



一、什么是RAG切片
给定一个场景,我们有一本非常厚的百科全书(就像公司的员工手册文档或公司知识库)。同时,我们有一个超级聪明的AI助手,他知识渊博,但有个弊端,他一次只能看一页纸,而且给他哪一页,他才能看哪一页。他做不到直接从整本厚厚的书里去寻找答案。
RAG 的切片策略,就是帮我们把这本厚厚的书,提前拆分成一页一页、或者一段一段的“小纸片”,并给这些小纸片做好详细的“目录”和“标签”,做成一个高效的“索引”或者“目录”,当AI助手需要回答问题时,它不需要去翻整本书,而是先快速查阅“目录”,找到最相关的那么几张小纸片(比如第45页的“考勤制度”和第46页的“福利政策”),然后你只把这几张纸递给它。AI助手看着这几张纸上的内容,就能给你一个非常精准的答案。不同的切片策略,就是做“目录”的不同方法。
所以,到底什么是RAG切片?
RAG切片就是把一份长长的文档(如PDF、Word),合理地切割成一个个小块(Chunks)的过程。这个过程是整个RAG系统的基石,它直接决定了后续检索和生成答案的质量。
二、是必须要切片吗
是的,由于以下原因,切片是势必要进行的过程:
- AI的“记忆力”有限:由于上下文窗口限制,AI一次只能看有限的内容,比如几千个字。如果不切片,整本书塞给它,它根本处理不了。
- 精准检索的需要:如果不进行切片,整本书就是一个巨大的整体。当你要搜索“年假”时,搜索引擎无法知道具体内容在书的哪一部分,很可能返回无关信息。切片后,搜索引擎可以精准地定位到包含“年假”关键词的那些小块。
三、几种切片策略
1.改进的固定长度切片
1.1 详细说明
这种方法在简单固定长度切片的基础上,增加了对语义完整性的基本保留。
- 核心思想:依然预设一个目标长度,但切割点不再是一个简单的字符索引,而是寻找最接近目标长度的自然语言边界(如句号、问号、换行符等),从而避免在句子中间切断。
- 工作流程:
- 将文本按段落或双换行符等主要分隔符进行初步分割。
- 对于每个初步分割出的段,如果其长度远超目标 chunk_size,则再使用句子级别的分隔符('. ', '? ', '! ')进行二次分割。
- 确保每个最终的块大小接近 chunk_size,且起始和结束都在完整的句子边界上。
- 优点:在保持计算高效的同时,显著减少了切碎句子的情况,比朴素固定切片效果好很多。
- 缺点:仍然无法处理复杂的语义单元(如一个表格、一个代码块、一个多句子的论点)。
- 适用场景:通用文本,是简单固定切片和复杂语义切片之间的一个良好折衷方案。
1.2 演示示例
"""
固定长度切片策略
在句子边界进行切分,避免切断句子
"""
def improved_fixed_length_chunking(text, chunk_size=512, overlap=50):
"""改进的固定长度切片 - 在句子边界切分"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# 尝试在句子边界切分
if end < len(text):
# 寻找最近的句子结束符
for i in range(end, max(start, end - 100), -1):
if text[i] in '.!?。!?':
end = i + 1
break
chunk = text[start:end]
if len(chunk.strip()) > 0:
chunks.append(chunk.strip())
start = end - overlap
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析结果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 统计信息:")
print(f" - 切片数量: {len(chunks)}")
print(f" - 平均长度: {avg_length:.1f} 字符")
print(f" - 最短长度: {min_length} 字符")
print(f" - 最长长度: {max_length} 字符")
print(f" - 长度方差: {max_length - min_length} 字符")
print(f"\n📝 切片内容:")
for i, chunk in enumerate(chunks, 1):
print(f" 块 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
print()
# 测试文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""
if __name__ == "__main__":
print("🎯 固定长度切片策略测试")
print(f"📄 测试文本长度: {len(text)} 字符")
# 使用改进的固定长度切片
chunks = improved_fixed_length_chunking(text, chunk_size=300, overlap=50)
print_chunk_analysis(chunks, "固定长度切片")
输出结果:
🎯 固定长度切片策略测试
📄 测试文本长度: 324 字符
============================================================
📋 固定长度切片
============================================================
📊 统计信息:
- 切片数量: 2
- 平均长度: 186.0 字符
- 最短长度: 80 字符
- 最长长度: 292 字符
- 长度方差: 212 字符
📝 切片内容:
块 1 (292 字符):
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日
票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需
认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。
块 2 (80 字符):
需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役
军人凭证件享8折,需至少提前3天登记审批。

2.语义切片
2.1 详细说明
这种方法基于内容本身的含义进行切割,是内容感知的。
- 核心思想:通过计算句子或段落之间的语义相似度来识别主题的转折点。当相邻文本单元的嵌入向量相似度突然变低时,就在那里进行切割。
- 工作流程:
- 将文本分割成更小的单元(如句子)。
- 为每个句子生成嵌入向量(Embedding)。
- 计算相邻句子之间的余弦相似度,形成一个相似度序列。
- 识别相似度序列中的“谷底”(即相似度显著下降的点),这些点就是潜在的主题转换边界。
- 在这些边界点进行切割,并将相似度高的相邻句子组合成一个块。
- 优点:能产生语义上高度连贯的块,检索精度最高。
- 缺点:计算成本非常高,需要对大量句子进行嵌入计算和相似度比较,速度慢。
- 适用场景:对答案准确性和相关性要求极高的场景,如法律条款分析、学术文献综述、高端知识库问答。
2.2 演示示例
"""
语义切片策略
基于句子边界进行切分,保持语义完整性
"""
import re
def semantic_chunking(text, max_chunk_size=512):
"""基于语义的切片 - 按句子分割"""
# 使用正则表达式分割句子
sentences = re.split(r'[.!?。!?\n]+', text)
chunks = []
current_chunk = ""
for sentence in sentences:
sentence = sentence.strip()
if not sentence:
continue
# 如果当前句子加入后超过最大长度,保存当前块
if len(current_chunk) + len(sentence) > max_chunk_size and current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence
else:
current_chunk += " " + sentence if current_chunk else sentence
# 添加最后一个块
if current_chunk.strip():
chunks.append(current_chunk.strip())
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析结果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 统计信息:")
print(f" - 切片数量: {len(chunks)}")
print(f" - 平均长度: {avg_length:.1f} 字符")
print(f" - 最短长度: {min_length} 字符")
print(f" - 最长长度: {max_length} 字符")
print(f" - 长度方差: {max_length - min_length} 字符")
print(f"\n📝 切片内容:")
for i, chunk in enumerate(chunks, 1):
print(f" 块 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
print()
# 测试文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""
if __name__ == "__main__":
print("🎯 语义切片策略测试")
print(f"📄 测试文本长度: {len(text)} 字符")
# 使用语义切片
chunks = semantic_chunking(text, max_chunk_size=300)
print_chunk_analysis(chunks, "语义切片")
输出结果:
语义切片策略测试
📄 测试文本长度: 324 字符
============================================================
📋 语义切片
============================================================
📊 统计信息:
- 切片数量: 2
- 平均长度: 158.0 字符
- 最短长度: 29 字符
- 最长长度: 287 字符
- 长度方差: 258 字符
📝 切片内容:
块 1 (287 字符):
迪士尼乐园提供多种门票类型以满足不同游客需求 一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动 两日票
需要连续两天使用,总价比购买两天单日票优惠约9折 特定日票包含部分节庆活动时段,需注意门票标注的有效期限 购票渠道以官方渠道
为主,包括上海迪士尼官网、官方App、微信公众号及小程序 第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识 所
有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件 生日福利需在官方渠道登记
,可获赠生日徽章和甜品券 半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐
块 2 (29 字符):
军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批
3.LLM语义切片
3.1 详细说明
这是语义切片的一种强化版,使用更强大的LLM来理解和识别最优切割点。
- 核心思想: prompting LLM来分析和判断文本的最佳分割边界。LLM可以理解更复杂的语义结构,如“论点结束”、“例子开始”、“结论部分”等。
- 工作流程:
- 将文本初步分成较大的段。
- 对于每个大段,构造Prompt让LLM判断:“如果我要将以下文本切成块,用于问答系统,最佳切割点在哪里?”或者“以下文本包含几个独立的观点?”。
- 解析LLM的输出(可能是标记后的文本或JSON),根据其指示进行切割。
- 优点:最智能、最准确,能理解最复杂的语义和逻辑结构。
- 缺点:成本极高,速度极慢,不适合大规模文档处理,更偏向于研究性或对质量有极端要求的场景。
- 适用场景:处理高度复杂、结构非正式的文本(如哲学著作、长篇评论、创意写作)。
3.2 演示示例
from openai import OpenAI
import json
import os
import re
def advanced_semantic_chunking_with_llm(text, max_chunk_size=512):
"""使用LLM进行高级语义切片"""
# 检查环境变量
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
print("警告: 未设置 DASHSCOPE_API_KEY 环境变量,将使用基础语义切片")
return fallback_semantic_chunking(text, max_chunk_size)
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
prompt = f"""
请将以下文本按照语义完整性进行切片,每个切片不超过{max_chunk_size}字符。
要求:
1. 保持语义完整性
2. 在自然的分割点切分
3. 返回JSON格式的切片列表,格式如下:
{{
"chunks": [
"第一个切片内容",
"第二个切片内容",
...
]
}}
文本内容:
{text}
请返回JSON格式的切片列表:
"""
try:
print("正在调用LLM进行语义切片...")
response = client.chat.completions.create(
model="qwen-turbo-latest",
messages=[
{"role": "system", "content": "你是一个专业的文本切片助手。请严格按照JSON格式返回结果,不要添加任何额外的标记。"},
{"role": "user", "content": prompt}
]
)
result = response.choices[0].message.content
print(f"LLM返回结果: {result[:800]}...")
# 清理结果,移除可能的Markdown代码块标记
cleaned_result = result.strip()
if cleaned_result.startswith('```'):
# 移除开头的 ```json 或 ```
cleaned_result = re.sub(r'^```(?:json)?\s*', '', cleaned_result)
if cleaned_result.endswith('```'):
# 移除结尾的 ```
cleaned_result = re.sub(r'\s*```$', '', cleaned_result)
# 解析JSON结果
chunks_data = json.loads(cleaned_result)
# 处理不同的返回格式
if "chunks" in chunks_data:
return chunks_data["chunks"]
elif "slice" in chunks_data:
# 如果返回的是包含"slice"字段的列表
if isinstance(chunks_data, list):
return [item.get("slice", "") for item in chunks_data if item.get("slice")]
else:
return [chunks_data["slice"]]
else:
# 如果直接返回字符串列表
if isinstance(chunks_data, list):
return chunks_data
else:
print(f"意外的返回格式: {chunks_data}")
return []
except json.JSONDecodeError as e:
print(f"JSON解析失败: {e}")
print(f"原始结果: {result}")
# 尝试手动解析
try:
# 尝试提取JSON部分
json_match = re.search(r'\{.*\}', result, re.DOTALL)
if json_match:
json_str = json_match.group()
chunks_data = json.loads(json_str)
if "chunks" in chunks_data:
return chunks_data["chunks"]
except:
pass
except Exception as e:
print(f"LLM切片失败: {e}")
def test_chunking_methods():
"""测试不同的切片方法"""
# 示例文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""
print("\n=== LLM高级语义切片测试 ===")
try:
chunks = advanced_semantic_chunking_with_llm(text, max_chunk_size=300)
print(f"LLM高级语义切片生成 {len(chunks)} 个切片:")
for i, chunk in enumerate(chunks):
print(f"LLM语义块 {i+1} (长度: {len(chunk)}): {chunk}")
except Exception as e:
print(f"LLM切片测试失败: {e}")
if __name__ == "__main__":
test_chunking_methods()
输出结果:
=== LLM高级语义切片测试 ===
正在调用LLM进行语义切片...
LLM返回结果: {
"chunks": [
"迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。",
"两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。",
"购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,
但需认准官方授权标识。",
"所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。",
"生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。",
"军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。"
]
}...
LLM高级语义切片生成 6 个切片:
LLM语义块 1 (长度: 57): 迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价
格根据季节浮动。
LLM语义块 2 (长度: 56): 两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标
注的有效期限。
LLM语义块 3 (长度: 71): 购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等
合作代理商也可购票,但需认准官方授权标识。
LLM语义块 4 (长度: 50): 所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件
。
LLM语义块 5 (长度: 54): 生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会
厅双人餐。
LLM语义块 6 (长度: 30): 军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
4.层次切片
4.1 详细说明
这种方法不再产生扁平的块,而是构建一个层次化的索引结构。
- 核心思想:创建不同粒度级别的块。例如,小粒度的句子级块(用于精准检索)和中粒度的段落级块(用于提供上下文)。
- 工作流程:
- 第一层(粗粒度):将文档按章节或大标题分割。
- 第二层(中粒度):将每个章节按段落分割。
- 第三层(细粒度):将每个段落按句子或小标题分割。
- 检索时,可以先检索最细粒度的块以找到最相关的信息,然后将其父级(中粒度)的块作为上下文一起发送给LLM。
- 优点:兼顾了检索的精度和上下文的完整性,效果好。
- 缺点:索引结构更复杂,需要存储父子关系,检索逻辑也更复杂(例如使用ParentDocumentRetriever)。
- 适用场景:长文档(书籍、手册、论文),其中既需要找到具体细节,又需要理解周围的上下文。
4.2 演示示例
"""
层次切片策略
基于文档结构层次进行切片
"""
def hierarchical_chunking(text, target_size=512, preserve_hierarchy=True):
"""层次切片 - 基于文档结构层次进行切片"""
chunks = []
# 定义层次标记
hierarchy_markers = {
'title1': ['# ', '标题1:', '一、', '1. '],
'title2': ['## ', '标题2:', '二、', '2. '],
'title3': ['### ', '标题3:', '三、', '3. '],
'paragraph': ['\n\n', '\n']
}
# 分割文本为行
lines = text.split('\n')
current_chunk = ""
current_hierarchy = []
for line in lines:
line = line.strip()
if not line:
continue
# 检测当前行的层次级别
line_level = None
for level, markers in hierarchy_markers.items():
for marker in markers:
if line.startswith(marker):
line_level = level
break
if line_level:
break
# 如果没有检测到层次标记,默认为段落
if not line_level:
line_level = 'paragraph'
# 判断是否需要开始新的切片
should_start_new_chunk = False
# 1. 如果遇到更高级别的标题,开始新切片
if preserve_hierarchy and line_level in ['title1', 'title2']:
should_start_new_chunk = True
# 2. 如果当前切片长度超过目标大小
if len(current_chunk) + len(line) > target_size and current_chunk.strip():
should_start_new_chunk = True
# 3. 如果遇到段落分隔符且当前切片已经足够长
if line_level == 'paragraph' and len(current_chunk) > target_size * 0.8:
should_start_new_chunk = True
# 开始新切片
if should_start_new_chunk and current_chunk.strip():
chunks.append(current_chunk.strip())
current_chunk = ""
current_hierarchy = []
# 添加当前行到切片
if current_chunk:
current_chunk += "\n" + line
else:
current_chunk = line
# 更新层次信息
if line_level != 'paragraph':
current_hierarchy.append(line_level)
# 处理最后一个切片
if current_chunk.strip():
chunks.append(current_chunk.strip())
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析结果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 统计信息:")
print(f" - 切片数量: {len(chunks)}")
print(f" - 平均长度: {avg_length:.1f} 字符")
print(f" - 最短长度: {min_length} 字符")
print(f" - 最长长度: {max_length} 字符")
print(f" - 长度方差: {max_length - min_length} 字符")
print(f"\n📝 切片内容:")
for i, chunk in enumerate(chunks, 1):
print(f" 块 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
print()
# 测试文本 - 包含层次结构
text = """
# 迪士尼乐园门票指南
## 一、门票类型介绍
### 1. 基础门票类型
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
### 2. 特殊门票类型
年票适合经常游玩的游客,提供更多优惠和特权。VIP门票包含快速通道服务,可减少排队时间。团体票适用于10人以上团队,享受团体折扣。
## 二、购票渠道与流程
### 1. 官方购票渠道
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。这些渠道提供最可靠的服务和最新的票务信息。
### 2. 第三方平台
第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。建议优先选择官方渠道以确保购票安全。
### 3. 证件要求
所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
## 三、入园须知
### 1. 入园时间
乐园通常在上午8:00开园,晚上8:00闭园,具体时间可能因季节和特殊活动调整。建议提前30分钟到达园区。
### 2. 安全检查
入园前需要进行安全检查,禁止携带危险物品、玻璃制品等。建议轻装简行,提高入园效率。
### 3. 园区服务
园区内提供寄存服务、轮椅租赁、婴儿车租赁等服务,可在游客服务中心咨询详情。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""
if __name__ == "__main__":
print("🎯 层次切片策略测试")
print(f"📄 测试文本长度: {len(text)} 字符")
# 使用层次切片
chunks = hierarchical_chunking(text, target_size=300, preserve_hierarchy=True)
print_chunk_analysis(chunks, "层次切片")
输出结果:
🎯 层次切片策略测试
📄 测试文本长度: 725 字符
============================================================
📋 层次切片
============================================================
📊 统计信息:
- 切片数量: 4
- 平均长度: 177.0 字符
- 最短长度: 11 字符
- 最长长度: 264 字符
- 长度方差: 253 字符
📝 切片内容:
块 1 (11 字符):
# 迪士尼乐园门票指南
块 2 (219 字符):
## 一、门票类型介绍
### 1. 基础门票类型
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需
要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
### 2. 特殊门票类型
年票适合经常游玩的游客,提供更多优惠和特权。VIP门票包含快速通道服务,可减少排队时间。团体票适用于10人以上团队,享受团体折
扣。
块 3 (214 字符):
## 二、购票渠道与流程
### 1. 官方购票渠道
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。这些渠道提供最可靠的服务和最新的票务信息。
### 2. 第三方平台
第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。建议优先选择官方渠道以确保购票安全。
### 3. 证件要求
所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
块 4 (264 字符):
## 三、入园须知
### 1. 入园时间
乐园通常在上午8:00开园,晚上8:00闭园,具体时间可能因季节和特殊活动调整。建议提前30分钟到达园区。
### 2. 安全检查
入园前需要进行安全检查,禁止携带危险物品、玻璃制品等。建议轻装简行,提高入园效率。
### 3. 园区服务
园区内提供寄存服务、轮椅租赁、婴儿车租赁等服务,可在游客服务中心咨询详情。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及
退役军人凭证件享8折,需至少提前3天登记审批。
5.滑动窗口切片
5.1详细说明
这种方法与固定重叠类似,但更强调上下文的连续性。
- 核心思想:以很小的步长(远小于块大小)在文本上滑动,生成大量重叠的块。这确保了任何一段文本及其周围上下文都会以多种形式被索引。
- 工作流程:
- 设定窗口大小(window_size)和步长(stride)。
- 从文本起始开始,取第一个window_size的字符作为第一个块。
- 向后移动stride个字符,取下一个window_size的字符作为第二个块。
- 如此重复,直到覆盖全文。
- 优点:能最大程度地保证检索到任何一段文本及其所有可能的上下文窗口,对于捕捉局部上下文非常有效。
- 缺点:会产生巨大的索引,因为冗余度很高,存储和检索成本大。
- 适用场景:代码、日志文件或任何局部上下文极度重要而存储成本不是首要考虑因素的场景。
5.2 演示示例
"""
滑动窗口切片策略
固定长度、有重叠的文本分割方法
"""
def sliding_window_chunking(text, window_size=512, step_size=256):
"""滑动窗口切片"""
chunks = []
for i in range(0, len(text), step_size):
chunk = text[i:i + window_size]
if len(chunk.strip()) > 0:
chunks.append(chunk.strip())
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析结果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 统计信息:")
print(f" - 切片数量: {len(chunks)}")
print(f" - 平均长度: {avg_length:.1f} 字符")
print(f" - 最短长度: {min_length} 字符")
print(f" - 最长长度: {max_length} 字符")
print(f" - 长度方差: {max_length - min_length} 字符")
print(f"\n📝 切片内容:")
for i, chunk in enumerate(chunks, 1):
print(f" 块 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
# 测试文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""
if __name__ == "__main__":
print("🎯 滑动窗口切片策略测试")
print(f"📄 测试文本长度: {len(text)} 字符")
# 使用滑动窗口切片
chunks = sliding_window_chunking(text, window_size=300, step_size=150)
print_chunk_analysis(chunks, "滑动窗口切片")
输出结果:
🎯 滑动窗口切片策略测试
📄 测试文本长度: 324 字符
============================================================
📋 滑动窗口切片
============================================================
📊 统计信息:
- 切片数量: 3
- 平均长度: 165.0 字符
- 最短长度: 23 字符
- 最长长度: 299 字符
- 长度方差: 276 字符
📝 切片内容:
块 1 (299 字符):
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日
票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需
认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及
块 2 (173 字符):
小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行
证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及
退役军人凭证件享8折,需至少提前3天登记审批。
块 3 (23 字符):
退役军人凭证件享8折,需至少提前3天登记审批。
四、结合 FAISS 搭建本地知识库流程图
以下是结合 FAISS 搭建本地知识库的完整流程图。该流程图详细展示了从原始文档到最终问答的整个流程,并突出了不同切片策略的应用场景和选择路径。
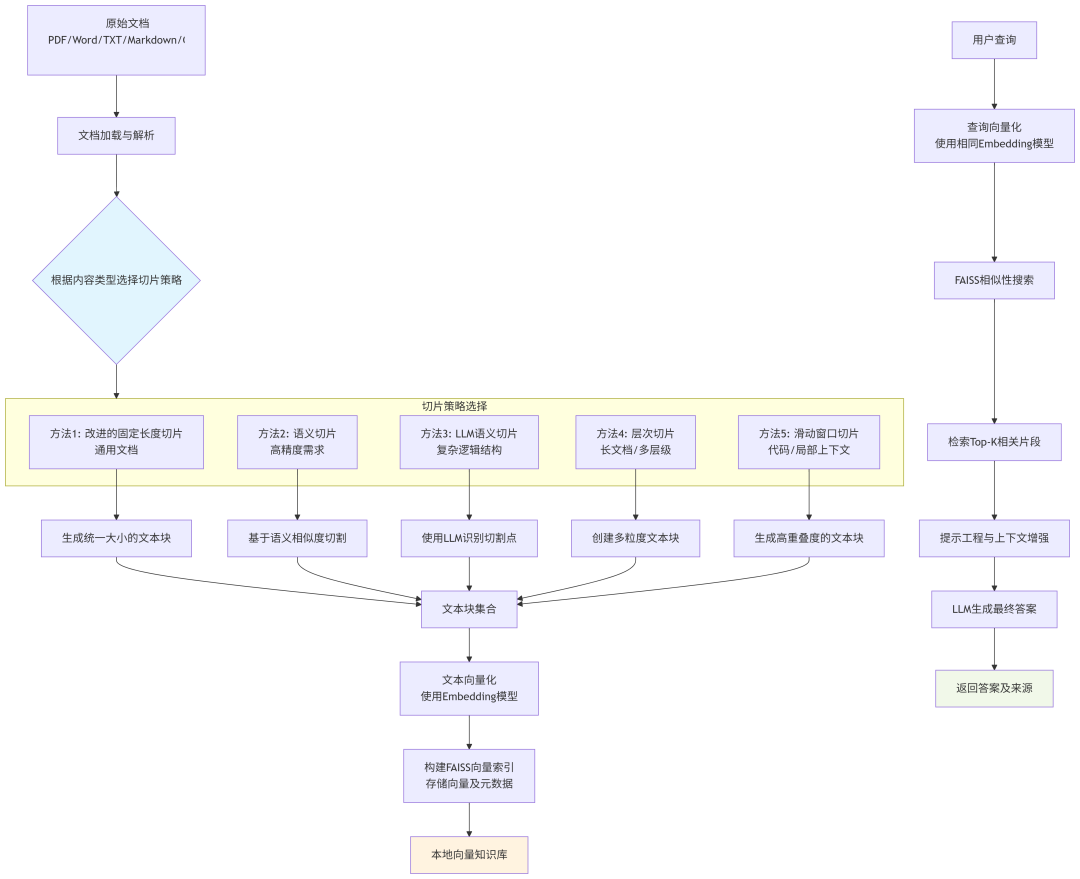
流程解析:
1. 文档加载与解析
- 系统接受多种格式的原始文档输入(PDF、Word、文本、Markdown、代码等)
- 使用相应的解析器提取纯文本和元数据
2. 切片策略选择(核心决策点)
这是流程中的关键决策环节,根据文档类型和需求选择最适合的切片策略:
- 方法1: 改进的固定长度切片
- 适用:通用文档,内容结构相对统一
- 特点:在固定长度基础上尊重句子边界,平衡效率与语义完整性
- 方法2: 语义切片
- 适用:高精度需求场景(法律、学术、医疗)
- 特点:基于嵌入相似度检测主题变化点,保证语义连贯性
- 方法3: LLM语义切片
- 适用:复杂逻辑结构文档(哲学论述、创意写作)
- 特点:使用LLM识别最佳切割点,智能度最高但成本也最高
- 方法4: 层次切片
- 适用:长文档、手册、书籍等多层级内容
- 特点:创建不同粒度的文本块(章节、段落、句子),支持分层检索
- 方法5: 滑动窗口切片
- 适用:代码、日志文件等局部上下文至关重要的内容
- 特点:高重叠度切割,确保任何内容都有充足的上下文
3. 向量化与索引构建
- 使用嵌入模型(如DeepSeek、OpenAI等)将文本块转换为向量
- 使用FAISS构建高效的向量索引,存储向量及元数据(包括来源、页码等信息)
- 最终形成本地向量知识库,支持快速相似性搜索
4. 查询处理与答案生成
- 用户查询经过相同嵌入模型向量化
- 在FAISS索引中执行相似性搜索,找到最相关的文本片段
- 通过提示工程将检索到的上下文与用户问题组合
- LLM基于增强的上下文生成最终答案,并返回答案及其来源信息
五、选择指南与建议
| 方法 | 智能度 | 计算成本 | 检索质量 | 适用场景 |
| 改进固定切片 | 低 | 低 | 中 | 通用场景,良好的默认选择 |
| 语义切片 | 高 | 非常高 | 非常高 | 高精度问答,法律、学术 |
| LLM语义切片 | 极高 | 极高 | 极高 | 研究性,复杂文本结构 |
| 层次切片 | 中 | 中 | 高 | 长文档,需兼顾精度与上下文 |
| 滑动窗口切片 | 低 | 中(索引大) | 中(局部性好) | 代码、日志、局部上下文关键 |
决策建议:
- 从方法1改进固定切片开始,调整 chunk_size 和 chunk_overlap。
- 如果处理长文档(书籍、手册),优先尝试方法4层次切片。
- 如果对答案质量有极致要求且不计成本,可以研究方法2语义切片。
- 方法5滑动窗口非常特殊,通常只用于代码等场景。
- 方法3LLM语义切片目前更多处于实验阶段,成本过高。
总之,没有放之四海而皆准的最佳策略。 最适合你数据和用例的策略需要通过实验来确定。
- 准备一组代表性的测试问题。
- 用不同的策略和参数(大小、重叠)处理你的文档。
- 运行你的RAG管道,评估答案的质量。评估答案是否准确?检索到的上下文是否真正相关?
- 迭代优化:选择效果最好的那种策略。
六、总结
RAG切片,本质上就是为了能让AI高效地“阅读”和“利用”庞杂的本地知识,我们提前把这些知识材料(文档)进行合理的“预处理”,切割成大小适中、语义完整的小块,并做好索引,以便快速精准检索。
它就像是给AI大脑外接了一个整理得井井有条的“资料架”,而不是扔给它一个“混乱的书堆”。切片策略的好坏,直接决定了这个“资料架”的易用性和AI最终回答的质量。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









