3 -> 3 -> 4 -> NULL
ListNode* head2 = (ListNode*)malloc(sizeof(ListNode));
head2->val = 1;
head2->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->val = 2;
head2->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->val = 2;
head2->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->next->val = 3;
head2->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->next->next->val = 3;
head2->next->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->next->next->next->val = 3;
head2->next->next->next->next->next->next = (ListNode*)malloc(sizeof(ListNode));
head2->next->next->next->next->next->next->val = 4;
head2->next->next->next->next->next->next->next = NULL;
ListNode* newHead2 = deleteDuplicates_II(head2);
printf("BM16测试,去重后: ");
ListNode* p2 = newHead2;
while(p2 != NULL) {
printf("%d -> ", p2->val);
p2 = p2->next;
}
printf("NULL (结果: 1 -> 4)\n");
// 内存清理...
return 0;
}
总结与超越: BM15和BM16的区别,仅仅是**“保留一个”和“全部删除”。但正是这一个细微的差别,让我们的解法从一个指针的简单遍历,变成了两个指针的精妙配合,并再次凸显了虚拟头节点**的重要性。这正是编程的魅力所在:问题千变万化,但核心思想往往是相通的。
终章:链表这门内功,算是“走火入魔”了
-
第一篇,我们从C语言的内存和指针视角,彻底搞懂了链表反转和合并。
-
第二篇,我们用快慢指针解决了环形链表的终极难题,用小学算术的思想模拟了链表相加,并用归并排序实现了链表排序。
-
第三篇,我们用三步走策略破解了回文链表,用双头双尾重排了奇偶链表,并深入对比了两种去重问题的解法。
至此,链表这门内功心法,从最基础的入门,到面试中的高级应用,我们已经全部啃完了。希望这三篇神文,能让你对链表有一个全新的、更深入的理解。它不仅仅是面试题,更是贯穿于操作系统、文件系统、设备驱动等底层技术的核心思想。掌握它,你就掌握了C语言编程的精髓。
如果你觉得这三篇文章对你有启发,有帮助,请不要吝啬你的点赞、收藏、关注!
2025.8.1 晚11:31
附录:1200行源码>>>
1、3 反转 + 合并链表?
过于简单,略过.....
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
#include <stdio.h>
struct ListNode
{
int val;
struct ListNode *next;
};
struct ListNode *ReverseList(struct ListNode *head)
{
// write code here
struct ListNode *pre = NULL;
struct ListNode *p = head;
struct ListNode *pnext = head->next;
while (p != NULL)
{
struct ListNode* temp = p->next;
p->next = pre;
pre = p ;
p = temp ;
}
return pre ;
}
// /**
// * struct ListNode {
// * int val;
// * struct ListNode *next;
// * };
// */
// /**
// * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
// *
// *
// * @param pHead1 ListNode类
// * @param pHead2 ListNode类
// * @return ListNode类
// */
// struct ListNode *Merge(struct ListNode *pHead1, struct ListNode *pHead2)
// {
// // write code here
// if (pHead1 == NULL)
// {
// return pHead2;
// }
// if (pHead2 == NULL)
// {
// return pHead1;
// }
// struct ListNode p0 = {1, NULL};
// struct ListNode *cur = &p0;
// while (pHead1 != NULL && pHead2 != NULL)
// {
// if (pHead1->val < pHead2->val)
// {
// cur->next = pHead1;
// pHead1 = pHead1->next;
// }
// else
// {
// cur->next = pHead2;
// pHead2 = pHead2->next;
// }
// cur = cur->next;
// }
// if (pHead1 == NULL)
// {
// cur->next = pHead2;
// }
// else
// {
// cur->next = pHead1;
// }
// return p0.next;
// }
// int main()
// {
// return 0;
// }
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead1 ListNode类
* @param pHead2 ListNode类
* @return ListNode类
*/
// # 3刷
struct ListNode *Merge(struct ListNode *pHead1, struct ListNode *pHead2)
{
// write code here
if (pHead1 == NULL)
{
return pHead2;
}
if (pHead2 == NULL)
{
return pHead1;
}
struct ListNode p0;
p0.val = 0;
p0.next = pHead1->val < pHead2->val ? pHead1 : pHead2;
struct ListNode *p = &p0;
// p = &p0;
while (pHead1 != NULL && pHead2 != NULL)
{
if (pHead1->val < pHead2->val)
{
p->next = pHead1;
pHead1 = pHead1->next;
}
else
{
p->next = pHead2;
pHead2 = pHead2->next;
}
p = p->next;
}
if (pHead1 != NULL)
{
p->next = pHead1;
}
if (pHead2 != NULL)
{
p->next = pHead2;
}
return p0.next;
}
2 指定区间内反转?
待3刷ing!
4 BM5 合并k个链表?
hard!!!
5 是否有环?
思路:fast指针+slow指针,如果碰到了,就是有!
// #include <stdbool.h>
// /**
// * struct ListNode {
// * int val;
// * struct ListNode *next;
// * };
// */
// /**
// *
// * @param head ListNode类
// * @return bool布尔型
// */
// #include <stdbool.h>
// bool hasCycle(struct ListNode *head)
// {
// // write code here
// if (head == NULL)
// {
// return false;
// }
// if(head->next ==NULL){
// return false;
// }
// struct ListNode *fast = head;
// struct ListNode *slow = head;
// //#self !vip
// //在这里为什么是fast的两次都要考虑
// while (fast != NULL && fast->next!= NULL)
// {
// fast = fast->next->next ;
// slow =slow->next ;
// if(fast ==slow){
// return true;
// }
// }
// return false;
// }
// #3刷
// #include <stdbool.h>
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param head ListNode类
* @return bool布尔型
*/
#include <stdbool.h>
bool hasCycle(struct ListNode *head)
{
// write code here
struct ListNode *slow = head;
struct ListNode *fast = head;
if (head == NULL)
return head;
while (fast->next != NULL && fast->next->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
if (slow == fast)
{
return true;
}
}
return false;
}
6 环的入口结点?
思路:如果有,那么flag标记+返回整个fast==slow的地方!
// /**
// * struct ListNode {
// * int val;
// * struct ListNode *next;
// * };
// */
// /**
// * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
// *
// *
// * @param pHead ListNode类
// * @return ListNode类
// */
// struct ListNode *EntryNodeOfLoop(struct ListNode *pHead)
// {
// // write code here
// // #self !!!vip
// //!!!vip 自己写的时候为什么能翻这种低级错误?&还是|
// // if (pHead == NULL || pHead->next == NULL)
// // {
// // return NULL;
// // }
// // struct ListNode *fast = pHead;
// // struct ListNode *slow = pHead;
// // while (fast != NULL && fast->next != NULL)
// // {
// // fast = fast->next->next;
// // slow = slow->next;
// // if (fast == slow)
// // {
// // return fast;
// // }
// // }
// // return NULL;
// struct ListNode* p = pHead;
// while(p!=NULL){
// if(p->val>0){
// p->val = 0-p->val;
// p = p->next;
// }
// else{
// p ->val= -(p->val );
// return p ;
// }
// }
// return NULL;
// }
// #!!!vip3刷
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @return ListNode类
*/
struct ListNode *EntryNodeOfLoop(struct ListNode *pHead)
{
// write code here+
if (pHead == NULL)
return pHead;
if (pHead->next == NULL)
{
return NULL;
}
struct ListNode *fast = pHead;
struct ListNode *slow = pHead;
int flag = 0;
while (fast->next != NULL && fast->next->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
if (fast == slow)
{
flag = 1;
break;
}
// if (fast == NULL || fast->next == NULL)
// {
// flag = 0;
// return NULL;
// }
// #vip 永远不会被触发
}
if (flag == 1)
{
slow = pHead;
while (slow != fast)
{
slow = slow->next;
fast = fast->next;
}
return fast;
}
if (flag == 0)
{
return NULL;
}
// return NULL;
}
7 倒数k个节点?
思路:先走k下,然后返回!
// /**
// * struct ListNode {
// * int val;
// * struct ListNode *next;
// * };
// */
// /**
// * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
// *
// *
// * @param pHead ListNode类
// * @param k int整型
// * @return ListNode类
// */
// struct ListNode *FindKthToTail(struct ListNode *pHead, int k)
// {
// // write code here
// if (k <= 0 || pHead == NULL)
// {
// return NULL;
// }
// struct ListNode *pLast = pHead;
// for (int i = 0; i < k - 1; i++)
// {
// if (pLast->next == NULL)
// {
// return NULL;
// }
// pLast = pLast->next;
// }
// struct ListNode *p = pHead;
// while (pLast!=NULL && pLast->next != NULL)
// {
// pLast = pLast->next;
// p = p->next;
// }
// return p;
// }
// # !!!!!vip 3刷
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode *FindKthToTail(struct ListNode *pHead, int k)
{
// write code here
struct ListNode *slow = pHead;
struct ListNode *fast = pHead;
int len = 0;
while (fast != NULL)
{
fast = fast->next;
len++;
}
if (len < k)
{
return NULL;
}
fast = pHead;
int i = 0;
while (i < k)
{
fast = fast->next;
i++;
}
while (fast != NULL)
{
slow = slow->next;
fast = fast->next;
}
return slow;
}
8 第一个公共节点?
思路:交叉遍历!!
// /**
// * struct ListNode {
// * int val;
// * struct ListNode *next;
// * };
// */
// /**
// *
// * @param pHead1 ListNode类
// * @param pHead2 ListNode类
// * @return ListNode类
// */
// struct ListNode *FindFirstCommonNode(struct ListNode *pHead1, struct ListNode *pHead2)
// {
// // write code here
// struct ListNode *p1 = pHead1;
// struct ListNode *p2 = pHead2;
// if (pHead1 == NULL)
// return pHead1;
// if (pHead2 == NULL)
// return pHead2;
// if (pHead1 == pHead2)
// {
// return pHead1;
// }
// // #self
// // 当没有公共节点是不是p1、p2同时为空,或者p1 !=p2
// while (1)
// {
// if (p1 == p2)
// {
// return p1;
// }
// if (p1->next != NULL)
// {
// p1 = p1->next;
// }
// else
// {
// p1 = pHead2;
// }
// if (p2->next != NULL)
// {
// p2 = p2->next;
// }
// else
// {
// p2 = pHead1;
// }
// if (p1 == pHead2 && p2 == pHead1)
// {
// return NULL;
// }
// }
// return NULL;
// }
// #!!!vip 3刷
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pHead1 ListNode类
* @param pHead2 ListNode类
* @return ListNode类
*/
struct ListNode *FindFirstCommonNode(struct ListNode *pHead1, struct ListNode *pHead2)
{
// write code here
if (pHead1 == NULL || pHead2 == NULL)
{
return NULL;
}
struct ListNode *p1 = pHead1;
struct ListNode *p2 = pHead2;
while (p1 != p2)
{
if (p1 == NULL && p2 == NULL)
{
break;
}
p1 = p1 == NULL ? pHead2 : p1->next;
p2 = p2 == NULL ? pHead1 : p2->next;
}
if (p1 == p2)
{
return p1;
}
else
{
return NULL;
}
// return NULL;
}
9 链表相加?
思路:老模板,直接用!reverse+ newnode链接到cur上!
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head1 ListNode类
* @param head2 ListNode类
* @return ListNode类
*/
// struct ListNode *reverse(struct ListNode *head)
// {
// struct ListNode *p = head;
// struct ListNode *pre = NULL;
// struct ListNode *pNext = head->next;
// while (p != NULL)
// {
// pNext = p->next;
// p->next = pre;
// pre = p;
// p = pNext;
// }
// return pre;
// }
// struct ListNode *
// addInList(struct ListNode *head1, struct ListNode *head2)
// {
// // write code here
// struct ListNode *l1 = reverse(head1);
// struct ListNode *l2 = reverse(head2);
// // 这个题目老师做不对:#self :问题在于没有一个通用模板!
// // 画一个图:
// struct ListNode temp = {0, NULL};
// struct ListNode *p = &temp;
// int flag = 0;
// while (l1 || l2 || flag != 0)
// {
// int v1 = (l1 == NULL )? 0 : l1->val;
// int v2 = (l2 == NULL )? 0 : l2->val;
// int sum = v1 + v2 + flag;
// flag = sum / 10;
// struct ListNode *newnode = (struct ListNode *)malloc(sizeof(struct ListNode));
// newnode->val = sum % 10;
// newnode->next = NULL;
// p->next = newnode;
// p = p->next;
// l1 = (l1== NULL) ? NULL : l1->next;
// l2 = (l2== NULL) ? NULL : l2->next;
// }
// struct ListNode *res = reverse(temp.next);
// return res;
// }
// #!!!vip 3刷
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head1 ListNode类
* @param head2 ListNode类
* @return ListNode类
*/
struct ListNode *reverse(struct ListNode *head)
{
struct ListNode *pre = NULL;
struct ListNode *p = head;
struct ListNode *pNext;
while (p != NULL)
{
pNext = p->next;
p->next = pre;
pre = p;
p = pNext;
}
return pre;
}
struct ListNode *addInList(struct ListNode *head1, struct ListNode *head2)
{
// write code here
if (head1 == NULL)
return head2;
if (head2 == NULL)
return head1;
struct ListNode *p1 = reverse(head1);
struct ListNode *p2 = reverse(head2);
int sum = 0, flag = 0, res = 0;
struct ListNode pNewHead;
struct ListNode *cur = &pNewHead;
while (p1 != NULL || p2 != NULL || flag != 0)
{
int val1 = p1 == NULL ? 0 : p1->val;
int val2 = p2 == NULL ? 0 : p2->val;
sum = val1 + val2 + flag;
res = sum % 10;
flag = sum / 10;
struct ListNode *tempNode = (struct ListNode *)malloc(sizeof(struct ListNode));
tempNode->val = res;
tempNode->next = NULL;
cur->next = tempNode;
cur = cur->next;
if (p1 != NULL)
p1 = p1->next;
if (p2 != NULL)
p2 = p2->next;
}
return reverse(pNewHead.next);
}
10 单链表排序?
思路:归并之魂!!!
// struct ListNode
// {
// int val;
// struct ListNode *next;
// };
// /**
// * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
// *
// *
// * @param head ListNode类 the head node
// * @return ListNode类
// */
// struct ListNode *merge(struct ListNode *left, struct ListNode *right)
// {
// struct ListNode temp = {0, NULL};
// struct ListNode *p = &temp;
// while (left != NULL && right != NULL)
// {
// if (left->val < right->val)
// {
// p->next = left;
// left = left->next;
// }
// else
// {
// p->next = right;
// right = right->next;
// }
// p = p->next;
// }
// if (left == NULL)
// {
// p->next = right;
// }
// if (right == NULL)
// {
// p->next = left;
// }
// return temp.next;
// }
// struct ListNode *sortInList(struct ListNode *head)
// {
// // write code here
// if (head == NULL || head->next == NULL)
// {
// return head;
// }
// struct ListNode *slow = head;
// // struct ListNode *mid = NULL;
// struct ListNode *fast = head->next;
// while (fast != NULL && fast->next != NULL)
// {
// slow = slow->next;
// fast = fast->next->next;
// }
// struct ListNode *mid = slow->next;
// slow->next = NULL;
// // struct ListNode *right = mid;
// struct ListNode *left = sortInList(head);
// struct ListNode* right = sortInList(mid);
// return merge(left, right);
// /* data */
// }
// # 3刷 #!!!vip
struct ListNode
{
int val;
struct ListNode *next;
};
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类 the head node
* @return ListNode类
*/
struct ListNode *mergeList(struct ListNode *left, struct ListNode *right)
{
struct ListNode p0;
p0.val = 0;
p0.next = NULL;
struct ListNode *p = &p0;
while (left != NULL && right != NULL)
{
if (left->val < right->val)
{
p->next = left;
left = left->next;
}
else
{
p->next = right;
right = right->next;
}
p = p->next;
}
if (left != NULL)
{
p->next = left;
}
if (right != NULL)
{
p->next = right;
}
return p0.next;
}
struct ListNode *
sortInList(struct ListNode *head)
{
// write code here
if (head == NULL || head->next == NULL)
{
return head;
}
struct ListNode *slow = head;
// #vip 这里是学艺不精 fast应该是第二个开始
struct ListNode *fast = head->next;
while (fast != NULL && fast->next != NULL)
{
fast = fast->next->next;
slow = slow->next;
}
struct ListNode *rightHead = slow->next;
// #vip 学艺不精 没有切断前后的链接,导致问题出现,会一直这么走下去,想象一下,:123456 456 两个去链接!!!vip
slow->next = NULL;
struct ListNode *left = sortInList(head);
struct ListNode *right = sortInList(rightHead);
return mergeList(left, right);
}
11 是否回文?
思路: 1234567,举个栗子:left + right找到之后,两边分别访问对比!
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
struct ListNode
{
int val;
struct ListNode *next;
};
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类 the head
* @return bool布尔型
*/
struct ListNode *reverse(struct ListNode *head)
{
struct ListNode *pre = NULL;
struct ListNode *p = head;
struct ListNode *pNext = NULL;
while (p != NULL)
{
pNext = p->next;
p->next = pre;
pre = p;
p = pNext;
}
return pre;
}
bool isPail(struct ListNode *head)
{
// write code here
// if (head == NULL || head->next == NULL)
// {
// retrun false;
// }
// struct ListNode *slow = head;
// struct ListNode *fast = head;
// while (fast != NULL && fast->next != NULL)
// {
// slow = slow->next;
// fast = fast->next->next;
// }
// struct ListNode *mid = slow;
// struct ListNode *right = reverse(mid);
// struct p1 = head;
// struct p2 = right;
// while (p2 != NULL)
// {
// if (p1->val != p2->val)
// {
// return false;
// }
// p1 = p1->next;
// p2 = p2->next;
// }
// retrun true;
// #3刷
struct ListNode *slow = head;
struct ListNode *fast = head;
if (head == NULL || head->next == NULL)
{
return true;
}
while (fast != NULL && fast->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
}
struct ListNode *p = head;
struct ListNode *q = reverse(slow);
while (q != NULL)
{
if (p->val != q->val)
{
return false;
}
p = p->next;
q = q->next;
}
return true;
}
12 奇偶重排?
思路:ji + ou指针互相交叉遍历!!!
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
// struct ListNode *oddEvenList(struct ListNode *head)
// {
// // write code here
// //
// if (!head || !head->next)
// {
// return head;
// }
// struct ListNode *odd = head;
// struct ListNode *even = head->next;
// struct ListNode *evenHead = head->next;
// while (even && even->next != NULL)
// {
// odd->next = even->next;
// odd = odd->next;
// even->next = odd->next;
// even = even->next;
// }
// odd->next = evenHead;
// return head;
// }
// #3刷 #vip3
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
struct ListNode *oddEvenList(struct ListNode *head)
{
// write code here
if (head == NULL || haed->next == NULL)
{
head;
}
struct ListNode *ji = head;
struct ListNode *ou = head->next;
struct ListNode *ouHead = head->next;
while (ou != NULL && ou->next != NULL)
{
ji->next = ou->next;
ji = ji->next;
ou->next = ji->next;
ou = ou->next;
}
ji->next = ouHead;
return head;
}
13 去掉重复的节点?
思路: 1 1 2 3 4 4 4 4 45 6 > 123456
跳过重复的!
// struct ListNode
// {
// int val;
// struct ListNode *next;
// };
// /**
// * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
// *
// *
// * @param head ListNode类
// * @return ListNode类
// */
// struct ListNode *deleteDuplicates(struct ListNode *head)
// {
// // write code here
// if(head==NULL){
// return head;
// }
// if (head->next == NULL)
// {
// return head;
// }
// struct ListNode* p0 = head;
// struct ListNode *p = head;
// struct ListNode *q = head;
// int zhi = 0;
// while (p!=NULL)
// {
// zhi = p->val;
// while(q->next !=NULL && q->next->val==p->val){
// q = q->next;
// }
// p->next = q->next;
// p = p->next;
// q = q->next ;
// }
// return p0;
// }
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @return ListNode类
*/
struct ListNode *deleteDuplicates(struct ListNode *head)
{
// write code here
if (head == NULL || head->next == NULL)
{
return head;
}
struct ListNode *p = head;
struct ListNode *q = head->next;
while (p != NULL)
{
q = p->next;
while (q!=NULL && q->val == p->val )
{
q = q->next;
}
p->next = q;
p = q;
}
return head;
}
14 去掉重复的2?
思路: 1 1 1 3 4 5 5 5 5 6 8 > 3 4 6 8
undone 未解决


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









