




 本文深入解析了MySQL如何确保事务的ACID特性,详细介绍了通过undo log和redo log等机制实现原子性、一致性和持久性的方式,同时探讨了隔离级别的概念及其在解决脏读、不可重复读等问题中的应用。
本文深入解析了MySQL如何确保事务的ACID特性,详细介绍了通过undo log和redo log等机制实现原子性、一致性和持久性的方式,同时探讨了隔离级别的概念及其在解决脏读、不可重复读等问题中的应用。
回答这个问题,就要搞清楚 MySql 如何保证事务的 ACID 特性的。当我们弄明白 ACID 是如何实现的,我们页就知道了 Mysql事务的原理。
原子性(Atomic): 原子性。事务中的几个修改数据的操作,要么都做完,要么都不做完。都做完的情况当然皆大欢喜,这是我们想要的情况。那怎么在做完一部分工作之后,取消他们呢?就像编辑器的 ctrl +z 功能。其实也简单,如果我们把对每一行的修改的逆操作保存下来,在需要取消(专业名词是回滚)之前操作的情况下,执行逆操作即可。记录逆操作的就是 undo log 日志。
undo log 日志保存在磁盘的 table spache -> segement ->区 -> page -> row 里面,在一行的末尾保存这 undo log 的指针,指向了此条记录 undo 日志的位置。在 buffer pool 中,也会有 undo log 的缓存区域。
逆操作有那些呢?有多少正向操作就有多少逆向操作。我们来看 DML 中有 update、insert、delete、这几种操作。我们的逆操作也就是针对这些操作了。
1)先来看看 insert 的逆操作,它是最简单的逆操作了,只需在 undo 日志中写入 delete 信息。当需要回滚的时候,执行 delete 操作即可。
2)delete 的逆操作使用了记录上的一个 delete mark 字段来实现的。当在一个事务中,执行了 delete 操作,则 delete_mark 置为 1 。当事务被提交上后,此记录的空间被 Free 列表连接到,此时此条记录的空间就能被重新利用起来。如果此 delete 进行了回滚,则直接将 delete_mark 设置为 0 ,这样就撤销了对这条记录的删除。
3)update 的情况比较特殊,分成了修改主键和不修改主键,当不修改主键的时候,记录在 B+ 树种的位置是不改变的,所以在修改前后数据所占空间的大小不改变的时候,则会直接在上面修改。如果修改后的数据比修改前的数据大,可以在使用原来数据的基础上申请新的空间。修改前的数据会被放到回滚段中,当有需要回滚的时候,在拿出来回滚。这里也涉及到 MVCC 的东西,当修改前的数据放到回滚段之后,是不会被删除的,因为要看事务的隔离级别来定的,如果是 read_commit 级别,则可以在事务没有提交前,读取回滚段中的数据,这样就能读取就得数据了。然后就是主键被更新的情况,采用了 delete mark + insert 的方式来处理的。
当事务中执行 rollback 或者服务器重启的情况,则可以根据据 undo log 来取消没有完成事务前面的操作,实现事务的原子性,也实现了事务的一致性。
一致性(consistence)比较特殊,它不但包含了事务本身的一致性。也包含了业务逻辑的一致性。例如,转账的场景中,如果业务逻辑中只写了在 A 账号减 1000 的,但是没有写在 B 1000 的逻辑,那就不一致了。
隔离性(isolation): 隔离性是多个事务执行执行的时候相关不影响的特性。隔离性有三个问题:脏读、幻读、不可重复读。我们现在有两个事务: A 和 B,我就用这两个事务来说明问题。
脏读:A insert 了一条记录,B 读到了这条记录,然后 B 再读一次,这条记录就没有了。
不可重复读:A 第一个读记录的字段值为 1 ,A 第二次读就成了 2 , 在 A 两次读之间,B 对数据进行修改了。影响了 A 的结果。
幻读:A 两次统计表的数据量,由于在两次中间执行了插入操作,则两次执行的结果不相同。
解决脏读的办法是让 A 只能读到已提交的事务修改。
解决不可重复读可以在其他事务不能更改数据,或者更其他事务可以更改,但是 A 不能看到 B 的更改。
解决幻读的办法是在解决不可重复读的情况下,其他事务不能插入数据,或者A看不到数据的更改。
在编程语言中,往往使用锁来解决进行间协调的问题。所以在 Mysql 中也可以使用锁来解读这些问题。
- lock tables read ,表级别共享锁,其他的事务就不能对表做插入、修改,只能读操作。所以它能解决脏读、幻读、不可重复读。
- lock tables write 表级别的独占锁。其他的事务对表什么也做不了。所以它能解决脏读、幻读、不可重复读。
- select … iock in share mode (只读行级锁); 其他的事务只对锁定的行做读操作,但是可以插入新数据。所以不能解决幻读,可以解决脏读和不可重复读。
- select … for updte 和 in lock share mode 的效果是一样的。
上锁固然能解决问题,但是在高并发的情况下,吞吐量就上不去了。因为只能串行的执行更新、插入语句。
还有一个空间换时间的法子,那就是 MVCC 这东西。这个核心思想是在事务没有提交之前,我把所有的修改的版本都记录下来,并且使用链表的方式记录下来前后关系。然后根据提交情况和隔离级别解决这个问题。例如下图中:
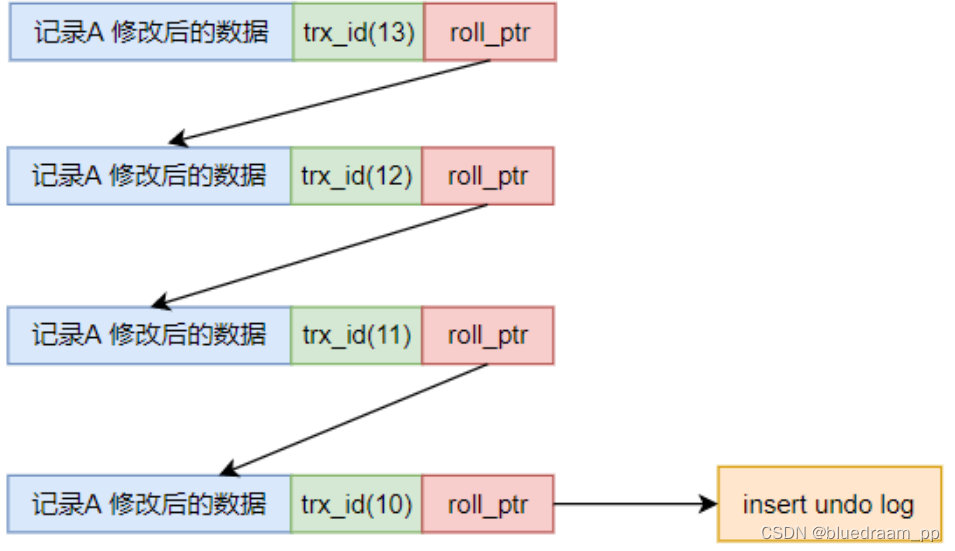
记录A 被多次的修改,但是都没有提交事务。B 事务读取记录A。
read uncommit 的实现。B 事务在读取记录A 的时候,直接读事务 11 的最新的记录。
read commit 的实现。B 事务,在执行 select 执行之前,会先获取一个 ReadView 试图,在试图中,可以知道那些 undo 能读那些不能读。ReadView(m_id , min_trx_id , max_trx_id , creator_trx_id):
从 ReadView 中查找的那些 undo 日志是提交的,那些是没有提交的,如果提交的是可以读取的,如果没有提交的是不可以读取的。需要注意的是,两次执行 select 语句之前都会更新 ReadView 视图。
repeatable read 的实现。只有在第二次执行 select 语句之前,不能更新 ReadView 就行了,这样当其他的事务提交之后,本事务在遍历版本链的时候,也会跳过的,所以就实现了可重复读。可以部分解决幻读的情况,但是 Mysql 存在 Bug ,有些场景下,不能解决幻读的。在读的事务中,执行 update 某条(此记录刚被其他的事务插入)记录后,这样本事务在事务链条上增加了一个自己的节点,我自己的节点总可以读取了吧,于是乎,拐了一个弯,幻读又被打破了。
持久性(duration):
从硬件的角度来说,利用的是磁盘断电不丢数据的特性。为什么这样说呢?如果说 CPU 计算出来的数据直接放到磁盘,那就没有所谓的持久性问题了。但是为什么不这样做呢?因为 CPU 的计算速度是在是比磁盘的读写速度大太多了。举个例子,从上海运一批疫苗到巴基斯坦,然后用汽车运送到各个城市,飞机是不能等着起车运送完了再运送下一趟。因为他们两个速度相差太大了。如果 CPU 计算出数据来之后,等待磁盘写好数据,那 CPU 的利用率将会很低。这就有要有缓存的存在。缓存的一次是,每当 CPU 计算完数据之后,就把数据放到缓存中,放完就走,继续计算其他的数据,这样就能显著提高 CPU 的使用效率。
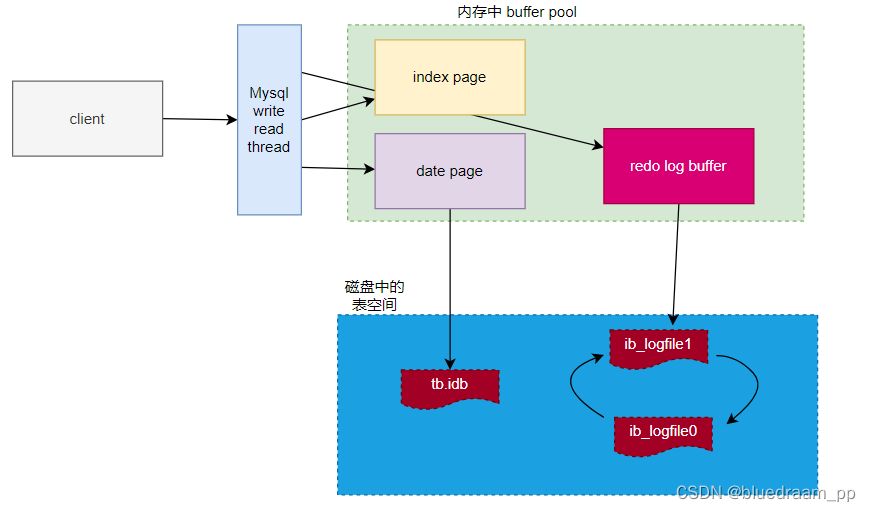
MySql 也是用了这个策略,这个缓存叫做 Buffer pool 。CRUD 的结果数据都会放到 Buffer pool 中。这就会存在一个问题,如果事务执行到一半,有几个 updtate 操作更新了 buffer pool 中的数据,但是没有来得及把 buffer pool 中的数据写入到磁盘中,那不就把事务做得更新操作丢失了嘛。那怎么办呢?
MySql 使用了 write ahead log 策略。就是把对 buffer pool 的更改先不作用于 buffer pool ,而是先做成日志文件中。然后再做 buffer pool 的更新。哎,这里有个疑问,为什么可以把更新写入磁盘的日志文件中,那为什么不把数据直接到相应的表空间中呢?不到写到磁盘里面吗?
答案是写日志是 appead 的过程是顺序的写入磁盘。但是写表空间是随机的写磁盘。两者的效率相差非常大。顺序写是非常快的。这也是利用了磁盘顺序写效率高的特点。才会这样设计的。
刚才所说的日志就是 redo log 日志。redo log 的格式是:
|type | table space number | page number | offset | data |
type : 更新类型
table space number : 表空间编号
page number : 页编号
data : 具体要更新的数据
从 redo log 的格式来看,它是直接更新 buffer pool 中缓存页中的数据的。
如果我们有一个完整事务产生的 redo log 就能重现事务对磁盘所作的所有操作。所以即使事务 commit 之后,即使 buffer pool 中的数据没有刷新到磁盘中,也能根据 redo log 把数据找回来,然后写入到磁盘中。

















 3854
3854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









