




 本文详细介绍了Spark核心API,包括Transformation(转化、聚合、排序、连接类算子)、控制类算子、action算子和数据源算子。阐述了各算子的功能、使用场景及实现原理,如转化算子可进行数据加工,控制类算子用于优化计算等,是写出高效Spark代码的基础。
本文详细介绍了Spark核心API,包括Transformation(转化、聚合、排序、连接类算子)、控制类算子、action算子和数据源算子。阐述了各算子的功能、使用场景及实现原理,如转化算子可进行数据加工,控制类算子用于优化计算等,是写出高效Spark代码的基础。
核心 API
spark core API 指的是 spark 预定义好的算子。无论是 spark streaming 或者 Spark SQL 都是基于这些最基础的 API 构建起来的。理解这些核心 API 也是写出高效 Spark 代码的基础。
Transformation
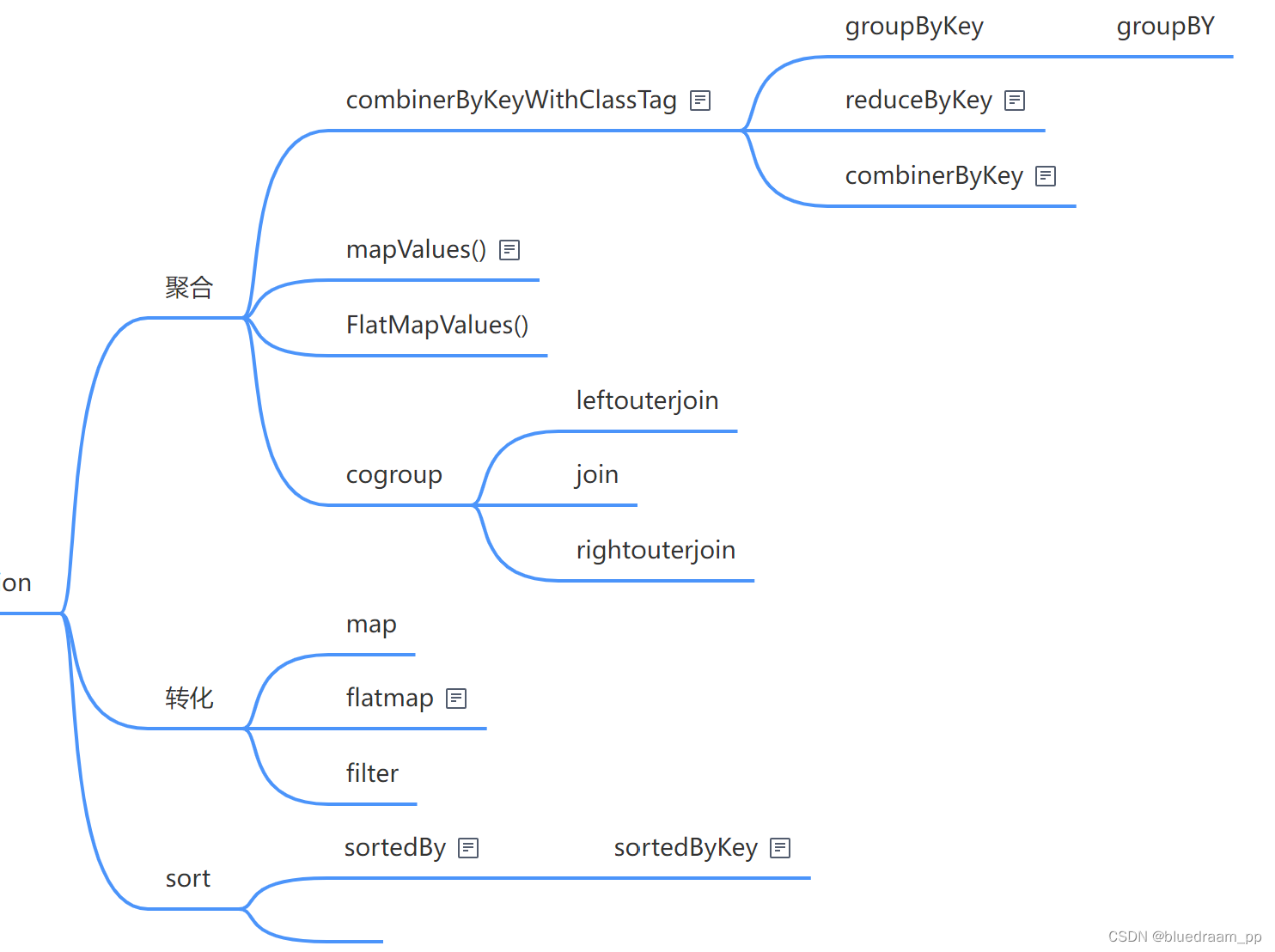
转化类的算子是最多的,学会使用这些算子就应付多数的数据加工需求了。他们有啥呢?可以如下分发:
- 转化算子: map、flatMap、filter
- 聚合算子:reduceByKey、reducerBy、groupBy、groupByKey、conbinerByKey、mapValues、flatMapValues
- 连接算子: cogroup、join、union、leftOuterJoin、rightOuterJoin、union
- 排序算子:sortBy、sortByKey
看起来好多,其实就这四种数据加工操作。他们之间又有实现上依赖关系。如下图所示:
转化算子
在做数据加工的时候,我经常会将某个字段的值进行加工,例如,格式化日期、正则匹配、数据计算、逻辑判断、过滤。 都可以使用转化算子进行加工。举个例子,将过来出 158 开头的手机号,显示出来的电话中间四位替换为*。
import org.apache.spark.{
SparkConf, SparkContext}
object 优快云 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName(优快云.getClass.getCanonicalName)
val sc = new SparkContext(conf)
sc.parallelize(List("15899887112"
, "15799887112"
, "15999887152"
, "15799887192"
)).filter(x => x.startsWith("158"))
.map(x => x.substring(0 , 3) + "****" + x.substring(7 , x.length))
.foreach(println);
}
}
总结一下,map 做的事情就是 A -> B ,filter 是过滤的功能。
flatMap 的功能比较难理解,他是这样的,A -> [B , B , B] ,flatMap 返回的是一个数组。还是用一个例子来说明吧。有如下例子,
| group | player |
|---|---|
| Lakers | James,Davis |
| Celtics | Atum,Borrow |
转化为
| player | group |
|---|---|
| James | Lakers |
| Davis | Lakers |
| Atum | Celtics |
| Borrow | Celtics |
代码是:
val conf = new SparkConf().setMaster("local").setAppName(优快云.getClass.getCanonicalName)
val sc = new SparkContext(conf)
sc.parallelize(List(
("Lakers" , "James,Davis")
,("Celtics" , "Atum,Borrow")
)).flatMap(x => {
x._2.split(",").map(xx => (x._1 , xx))
}).foreach(println)
还有两个和 map 和 flatMap 长的差不多的,分别是 mapValue 和 flatMapValues 两个函数。这两个函数是 PairRDDFunctions 的匿名类中的函数,从 PairRDDFunctions 的名称中可以知道,PairRDDFunctions 是真的键值对的,也就是说 RDD 中的数据是键值对的时候,我们可以调 PairRDDFunctions 的函数,scala 这个功能好像类的被动技能。这是对 RDD 功能一种扩展。说了写废话,还是说回 mapValue 和 flatMapValue ,当这个两个算子接收到 我们字段的函数后,作用到的是 key-value 的 value 上面的, map 和 flapMap 是作用到整个数据上的。例如,我们的数据是 ( James , 37) ,我自定义的函数是 self_define_function , map 和 flatMap 的效果是 self_define_function((James , 37)) , 而 mapValue 和 flatMapValues 则是 (James , self_define_function(value))。
聚合算子
聚合算子包括 combinerByKeyWithClassTag、reduceBykey、reduceBy,然后把数据连接启动的算子:cogroup、join、leftOuterJoin、rightOuterJoin,还有 union 这几个东西。
combinerByKeyWithClassTag 是一个基础类,当明白了它,reduceByKey 和 reduceBy 都会明白了。conbinerByKey 和 Accumulator(累加器) 的计算逻辑一样的。就看一下它的入参吧。
combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)
createCombiner : 是一个函数,此函数的入参是 V 返回的是一个 C , V 和 C 是泛型。此函数的功能是创建一个初始值。
mergeValue :也是一个函数,此函数的入参是 C 和 V 返回的是 V ,此函数会接收各个分区每条数据 V ,然后经过加工,返回的还是一个 C 。
mergeCombiner: 又是一个函数,它是合并各个分区 combiner 后的值。
partitioner: 是分区器,它是用来位每条记录计算分区用的。
mapSideCombiner:这个是设置是否在 shuffle 的过程执行,执行 map-side 的局部聚合。
serializer:是数据序列化器,数据在不同的通过网络间传输的时候,需将数据序列化后传输的,这样可以提高效率。
下面
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









