




布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,主要用于测试一个元素是否是某集合的成员。它的特点是可能会误判(即认为某元素在集合中,但实际上并不在),但不会漏判(即不可能认为一个集合中的元素不在集合中)。
工作原理
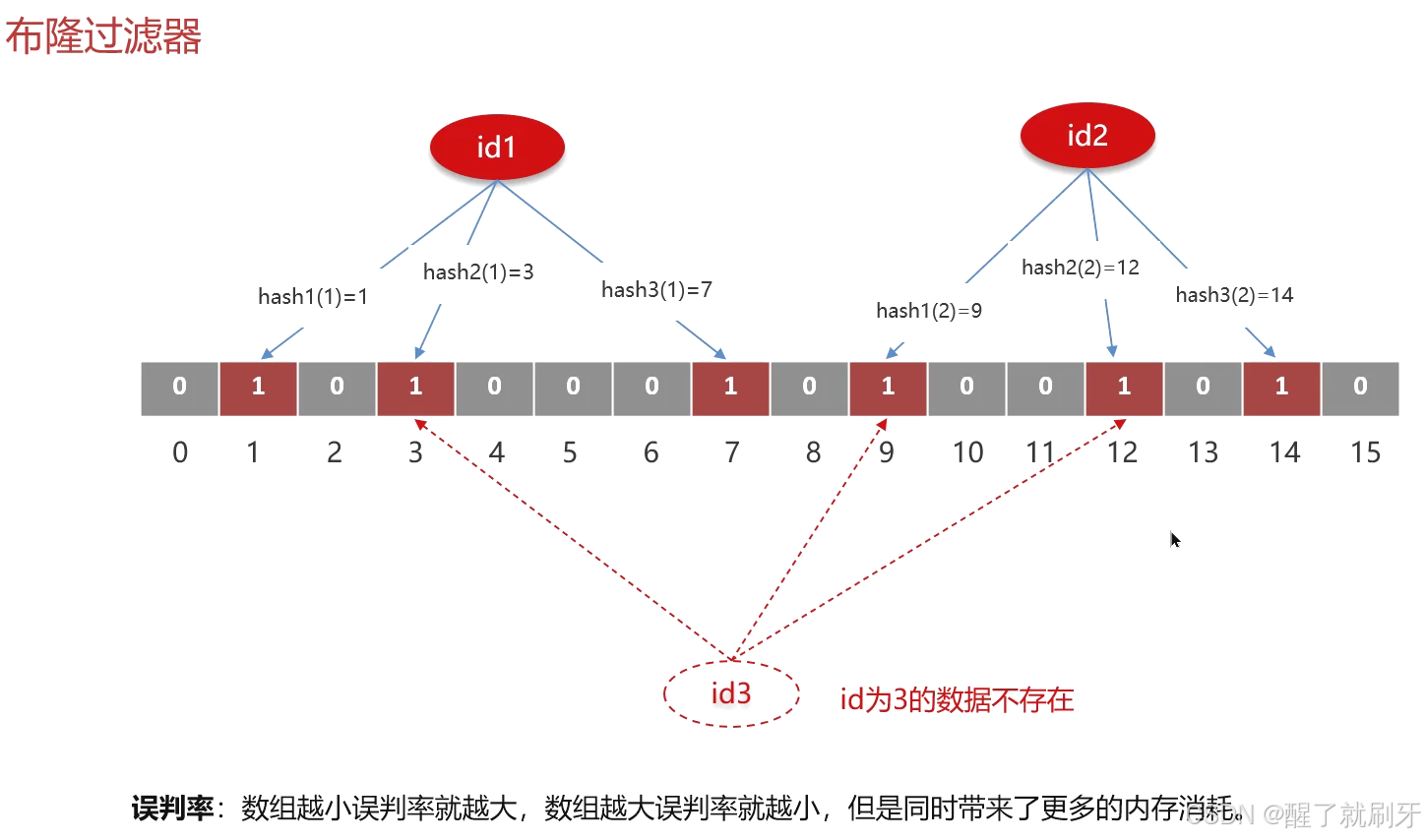
布隆过滤器通过使用多个哈希函数和一个位数组来存储信息。其主要步骤如下:
- 初始化:创建一个位数组,所有位初始化为0。
- 添加元素:对于每个要加入集合的元素,布隆过滤器通过多个哈希函数生成多个哈希值,然后在位数组的对应位置将这些值设为1。
- 查询元素:要检查某个元素是否在集合中,布隆过滤器通过相同的哈希函数计算该元素的哈希值,并检查位数组中对应位置的值。如果所有位置都是1,可能是集合中有该元素;如果有任何位置是0,则肯定不在集合中。
特点
- 空间效率高:相比传统的集合或哈希表,布隆过滤器占用的内存要少得多。
- 查询速度快:布隆过滤器查询操作是常数时间复杂度(O(k),k为哈希函数个数)。
- 误判率:布隆过滤器会出现误判,指示一个元素可能在集合中。误判率与位数组的大小、哈希函数的数量、添加的元素数量等因素有关。
- 不能删除元素:标准的布隆过滤器不能删除元素,删除元素可能会影响其他已经存储的元素的正确性。虽然有变种如“计数布隆过滤器”能够实现删除,但通常需要更多的空间。
应用场景
布隆过滤器常用于以下场景:
- 缓存系统:用来快速判断某个数据是否存在于缓存中,减少不必要的查询。
- 去重:在大数据流处理中,布隆过滤器常用于去重操作。
- 网络爬虫:判断某个网页是否已被访问过,以避免重复爬取。
- 数据库查询优化:减少数据库中的不必要查询,减少数据库负载。
变种
- 计数布隆过滤器:支持删除元素,但代价是使用多个计数器代替位数组。
- 分层布隆过滤器:将多个布隆过滤器组合起来,用于减少误判率。
布隆过滤器是一个非常有用的工具,尤其适合大规模数据处理中的成员查询和去重操作。

















 167万+
167万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









