




你是不是也在想——“鸿蒙这么火,我能不能学会?”
答案是:当然可以!
这个专栏专为零基础小白设计,不需要编程基础,也不需要懂原理、背术语。我们会用最通俗易懂的语言、最贴近生活的案例,手把手带你从安装开发工具开始,一步步学会开发自己的鸿蒙应用。
不管你是学生、上班族、打算转行,还是单纯对技术感兴趣,只要你愿意花一点时间,就能在这里搞懂鸿蒙开发,并做出属于自己的App!
📌 关注本专栏《零基础学鸿蒙开发》,一起变强!
每一节内容我都会持续更新,配图+代码+解释全都有,欢迎点个关注,不走丢,我是小白酷爱学习,我们一起上路 🚀
全文目录:
一、Kurator 到底在“重新定义”什么?
先用一句话定个调:
Kurator 想做的,是「多云 / 边缘 / 算力」时代的统一控制面,让集群、应用、流量、策略、监控、流水线都回到一个声明式的中心。
从官方的介绍可以看到,Kurator 核心抓了几件事:
- 提供 Fleet 抽象:按业务 / 区域把集群编成「舰队」,在舰队级别做统一应用分发、统一监控与策略。
- 提供 Application + Rollout 抽象:把统一应用分发 + 渐进式发布封装成上层 CRD,底层用 FluxCD、Istio、Prometheus 托底。
- 提供 Pipeline 抽象:在 v0.6.0 中引入 CI/CD 流水线 + 软件供应链安全能力,从源码到上线全程统一到 Kurator 控制面。
- 提供 Plugin 机制:metric / policy / edge / (新增的 gateway 等),让 Prometheus/Thanos、Kyverno、KubeEdge 这类组件可以通过 Fleet 插件统一启用或关闭。
如果说 Kubernetes 把「单集群」资源抽象成 Pod/Service/Deployment;
Kurator 做的是把「多集群 + 多云 + 边缘」抽象成 Fleet/Application/Rollout/Pipeline/Plugin。
这个抽象层,在我看来就是 Kurator 最大的前瞻价值:
它让我们在讨论未来演进的时候,不再纠结「这个功能是不是由某个具体组件提供」,而是从「控制面」这个高度去重新设计整条链路。
首先先来参考下官方的Kurator架构图:
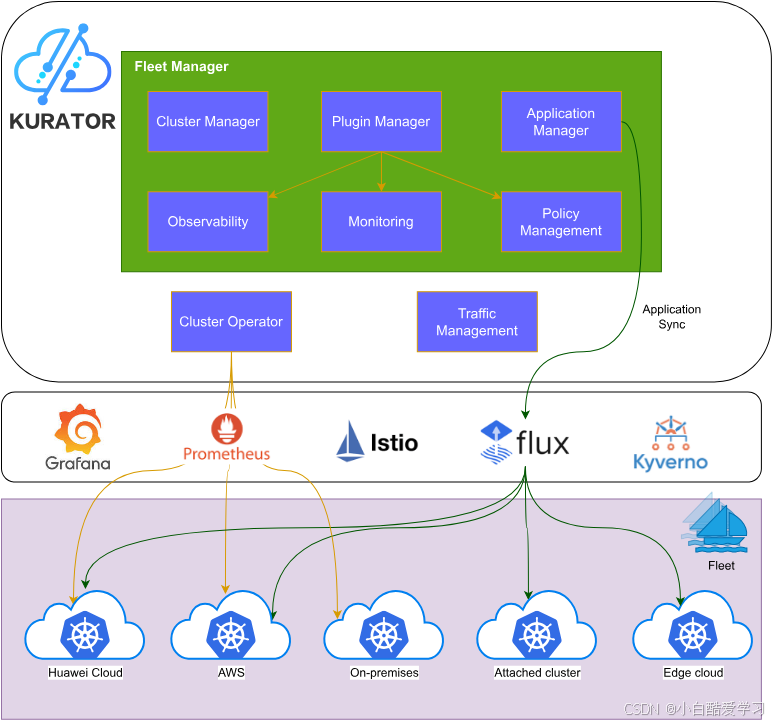
二、从五大内置项目看 Kurator 的“二次放大效应”
Kurator 本身不是在「重造轮子」,而是把几个云原生明星项目变成「组件化基石」。我们不妨一个一个看:Kurator 在它们之上还能做什么更前瞻的事。
2.1 Prometheus / Thanos:从指标收集到“跨集群智能信号中心”
当前现状(Kurator 已做的):
- 通过 metric 插件,Kurator 在 Fleet 里一键为多个集群安装 Prometheus + Thanos Sidecar,汇总到统一的 Thanos Query,再由 Grafana 展示。
- 用户只要在 Fleet 里配置一次 object storage & Grafana,就能获得全局统一监控视图。
Kurator 的“二次放大”:
Kurator 不只是帮你把监控「集中」,更关键的是:
-
在 Rollout 策略中内置对 Prometheus 指标的引用,把「请求成功率」「延迟」当作金丝雀 / A/B / 蓝绿发布的判断依据。
-
在未来完全可以继续往前做:
- 把多集群指标抽象成「健康信号」,反馈到 Fleet 层调度策略;
- 把应用 SLA 与 Kurator 的调度 / 发布策略直接绑定。
一个前瞻式 YAML 小示例:
设想一下未来 Kurator 支持在 Fleet 级别声明「健康信号与调度行为」的策略(伪代码,示意用):
apiVersion: fleet.kurator.dev/v1alpha1
kind: HealthAwareFleet
metadata:
name: global-fleet
spec:
fleetRef:
name: global-fleet
signals:
- name: checkout-latency
metric: "http_request_duration_p95_seconds"
selector:
service: checkout
threshold:
max: 0.3 # 300ms
- name: payment-error
metric: "http_request_error_rate"
selector:
service: payment
threshold:
max: 0.01 # 1%
actions:
- when:
signal: checkout-latency
condition: "above-threshold"
do:
type: "scale-out"
target:
clusters:
strategy: "prefer-low-cost"
replicasStep: 2
- when:
signal: payment-error
condition: "above-threshold"
do:
type: "pause-rollout"
rolloutSelector:
app: payment-service
这类配置今天 Kurator 还没这么写,但从已有的 Rollout + Prometheus 整合能力来看,未来让「指标直接驱动调度和发布」完全是顺势而为。
当然,我们还可以参考如下流程图:
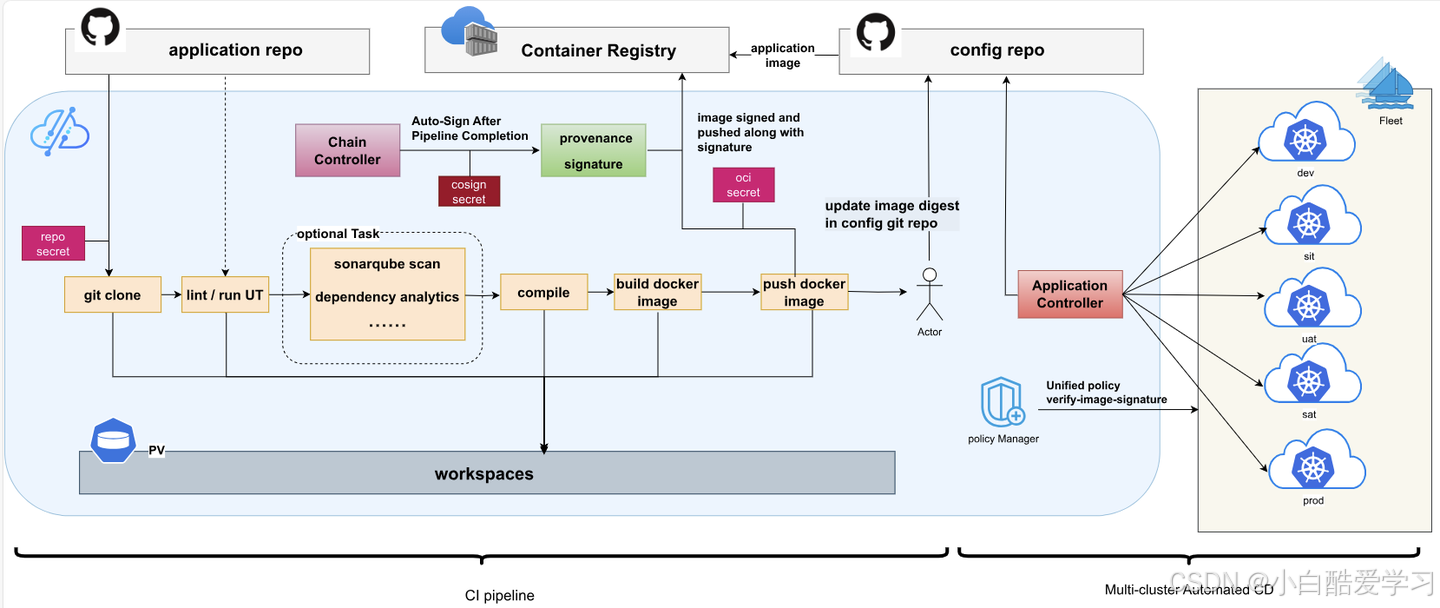
2.2 Istio:从服务网格到“多云多地域流量策略中枢”
现状:
- Kurator 在 v0.6.0 版本中,已经把金丝雀 / A/B / 蓝绿发布封装到了 Rollout CR 里,底层用 Istio VirtualService / DestinationRule 控制流量权重和路由。
- 用户无需直接操作复杂的 Istio YAML,只需要在 Rollout 中配置策略即可。
Kurator 的前瞻空间:
-
更细粒度的跨集群流量治理
- 借助 Fleet 和多集群 service discovery,未来可以支持「按地域 / 机房 / 云厂商」来做流量拆分。
- 再往前一步,可以结合成本信息,形成「既考虑延迟又考虑成本」的多云流量策略。
-
API Gateway 插件 + Mesh 一体化治理
- Kurator 社区已经有 Gateway Plugin 的支持记录,说明已经开始往「入口流量」这层做统一抽象。
- 未来很自然的方向是:在 Fleet 层声明 API Gateway 策略(限流、黑白名单、域名路由等),由 Kurator 自动在各集群安装并配置对应的 Gateway 实现(例如 Istio Gateway、Kong、APISIX 等)。
构想一个 Gateway 插件配置示例:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: asia-fleet
spec:
clusters:
- name: cn-north-prod
kind: Cluster
- name: hk-prod
kind: AttachedCluster
plugin:
gateway:
type: istio-gateway
ingressClass: kurator-gw
hosts:
- domain: api.example.com
tls:
secretName: api-tls
routes:
- match:
prefix: /checkout
backend:
service: checkout-service
port: 80
policy:
rateLimit:
qps: 500
auth:
jwt:
issuer: "https://auth.example.com"
jwksUri: "https://auth.example.com/jwks.json"
这里的重点不是语法本身,而是:把多集群 API 网关策略收敛到 Fleet + plugin 的抽象里,让 Istio 从「服务网格」变成「多云入口策略中枢的一环」。
2.3 Karmada:从多集群编排到“多云算力总控”
当前 Kurator 怎么用 Karmada?
- 官方文档和博客都提到,Kurator 以 Karmada 作为多集群编排基础,实现跨集群应用部署与服务发现。
- Karmada 本身支持基于多集群工作负载的调度策略,能处理副本在不同集群间的分布。
在 Kurator 的视角下,Karmada 可以被“发挥到什么程度”?
-
多云部署策略的统一入口
- Kurator 的 Application 其实可以把「应用在各集群的副本数 / 配置差异」封装成高级策略,由控制面转译成 Karmada 的 PropagationPolicy / OverridePolicy。
- 用户表达的是「我要在亚太 Region 至少有 3 个副本、在欧洲按照用户量弹性扩容」,而不是关心哪个集群装了多少 Pod。
-
与成本、碳排放等新维度结合(这已经是非常前瞻的方向了 😎)
- 随着多云成本、绿色算力成为很多企业 KPI,完全可以在 Kurator 中声明诸如「优先把非关键批任务调度到价格更低或碳排系数更低的区域」这样的策略,由 Karmada 负责实际调度。
一个「成本感知 + Karmada」的设想 YAML:
apiVersion: apps.kurator.dev/v1alpha1
kind: MultiRegionApp
metadata:
name: ml-feature-service
spec:
templateRef:
name: ml-feature-deploy
placement:
strategy:
type: cost-aware
constraints:
latency:
maxMs: 150
policies:
- region: asia
minReplicas: 4
costPreference: "low"
- region: europe
minReplicas: 2
costPreference: "balanced"
Kurator 控制器可以根据上述抽象,生成对应的 Karmada Policy,将应用调度到最合适的集群;
结合 Prometheus / Thanos 的跨集群指标,还能动态调整这一策略。
当然,如果这里你已经感兴趣了,你可以直接去克隆代码:
2.4 KubeEdge:从“边缘节点”到“边云一体的应用生命周期”
现状:
- 官网上 Kurator 介绍中明确提到了 KubeEdge 的内置集成,用于边缘场景。
- 这意味着 Kurator 不只关注「云上的多集群」,还把边缘节点纳入统一编排范围。
在前瞻视角下,Kurator + KubeEdge 至少可以做几件有趣的事:
-
统一的边云发布策略
- 在 Application / Rollout 中,增加对「边缘节点组」的专门支持,例如先在边缘做 A/B 测试,再向云上主集群推广。
-
边缘数据上云链路的标准化
- 结合 KubeEdge 的 MQTT / WebSocket 能力,在 Kurator 中声明「数据通道」资源,自动在边缘和云上部署对应的采集 / 转发组件。
构造一个边云协同的 Rollout 示例(伪代码):
apiVersion: rollout.kurator.dev/v1alpha1
kind: EdgeAwareRollout
metadata:
name: video-analytics-rollout
spec:
workload:
kind: Deployment
apiVersion: apps/v1
name: video-analyzer
stages:
- name: edge-pilot
targets:
clusters:
fleet: edge-fleet
edgeSelector:
city: "shenzhen"
traffic:
type: "shadow" # 影子流量,只复制请求不影响生产
metrics:
- name: frame-drop-rate
max: 0.02
- name: cloud-extend
targets:
clusters:
fleet: core-cloud-fleet
traffic:
type: "canary"
stepWeight: 10
maxWeight: 50
这个设想中的 CR 体现一种更符合真实业务的思路:
先在边缘侧吃一轮数据、观察模型效果,再逐步扩展到云上主站流量。Kurator 的职责就是把整条链路串起来。
2.5 Volcano:从批任务调度到“AI & 大数据算力中台”
Volcano 本身就是为 AI、批处理和大数据作业设计的调度器,在 AI 算力大规模上云的背景下,Kurator + Volcano 的组合天然具有前瞻性。
想象一个场景:
- 你有一堆 AI 训练任务,既可以在本地 GPU 集群跑,也可以在某云 Region 的 Spot 实例跑;
- 你希望在「价格低 + GPU 空闲 + 网络带宽足够」时触发训练任务;
- 你还希望训练数据存放位置、合规要求、甚至碳排放因素都纳入考虑。
设想一个 Kurator 调度 AI 训练作业的 YAML:
apiVersion: batch.kurator.dev/v1alpha1
kind: AITrainingJob
metadata:
name: recsys-train-v2
spec:
framework: "pytorch"
image: "registry.example.com/ai/recsys-train:v2"
data:
dataset: "oss://ml-bucket/datasets/recsys/v2"
locality:
regionPreferred: ["cn-north-4", "ap-southeast-1"]
resources:
gpuPerReplica: 4
cpuPerReplica: "8"
memoryPerReplica: "32Gi"
replicaCount: 8
scheduling:
strategy: "volcano"
constraints:
spotAllowed: true
maxCostPerHour: 200
minThroughput: "10Gbps"
由 Kurator 控制器将这一抽象翻译为 Volcano 的 Job / PodGroup 等资源,并结合 Karmada 决定究竟把这些任务下发到哪个集群。
这已经不是「单个调度器」能完成的工作,而更像是 Kurator 在扮演一个多云算力中台的总调度官。
可看下如下分发示意图,以便于理解:
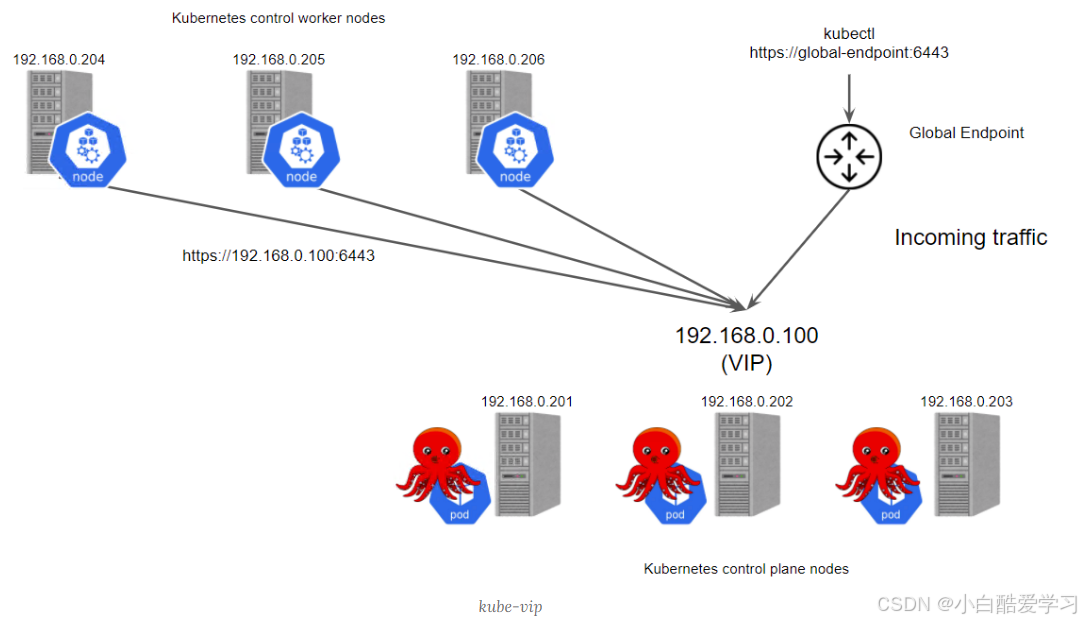
三、从控制面视角重新审视 Kurator Pipeline
前一篇我们更多是从「DevOps 实战」的角度聊了 Pipeline。这次用更「前瞻」的视角看,Kurator 的 Pipeline 实际是在做三件事:
- 把 CI/CD 的复杂度收敛到预置模板——例如 git-clone、go-test、go-lint、build-and-push-image 等 Task 模板,用户几乎只要填参数。
- 把流水线与 Rollout / Application 紧密耦合——从源码改动到渐进式发布,整个链路都在 Kurator 控制面中形成闭环。
- 在流水线阶段引入软件供应链安全——镜像构建时自动签名、生成 provenance,避免假冒镜像。
3.1 一个“供应链安全 + 多集群发布”的综合 Pipeline 示例
下面是一个更「前瞻」的 Pipeline 例子,相比常规示例增加了两点:
- 在构建阶段对镜像进行 SBOM 生成、漏洞扫描;
- Pipeline 成功后,通过一个「控制面 API 调用 Task」去更新 Kurator Application 的镜像 tag,触发多集群渐进式发布。
apiVersion: pipeline.kurator.dev/v1alpha1
kind: Pipeline
metadata:
name: checkout-end2end
namespace: kurator-pipelines
spec:
git:
repo: https://github.com/my-org/checkout-service.git
revision: main
credentialRef: git-cred
tasks:
- name: clone
template: git-clone
- name: unit-test
template: go-test
dependsOn: [clone]
- name: static-analysis
template: go-lint
dependsOn: [clone]
- name: build-image
template: build-and-push-image
dependsOn: [unit-test, static-analysis]
params:
imageRepo: "registry.example.com/shop/checkout"
tag: "v1.5.0"
- name: sbom-and-scan
customTask:
image: "registry.example.com/tools/security-toolkit:latest"
command: ["sh", "-c"]
args:
- |
generate-sbom --image registry.example.com/shop/checkout:v1.5.0 -o /tmp/sbom.json
security-scan --sbom /tmp/sbom.json --policy high
echo "SBOM and security scan passed."
dependsOn: [build-image]
- name: sign-and-publish
template: image-sign
dependsOn: [sbom-and-scan]
params:
image: "registry.example.com/shop/checkout:v1.5.0"
keyRef: cosign-key
- name: trigger-rollout
customTask:
image: "curlimages/curl:8.5.0"
command: ["sh", "-c"]
args:
- |
curl -X PATCH \
-H "Content-Type: application/merge-patch+json" \
-d '{"spec":{"template":{"spec":{"containers":[{"name":"checkout","image":"registry.example.com/shop/checkout:v1.5.0"}]}}}}' \
https://kurator-api.kurator-system.svc/apis/apps.kurator.dev/v1alpha1/namespaces/shop-system/applications/checkout
dependsOn: [sign-and-publish]
supplyChainSecurity:
sign:
enabled: true
keyRef: cosign-key
provenance:
enabled: true
attestationStorage: oci
这里的
image-sign/security-toolkit/kurator-api都是示意性的名字,目的是表达:
Kurator Pipeline 完全可以成为「安全感知的发布入口」,并与多集群 Rollout 严密联动。
而且,我们也可以看到,社区开源信息基本都给出了:
四、行业级的前瞻蓝图:三种典型场景
从「未来想象」回落到业务角度,我们不妨看三类典型行业,用 Kurator 去画一张 2~3 年的蓝图会是什么样子。
4.1 金融行业:监管 + 多活 + 安全的“多云控台”
痛点:
- 数据与系统跨多个 Region、多个云厂商;
- 对金融级高可用(同城双活、异地多活)要求极高;
- 合规与审计要求严苛(安全策略、访问日志、软件供应链安全)。
Kurator 能提供的前瞻方案:
-
以 Fleet 划分「监管域」:
- 一个 Fleet 代表一个监管区域,例如「境内生产 Fleet」「境外分支 Fleet」。
- 监控 / 策略 / 应用分发都按 Fleet 做隔离和统一配置。
-
声明式的「金融级发布策略」:
- 所有关键系统必须通过 Rollout 做金丝雀 + 自动回滚;
- 发布过程中的关键指标(失败率、延迟、交易成功率)都来自统一的 Prometheus/Thanos 指标。
-
软件供应链安全全程可追踪:
- Pipeline 把构建、签名、证明固化为合规要求的一部分;
- 镜像与配置变更都可在 Kurator 控制面中审计。
小结:
对金融行业来说,Kurator 更像是一个「多云监管与运维中台」,它的前瞻意义在于——通过统一抽象给未来监管预留接口,而不是让每家银行自己去 bricolage 一堆脚本和工具链。
4.2 车联网 / 智慧交通:边云协同 + 实时决策
典型画面:
- 全国上千个路口摄像头和边缘节点,跑着 KubeEdge 容器;
- 云上有多套大模型、规则引擎,实现全局的路径规划与流量优化;
- 每一次算法更新、模型版本迭代,都可能影响行车安全。
Kurator 的前瞻用法:
-
Edge Fleet + Cloud Fleet 分层管理:
- Edge Fleet:所有边缘集群(基于 KubeEdge),只部署轻量推理服务和观测组件;
- Cloud Fleet:负责模型训练、策略决策、数据汇总。
-
边缘优先发布策略:
- 新模型优先在 Edge Fleet 中的少量城市做灰度验证,使用 EdgeAwareRollout 之类的策略;
- 通过多集群 Prometheus 汇总模型效果指标(误检率、漏检率、延迟等),再决定是否在全国推广。
-
跨域数据路径声明:
- Kurator 中定义 DataPipeline CR,统一声明数据从 Edge → Cloud → Data Lake 的流向规则和 QoS 要求;
- 控制面自动在边缘和云上部署对应采集 / 聚合 / 加密组件。
这样一套体系,如果真正建起来,其实就已经是下一代边云协同控制面的雏形了。
作为华为的开源项目,对于Kurator项目也上了热门开源项目榜:

4.3 工业互联网:算力编排 + 能耗优化
在工业互联网场景,除了高可靠,高实时性之外,还有一个越来越重要的指标:能效。
- 某些工厂白天用电紧张,更适合跑轻任务;
- 夜间电价低,适合做批量分析 / AI 训练;
- 多个工厂 / 区域之间有不同的电价、碳排系数。
如果 Kurator 能与这类能效平台打通,就可以做这些事:
-
能耗感知的 Batch 调度(基于 Volcano + Karmada):
- 在 AITrainingJob 之类的 CR 中增加「energyBudget」「carbonLimit」等字段;
- Kurator 根据电价 / 能耗信号选择调度目标集群。
-
工厂边缘 + 云中心协同分析:
- 工厂侧边缘集群只做数据预处理和初步诊断;
- 云侧集中做多工厂联合分析与模型训练。
-
多维度 SLA:把“成本”和“SLA”共同纳入 Kurator 的 declarative world。
五、对 Kurator 社区的一点“前瞻建议”
建议 1:正式抽象出“信号驱动控制循环”
现在 Kurator 已经把 Metrics、Rollout、Pipeline 等关键要素放到一张图里了,下一步我觉得可以:
- 在 API 层抽象出类似 Signal 与 ControlLoop 的 CRD;
- Signal = 从 Prometheus / 日志 / Trace / 外部系统 等获取的「可用于决策的度量」;
- ControlLoop = 根据 Signal 做出「暂停发布」「缩容」「换集群」等动作的自动化控制逻辑。
这会让 Kurator 更像一个「云原生控制理论实验场」,非常适合 AIOps 的演进。
建议 2:把「多云成本、碳排」纳入第一等公民
在多云时代,工程视角的“最优” 与 成本/碳排视角的“最优” 其实是经常打架的。如果 Kurator 能:
- 在 Fleet / Application 中原生支持 cost / carbon / energy 相关字段;
- 提供与第三方计费 / 能耗平台对接的标准接口;
那将会在多云成本治理领域占据很重要的一席之地。
建议 3:定义“插件市场”和“扩展规范”
当前 Kurator 已经有 metric / policy / edge / gateway 等插件类型,未来完全可以走向:
- 建立 Kurator Plugin Hub,让社区和厂商贡献各自的插件包;
- 提供 Plugin SDK + 认证流程,确保插件在安全 / 兼容性上可控;
- 在控制面 UI 上提供「一键启用插件到 Fleet」的能力。
这会让 Kurator 更像一个「分布式云原生应用商店」的底座,非常有想象空间。
建议 4:开放“可编程控制平面”接口
给高级用户一个能力:
- 通过 Go / Rust / Wasm 等扩展语言,直接在 Kurator 控制面上写控制逻辑(类似 Operator,但更聚焦在多云控制);
- 比如写一段 Go 代码监听 Rollout 事件,根据自定义指标决定是否继续发布。
简单示例:一个监听 Rollout 事件的小 Go 片段(伪代码)
func main() {
config, _ := rest.InClusterConfig()
client, _ := rolloutclientset.NewForConfig(config)
informer := rolloutinformers.NewRolloutInformer(
client, metav1.NamespaceAll, 0, cache.Indexers{},
)
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
UpdateFunc: func(oldObj, newObj interface{}) {
r := newObj.(*kuratorv1alpha1.Rollout)
if r.Status.Phase == "Progressing" && isRiskHigh(r) {
// 标记为暂停
patch := []byte(`{"spec":{"paused":true}}`)
client.Rollouts(r.Namespace).Patch(context.TODO(),
r.Name, types.MergePatchType, patch, metav1.PatchOptions{})
}
},
})
stop := make(chan struct{})
defer close(stop)
informer.Run(stop)
}
如果 Kurator 官方提供对这种「可编程控制循环」的标准入口,整个控制面就会从「配置驱动」进化到「配置 + 代码双驱动」,非常适合大规模复杂企业。
如下是GitHub开源截图:
❤️ 如果本文帮到了你…
- 请点个赞,让我知道你还在坚持阅读技术长文!
- 请收藏本文,因为你以后一定还会用上!
- 如果你在学习过程中遇到bug,请留言,我帮你踩坑!


















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









