




 本文探讨了在Linux环境下,通过gcc编译HelloWorld程序时经历的预处理、编译、汇编和链接四个步骤。预处理主要处理宏定义、条件指令和#include;编译阶段涉及词法分析、语法分析、语义分析和优化,生成汇编代码;汇编阶段将汇编代码转换为机器码;链接则负责符号绑定和地址空间分配,解决符号定义和地址问题。
本文探讨了在Linux环境下,通过gcc编译HelloWorld程序时经历的预处理、编译、汇编和链接四个步骤。预处理主要处理宏定义、条件指令和#include;编译阶段涉及词法分析、语法分析、语义分析和优化,生成汇编代码;汇编阶段将汇编代码转换为机器码;链接则负责符号绑定和地址空间分配,解决符号定义和地址问题。
在当今这个时代,我们有着各种各样非常强大的集成开发工具,得益于它们那些强大的诸如符号解析,引用构建,代码补全,一键式编译,类库支持等等功能,我们可以从工程本身的结构中抽身出来,专注于业务和功能。但是,不好的一点在于,对于很多新手来说,IDE便成为了一个夹在源代码和可执行文件中间的黑盒,那些被隐藏的处理一旦出现了错误,他们往往不知道如何去解决这些问题。
以下面这段几乎每个程序员都能闭眼写出的HelloWorld而言,在linux下当我们执行 "gcc Hello.c -o Hello"后,最终便成生了名为Hello的可执行程序。
#include<stdio.h>
int main()
{
printf("Hello World!\n");
return 0;
}
事实上,gcc的上述处理其实可以分解为4个步骤,预处理,编译,汇编,链接,如下图所示:

1.预处理
预处理其实也可以使用gcc命令来单独完成,对于上述编译链接过程,第一步预处理其实相当于执行了如下命令:
gcc -E hello.c -o Hello.i
预处理过程主要处理那些源代码中以"#"开始的预处理指令,比如"#include", "#define","#if","#else"等等,预处理的主要规则如下:
(1) 将所有的"#define"删除,并展开所有的宏定义。
(2) 处理所有预处理条件指令,例如"#if"、"#ifdef"、"#else"、"#elif"、"#endif"。
(3) 处理"#include"指令,将"#include"包含的文件插入到该指令所在的位置。值得注意的是,这个过程是递归进行的,即"#include"包含的文件同时也可以"#include"包含其他文件
(4) 删除所有空行和注释
(5) 添加行号和文件名表示,以偏于编译时帮助编译器产生调试使用的行号信息,并且在编译错误时,反馈发生error, warning的具体行号位置
(6) 保留所有"#pragma",共后续的编译过程使用。
所以经过预处理后的.i文件,本质上还是源代码文件,只是为了帮助后续的编译过程, 提前对源文件做一些必要的处理。而且有上述规则我们可知,经过预处理后的.i文件不包括任何形式的宏,注释,并且包含的头文件也全部插入到原来的"#include"中。所以当我们遇到一些编译问题并无法确定是否正确的包含了头文件时,可以通过查看预处理后的.i文件来判断头文件的包含是否正确。
2.编译
编译其实也可以使用gcc命令来单独完成,对于上述编译链接过程,编译其实相当于执行了如下命令:
gcc -S hello.i -o Hello.s
编译是通过一些列词法分析,语法分析,语义分析和目标代码优化过程后生成汇编代码的处理过程,他是整个程序构建过程中的核心部分,其中涉及的内容非常非常多,这里仅仅以如下代码为例,对词法分析,语法分析,语义分析和目标代码生成与优化做一个简单地介绍:
array[index] = (index + 4) * (2 + 6);
(1) 词法分析
词法分析是指编译器通过一种类似于有限状态机的算法,将源代码语句分割成一个个token的过程。以上述代码为例,通过词法分析后,总共产生了16个token,分别是"array","[","index","]","=","(","index","+","4",")","*","(","2","+","6",")"。
词法分析产生的token一般可以分为如下几类:关键字,标识符,常数(数字和字符串),特殊符号(运算符)。
(2) 语法分析
语法分析是指编译器对词法分析产生的token进行语法分析,产生语法树的过程。以上述代码为例,通过上下文无关语法处理之后,生成的语法分析树如下所示:
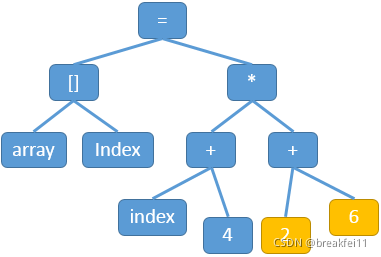
(3) 语义分析
语义分析指示对生成的语法树进行语义层面的检查处理。因为语法分析只对表达式完成了语法层面的分析,但是他并不清楚运算的含义。例如,在C语言中,两个指针进行乘操作是没有任何意义的,但是该语句在语法层面是合法的,因此语法分析并不能检查表达式的语义。
语义分析对处理类型的声明,匹配和类型的转换,并对此进行检查。经过语义分析之后,上述语法树的每个节点都被标明了类型,如下所示:
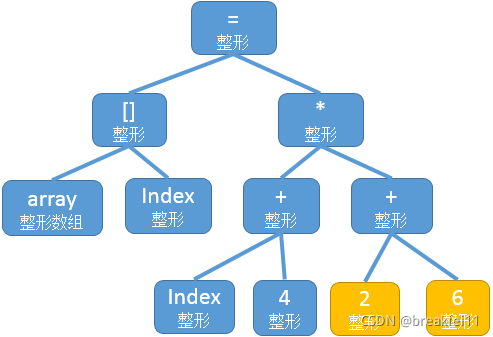
(4) 目标代码生成与优化
现代编译器在编译过程中有很多层次的各种各样的优化方法,以源码级优化为例,上述生成的语法树中,最右侧的"(2+6)"这个表达式,可以直接被优化成8,因为该表达式的值在编译期间就可以直接确定。因此,经过优化后的语法树如下图所示:
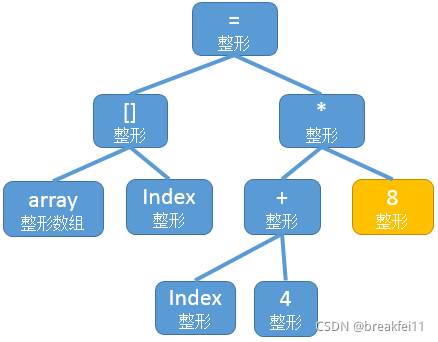
然而实际处理过程中,对语法树进行优化是一件十分困难的事情。往往我们是通过先生成中间代码,对中间代码进行优化后,再去生成目标代码,并对目标代码优化的。以上述表达式为例,生成的中间代码如下所示:
t1 = 2 + 6
t2 = index + 4
t3 = t2 * t1
array[index] = t3
其中 t1的值可以直接确认为8,因此优化后的中间码如下所示:
t2 = index + 4
t3 = t2 * 8
array[index] = t3
经过优化后的中间代码,被编译器重新进行解析,最终生成了目标汇编代码,以X86平台为例,上述中间代码最终生成为如下汇编代码:
mov index %ecx
add 4, %ecx
mul 8, %ecx
mov index, %eax
mov %eax, array(,eax,4)
3.汇编
经过编译,生成了汇编代码之后,汇编过程就简单很多了。因为我们的汇编代码和机器码是一一对应的,所以只要根据汇编指令-机器码对照表一一进行翻译就可以了。对于上述编译链接过程,汇编其实相当于执行了如下命令:
gcc -c hello.s -o Hello.o
4.链接
链接是一个我们耳熟能详的名次,但往往我们对这一过程十分费解。为什么汇编后不直接输出可执行文件,而是输出一个.o的目标文件呢?我们为什么要进行链接呢?以上述编译过程为例,当我们查看具体的链接命令的时候,命令显示如下:
ld -static /usr/lib/crt1.o /usr/lib/crti.o /usr/lib/gcc/i486-linux-gnu/4.1.3/crtbeginT.o hello.o --start-group -lgcc -lgcc_eh -lc -end-group crtend.o crtn.o
看到这个命令后,可能大家会更加疑惑了,原来需要这么一大堆文件链接起来才能得到我们最终的可执行文件 Hello,那这些crt1.o,crti.o,crtbeginT.o等等的文件都是干什么用的呢?为什么要链接他们呢。
简单来说,链接主要做了两件事情,符号绑定和地址空间分配。以上述的那句表达式为例
array[index] = (index + 4) * (2 + 6);
我们可以发现直到我们已经编译生成了Hello.o文件后,我们都遗留着一个问题没有解决,那么就是array和index到底是那里来的,地址在哪里?或者是在自己的源码中定义了array和index,或者是通过extern引用了定义在其他源代码中的array和index,链接器功能正是对.o目标文件中的符号(array,index)进行一个确认,确认该符号来自于哪里,并对该符号进行地址空间的分配。
链接是一个十分重要但现代很多计算机书籍中往往经常忽略掉的一个部分,因此,我们将在下一篇博客中详细的介绍一下链接的内容以及链接到底干了什么事情?

















 6205
6205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









