




 本文详细介绍了正则表达式的基拙概念和高级用法,覆盖元字符、重复、范围、逻辑运算、分组、简写字符集等内容,并通过实例演示了如何在Python、Java等语言中应用正则表达式进行文本处理。
本文详细介绍了正则表达式的基拙概念和高级用法,覆盖元字符、重复、范围、逻辑运算、分组、简写字符集等内容,并通过实例演示了如何在Python、Java等语言中应用正则表达式进行文本处理。
如何做
- 整合之前学习成果。包括 evernote、youdaonode 里面的东西。
- 探索 Linux 里面的正则表达式
- python 里面的正则表达式
- Java 里面的正则表达式
- 通用型的正则表达式
好的学习资源
基础的部分
-
元字符,就是组成计算所有文本的基本元素,例如,字符、标点符号、文字,总之,就是我们能在键盘上敲出来的东西
-
重复,描述了让元字符重复多少次的语法
-
描述开头和结束的语法
-
描述范围的语法
-
或逻辑
-
分组
-
简写字符集
.代表所有的字符
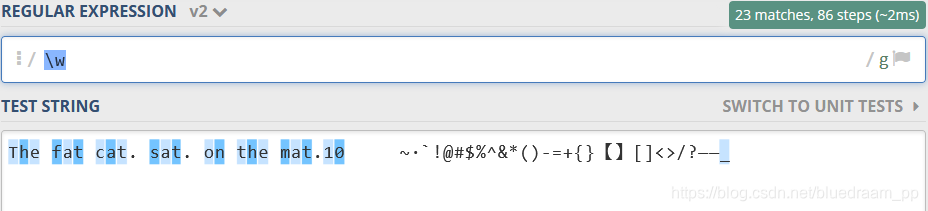
\w(word) 代表所有的字母和数字,相当于 [a-zA-Z0-9_]
在下面的图中,我们看到键盘上的字母、数字和_都匹配上了。
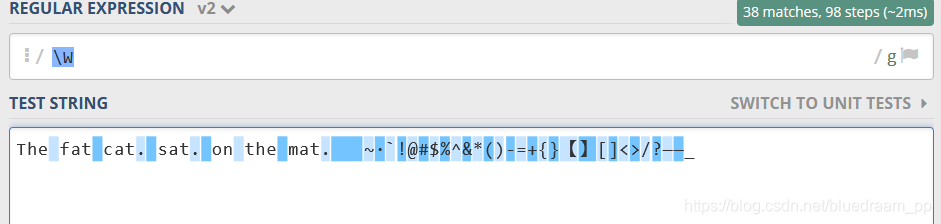
\W和\w正好相反,只要\w匹配不到得,\W都能匹配上
如下所示,空格和所有键盘上非字母的字符都匹配上了,不过还有一个漏网之鱼 _ ,这个哥们是在 \w 里面的
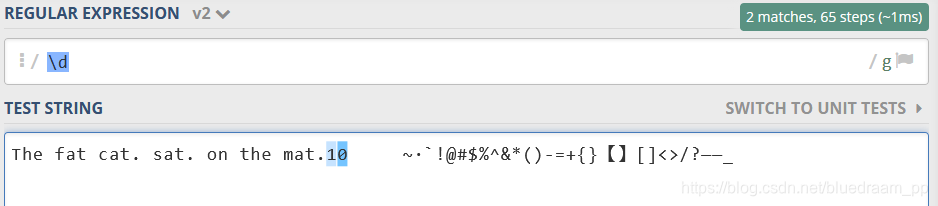
\d(digital) 匹配数字,类似 [0-9]
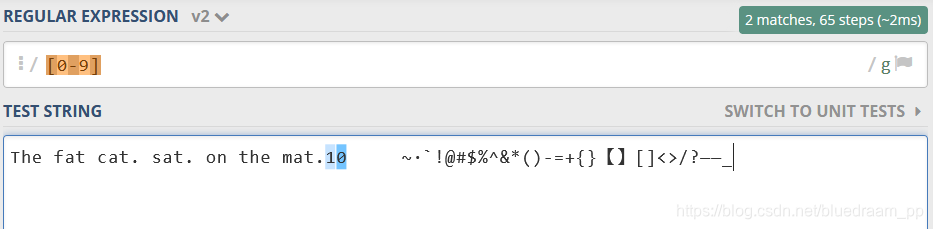
\D(non-digital) 不是数字的那些字符,[^0-9]
如下图,只有数字没有匹配到


\f匹配一个换页符
目前还没有找到这个字符如何
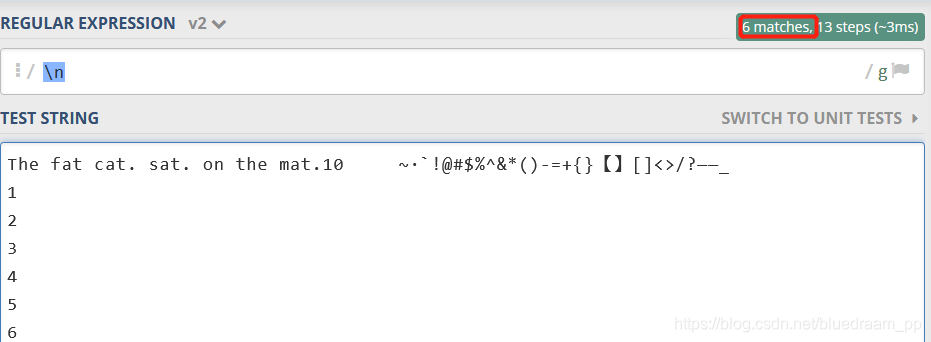
\n匹配一个符号,这个符号代表了一个新行的开始
如下图所示,有 7 行,\n 匹配到 6 个新行的开始
 >
> \r 匹配一个回车字符
目前没有用到。
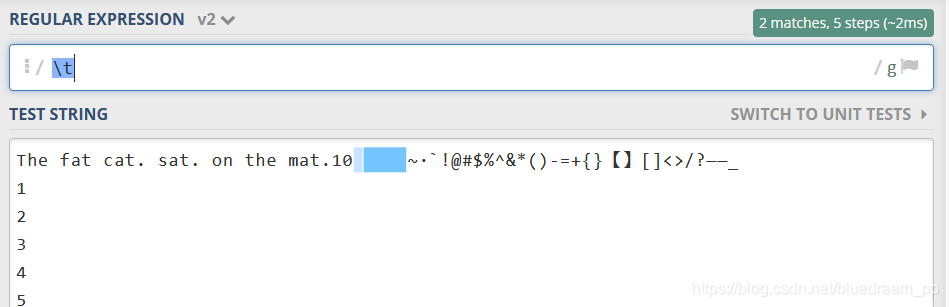
\t制表符
\v匹配一个垂直制表符
用的不多
\p匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符
用的不多
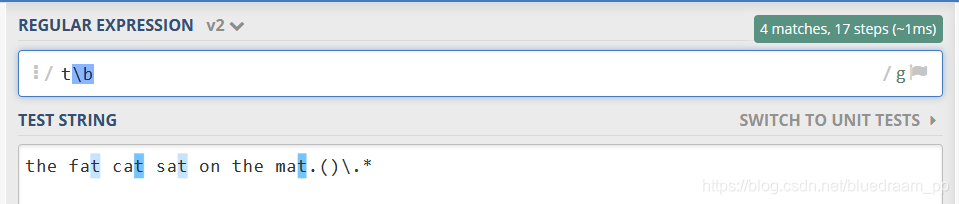
\bMatches, without consuming any characters, immediately between a character matched by \w and a character not matched by \w (in either order). It cannot be used to separate non words from words.
\b只能和字符(\w)组合使用,表示字符的后面是 \W,如下图所示,第一个 t 没有匹配上,后面都匹配上了,\b 不会匹配任何字符,只是作为一个参照。
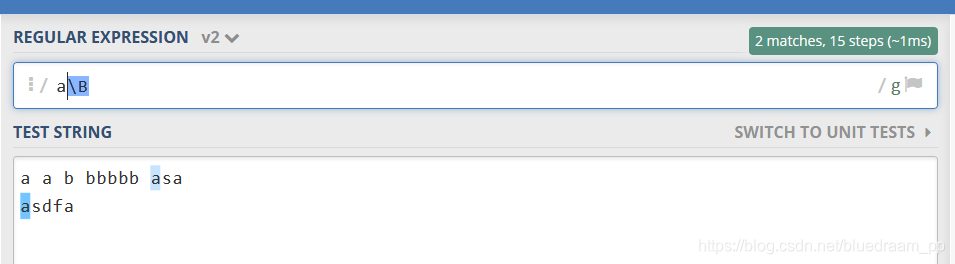
\B, 匹配那些\b匹配不到的\w
如下图所示,后面有空格的 a 没有匹配上。\b不匹配任何的字符,只是做为一个参照,在下面的图中只匹配到了 a
8. 转义,一般的情况,我们可以是 \来将特殊的字符转成普通字符
如下图所示,(和)是分组含义,在正则表达的保留字符,在保留字符的前面加上\就可以匹配了。
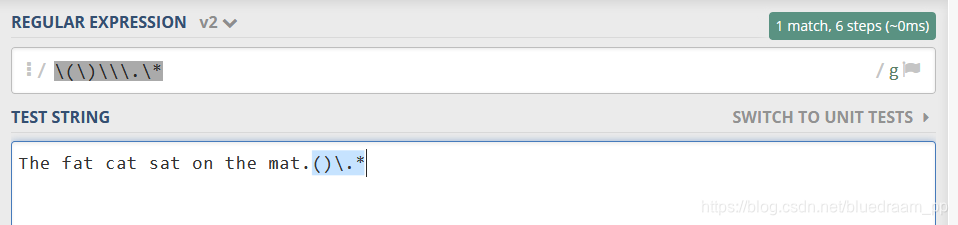
\s匹配所有空格字符,等同于: [\t\n\f\r\p{Z}]
\s 代表所有不可见字符。
\S,就是 [^\s]
进阶的部分
- 零宽断言
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 |
| ?! | 负先行断言-排除 |
| ?<= | 正后发断言-存在 |
| ?<! | 负后发断言-排除 |
有的时候,我们之前匹配到的两种字符串之间的字符串,例如,
select * from table_name where field_name = 'aaa' ;
想从上面这个字符串里面匹配到 table_name。
.*(?=\swhere)
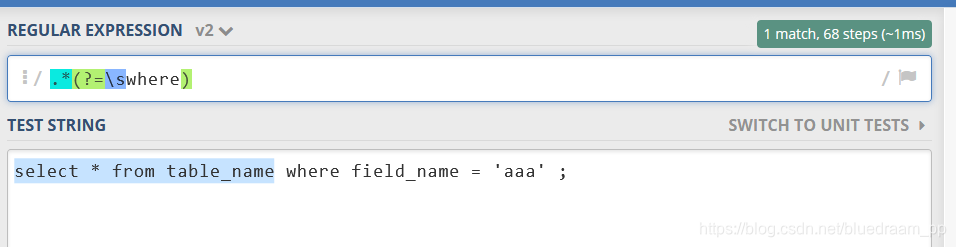
(?<=from\s).*(?=\swhere)
\\1' , '\\1')
- 贪婪和非贪婪
- 反义
select regexp_replace('18712344321' , '(?<=\\d{3})\\d{4}(?=\\d{4})' , '****')
select regexp_replace('2020-01-01' , '(20)\\1' , '')
select regexp_replace('2020-01-01 00:00:00' , '[-: ]' , '')
select regexp_replace('2020-01-01 00:00:00' , '[-: ]' , '')
select regexp_replace('2020-01-01 00:00:00' , '(?<=\\d{4}-\\d{2}-\\d{2}).*' ,'')
select regexp_replace('00:00' , '\\d{2}:00' , '' )
select regexp_replace('hello world' , '(hello|world)' , '')
select regexp_extract('hello world' , '(hello|world)')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









