



 文章介绍了如何在PowerBI中利用字段参数和数值范围参数实现动态TopN分析,涉及创建计算表、度量以及使用SWITCH函数根据选择的维度动态调整排序。同时,提到了使用计算组作为替代方法,并探讨了查看不同维度下特定指标如Margin%的TopN情况。
文章介绍了如何在PowerBI中利用字段参数和数值范围参数实现动态TopN分析,涉及创建计算表、度量以及使用SWITCH函数根据选择的维度动态调整排序。同时,提到了使用计算组作为替代方法,并探讨了查看不同维度下特定指标如Margin%的TopN情况。
我们已经知道了使用字段参数可以实现动态轴,提到动态当然少不了动态topn,在字段组出来前,我们如果想实现多维度自动切换的topn需要使用计算表组合包含我们要切换维度的字段,然后在写度量时还要建立虚拟关系。
那么使用字段参数呢?
首先,创建一个字段参数包含我们要切换的维度字段

因为是topn,再创建一个数值范围的参数表
PtopN = GENERATESERIES(3, 20, 1)
接下来就是需要实现topn,在这之前我们需要获取字段参数当前的值,即是选择了City,还是EnglishProductName。
selected PAxis =
MAXX(
SUMMARIZE(
'PAxis',
'PAxis'[PAxis],
'PAxis'[PAxis 个字段]
),
[PAxis]
)
有了当前字段参数的值,就很简单了
parameter topn =
var x = [PtopN 值]
return
SWITCH(
[Selected PAxis],
"City" , CALCULATE( [Sales Amount], TOPN(x, ALLSELECTED( 'DimGeography'[City]), [Sales Amount]), values( 'DimGeography'[City] )) ,
"EnglishCountryRegionName" , CALCULATE( [Sales Amount], TOPN(x, ALLSELECTED( 'DimGeography'[EnglishCountryRegionName]), [Sales Amount]), values( 'DimGeography'[EnglishCountryRegionName] )) ,
"EnglishProductName" , CALCULATE( [Sales Amount], TOPN(x, ALLSELECTED( 'DimProduct'[EnglishProductName]), [Sales Amount]), values( 'DimProduct'[EnglishProductName] ))
)
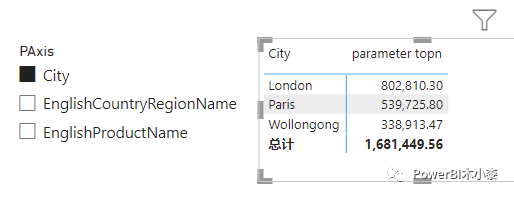
上面的写法限定死了是按Sales Amount进行排序,这里也可以修改为动态的,同样需要先创建一张计算表,包含我们要进行topn筛选的度量名称,这里我们直接使用在字段参数和计算组:多表头矩阵 时创建的计算表
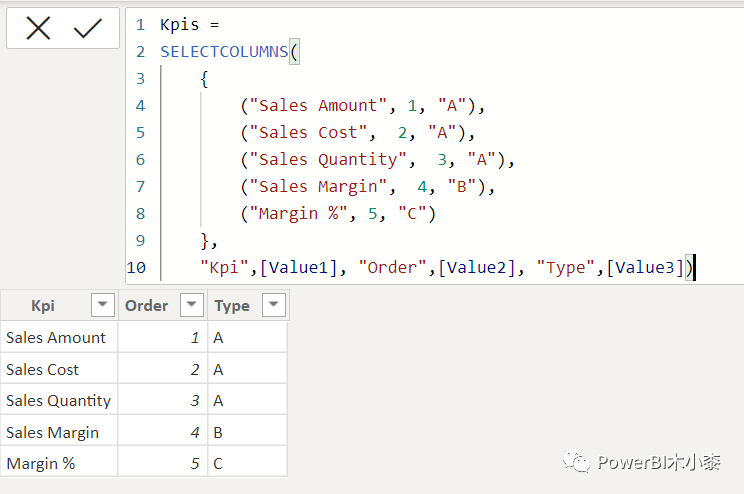
并创建动态融合度量如下
Kpis =
var _sel = SELECTEDVALUE( 'Kpis'[Order] )
return
SWITCH(
_sel,
1, [Sales Amount],
2, [Sales Cost],
3, [Sales Quantity],
4, [Sales Margin],
5, [Margin %],
[Sales Amount]
)
修改topn的度量如下
parameter topn2 =
var x = [PtopN 值]
return
SWITCH(
[Selected PAxis],
"City" , CALCULATE( [Kpis], TOPN(x, ALLSELECTED( 'DimGeography'[City]), [Kpis]), values( 'DimGeography'[City] )) ,
"EnglishCountryRegionName" , CALCULATE( [Kpis], TOPN(x, ALLSELECTED( 'DimGeography'[EnglishCountryRegionName]), [Kpis]), values( 'DimGeography'[EnglishCountryRegionName] )) ,
"EnglishProductName" , CALCULATE( [Kpis], TOPN(x, ALLSELECTED( 'DimProduct'[EnglishProductName]), [Kpis]), values( 'DimProduct'[EnglishProductName] ))
)
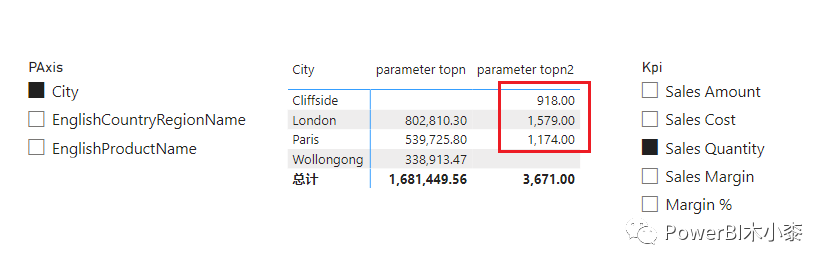
可以看到Sales Amount 和Sales Quantity的top3并不相同,我们也可以直接放到矩阵里查看不同指标的topn
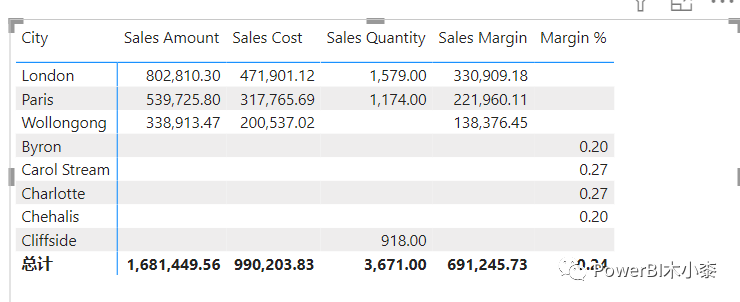
当然我们也可以使用计算组来实现topn的效果,新建一个计算组,然后创建topn的计算项,只是把上述的度量名称替换成了SELECTEDMEASURE()
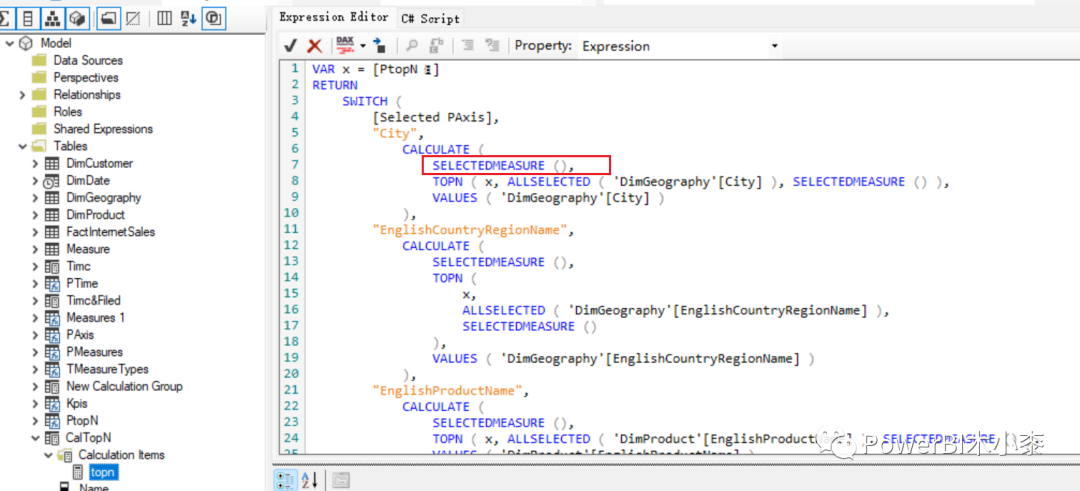
更进一步,如果我们要查看不同维度的Margin % 的topn的所有指标该如何修改呢?

















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









