








文章目录
太…完整了!同济大佬唐宇迪博士终于把【Transformer】入门到精通全套课程分享出来了,最新前沿方向
学习笔记
1、Transformer



无法并行,层数比较少


词向量生成之后,不会变,没有结合语境信息的情况下,存在一词多义,无法处理

词如何编码成向量


第一句话中,it 和 animal 的相应最高



内积,正交的话内积为0,越相近(相关),内积越大


d k \sqrt{d_k} dk 的目的,向量维度越大,内积也越大, d k \sqrt{d_k} dk 起到 scale 的作用

对于每个输入 x1 … xn, 计算一样的,可以并行为一个矩阵乘法
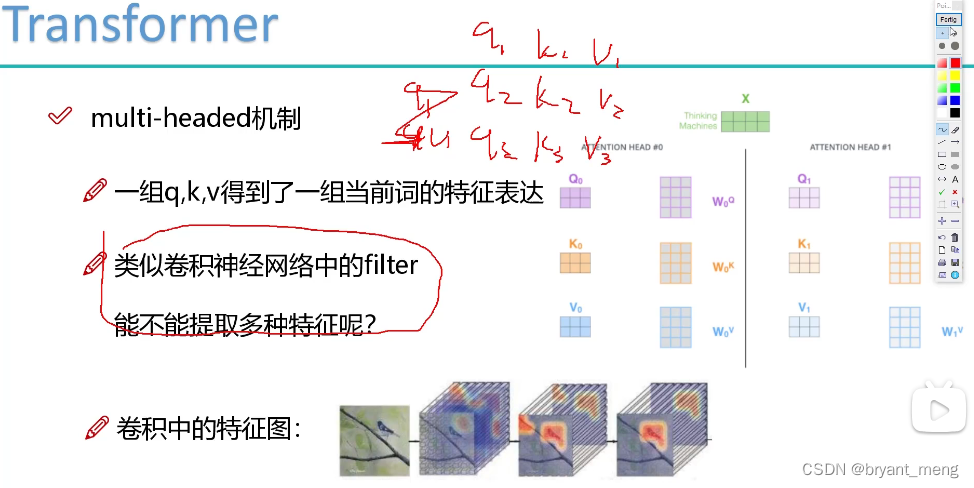
多头类比多个卷积核,来提取多种特征



不同的头得到的特征表达也不相同

多头包含在了 self-attention 中了

引入位置编码,形式有很多,比如 one-hot,原文中作者使用的是周期性信号进行编码

layer normalization 和 residual structure


encoder-decoder attention,encoder 的 K,V,decoder 的 Q

mask 机制:以翻译为例,不能透答案了,翻译到 I am a 的时候,student 要被 mask 起来,只能计算 I am a 的注意力
不能用后面未知的结果当成已知的条件



2、BERT


语料

预测出 mask,来训练提升特征编码能力


end-to-end 的形式,词编码表达和 task 一起训练


答案 d2->d3

















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









