




我在讲什么
空间换时间这样的思路,在编程算法、硬件设计灯、战争领域都是有涉及的,我这里所讲的空间换时间是被包含在数据仓库范畴里面的。空间换时间,我的理解是什么呢?就是我们需要设计一种数据结构,这种数据结构最大的特点是提高查询的效率。我在这里总结一下,空间换时间的做法。
拉宽
在业务系统里面,一般会按照数据库的三范式来设计表的结构。来,我们先看看三范式是什么?
- 第一范式: 相似的属性只能放到一列里面。也就说一列都是一种属性,不能出现第二种属性。另外,两列里面不能有相似的属性内容。
- 第二范式: 在第一范式的基础上,如果表里面的每一行都能被唯一的标识,则这个表的设计符合第二范式。这是在说记录和记录之间的原子性。也就是说,每条记录每应该有一组唯一标识它的主键。
- 第三范式: 在第二范式的基础上,属性不依赖于其它非主属性 属性直接依赖于主键。
符合这三范式的表会具有高内聚,低耦合的特定,也就是往往相关的内容会分割到一个表里面。
如下图所示一个商品模块的数据库设计。
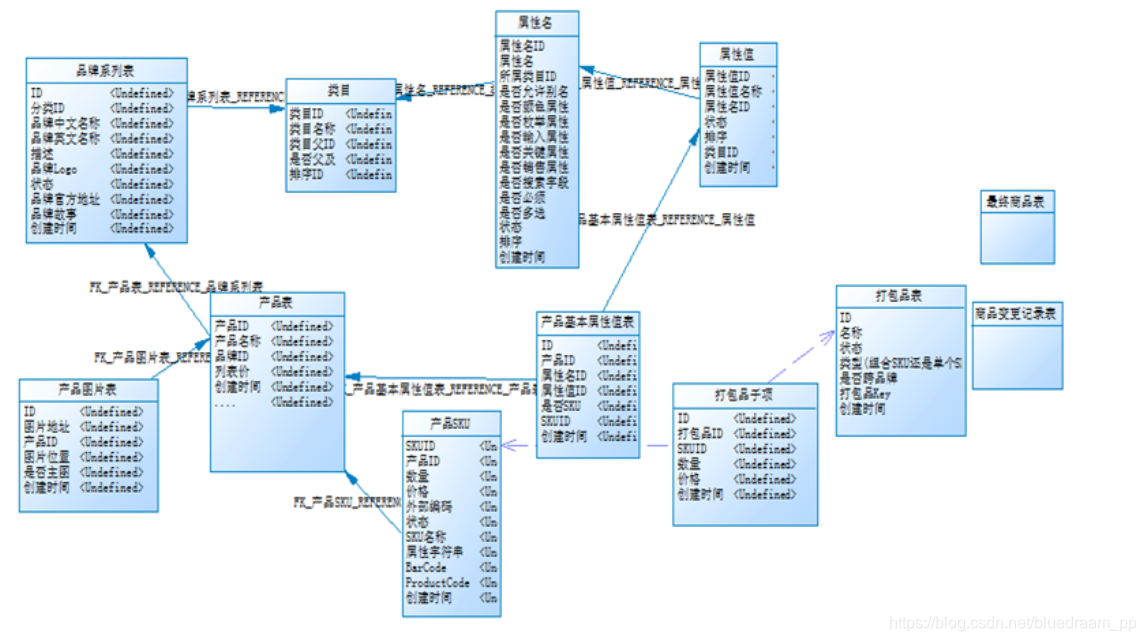
我们看到商品各个维度的属性都放到不同的表里面,这样的做会减少冗余数据的产生,大大的节约存储空间。但是利于我们快速的查询商品的属性,在数仓里面,我们会将商品相关属性关联起来放到一表里面。例如,在电商的场景下,我们经常会做一个商品的分类表。我们的做法是将类目、属性名、产品基本属性值表、属性值这几张表 join 到一起,形成一个表。
这种做法就是一种非常常见的空间换时间的做法,我们知道如果我们想知道商品的某种属性的名称和值,那我们需要将类目、属性名、产品几步属性值表、属性值这几张表 join 起来,join 是需要时间来计算的,这不好,我们可以预先将这几个表 join 到一起形成一个表,这样的话,我们在每次查询的过程中,是不是就不用 join 这种操作了,只是会增加一些冗余的数据。不过这就是空间换时间的代价。
说了这么多,数据拉宽到底是个什么东西呢?你看我们上面我们把几个表放到一个表里面,是不是好像把表拉宽以后,把数据放到一个表里面了,目标表我们通常叫做宽表。这就是所谓的拉宽操作。
上面提到的 join 方式是拉宽的一种形式。还有另外一种形式。
我们以折现图为例子,加入我们需要设计一个表来保存折现图里面的数据,应该如何设计呢?
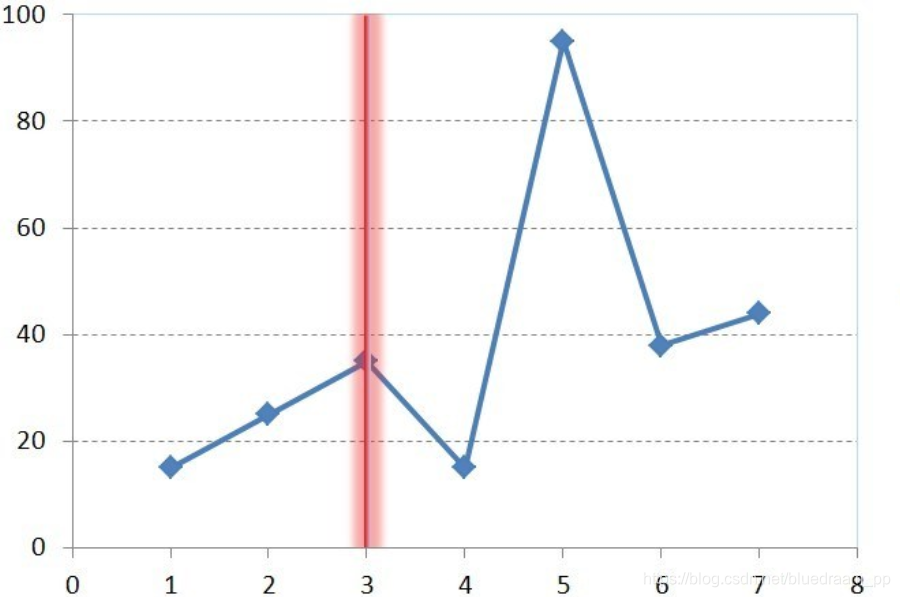
我们可以设计成如下的结构:
| 字段名字 | 字段解释 |
|---|---|
| x轴坐标 | |
| y轴坐标 |
这样会产生 8 条记录。对我们查询系统来说。还有更快的设计。
| 字段名字 | 字段解释 |
|---|---|
| 1 对应 x 轴的坐标 | 1 对应 y 轴坐标 |
| 2 对应 x 轴的坐标 | 2 对应 y 轴坐标 |
| 3 对应 x 轴的坐标 | 3 对应 y 轴坐标 |
| 4 对应 x 轴的坐标 | 4 对应 y 轴坐标 |
| 5 对应 x 轴的坐标 | 5 对应 y 轴坐标 |
| 6 对应 x 轴的坐标 | 6 对应 y 轴坐标 |
| 7 对应 x 轴的坐标 | 7 对应 y 轴坐标 |
| 8 对应 x 轴的坐标 | 8 对应 y 轴坐标 |
这样设计呢?我们是不是一条记录就可以差到所有需要的数据,看起来是不是也是把数据拉宽了。
有的时候增强数据的对标效果,我们也会将数据拉宽处理。例如下面的 GDP。为更直观对比每个季度 GDP 的数值,我们通常会将各个季度数据拉宽。
 另外还有一种处理日志的拉宽。例如,互联网出租车业务中,常常会记录下来每司机的在线情况。日志是下面的这种格式:
另外还有一种处理日志的拉宽。例如,互联网出租车业务中,常常会记录下来每司机的在线情况。日志是下面的这种格式:
| 字段名称 | 字段说明 |
|---|---|
| 司机名称 | |
| 打点时间 |
我可以中打点一般会每隔一段时间回传到服务器。假设每 5 分钟回传一次吧。我们可以在一个字段里面,保存一系列的 0 1 ,第一个位置是 1 代表在线,0 代表不在线。则1和 0 的位置代表了时间。
举个拉宽以后的例子吧。
10
| 司机名称 | 打点数据 |
|---|---|
| 张三 | 111100001010101010101010100101010101 … |
一天有 24 小时,就有 24*60/5 = 288 个点。大点数据哪里一共有 288 个 0 和 1 。 每个 0 或者 1 代表在那个时间点司机师傅是否在线。
预计算
预计算就是将可能用到的指标先计算出来放到哪里,等用到的时候,之间拿出来用的做法。例如,还是以电商为例子,肯定会计算每个城市下面的销售额。那我们会想到会不会用到每个省下面的销售额?不管有没有,我们先计算出来再说。虽然存在暂时没有用的情况,但是其实再写 sql 或者其他实现方式的时候,工作量是差不多的,占用的空间也是有限的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









