 异步多模态摘要方法及数据集研究
异步多模态摘要方法及数据集研究





文章汉化系列目录
摘要
随着互联网多媒体数据传输的快速增加,来自文本、图像、音频和视频的多模态摘要(MMS)变得愈加重要。在本研究中,我们提出了一种提取式多模态摘要方法,该方法能够根据与特定主题相关的文档、图像、音频和视频集合自动生成文本摘要。关键思想是弥合多模态内容之间的语义差距。对于音频信息,我们设计了一种选择性使用其转录文本的方法。对于视觉信息,我们通过神经网络学习文本和图像的联合表示。最后,考虑到所有多模态方面,我们通过预算化优化子模函数,最大化摘要的突出性、非冗余性、可读性和覆盖度,从而生成文本摘要。我们进一步推出了一个包含英文和中文的MMS语料库,并已公开发布。基于该数据集的实验结果表明,我们的方法优于其他竞争基准方法。
引言
近年来,多媒体数据(包括文本、图像、音频和视频)激增,这使得用户很难高效地获取重要信息。多模态摘要(MMS)可以为用户提供文本摘要,帮助他们在短时间内获取多媒体数据的要点,而无需从头到尾阅读文档或观看视频。现有的与MMS相关的应用包括会议记录总结(Erol等,2003;Gross等,2000)、体育视频总结(Tjondronegoro等,2011;Hasan等,2013)、电影总结(Evangelopoulos等,2013;Mademlis等,2016)、图像故事情节总结(Wang等,2012)、时间线总结(Wang等,2016b)以及社交多媒体总结(Del Fabro等,2012;Bian等,2013;Schinas等,2015;Bian等,2015;Shah等,2015,2016)。在总结会议记录、体育视频和电影时,这些视频通常包含同步的语音、视觉和字幕。对于图像故事情节的总结,输入是包含文本描述的一组图像。这些应用都没有关注总结包含关于一般主题的异步信息的多媒体数据。
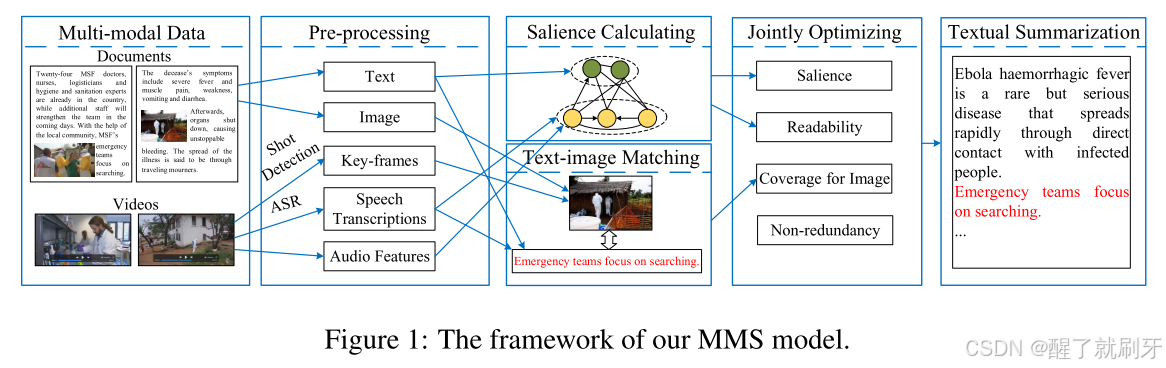
在本文中(如图1所示),我们提出了一种方法,从一组关于同一主题的异步文档、图像、音频和视频中生成文本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









