



1. 优化的目的:
-
避免页面出现访问错误
- 数据库连接timeout产生5xx错误
- 慢查询导致页面无法加载(就是查询操作消耗了比较多的时间)
- 数据库阻塞导致数据无法提交
-
增加数据库的稳定性
- 很多的数据库问题都是低效的查询引起的
-
优化用户体验
- 提升浏览速度
2. 数据准备
准本一个数据库:https://blog.youkuaiyun.com/forever19911314/article/details/73527610
3. 优化一:慢查询日志
使用慢查询监控有效率的问题
显示是否开启了慢查询日志
show variables like 'slow_query_log';
指定慢查询文件位置在哪里
set global show_query_log_file = '/home/mysql/sql_log/mysql-slow.log'
是否要把没有使用索引的sql记录到慢查询日志中
set global log_queries_not_using_indexes = on;
把大于1秒的查询记录在日志中
set global long_query_time = 1
show variables like '%log%';
查看配置项set global log_queries_not_using_indexes = on;
把没有使用索引的sql记录到慢查询日志中-
show variables like 'long_query_time';
查看long_query_time的配置,并将它设置为0.000000
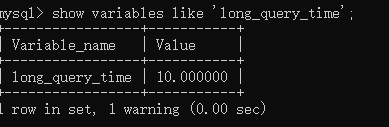 10秒
10秒
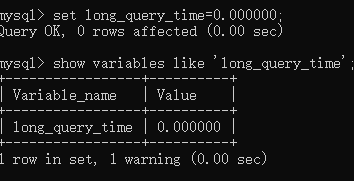 设置为0
设置为0 开启慢查询
set global slow_query_log = on;
-
show variables like 'slow%';
查看日志存储目录
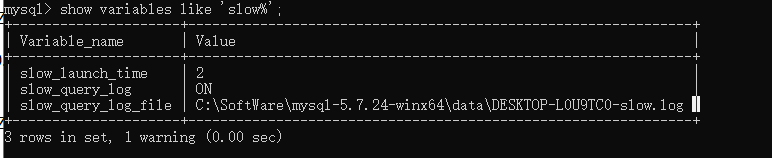 目录
目录 日志格式
时间
# Time: 2018-12-06T08:13:23.876056Z
主机信息
# User@Host: root[root] @ localhost [::1] Id: 7
sql执行信息
# Query_time: 0.003867 Lock_time: 0.003738 Rows_sent: 2 Rows_examined: 2
sql执行时间
SET timestamp=1544084003;
sql内容
select * from store limit 10;
- 慢查询分析工具
有问题的sql有哪些:
- 每次查询占用时间长的sql
通常为pt-query-digest的前几个查询
- IO大的sql
注意pt-query-digest分析的rows examine项
- 未命中索引的sql
注意pt-query-digest分析的rows examine项和Rows send的对比
- mysqldumpslow
mysql自带,linux可以直接使用,windows不行,需要安装个别的东西,
-t 3:显示top3的记录,后面跟着的是日志的目录位置
mysqldumpslow -t 3 /var/lib/mysql/zl-virtual-machine-slow.log | more
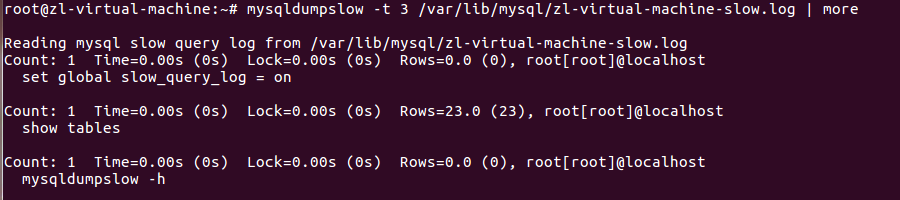
查询后的结果
- pt-query-digest
效果比mysqldumpslow好一些
我使用的时候遇到了bug,不能用:
The pipeline caused an error: Pipeline process 5 (iteration) caused an error: Redundant argument in sprintf at /usr/bin/pt-query-digest line 2556.
网上说安装高版本的就好了,没有试。
sudo pt-query-digest /var/lib/mysql/zl-virtual-machine-slow.log | more
4.优化二:通过explain查询和分析sql的执行计划
就是在运行sql之前,运行一下explain sql,看一下这个sql好不好使

示例
explain返回各列的含义
- table:显示这一行的数据是关于那张表的
- type:重要,显示连接使用了何种类型,从最好到最差的连接类型为:const、eq_reg、ref、range、index、all
- possible_keys:显示可能应用在这张表中的索引。空表示没有可能的索引。
- key:实际使用的索引。null表示没有索引。
- key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好。
- ref: 显示索引的哪一列被使用了,如果可能的话,是一个常数。
- rows:MYSQL认为必须检查的用来返回请求数据的行数。
5 语句优化
5.1 max(利用索引)
- 比如查询一个max:
select max(payment_date) from payment
- 用explain分析一下:
explain select max(payment_date) from payment \G
-
分析结果:
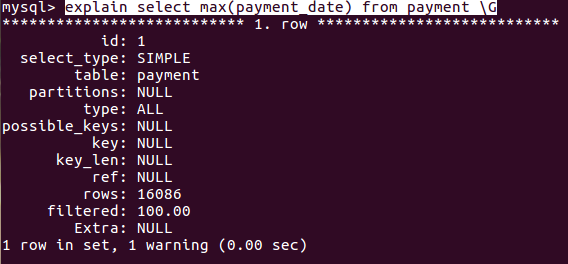 rows达到了一万6
rows达到了一万6 建立索引:
create index idx_paydate on payment (payment_date)

建立索引
-
再次explain分析一下:
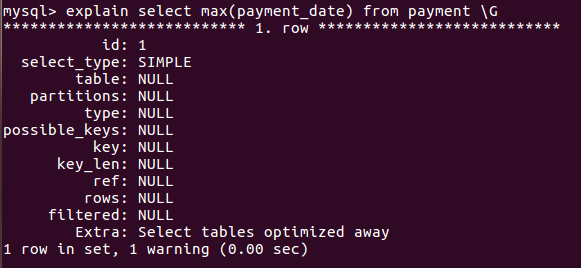 rows变成了null
rows变成了null
这时候再select max(payment_date) from payment就比原来优化了

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









