





文章目录
- Linux Shell 与 Shell 脚本编程简介
- 1 什么是内核
- 2 什么是 Shell
- 3 什么是终端
- 4 Shell 脚本
- 5 如何在 Linux 创建一个 Shell 脚本
- 6 Linux 中的不同 Shell
- 7 Linux 中的基本 Shell 命令
- 8 Linux 目录结构
- 9 Linux 中的输入输出重定向
- 10 Shell 脚本——Shell 变量
- 11 Shell 脚本——变量名命名规则
- 12 Shell 脚本中的字符串操作
- 13 Shell 脚本中的数组基础知识
- 14 条件语句 | Shell 脚本
- 15 循环语句 | Shell 脚本
- 16 Linux 中的 break 与 continue 关键字(附示例)
- 17 Shell 脚本——函数及其类型
- 18 如何传递和解析 Linux Bash 脚本参数和参数
- 19 Shell 脚本 | 标准输入,输出与错误
- 20 对文件执行操作的 Shell 脚本
- 21 Shell 脚本举例说明特殊参数
- 22 Linux 中的用户空间调试工具
- 23 如何在 Linux 上使用正则表达式(RegEx)
- 24 Shell 脚本注释
- 25 Shell 脚本示例与工程
- 参考资料
Linux Shell 与 Shell 脚本编程简介
如果我们使用任何主要的操作系统,我们都是间接地在与 shell 交互。当运行 Ubuntu, Linux Mint 或任何其他 Linux 发行版本,我们通常使用终端与 shell 进行交互。在本文中,我们将讨论 Linux shell 与 shell 脚本编程,因此在理解 shell 脚本编程之前,我们必须熟悉以下术语:
- 内核
- Shell
- 终端
1 什么是内核
内核是一个计算机程序,是计算机操作系统的核心,可以完全控制系统中的一切。它管理 Linux 系统的以下资源:
- 文件管理
- 进程管理
- 输入/输出管理
- 内存管理
- 设备管理等
人们经常误以为 Linus Torvalds 开发了 Linux 操作系统,但实际上,他只负责 Linux 内核的开发。
完整的 Linux 系统 = 内核 + GNU 系统工具与库 + 其他管理脚本 + 安装脚本。
2 什么是 Shell
Shell 是一种特殊的用户程序,为用户提供使用操作系统服务的接口。Shell 接受用户发出的可读命令,并将其转换为内核能够理解的内容。它是一个命令语言解释器,用于执行从键盘等输入设备或文件中读取的命令。当用户登录或启动终端时,shell 就会启动。
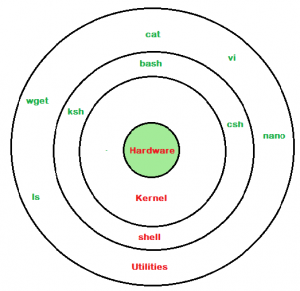
Shell 大致分为两类:
- 命令行 Shell
- 图形化 Shell
2.1 命令行 Shell
用户可以使用命令行界面访问 Shell。在 Linux/macOS 称为终端,或在 Windows 操作系统中称为命令提示符的特殊程序,用于键入人类可读的命令,如「cat」,「ls」等,然后执行。然后将结果显示在终端给用户。Ubuntu 16.04 系统中的终端如下所示:
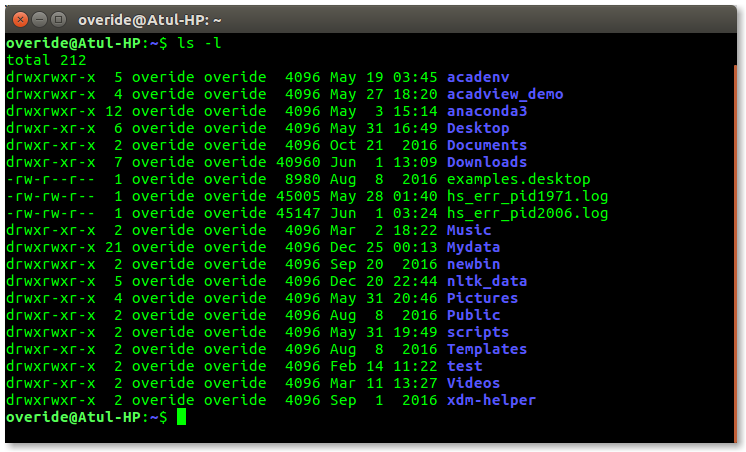
在上面的屏幕截图中「ls」命令带着「-l」选项执行。它将以长列表格式列出当前工作目录中的所有文件。
对于初学者来说,使用命令行 shell 有点困难,因为很难记住这么多命令。它非常强大;它允许用户将命令存储在一个文件中并一起执行。这样,任何重复的任务都可以很容易地自动化。这些文件在 Windows 中通常称为批处理文件,在 Linux/macOS 系统中称为 Shell 脚本。
2.2 图形化 Shell
图形化 Shell 通过允许诸如打开、关闭、移动和调整窗口大小以及在窗口之间切换焦点之类的操作,提供了基于图形用户界面(GUI, graphical user interface)操纵程序的手段。Window 操作系统或 Ubuntu 操作系统可以被认为是一个很好的例子,它为用户提供了与程序交互的 GUI。用户不需要为每个操作键入命令。Ubuntu 系统中的典型 GUI:
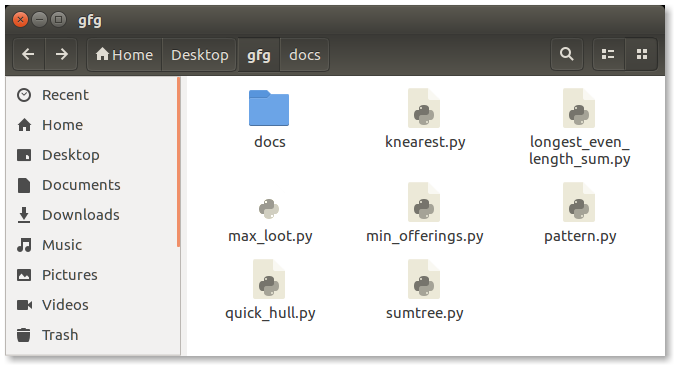
有几个 shell 可用于 Linux 系统,例如:
- BASH(Bourne Again SHell)—— 它是 Linux 系统中使用最广泛的 shell,它在 Linux 系统和 macOS 中用作默认登录 shell,它也可以安装在 Windows 操作系统上。
- CSH(C SHell)—— C shell 的语法及其用法与 C 编程语言非常相似。
- KSH(Korn SHell)—— Korn Shell 也是 POSIX Shell 标准规范等的基础。
每个 shell 执行相同的工作,但理解不同的命令并提供不同的内置功能。
3 什么是终端
一种程序,负责为用户提供接口,以便他/她可以访问 shell。它基本上允许用户在基于文本的界面中输入命令并查看这些命令的输出。为自动化和执行复杂任务而编写的大型脚本在终端中执行。
要访问终端,只需在搜索框中输入「terminal」并双击即可。
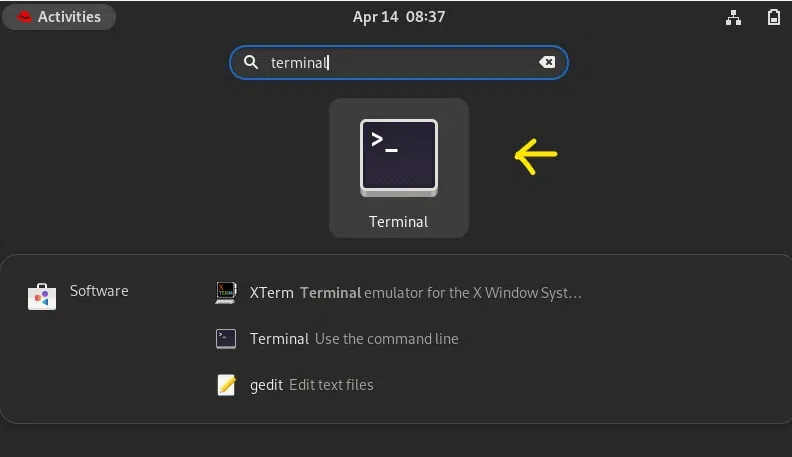
在这里,您可以看到 Red Hat Linux 的终端外观。
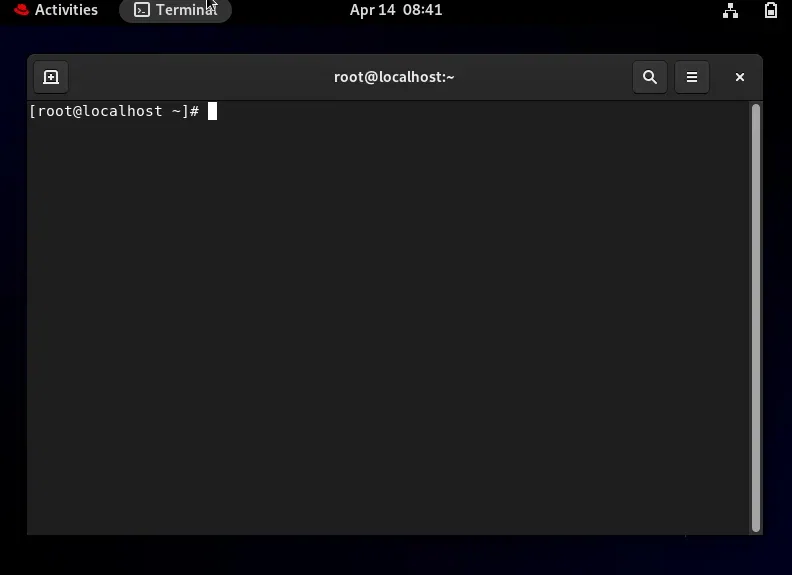
4 Shell 脚本
通常,shell 是交互式的,这意味着它们接受来自用户的命令作为输入并执行它们。然而,有时我们想例行地执行一堆命令,所以每次都必须在终端中键入所有命令。
由于 shell 也可以从文件中获取命令作为输入,我们可以将这些命令写入文件中,并在 shell 中执行它们,以避免这种重复的工作。这些文件被称为 Shell 脚本或 Shell 程序。Shell 脚本类似于 MS-DOS 中的批处理文件。每个 shell 脚本都以「.sh」文件扩展名保存,例如 myscript.sh。
shell 脚本的语法与任何其他编程语言一样。如果你以前有任何编程语言的经验,比如 Python、C/C++ 等,那么很容易上手。
shell 脚本包括以下元素:
- Shell 关键字 —— if、else、break 等。
- Shell 命令 —— cd、ls、echo、pwd、touch 等。
- 函数
- 控制流 —— if…then…else,case 和 shell 循环等。
4.1 为什么我们需要 shell 脚本
编写 shell 脚本的原因有很多:
- 避免重复工作和自动化
- 系统管理员使用 shell 脚本进行例行备份。
- 系统监控
- 为 shell 添加新函数等。
4.2 shell 脚本的一些优点
- 命令和语法与直接在命令行中输入的命令和语法完全相同,因此程序员不需要切换到完全不同的语法
- 编写 shell 脚本要快得多
- 快速启动
- 交互式调试等。
4.3 shell 脚本的一些缺点
- 容易出现代价高昂的错误,一个错误就可以更改命令,这可能是有害的。
- 执行速度慢
- 语言语法或实现中的设计缺陷
- 不太适合大型复杂任务
- 提供与其他脚本语言不同的最小数据结构等
4.4 使用 Bash shell 编写 shell 脚本的简单演示
如果你在一个终端上工作,你可以在目录中深入遍历一些东西。然后,对于路径中即将出现的几个目录,我们必须执行如下所示的命令,以进入「python」目录:
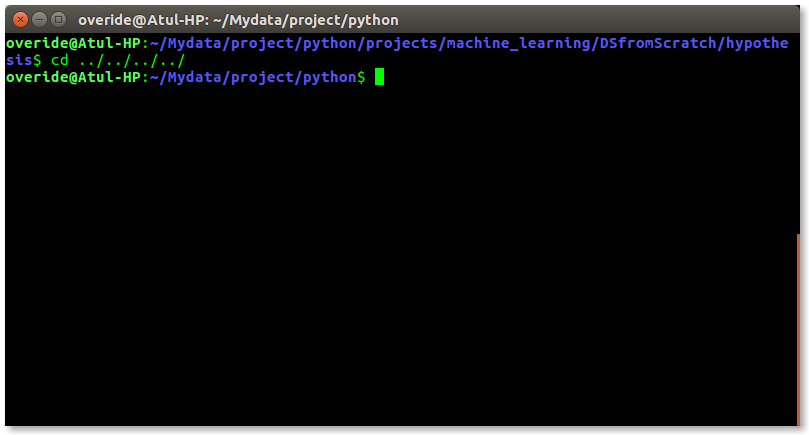
这是非常令人沮丧的,所以我们为什么不可以有一个实用程序,我们只需要键入目录的名称,就可以直接跳转到该名称,而无需反复执行「cd…/」命令。将脚本另存为「jump.sh」
#!/bin/bash
# A simple bash script to move up to desired directory level directly
function jump()
{
# original value of Internal Field Separator
OLDIFS=$IFS
# setting field separator to "/"
IFS=/
# converting working path into array of directories in path
# eg. /my/path/is/like/this
# into [, my, path, is, like, this]
path_arr=($PWD)
# setting IFS to original value
IFS=$OLDIFS
local pos=-1
# ${path_arr[@]} gives all the values in path_arr
for dir in "${path_arr[@]}"
do
# find the number of directories to move up to
# reach at target directory
pos=$[$pos+1]
if [ "$1" = "$dir" ];then
# length of the path_arr
dir_in_path=${#path_arr[@]}
#current working directory
cwd=$PWD
limit=$[$dir_in_path-$pos-1]
for ((i=0; i<limit; i++))
do
cwd=$cwd/..
done
cd $cwd
break
fi
done
}
目前,我们无法执行 shell 脚本,因为它没有权限。我们必须通过键入以下命令使其可执行 ——
$ chmod +x path/to/our/file/jump.sh
现在,为了在每个终端会话中都能使用它,我们必须将它放在「.bashrc」文件中。
「.bashrc」是一个 shell 脚本,每当以交互方式启动时,Bash-shell 都会运行该脚本。.bashrc 文件的目的是提供一个地方,您可以在这里设置变量、函数和别名,定义我们的提示,并定义我们在打开新的终端窗口时要使用的其他设置。
现在打开终端并键入以下命令:
$ echo "source ~/path/to/our/file/jump.sh">> ~/.bashrc
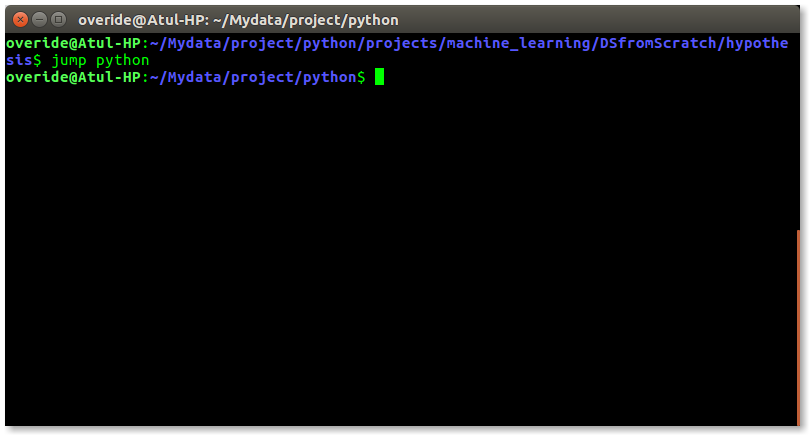
现在打开您的终端,输入以下命令来尝试新的「jump」函数 ——
$ jump dir_name
就像下面的屏幕截图一样:
5 如何在 Linux 创建一个 Shell 脚本
Shell 是操作系统的一个接口。它接受来自用户的命令,并将它们解释给操作系统。如果你想同时运行一堆命令,你可以通过创建一个 shell 脚本来实现。如果您需要定期执行任务(如备份),Shell 脚本非常有用。只需一个脚本,就可以列出这些命令并全部执行。让我们看看如何创建一个 shell 脚本并在 Linux 上运行它。
5.1 创建 Shell 脚本
登录到您的 Linux 系统并打开终端,导航到要存储 shell 脚本的文件夹。Shell 脚本以扩展名「.sh」结尾。让我们创建我们的第一个 shell 脚本。键入
touch script.sh
现在,这个脚本文件在默认情况下是不可执行的,我们必须给这个文件可执行的权限。键入
chmod +x script.sh
现在,我们将向这个 shell 脚本添加一些命令。使用您选择的任何文本编辑器(基于命令行或基于 GUI)打开此shell 脚本,并添加一些命令。我们将使用 nano。键入
nano script.sh
添加以下命令来测试此 shell 脚本
echo This is my first shell script
touch testfile
ls
echo End of my shell script
保存更改,然后运行 shell 脚本通过输入
./script.sh
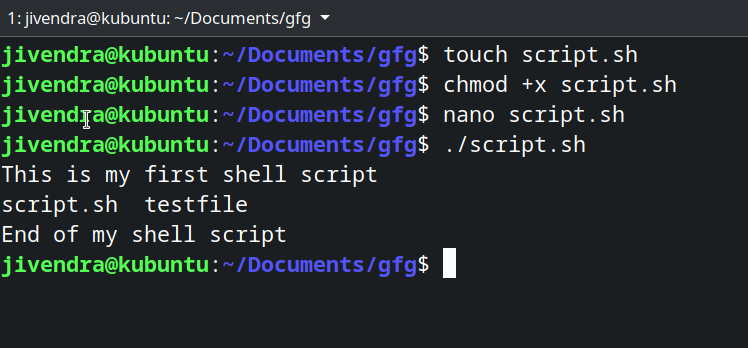
你可以看到,它执行了所有指定的命令。
5.2 shell 脚本中的注释
shell 脚本中任何以「#」开头的行都将被视为注释,并且在执行过程中被 shell 忽略,但 shebang 行除外,我们将在本文后面看到它。让我们看一个例子。将创建一个包含以下内容的 shell 脚本。
# This is a comment
echo Testing comments in shell script
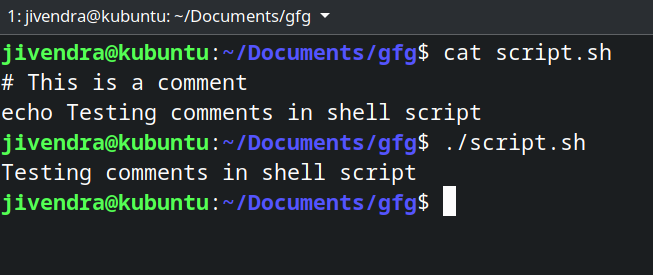
你可以看到,注释被忽略了。
5.3 Shell 脚本中的变量
是的,Shell 脚本支持使用变量,并且我们不需要在声明变量时定义变量的类型。有两种类型的变量:
- 系统定义变量
- 用户定义变量
系统定义的变量,也称为环境变量,通常是资本化的(Capitalised)。您可以使用 printenv 命令查看所有当前环境变量。用户定义的变量由用户设置,并且它们仅在脚本执行期间存在。您可以通过简单地键入变量名称并用「=」符号赋值来定义变量,并通过在变量名称前添加「$」来访问变量。下面的示例脚本演示了变量。
# Accessing an Environment Variable
echo $USER
# Creating and accessing User defined Variable
variable_name="Geeksforgeeks"
echo $variable_name
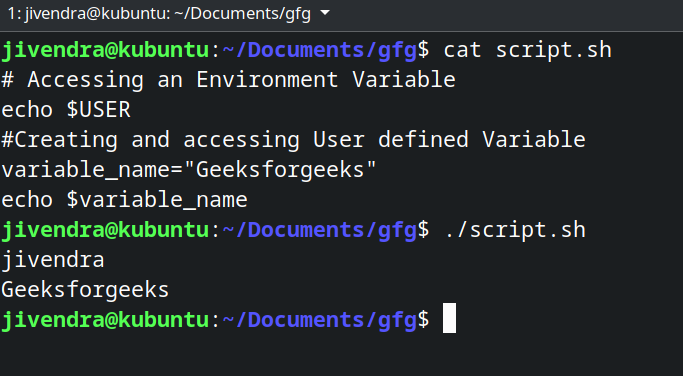
5.4 定义 Shell 脚本解释器
Linux 中有许多可用的 shell,如 bourne shell(sh)、Korn shell(ksh)和 GNU Bourne-Again Shell(bash)。为 sh shell 编写的脚本称为 shell 脚本,它们可以由 ksh 和 bash shell 进行解释。ksh 和 Bash 是原始 sh shell 的改进版本,它们比 sh 有更多的功能。Bash 通常是大多数 Linux 发行版中的默认 shell,专门为 Bash shell 编写的脚本称为 Bash 脚本。
您可以指定脚本将使用哪个 shell,即使脚本是从另一个 shell 终端执行的。要执行此操作,请在脚本文件顶部添加 #!,然后添加所选 shell 的绝对路径。要指定 bash 作为解释器,请在 shell 脚本顶部添加以下行。
#!/bin/bash
这一行被称为 shebang 行。
注意: 只有在您的系统上安装了 bash 时,这才会起作用。
5.5 比较运算符
您可以在 shell 脚本中比较两个变量。我们进行这些比较是为了做出决定,我们将在本文后面看到如何做到这一点,但在此之前,这里列出了一些比较运算符。
整数比较
| Operator | Description |
|---|---|
| -eq | is equal to |
| -ne | is not equal to |
| -gt | is greater than |
| -ge | is greater than or equal to |
| -lt | is less than |
| -le | is less than or equal to |
字符串比较
| Operator | Description |
|---|---|
| == | is equal to |
| != | is not equal to |
| \< | is less than, in ASCII alphabetical order |
| \> | is greater than, in ASCII alphabetical order |
我们在 < 和 > 之前添加了一个 \,因为在 [ ] 条件判断体中键入它们时需要对它们进行转义。现在,让我们看看这些在哪里使用。
5.6 条件语句
条件语句用于仅在满足某些条件时执行代码块。Shell 脚本支持使用条件语句,我们使用比较运算符来检查条件。让我们看看一些条件语句。
5.6.1 if 语句
它检查条件,如果条件为 true,则执行命令。
语法
if [ condition ]
then
#statements
fi
让我们看一个示例。
#!/bin/sh
x=10
y=11
if [ $x -ne $y ]
then
echo "Not equal"
fi
运行结果:
$ ./script.sh
Not equal
5.6.2 if-else 语句
在 if-else 语句中,如果不满足条件,可以指定一组要运行的命令。
语法
if [ condition ]
then
#set of statements if the condition is true
else
#set of statements if the condition is false
fi
让我们看一个示例。
#!/bin/sh
x=10
y=10
if [ $x -ne $y ]
then
echo "Not equal"
else
echo "They are equal"
fi
运行结果:
$ ./script.sh
They are equal
注意: 在指定要检查的条件时,请在 [ 与 ] 的前后位置键入空格,否则会出现错误。
5.7 循环
使用循环,您可以一次又一次地执行一组命令,直到满足某个条件。让我们看看其中的一些循环。
5.7.1 while 循环
如果条件为 true,它将开始运行指定的命令,并重复这些命令,直到条件为 false。
语法
while [ condition ]
do
#set of statements
done
让我们看一个示例。
#!/bin/sh
x=2
while [ $x -lt 6 ]
do
echo $x
x=`expr $x + 1`
done
运行结果:
$ ./script.sh
2
3
4
5
当将 expr 语句赋值给变量时,我们将其包含在 `` 中。
5.7.2 for 循环
在 for 循环中,变量在值列表上迭代,并在没有更多值可迭代时结束。
语法
for var in val1 val2 val3
do
#statements
done
让我们看一个示例。
#!/bin/sh
for var in 2 4 5 8
do
echo $var
done
运行结果:
$ ./script.sh
2
4
5
8
5.8 位置参数
位置参数是我们在执行脚本时传递给 shell 脚本的参数或值。它们由变量 $0、$1、$2…$9 访问。除此之外,它们还被 ${10}、${11} 等引用。$# 存储传递的参数的数目,$0 存储脚本的名称。让我们看一个例子来理解这一切。
#!/bin/sh
echo "No of arguments is $#"
echo "Name of the script is $0"
echo "First argument is $1"
echo "Second argument is $2"
要传递参数,只需在终端中的脚本名称后面键入它们,如下所示。
$ ./script.sh value1 value2
No of arguments is 2
Name of the script is ./script.sh
First argument is value1
Second argument is value2
5.9 存储命令输出
您可以将命令的输出存储在 shell 脚本的变量中。有两种方法可以做到这一点。
语法
#Syntax 1
var=$(a valid linux command)
#Syntax 2
var2=`a valid linux command`
让我们看一个示例。
#!/bin/sh
b=$(pwd)
c=`pwd`
echo $b
echo $c
d=$(ls /bin | grep bash)
echo $d
运行结果:
$ ./script.sh
/tmp
/tmp
bash bashbug dh_bash-completion rbash
5.10 shell 命令的退出代码
每当命令结束并将控制权返回给父进程时,它都会返回 0 到 255 之间的退出代码。退出代码 0 表示命令成功,任何其他退出代码表示命令不成功。您可以在运行任何命令后访问 $? 变量,请参阅下面的示例。
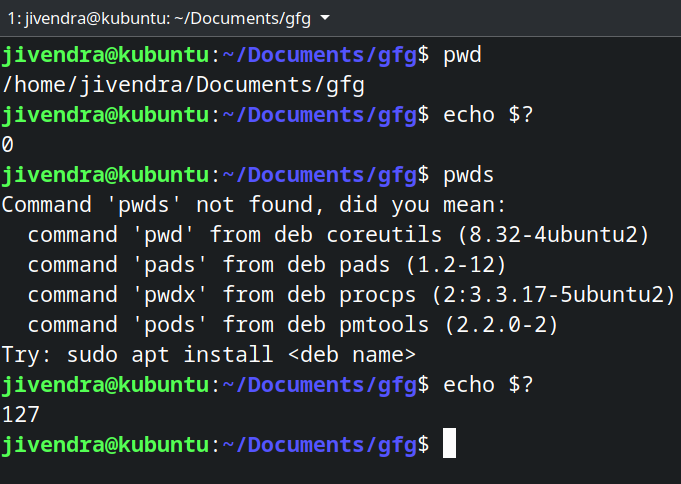
您可以手动设置 shell 脚本的退出代码。这可以与条件语句一起使用,以传达脚本的目的是否实现。
示例:
#!/bin/sh
read x
if [ $x -ne 10 ]
then
echo failed
exit 1
else
echo passed
exit 0
fi
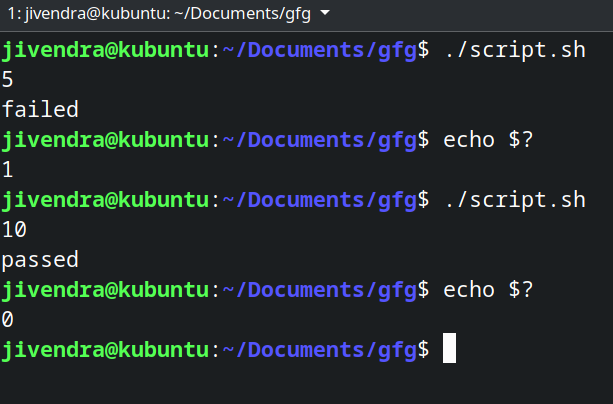
6 Linux 中的不同 Shell
SHELL 是一个在用户和操作系统之间提供接口的程序。当用户登录时,操作系统会为用户启动一个 shell。内核控制所有重要的计算机操作,提供对硬件访问的限制,协调所有执行的实用程序,并管理进程之间的资源。只有使用内核的用户才能访问操作系统提供的实用程序。
Shell 类型:
-
The C Shell
表示为 csh
-
Bill Joy 在加州大学伯克利分校创建了它,它包含了别名和命令历史记录等功能,它包括一些有用的编程功能,如内置算术和类 C 表达式语法。在 C Shell 中:
Command full-path name is /bin/csh, Non-root user default prompt is hostname %, Root user default prompt is hostname #. -
The Bourne Shell
表示为 sh
-
它是由 Steve Bourne 在 AT&T 贝尔实验室写的。它是最初的 UNIX shell。它更快,更受欢迎。它缺乏交互式使用的功能,比如调用以前的命令的能力。它还缺乏内置的算术和逻辑表达式处理。它是 Solaris 操作系统的默认 shell。对于 Bourne shell:
Command full-path name is /bin/sh and /sbin/sh, Non-root user default prompt is $, Root user default prompt is #. -
The Korn Shell
表示为 ksh
-
这是由 AT&T 贝尔实验室的 David Korn 撰写的。它是 Bourne shell 的超集。因此,它支持 Bourne shell 中的所有内容。它具有交互功能。它包括诸如内置算术和类 C 数组、函数和字符串操作设施之类的功能。它比C shell 更快。它与为 C shell 编写的脚本兼容。对于 Korn shell:
Command full-path name is /bin/ksh, Non-root user default prompt is $, Root user default prompt is #. -
GNU Bourne-Again Shell
表示为 bash
-
它与 Bourne shell 兼容。它包含了 Korn 和 Bourne shell 的功能。对于 GNU Bourne-Again shell:
Command full-path name is /bin/bash, Default prompt for a non-root user is bash-g.gg$ (g.ggindicates the shell version number like bash-3.50$), Root user default prompt is bash-g.gg#. -
T Shell
表示为 tsh
-
它最初是为 Plan 9 操作系统开发的,但后来被移植到其他系统,包括 Linux、FreeBSD 和 macOS。
Command full-path name is /bin/tcsh, Default prompt for a non-root user is abhishekaslk(user):~> Root user default prompt is root@abhishekaslk(user):~#. -
Z Shell
表示为 zsh
-
Z Shell(zsh)由 Paul Falstad 于 1990 年创建,当时他还是普林斯顿大学的学生。Z Shell 是 Bourne-Again Shell(bash)的扩展版本,具有其他特性和功能。
Command full-path name is /bin/zsh, Default prompt for a non-root user is abhishekaslk(user)% Root user default prompt is root@abhishekaslk(user):~#
7 Linux 中的基本 Shell 命令
shell 是一种特殊的用户程序,为用户提供使用操作系统服务的接口。Shell 接受用户发出的可读命令,并将其转换为内核能够理解的内容。它是一个命令语言解释器,用于执行从键盘等输入设备或文件中读取的命令。当用户登录或启动终端时,shell 就会启动。
1. 在终端上显示文件内容:
cat: 它通常用于连接(concatenate)文件,在标准输出设备上进行输出。more: 它是一个过滤器,用于一次一屏地对文本进行分布。
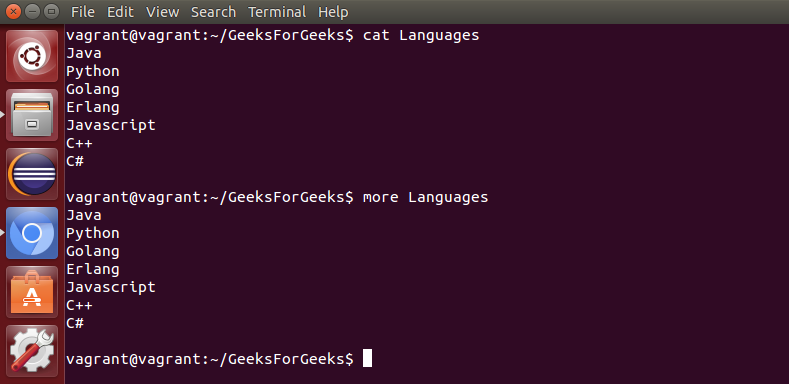
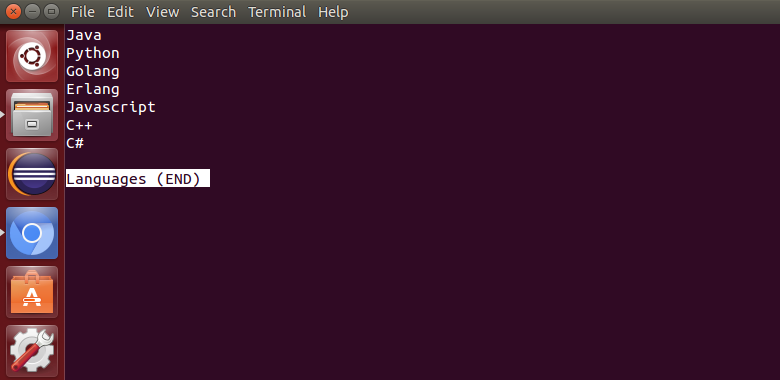
less: 它用于查看文件,而不是打开文件。类似于更多的命令,但它允许向后和向前移动。
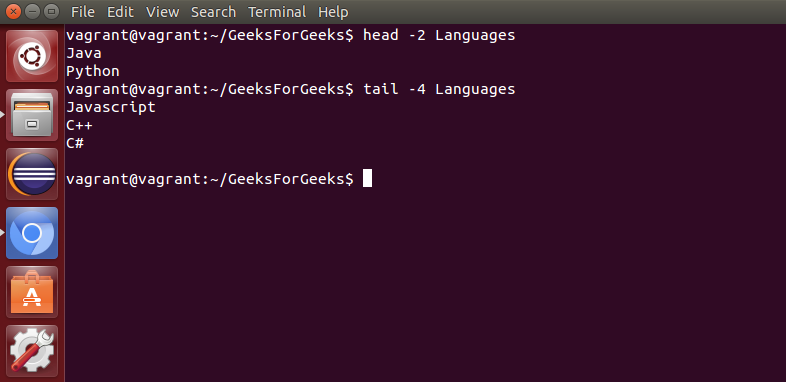
head: 用于打印文件的前 N 行。它接受 N 作为输入,N 的默认值为 10。tail: 用于打印文件的最后 N-1 行。它接受 N 作为输入,N 的默认值为 10。
2. 文件和目录操作命令:
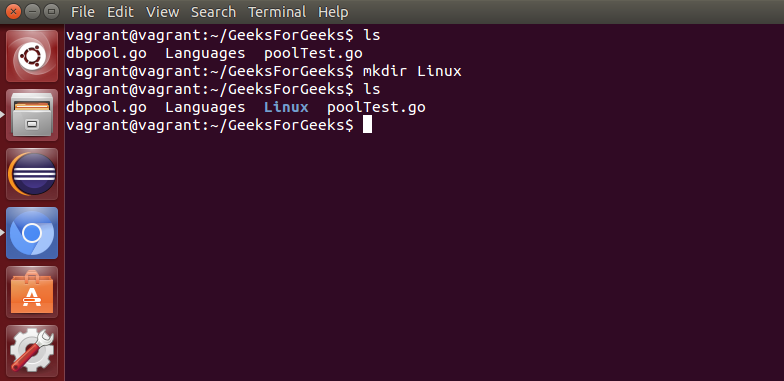
mkdir: 用于创建目录(如果不存在),它接受目录名称作为输入参数。
cp: 此命令将文件和目录从源路径复制到目标路径。它可以将具有新名称的文件/目录复制到目标路径。它接受源文件/目录和目标文件/目录。
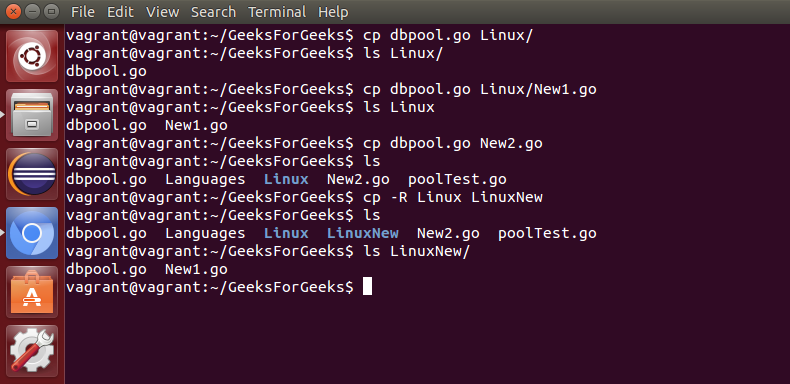
mv: 用于移动文件或目录。该命令的工作方式几乎类似于 cp 命令,但它会从源路径中删除文件或目录的副本。
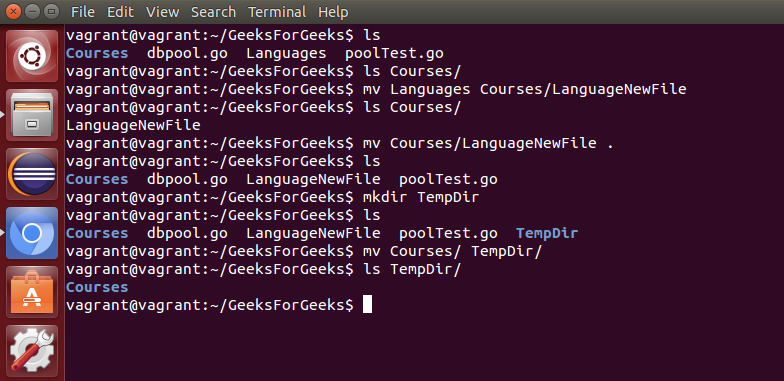
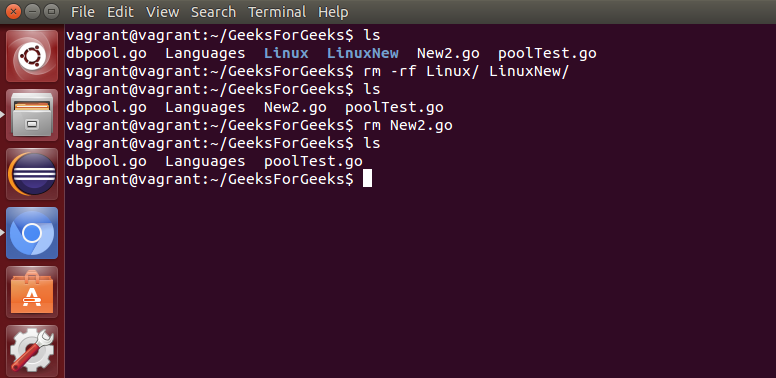
rm: 用于删除文件或目录。
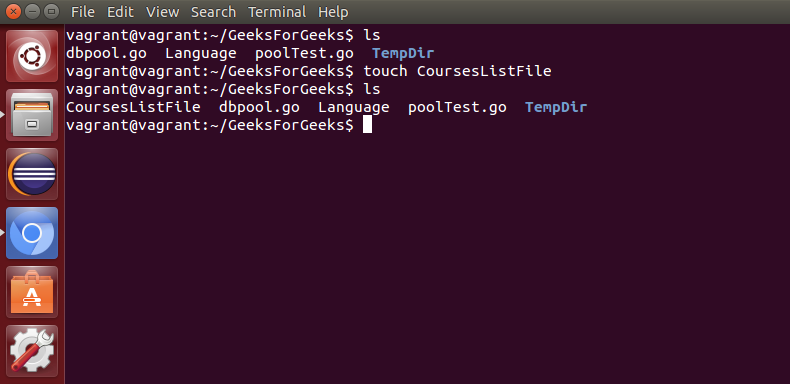
touch: 用于创建或更新文件。
3. 提取、排序和筛选数据命令:
grep: 此命令用于在文件中搜索指定的文本。
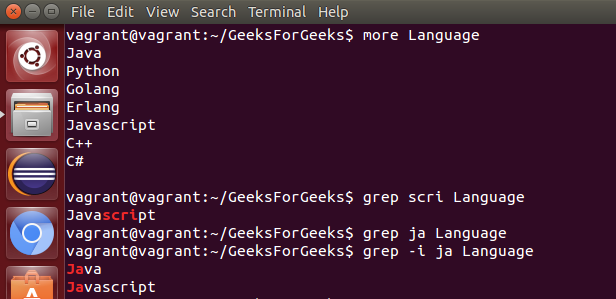
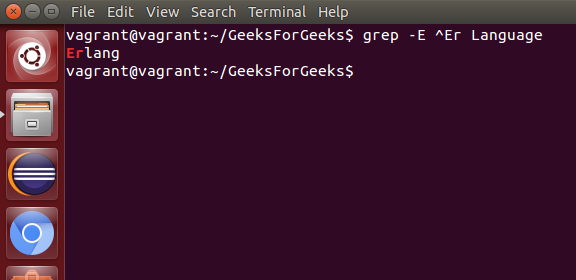
- grep with Regular Expressions: 用于在文件中使用特定正则表达式搜索文本。
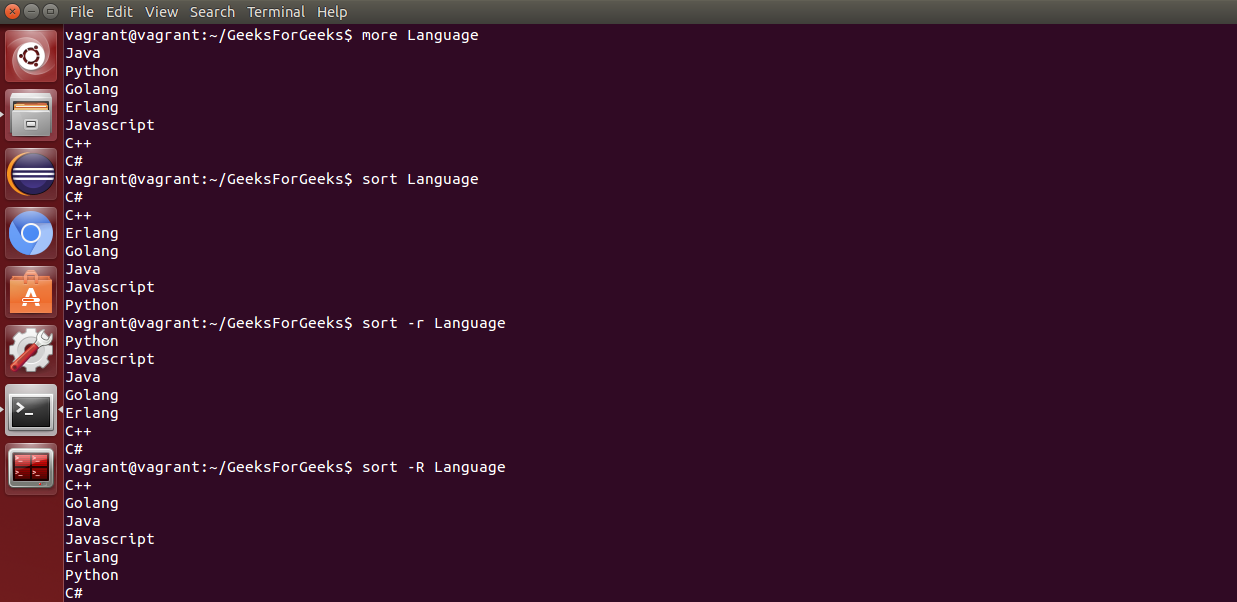
sort: 此命令用于对文件的内容进行排序。
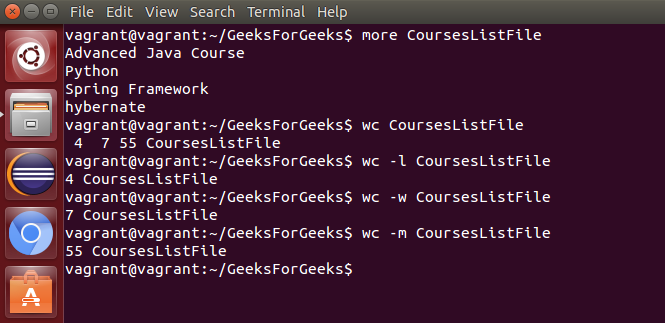
wc: 用于计算文件中的字符数、字数。
cut: 用于剪切文件的指定部分。
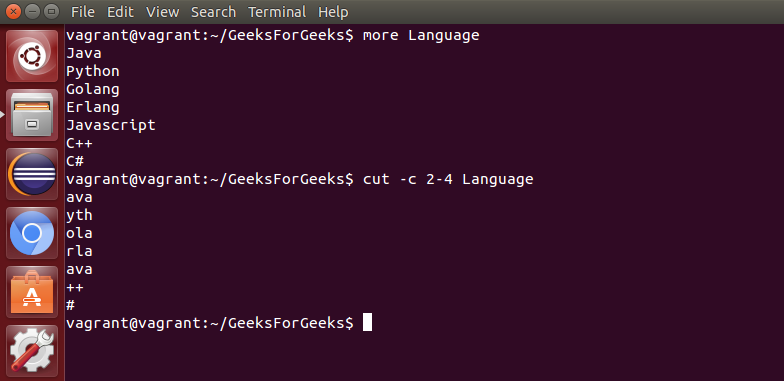
4. 基本终端导航命令:
ls: 获取所有文件或文件夹的列表。ls -l: 可选标志被添加到 ls 中以修改默认行为,以扩展形式列出内容 -l 用于「长」输出。ls -a: 所有文件的列表,包括隐藏的文件,添加 -a 标志cd: 用于切换目录。du: 显示磁盘使用状态。pwd: 显示当前工作目录。man: 用于显示 Linux 中存在的任何命令的手册。rmdir: 它用于在目录为空时删除该目录。ln file1 file2: 创建物理链接。ln -s file1 file2: 创建符号链接。locate: 它用于在 Linux 系统中定位文件。echo: 这个命令可以帮助我们将一些数据(通常是文本)移动到文件中。df: 它用于查看系统中每个分区中的可用磁盘空间。tar: 用于处理 tarball(或压缩在 tarball 档案中的文件)
5. 文件权限命令: chmod 和 chown 命令用于控制对 UNIX 和 Linux 系统中文件的访问。
chown: 用于更改文件的所有者。chgrp: 用于更改文件的组所有者。chmod: 用于修改用户的访问权限。
8 Linux 目录结构
在 Linux/Unix 操作系统中,所有东西都是一个文件,甚至目录是文件,文件是文件,鼠标、键盘、打印机等设备也是文件。在这里,我们将看到 Linux 中的目录结构。
8.1 Linux 系统中的文件类型
1. 常规文件 —— 也称为普通文件。它可以是图像、视频、程序或简单的文本文件。这些类型的文件可以是 ASCII 或二进制格式。它是 Linux 系统中最常用的文件。
2. 目录文件 —— 这些类型的文件是其他文件类型的仓库。它可能是一个目录(子目录)中的一个目录文件。
3. 设备文件 —— 在类似 Windows 的操作系统中,CD-ROM 和硬盘驱动器等设备表示为驱动器号,如 F:G:H,而在 Linux 系统中,设备表示为文件。例如,/dev/sda1、/dev/sda2 等等。
我们知道,在类似 Windows 的操作系统中,文件存储在不同数据驱动器(如 C:D:E)上的不同文件夹中,而在 Linux/Unix 操作系统中文件以树状结构存储,从根目录开始,如下图所示。
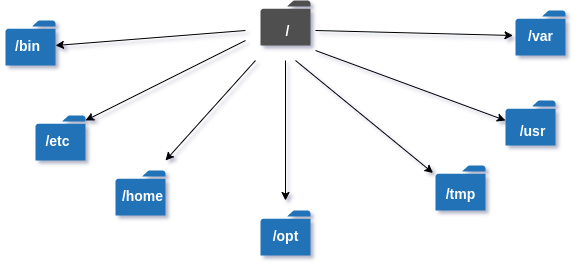
Linux/Unix 文件系统层次结构基础从根目录开始,所有内容都从根目录启动。
以下是与根目录关联的常见顶级目录:
| Directories | Description |
|---|---|
| /bin | 二进制或可执行程序 |
| /etc | 系统配置文件 |
| /home | 用户的主目录,它是默认的当前目录 |
| /opt | 可选的或第三方软件 |
| /tmp | 临时空间,通常在重新启动时清除 |
| /usr | 与用户相关的程序 |
| /var | 日志文件 |
Linux 系统中的其他一些目录:
| Directories | Description |
|---|---|
| /boot | 它包含所有与引导相关的信息文件和文件夹,如 conf、grub 等 |
| /dev | 它是设备文件的位置,例如 /dev/sda1、/dev/sda2 等 |
| /lib | 它包含内核模块和一个共享库 |
| /lost+found | 它用于查找损坏文件的恢复位 |
| /media | 它包含插入可删除媒体设备的子目录 |
| /mnt | 它包含用于装载文件系统的临时装载目录 |
| /proc | 它是一个虚拟和伪文件系统,包含有关具有特定进程 ID 或 PID 的运行进程的信息 |
| /run | 它存储易失性运行时数据 |
| /sbin | 管理员的二进制可执行程序 |
| /srv | 它包含特定于服务器的文件和与服务器相关的文件 |
| /sys | 它是一个用于现代 Linux 发行版的虚拟文件系统,用于存储并允许修改连接到系统的设备 |
探索目录及其可用性:
我们知道 Linux 是一个非常复杂的系统,与 Windows 操作系统不同,它需要一种有效的方式来启动、停止、维护和重新启动系统。在 Linux 系统中,每个进程都可以使用一些定义良好的配置文件、二进制文件、主页信息文件。
Linux 内核文件:
- /boot/vmlinuz —— Linux 内核文件。
设备文件:
- /dev/hda —— 第一个 IDE HDD 的设备文件。
- /dev/null —— 输出垃圾输出的伪设备被重定向到 /dev/null。
系统配置文件:
| Configuration Files | Description |
|---|---|
| /etc/bashrc | 它包含系统默认值和别名,由 bash shell 使用 |
| /etc/crontab | 一个 shell 脚本,用于在预定义的时间间隔内运行指定的命令 |
| /etc/exports | 它包含有关网络上可用的文件系统的信息 |
| /etc/fstab | 磁盘驱动器及其装载点的信息 |
| /etc/group | 它是一个定义安全组信息的文本文件 |
| /etc/grub.conf | 它是 grub 引导加载程序的配置文件 |
| /etc/init.d | 服务启动脚本 |
| /etc/lilo.conf | 它包含 lilo 引导加载程序配置文件 |
| /etc/hosts | IP 及相应主机名信息 |
| /etc/hosts.allow | 它包含允许访问本地计算机上的服务的主机列表 |
| /etc/host.deny | 拒绝访问本地计算机上服务的主机列表 |
| /etc/inittab | INIT 过程及其在不同运行级别上的交互 |
| /etc/issue | 允许编辑预登录消息 |
| /etc/modules.conf | 它包含系统模块的配置文件 |
| /etc/motd | 它包含日期的信息 |
| /etc/mtab | 当前挂载的块信息 |
| /etc/passwd | 它包含一个影子文件中的用户名、系统密码和用户 |
| /etc/printcap | 它包含打印机信息 |
| /etc/profile | Bash shell 默认值 |
| /etc/profile.d | 它包含其他脚本,如登录后执行的应用程序脚本 |
| /etc/rc.d | 它避免了脚本重复 |
| /etc/rc.d/init.d | 运行级别初始化脚本 |
| /etc/resolv.conf | 系统正在使用的 DNS |
| /etc/security | 它包含可以进行 root 登录的终端的名称 |
| /etc/skel | 初始化新用户主目录的脚本 |
| /etc/termcap | 一种 ASCII 文件,用于定义不同类型终端的行为 |
| /etc/X11 | 目录树包含 X-window 系统的所有 conf 文件 |
与用户相关的文件:
| User Related Files | Descriptions |
|---|---|
| /usr/bin | 它包含大多数可执行文件 |
| /usr/bin/X11 | /usr/bin 的符号链接 |
| /usr/include | 它包含 C 程序使用的标准文件 |
| /usr/share | 它包含独立于体系结构的可共享文本文件 |
| /usr/lib | 它包含对象文件和库 |
| /usr/sbin | 它包含用于超级用户和系统管理的命令 |
虚拟和伪进程相关文件:
| Files | Descriptions |
|---|---|
| /usr/bin | 它包含大多数可执行文件 |
| Virtual and Pseudo Process Related Files | Descriptions |
|---|---|
| /proc/cpuinfo | CPU 信息 |
| /proc/filesystems | 它保存有关当前正在运行的进程的有用信息 |
| /proc/interrupts | 它保持关于每个IRQ的中断数量的信息 |
| /proc/ioports | 包含服务器上设备使用的所有输入和输出地址 |
| /proc/meminfo | 它报告内存使用情况信息 |
| /proc/modules | 当前正在使用的内核模块 |
| /proc/mount | 挂载的文件系统信息 |
| /proc/stat | 它显示当前系统的详细统计信息 |
| /proc/swaps | 它包含交换文件信息 |
日志文件:
| Log Files | Descriptions |
|---|---|
| /var/log/lastlog | 它存储用户的最后登录信息 |
| /var/log/syslog | 它包含所有全局系统消息 |
| /var/log/wtmp | 它保存登录和注销信息的历史记录 |
要检查 Linux 目录,请打开终端并执行 sudo -s,然后执行系统密码以授予 root 权限。然后在将当前主目录更改为根目录后,检查基本目录中所有可用目录的列表,如下所示。
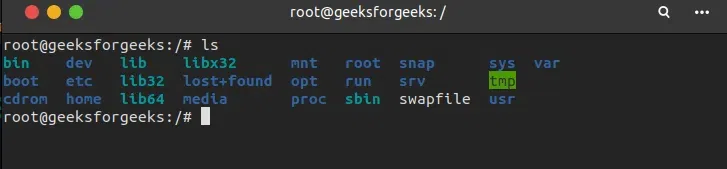
8.2 结论
如果我们正确理解 Linux 目录的结构,那么就可以很容易地有效地导航和管理我们的文件系统、定位重要的配置文件和访问系统信息。必须知道,本文中提到的目录结构和特定文件是基于标准 Linux 约定的。我们必须考虑到,不同的 Linux 发行版可能在目录结构和特定的文件位置上有所不同,但总体概念和组织结构仍然相似。
9 Linux 中的输入输出重定向
在 Linux 中,每当一个人运行一个命令时,它可以接受输入、给出输出,或者两者兼而有之。重定向帮助我们将这些输入和输出功能重定向到我们想要的文件或文件夹,我们可以使用特殊的命令或字符来做到这一点。
例如,如果我们运行 date 命令,它会在屏幕上为我们提供输出。但是,如果我们想将结果保存在文件中,我们可以使用输出重定向。通过这种方式,我们可以将 date 命令的输出存储在一个文件中,并在以后引用它。当我们处理多个大型输出或输入时,这些重定向会派上用场,因为我们可以直接使用文件数据作为输入并将结果存储在文件中。
所有这些都可以在终端上使用一些简单的命令轻松完成。在本文中,我们将讨论 Linux 中不同类型的重定向,以及如何在 Linux 中使用重定向。
9.1 重定向类型
1. 覆盖重定向:
当您希望将命令的输出存储/保存到文件并替换该文件的所有现有内容时,覆盖重定向非常有用。例如,如果运行一个提供报告的命令,并且希望将报告保存到上一个报告的现有文件中,则可以使用覆盖重定向来执行此操作。
>标准输出<标准输入
实施:
因此,无论你在运行这个命令后要写什么,都会被重定向并复制到 file.txt。这是标准的输出重定向。
cat > file.txt
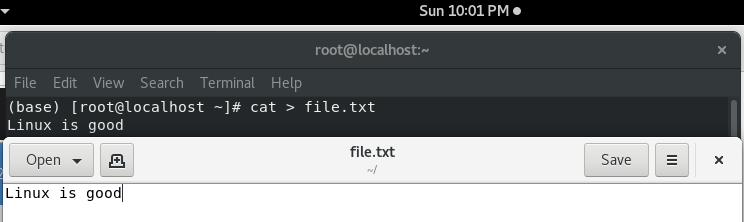
现在,这是标准的输入重定向,cat 命令将从 file.txt 中获取输入并将其打印到终端屏幕上。这行代码还显示了复制粘贴 cat 命令的实际工作和意义。很多人都有一种误解,认为 cat 是用来创建文件的,但事实并非如此,cat 的主要工作是复制输入并将输出提供给屏幕。
cat < file.txt
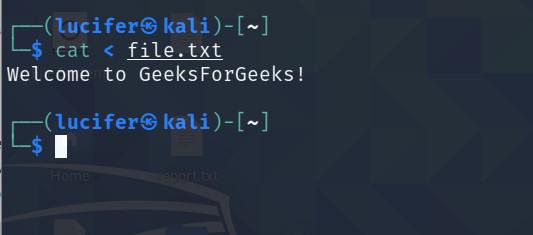
让我们看一个例子来理解cat命令的真实工作
cat
只需在终端上键入 cat,然后点击回车键。它会要求输入行,你可以写下你的名字,然后点击回车键。您将看到您的输入将被重新打印。
(base) [root@localhost ~]# cat
Hello this is GeeksForGeeks
Hello this is GeeksForGeeks
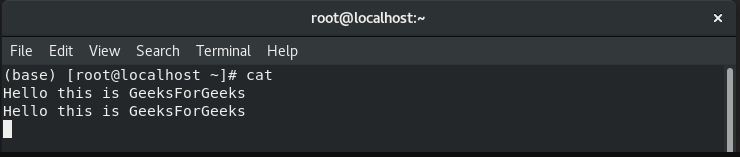
当我们想要将一些行附加到文件的现有内容时,就会使用此选项。如果只使用一个角括号,则文件的所有内容都将丢失。
cat >> file.txt
2. 附加重定向:
借助此重定向,您可以在不影响文件现有数据的情况下将输出附加到文件中。
>>标准输出<<标准输入
实施:
here 文档用于将输入重定向到交互式 shell 脚本或程序中。通过为交互式程序或交互式 shell 脚本提供所需的输入,您可以在 shell 脚本中运行任何程序,而无需用户操作。
此处文档的一般格式为:
Syntax:
command << delimiter
document
delimiter
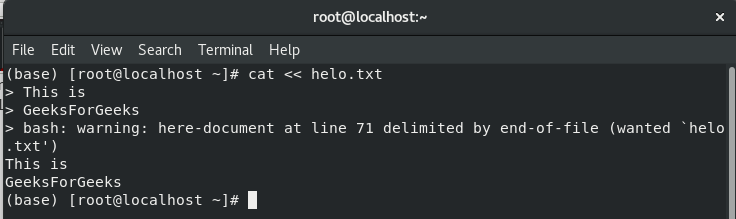
(base) [root@localhost ~]# cat << helo.txt
> Hello This is
> GeeksForGeeks
helo.txt
Hello This is
GeeksForGeeks
(base) [root@localhost ~]#
Note: Here, helo.txt is a delimiter.
分隔符标记文档的结束点。如果没有它,shell 将永远继续读取输入。分隔符必须是不包含空格或制表符的单个单词。
3. 合并重定向
这允许您将命令或程序的输出重定向到特定的文件描述符,而不是标准输出。使用合并重定向的语法是 >& 运算符后跟文件描述符编号。
p >& q将 stream p 的输出与 stream q 合并p <& q将 stream p 的输入与 stream q 合并
实施:
错误重定向:错误重定向将某些命令生成的错误传输到文件,而不是 STDOUT。
在终端执行程序时,将生成 3 个文件:标准输入(0)、标准输出(1)、标准错误(2)。这些文件始终在程序运行时创建。默认情况下,屏幕上显示错误流。
示例:
- 在下面提到的示例中,上面使用的文件描述符是 2 (STDERR)。使用
2>将错误输出重新直接发送到名为error.txt的文件,STDOUT 上没有显示任何内容。
$ somerandomcommand 2>error.txt

- 这里,
2>&1表示 STDERR 重定向到 STDOUT 的目标。更正式地说,「2」 生成的错误消息与当前输出 「1」 合并。
$ ls GEEK GFG > error.txt 2>&1
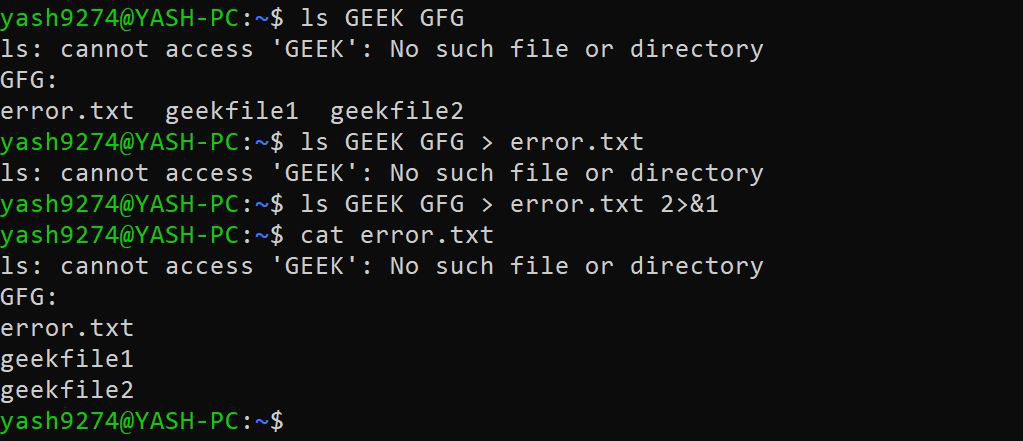
在上面的示例中,目录 GEEK 不存在。错误输出与标准输出合并,标准输出又被重定向到 error.txt。
10 Shell 脚本——Shell 变量
shell 变量是 shell 中存储某些值的字符串。它可以是一个整数、文件名、字符串或某个 shell 命令本身。基本上,它是存储在内存中的实际数据的指针。在脚本中编写变量时,我们必须遵守一些规则(这将在本文中讨论)。全面了解 shell 变量脚本使我们能够编写强大而优秀的 shell 脚本。
10.1 变量定义规则
变量名可以包含任何字母表(a-z,A-Z)、任何数字(0-9)和下划线(_)。但是,变量名必须以字母表或下划线开头。它永远不可能以数字开头。以下是一些有效和无效变量名的示例:
- 有效的变量名
ABC
_AV_3
AV232
- 无效的变量名
2_AN
!ABD
$ABC
&QAID
注意:必须注意的是,变量名中不能使用除下划线以外的任何其他特殊字符,因为所有其他特殊字符在 Shell 脚本中都具有特殊含义。
10.2 定义变量
语法
variable_name=<variable data>
示例
num="1"
name="Devil"
这类变量是标量变量,因为它们一次可以保持一个值。
1) 访问变量
变量数据可以通过在变量名附加 $ 来访问,如下所示:
#!/bin/bash
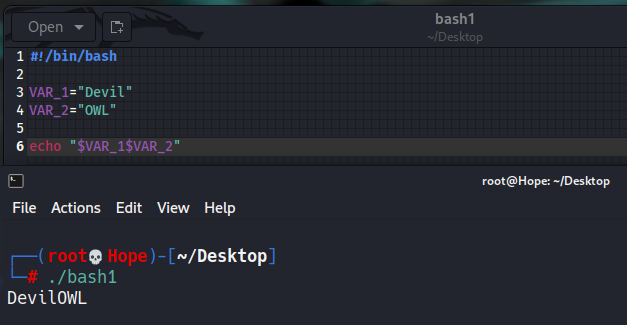
VAR_1="Devil"
VAR_2="OWL"
echo "$VAR_1$VAR_2"
输出:
DevilOWL
2) 取消设置变量
unset 命令指示 shell 从变量列表中删除变量及其存储的数据。其用途如下:
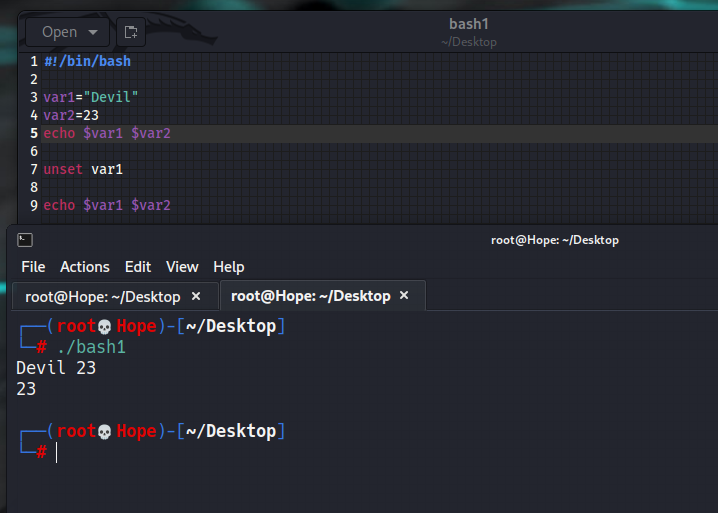
#!/bin/bash
var1="Devil"
var2=23
echo $var1 $var2
unset var1
echo $var1 $var2
输出:
DEVIL 23
23
注意:unset 命令不能用于取消只读变量的设置。
3) 只读变量
这些变量是只读的,也就是说,它们的值以后不能在脚本中修改。以下是一个示例:
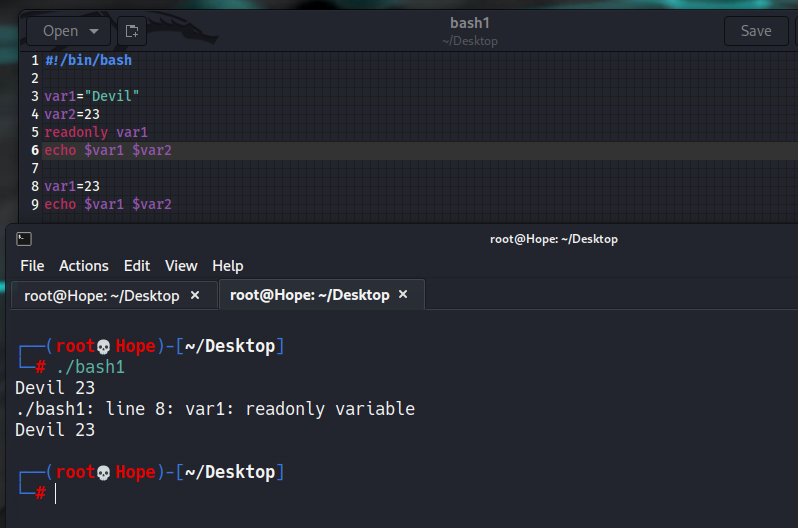
#!/bin/bash
var1="Devil"
var2=23
readonly var1
echo $var1 $var2
var1=23
echo $var1 $var2
输出:
Devil 23
./bash1: line 8: var1: readonly variable
Devil 23
现在让我们一起来看一下上面所有的代码。下面是一个 shell 脚本,其中包括上面讨论的所有 shell 变量。
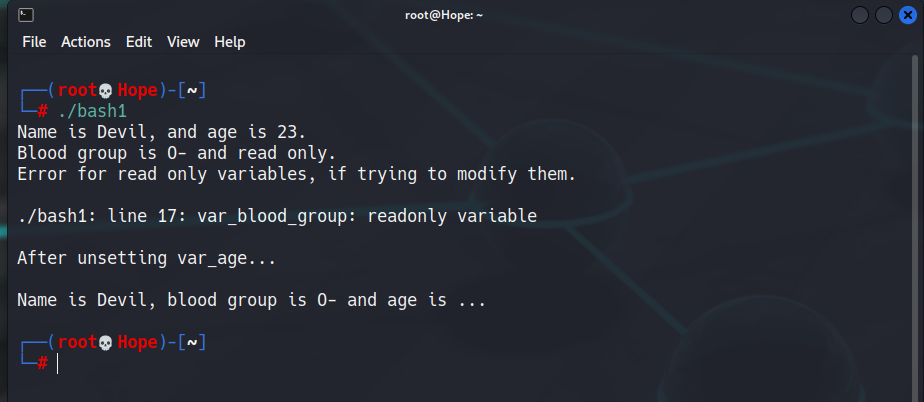
#!/bin/bash
#variable definitions
Var_name="Devil"
Var_age=23
# accessing the declared variables using $
echo "Name is $Var_name, and age is $Var_age."
# read-only variables
var_blood_group="O-"
readonly var_blood_group
echo "Blood group is $var_blood_group and read only."
echo "Error for read only variables, if trying to \
modify them."
echo
var_blood_group="B+"
echo
# unsetting variables
unset Var_age
echo "After unsetting var_age..."
echo
echo "Name is $Var_name, blood group is $var_blood_group\
and age is $Var_age..."
输出:
10.3 变量类型
我们可以讨论三种主要类型的变量:
1)本地变量
特定于 shell 当前实例的变量。它们基本上在 shell 中使用,但不适用于从当前 shell 中启动的程序或其他 shell。
例如:
name=Jayesh
在这种情况下,局部变量(name)值为 Jayesh。局部变量是 shell 脚本中数据的临时存储。
2)环境变量:
这些变量通常用于配置 shell 运行的行为脚本和程序。环境变量只创建一次,之后任何用户都可以使用它们。
例如:
export PATH=/usr/local/bin:$PATH
将在 shell 的可执行程序搜索路径的开头添加 /usr/local/bin。
3)Shell 变量:
由 shell 本身设置的变量,有助于 shell 正确使用函数。它包含两者,这意味着它同时包含两者,有些变量是环境变量,有些是局部变量。
例如:
$PWD = 存储当前工作目录
$HOME = 存储用户的主目录
$SHELL = 存储正在使用的 shell 程序的路径。
10.4 Shell 脚本和 Shell 变量中的几个例子
10.4.1 如何在变量中存储用户数据?
#!/bin/bash
echo "Enter the length of the rectangle"
read length
echo "Enter the width of the rectangle"
read width
area=$((length * width))
echo "The are of the rectangle is: $area"
在本例中,变量 length、width 和 area 用于存储用户输入并计算矩形的面积。
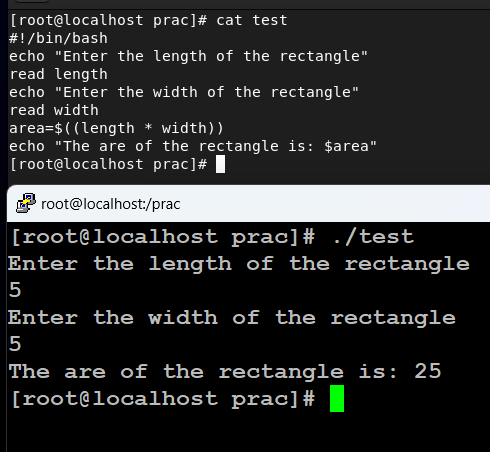
echo 是用于打印语句的命令,read 是用于从用户获取数据并将其存储在变量中的命令。
10.4.2 存储和显示消息
我们可以编写一个脚本,通过查看一天中的时间向用户显示消息。在这里,我们可以使用 shell 变量来存储和显示我们的消息。
#!/bin/bash
time=$(date +%H)
if [ $time -lt 12 ];then
message = "Good Morning User"
elif [ $time -lt 18 ];then
message = "Good Afternoon User"
else
message = "Good Evening User"
fi
echo "$message"hours
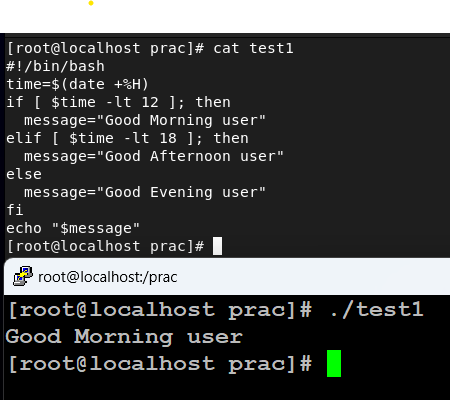
在这种情况下,time 是存储小时的变量,data 是用于获取当前时间的命令,%H 仅用于提取小时部分 -lt 是一个用于数值比较的小于运算符,fi 用于标记 if 语句的末尾。
10.5 什么是 Shell 及其类型
它是一个提供用于访问操作系统服务的用户界面的程序。或者我们可以说,它是一个我们可以运行程序和 shell 脚本等的环境,它是操作系统的核心。
有几种不同类型的 shell 可用,一些常见类型的 shell 包括:
- Bourne Shell (sh): UNIX 操作系统的原始 shell。它用于脚本编写目的,也用于提供基本命令。
- C Shell (csh): 这也是适用于 UNIX 操作系统的流行 shell。顾名思义,它的语法类似于 C 编程语言。
- Bourne-Again Shell (bash): 它是一个广泛用于 macOS 和 Linux 操作系统的 shell。它比原来的 Bourne shell 更先进,还具有 Korn shell 和 C shell 中的许多功能。
10.6 Shell 变量的用途是什么
Shell 变量用于在 shell(终端)中存储数据和信息,还用于控制程序和脚本的行为。一些常见用途包括:
- 设置环境变量。
- 存储配置数据。
- 存储临时数据。
- 将参数传递给脚本。
10.7 什么是 Shell 变量和 Shell 脚本
Shell 变量用于 shell 脚本中的许多功能,如存储数据和信息、接受用户输入、打印存储的值。它们还用于临时存储数据和存储命令的输出。
Shell 脚本是一种编写在终端或 shell 中执行的程序脚本的方法。基本上,它是一个在其中提到的变量的帮助下编写的程序或脚本。它之所以强大,是因为它可以自动化任务,并且在这个例子中,它可以使用 shell 中可用的编程结构,如循环、条件和函数。
10.8 结论
Shell 变量是 Shell 脚本的重要组成部分。Shell 变量允许我们在脚本中的任何位置使用它们。在本文中,我们讨论了定义标量变量、不设置变量、只读变量和访问变量的规则。这篇文章将为初学者提供一个有用的指南,那些想了解如何编写 shell 脚本的人必须知道如何使用 shell 变量。
11 Shell 脚本——变量名命名规则
变量在任何脚本或程序中都非常重要,因此我们需要了解命名这些变量的约定是什么。在 Shell 脚本中为变量命名时,需要记住某些规则和标准。在本文中,我们将讨论并列出在 Shell/Bash 脚本中声明变量名的所有规则和约定。
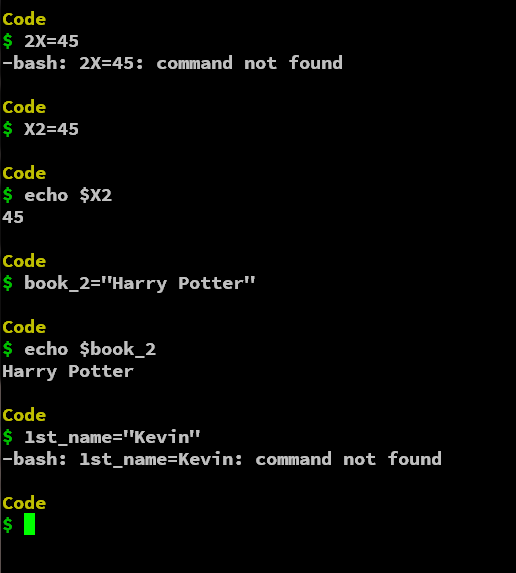
规则 1:变量名可以有字母、数字和下划线
变量名称可以是字母数字,即字母和数字以及下划线。您可以在名称中使用小写字母或大写字母。我们可以在变量名的任何位置使用下划线字符。
例如:
变量 var_name 有一个下划线,并且有小写字符。变量 X2 具有大写字符和数字。最后,最后一个变量有大写和小写字符、数字和下划线。
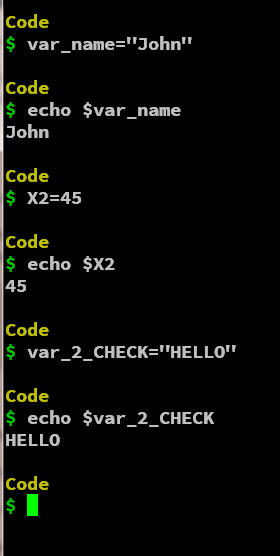
注意: 不要将 _ 用作变量名,因为当您尝试使用 $_ 访问变量 _ 时,它会产生错误,因为它是用于访问最后一个命令的大参数的保留命令。
规则 2:赋值运算符(=)的两边都不应该有空格
变量名后面的赋值运算符两边都不应该有空格。如果赋值运算符前后有空格,shell 解释器可能会给出有关变量名本身就是命令的错误消息。
例如:
在以下情况下,变量赋值被视为非法:
name = "John"
name= "John"
name ="John"
在 shell 脚本中分配变量的正确方法是在赋值运算符(=)的两侧都没有任何空格,如下所示:
name="John"
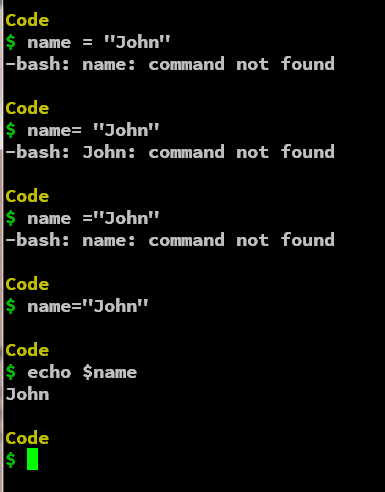
规则 3:变量名不能有特殊字符
除了第一条规则中讨论的下划线之外,变量名不能有任何特殊字符。由于 shell 脚本在一些操作任务中使用某些特殊字符,如 $ 用于访问变量文字值,& 作为 and 运算符 * 和 # 作为数组/字符串提取器等等。因此,在 shell 脚本中,不可能在变量名称中使用任何特殊字符。
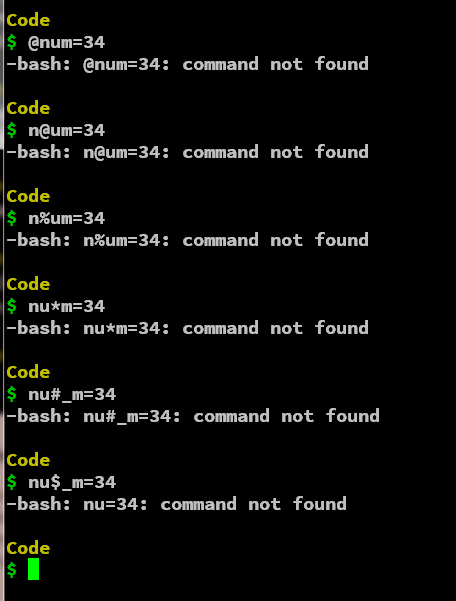
规则 4:变量名的第一个字符不能是数字
虽然我们可以在变量名中使用数字,但当数字是变量名中的第一个字符时,唯一的例外会出现。因此,除了变量名的第一个字符之外,任何位置都对数字有效。
以下是非法变量名,因为它们的第一个字符是数字。
2X
1st_name
6_gate
规则 5:变量名称不能是保留字
使用保留关键字(如 if、else、while、for、until、case 等)作为变量名不是一个好的做法。尽管它没有给出任何错误,但这仍然是一种糟糕的做法,很容易扰乱 shell 脚本的可读性,并在某些情况下导致某些错误。
shell/bash 脚本中的保留字如下:
if
elif
else
then
while
do
done
for
until
case
esac
continue
break
function
尽量避免将其用作变量名。
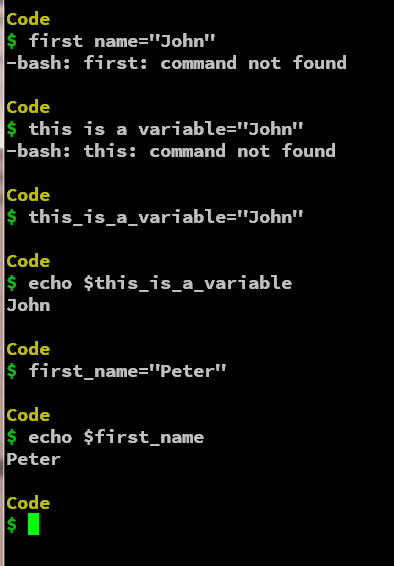
规则 6:变量名之间不能有空格
变量名之间不能有空格
first name="John"
这将生成一个错误,因为 shell 解释器将首先将单词视为命令并返回一个错误。因此,我们需要避免在变量名之间使用空格,我们可以使用 _ 来创建多词变量名,以提高可读性。
因此,在 shell 脚本环境中声明变量名时,需要记住以下规则。
12 Shell 脚本中的字符串操作
字符串操作被定义为对字符串执行多个操作,从而改变其内容。在 Shell 脚本中,这可以通过两种方式实现:纯 bash 字符串操作和通过外部命令进行的字符串操作。
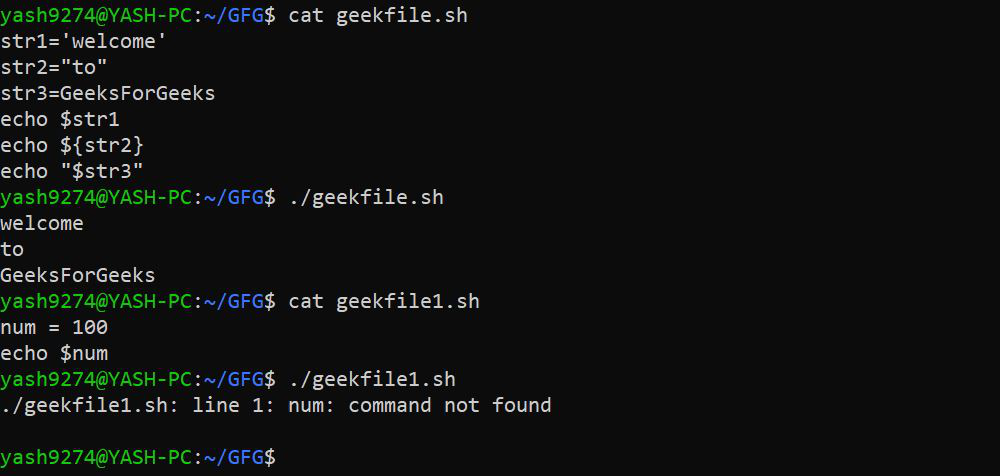
12.1 纯 bash 字符串操作的基础知识:
1. 将内容分配给变量并打印其内容: 在 bash 中,后面跟着变量名的 $ 用于打印变量的内容。Shell 在内部扩展变量及其值,shell 的这一特性也称为参数扩展。Shell 不关心变量的类型,可以存储字符串、整数或实数。
语法:
VariableName='value'
echo $VariableName
or
VariableName="value"
echo ${VariableName}
or
VariableName=value
echo "$VariableName"
注意: 变量赋值中的 = 号周围不应有任何空格。当您使用 VariableName=value 时,shell 将 = 视为赋值运算符,并将值赋值给变量。当您使用 VariableName = value 时,shell 会假定 VariableName 是一个命令的名称,并尝试执行它。
示例:
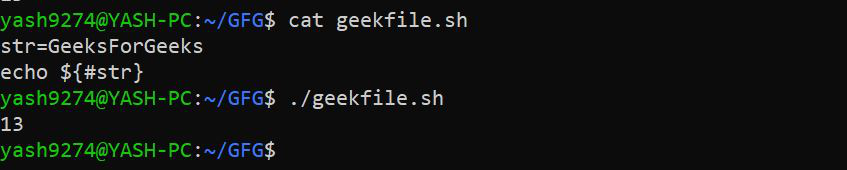
2. 打印 Bash Shell 中字符串的长度: # 符号用于打印字符串的长度。
语法:
variableName=value
echo ${#variablename}
示例:
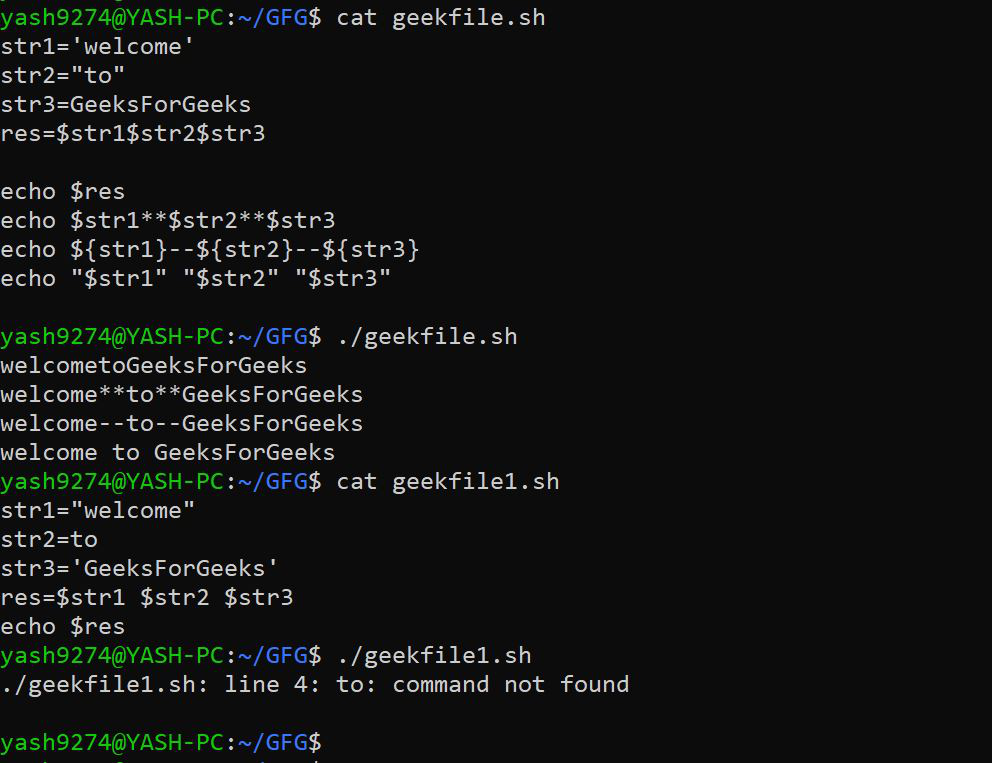
3. 使用变量在 Bash Shell 中连接字符串: 在 bash 中,将字符串列在一起会连接字符串。由此形成的字符串是一个包含所有列出的字符串的新字符串。
语法:
var=${var1}${var2}${var3}
or
var=$var1$var2$var3
or
var="$var1""$var2""$var3"
要在字符串之间连接任何字符,请执行以下操作:
The following will insert "**" between the strings
var=${var1}**${var2}**${var3}
or
var=$var1**$var2**$var3
or
var="$var1"**"$var2"**"$var3"
The following concatenate the strings using space:
var=${var1} ${var2} ${var3}
or
var="$var1" "$var2" "$var3"
or
echo ${var1} ${var2} ${var3}
注意: 当通过空格连接字符串时,请避免使用 var=$var1 $var2 $var3。在这里,shell 假定 $var2 和 $var3 为命令,并尝试执行它们,从而导致错误。
示例:
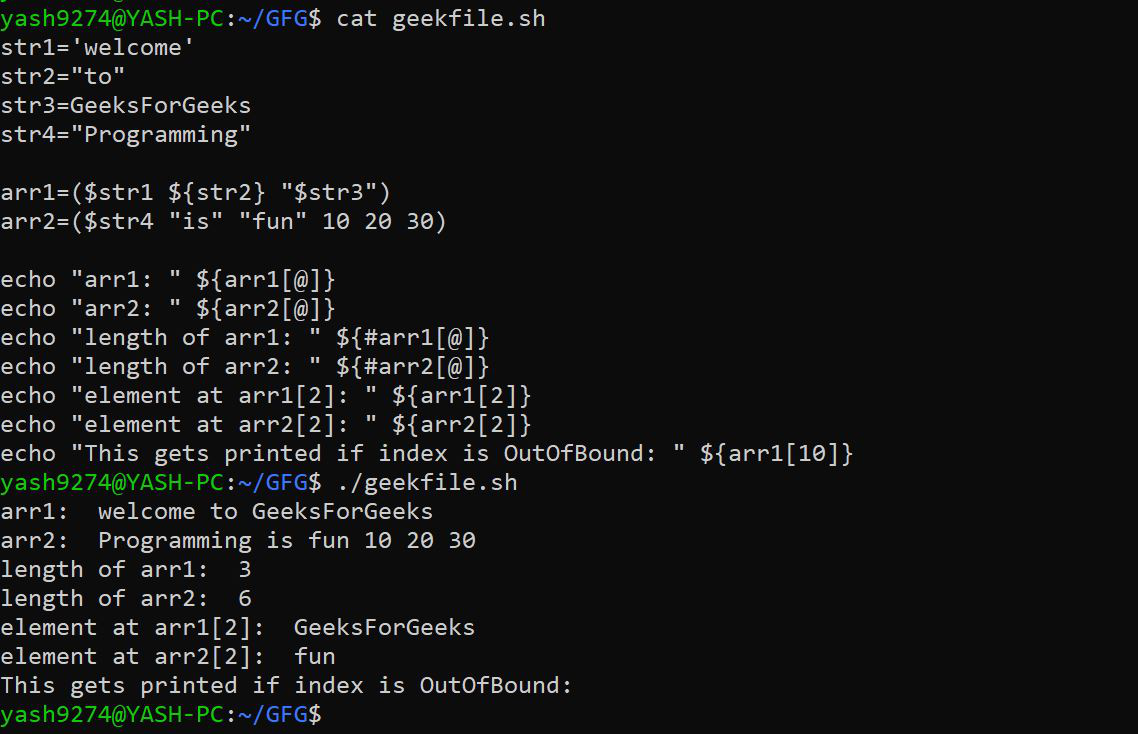
4. 使用数组在 Bash Shell 中连接字符串: 在Bash中,数组也可以用于连接字符串。
语法:
To create an array:
arr=("value1" value2 $value3)
To print an array:
echo ${arr[@]}
To print length of an array:
echo ${#arr[@]}
Using indices (index starts from 0):
echo ${arr[index]}
Note: echo ${arr} is the same as echo ${arr[0]}
示例:
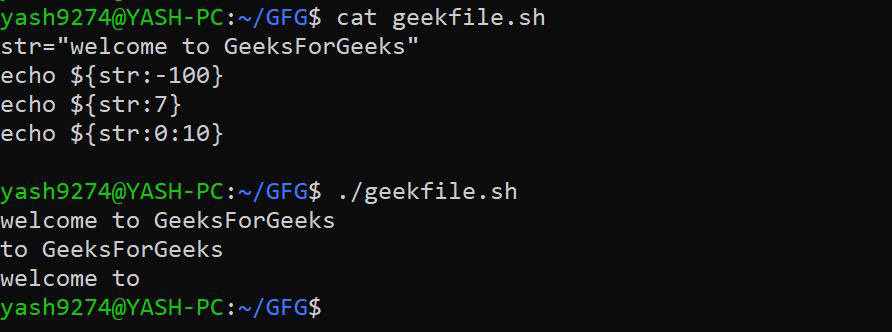
5. 从字符串中提取子字符串: 在 Bash 中,可以从字符串中抽取字符的子字符串。
语法:
${string:position} --> returns a substring starting from $position till end
${string:position:length} --> returns a substring of $length characters starting from $position.
注意: $length 和 $position 必须始终大于或等于零。
如果 $position 小于 0,它将打印完整的字符串。
如果 $length 小于 0,它将引发一个错误,并且不会执行。
示例:
6. 子字符串匹配: 在 Bash 中,可以找到子字符串的最短和最长匹配,并从前面或后面删除。
语法:
To delete the shortest substring match from front of $string:
${string#substring}
To delete the shortest substring match from back of $string:
${string%substring}
To delete the longest substring match from front of $string:
${string##substring}
To delete the shortest substring match from back of $string of $string:
${string%%substring}
示例:
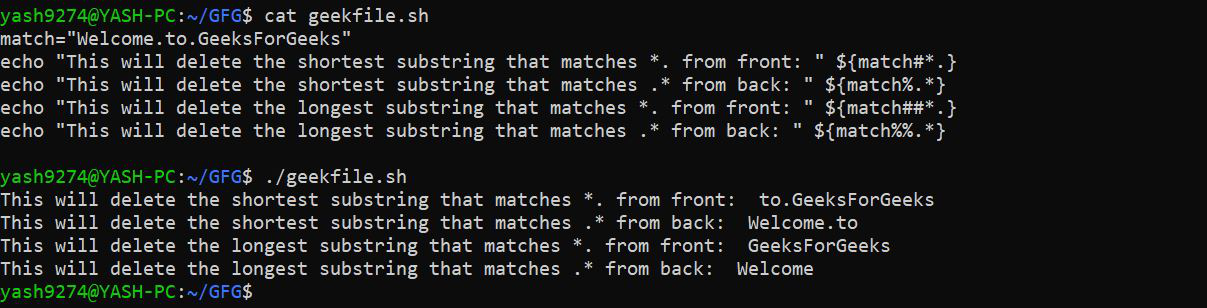
在上面的例子中:
- 第一个 echo 语句子字符串
*.匹配以句点结尾的字符,#从字符串前面删除子字符串的最短匹配项,因此它会去掉子字符串Welcome. - 第二个 echo 语句子字符串
.*匹配以句点开头、以字符结尾的子字符串,%从字符串后面删除该子字符串的最短匹配项,因此它剥离了子字符串.GeeksForGeeks - 第三个 echo 语句子字符串
*.匹配以句点结尾的字符,##从字符串前面删除子字符串的最长匹配项,因此它会删除子字符串Welcome.to. - 第四个 echo 语句子字符串
.*匹配以句点开头、以字符结尾的子字符串,%%从字符串后面删除该子字符串的最长匹配项,因此它会剥离子字符串.to.GeeksForGeeks
13 Shell 脚本中的数组基础知识
如果我们想存储 1000 个数字并对其执行操作,请考虑一种情况。如果我们使用一个简单的变量概念,那么我们必须创建 1000 个变量并对它们执行操作。但是处理大量的变量是很困难的。因此,最好在数组中存储相同类型的值,然后通过索引号进行访问。
13.1 了解 Shell 脚本中的数组
数组是相似数据元素的结构化排列。在 shell 脚本中,数组是一个包含多个值的变量,无论这些值是相同类型还是不同类型。需要注意的是,在 shell 脚本中,所有内容都被视为字符串。数组遵循基于零的索引,这意味着索引从0开始。
13.2 如何在 Shell 脚本中声明数组
可以使用各种方法在 shell 脚本中声明数组:
- 间接声明
在该方法中,可以为数组变量的特定索引指定一个值。不需要事先声明数组。
ARRAYNAME[INDEXNR]=value
- 显式声明
使用显式声明,首先声明数组,然后为其赋值。
declare -a ARRAYNAME
- 复合赋值
此方法包括声明数组及其初始值集,以后可以向数组中添加其他值。
ARRAYNAME=(value1 value2 .... valueN)
或者,也可以使用索引号显式指定值:
ARRAYNAME=([1]=10 [2]=20 [3]=30)
13.3 在 Shell 脚本中打印数组值:
要显示阵列元素,您有几个选项:
下面是一个解释多个选项的 array_test.sh 脚本。(您可以创建任何名称的脚本)
#!/bin/bash
# To declare a static Array
arr=("prakhar" "ankit" "1" "rishabh" "manish" "abhinav")
# To print all elements of the array
echo "All elements of the array:"
echo "${arr[@]}"
echo "${arr[*]}"
# To print the first element
echo "The first element:"
echo "${arr[0]}"
# To print a selected index element
selected_index=3
echo "Selected index element at index $selected_index:"
echo "${arr[$selected_index]}"
# To print elements from a particular index
echo "Elements from a particular index:"
echo "${arr[@]:2}" # Prints elements starting from index 2
echo "${arr[*]:2}" # Prints elements starting from index 2
# To print elements in a range
echo "Elements in a range:"
echo "${arr[@]:1:3}" # Prints elements from index 1 to 3
echo "${arr[*]:1:3}" # Prints elements from index 1 to 3
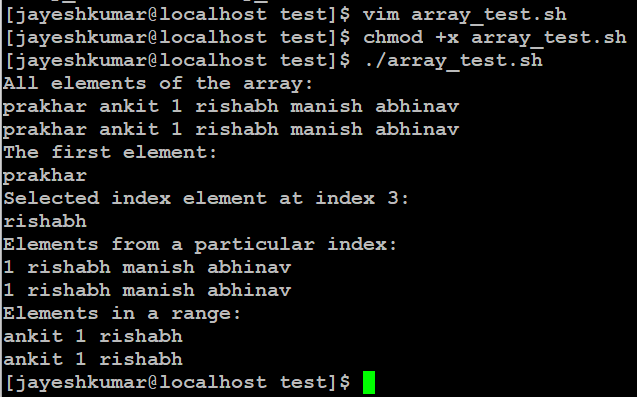
说明:
- 数组声明:
- 声明了一个名为
arr的数组,该数组包含六个元素。 - 这些元素是字符串:
"prakhar"、"ankit"、"1"、"rishabh"、"manish"和"abhinav"。
- 声明了一个名为
- 打印所有元素:
echo "All elements of the array:": 将打印一条消息,指示正在显示阵列的所有元素。${arr[@]}:此语法用于分别打印数组的每个元素。它显示阵列中的所有元素。${arr[*]}:与前一行类似,此语法将数组的所有元素打印为单个字符串。
- 打印第一个元素:
echo "The first element:":打印一条消息,指示正在显示数组的第一个元素。${arr[0]}:此语法检索并显示数组的第一个元素。在 Bash 中,数组索引从 0 开始。
- 打印选定的索引元素:
selected_index=3:名为selected_index的变量被赋予值 3,此变量表示数组中所需的索引。echo "Selected index element at index $selected_index:":打印一条消息以指示所选索引。${arr[$selected_index]}:使用存储在selected_index中的值,此语法检索并显示指定索引处的元素(本例中为索引3)。
- 打印特定索引中的元素:
echo "Elements from a particular index:":打印一条消息,指示正在显示特定索引的元素。${arr[@]:2}:此语法提取并显示数组中从索引 2 开始的所有元素。它分别打印每个元素。${arr[*]:2}:与前一行类似,此语法将元素显示为单个字符串,从索引 2 开始。
- 打印范围内的元素:
echo "Elements in a range:":打印一条消息,指示正在显示指定范围内的元件。${arr[@]:1:3}:此语法提取并显示从索引 1 到索引 3(包括索引 1 和索引 3)的元素。它分别打印每个元素。${arr[*]:1:3}:与前一行类似,此语法将提取的元素显示为单个字符串。
下面是一个 array_test2.sh 脚本,其中没有其他示例。(您可以创建任何名称的脚本)
#!/bin/bash
# Declare a static Array
arr=("Jayesh" "Shivang" "1" "rishabh" "Vipul" "Nishtan")
# Count the length of a particular element in the array
element_length=${#arr[2]}
echo "Length of element at index 2: $element_length"
# Count the length of the entire array
array_length=${#arr[@]}
echo "Length of the array: $array_length"
# Search in the array
search_result=$(echo "${arr[@]}" | grep -c "Jayesh")
echo "Search result for 'Jayesh': $search_result"
# Search and replace in the array
replaced_element=$(echo "${arr[@]/Shivang/SHIVANG}")
echo "Array after search & replace: ${replaced_element[*]}"
# Delete an element in the array (index 3)
unset arr[3]
echo "Array after deletion: ${arr[*]}"
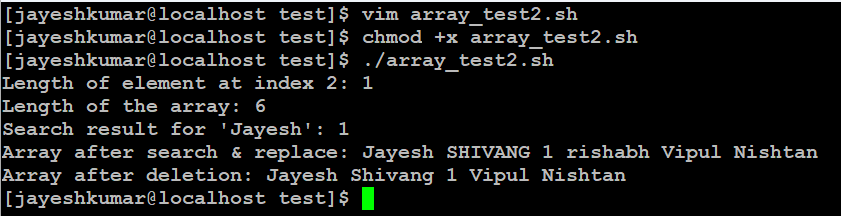
说明:
- 数组声明:
- 声明了一个名为
arr的数组,该数组包含六个元素。 - 这些元素是字符串:
"Jayesh"、"Shivang"、"1"、"rishabh"、"Vipul"和"Nishtan"。
- 声明了一个名为
- 打印元素长度:
- 数组索引 2 处元素的长度使用
${#arr[2]}计算。 - 该长度存储在变量
element_length中。
- 数组索引 2 处元素的长度使用
- 打印数组长度:
- 整个数组的长度使用
${#arr[@]}计算。 - 该长度存储在变量
array_length中。
- 整个数组的长度使用
- 在数据中搜索:
grep命令用于搜索字符串"Jayesh"在数组${arr[@]}中的出现情况。-c标志用于计算出现的次数。- 计数存储在变量
search_result中。
- 在数组中搜索和替换:
- 对数组
${arr[@]}执行搜索和替换操作。 - 字符串
"Shivang"替换为"SHIVANG"。 - 更新后的数组存储在变量
replaced_element中。
- 对数组
- 从数组中删除元素:
unset命令用于从数组${arr[@]}中删除索引 3 处的元素(即"rishabh")。
- 打印所有元素:
- 将回显消息
"Array after deletion:"。 ${arr[@]}语法用于分别打印数组的每个元素。这将显示阵列中的所有元素。
- 将回显消息
13.4 结论
在本文中,我们讨论了数组在 shell 脚本中的实用性。它强调了数组如何有效地处理大量值,替换大量变量。数组声明的概念通过三种方法来解释:间接赋值、显式赋值和复合赋值。本文使用实际的脚本示例进一步说明了打印数组元素。这一讨论不仅揭开了数组使用的神秘面纱,还强调了它在 shell 脚本中管理和操作数据方面的重要性。
14 条件语句 | Shell 脚本
条件语句: 总共有 5 个条件语句可用于 bash 编程
- if 语句
- if-else 语句
- if…elif…else.fi 语句(else if 梯形)
- if…then…else…if…then…fi…fi…(嵌套 if)
- switch 语句
它们的语法描述如下:
14.1 if 语句
如果指定的条件为 true,则此块将进行处理。
语法:
if [ expression ]
then
statement
fi
14.2 if-else 语句
如果 if 部分中指定的条件不为 true,则执行 else 部分。
语法:
if [ expression ]
then
statement1
else
statement2
fi
14.3 if…elif…else…fi 语句
若要在一个 if-else 块中使用多个条件,则在 shell 中使用 elif 关键字。如果 expression1 为 true,则它执行 statement1 和 statement2,并继续此过程。如果所有条件都不为真,则处理 else 部分。
语法:
if [ expression1 ]
then
statement1
statement2
.
.
elif [ expression2 ]
then
statement3
statement4
.
.
else
statement5
fi
14.4 if…then…else…if…then…fi…fi…(嵌套 if)
嵌套 if-else 块可以在满足一个条件时使用,然后再次检查另一个条件。在语法中,如果 expression1 为false,则它处理 else 部分,expression2 将再次被检查。
语法:
if [ expression1 ]
then
statement1
statement2
.
else
if [ expression2 ]
then
statement3
.
fi
fi
14.5 switch 语句
case 语句作为 switch 语句工作,如果指定的值与模式匹配,则它将执行该特定模式的块
当找到匹配项时,执行所有相关联的语句,直到双分号 (;;) 为止。
当执行最后一个命令时,case 将终止。
如果没有匹配项,则 case 的退出状态为零。
语法:
case in
Pattern 1) Statement 1;;
Pattern n) Statement n;;
esac
14.6 示例程序
示例 1:
执行 if 语句
#Initializing two variables
a=10
b=20
#Check whether they are equal
if [ $a == $b ]
then
echo "a is equal to b"
fi
#Check whether they are not equal
if [ $a != $b ]
then
echo "a is not equal to b"
fi
输出:
$bash -f main.sh
a is not equal to b
示例 2:
执行 if..else 语句
#Initializing two variables
a=20
b=20
if [ $a == $b ]
then
#If they are equal then print this
echo "a is equal to b"
else
#else print this
echo "a is not equal to b"
fi
输出:
$bash -f main.sh
a is equal to b
示例 3:
执行 switch 语句
CARS="bmw"
#Pass the variable in string
case "$CARS" in
#case 1
"mercedes") echo "Headquarters - Affalterbach, Germany" ;;
#case 2
"audi") echo "Headquarters - Ingolstadt, Germany" ;;
#case 3
"bmw") echo "Headquarters - Chennai, Tamil Nadu, India" ;;
esac
输出:
$bash -f main.sh
Headquarters - Chennai, Tamil Nadu, India.
注意: Shell 脚本是一种区分大小写的语言,这意味着在编写脚本时必须遵循正确的语法。
15 循环语句 | Shell 脚本
Shell 脚本中的循环语句: 总共有 3 个循环语句可用于 bash 编程
- while 语句
- for 语句
- until 语句
为了改变循环语句的流程,使用了两个命令:
- break
- continue
它们的描述和语法如下:
15.1 while 语句
在这里,对条件进行判断,并根据结果执行循环,如果遇到条件判断为 false,则循环将终止
while <condition>
do
<command 1>
<command 2>
<etc>
done
15.2 for 语句
for 循环对元素列表进行操作,它为列表中的每个元素重复一组命令。
这里 var 是变量的名称,value1 到 valueN 是由空格分隔的字符序列。每次执行 for 循环时,变量 var 的值都被设置为元素列表中的下一个值,即 value1 到 valueN。
语法:
for <var> in <value1 value2 ... valuen>
do
<command 1>
<command 2>
<etc>
done
15.3 until 语句
如果 condition/command 的计算结果为 false,则执行直到循环的次数与执行次数一样多。当 condition/command 变为 true 时,循环终止。
语法:
until <condition>
do
<command 1>
<command 2>
<etc>
done
15.4 示例程序
示例 1:
用 break 语句实现 for 循环
#Start of for loop
for a in 1 2 3 4 5 6 7 8 9 10
do
# if a is equal to 5 break the loop
if [ $a == 5 ]
then
break
fi
# Print the value
echo "Iteration no $a"
done
输出:
$bash -f main.sh
Iteration no 1
Iteration no 2
Iteration no 3
Iteration no 4
示例 2:
用 continue 语句实现 for 循环
#Start of for loop
for a in 1 2 3 4 5 6 7 8 9 10
do
# if a = 5 then continue the loop and
# don't move to line 10
if [ $a == 5 ]
then
continue
fi
echo "Iteration no $a"
done
输出:
$bash -f main.sh
Iteration no 1
Iteration no 2
Iteration no 3
Iteration no 4
Iteration no 6
Iteration no 7
Iteration no 8
Iteration no 9
Iteration no 10
示例 3:
实现 while 循环
a=0
# -lt is less than operator
#Iterate the loop until a less than 10
while [ $a -lt 10 ]
do
# Print the values
echo $a
# increment the value
a=`expr $a + 1`
done
输出:
$bash -f main.sh
0
1
2
3
4
5
6
7
8
9
示例 4:
实现 until 循环
a=0
# -gt is greater than operator
#Iterate the loop until a is greater than 10
until [ $a -gt 10 ]
do
# Print the values
echo $a
# increment the value
a=`expr $a + 1`
done
输出:
$bash -f main.sh
0
1
2
3
4
5
6
7
8
9
10
注意: Shell 脚本是一种区分大小写的语言,这意味着在编写脚本时必须遵循正确的语法。
示例 5:
COLORS="red green blue"
# the for loop continues until it reads all the values from the COLORS
for COLOR in $COLORS
do
echo "COLOR: $COLOR"
done
输出:
$bash -f main.sh
COLOR: red
COLOR: green
COLOR: blue
示例 6:
- 我们甚至可以使用循环访问位置参数
- 我们使用三个参数执行一个名为
main.sh的 shell 脚本 - 脚本执行:
main.sh sample1 sample2 sample3 - 我们可以使用
$@访问以上三个参数
echo "Executing script"
# the script is executed using the below command
# main.sh sample1 sample2 sample
# where sample1, sample2 and sample3 are the positional arguments
# here $@ contains all the positional arguments.
for SAMPLE in $@
do
echo "The given sample is: $SAMPLE"
done
输出:
$bash -f main.sh sample1 sample2 sample3
Executing script
The given sample is sample1
The given sample is sample2
The given sample is sample3
示例 7:
无限循环
while true
do
# Command to be executed
# sleep 1 indicates it sleeps for 1 sec
echo "Hi, I am infinity loop"
sleep 1
done
输出:
$bash -f main.sh
Hi, I am infinity loop
Hi, I am infinity loop
Hi, I am infinity loop
.
.
.
.
It continues
示例 8:
检查用户输入
CORRECT=n
while [ "$CORRECT" == "n" ]
do
# loop discontinues when you enter y i.e.e, when your name is correct
# -p stands for prompt asking for the input
read -p "Enter your name:" NAME
read -p "Is ${NAME} correct? " CORRECT
done
输出:
$bash -f main.sh
Enter your name:Ironman
Is Ironman correct? n
Enter your name:Spiderman
Is Spiderman correct? y
16 Linux 中的 break 与 continue 关键字(附示例)
break 和 continue 都用于将程序的控制权转移到程序的另一部分。它在循环中用于更改循环的流程并终止循环或跳过当前迭代。
16.1 break
break 语句用于终止循环,可以在 while、for、until 和 select 循环中使用。
语法:
break [N]
// N is the number of nested loops.
// This parameter is optional.
// By default the value of N is 1.
在循环中使用 break 命令。
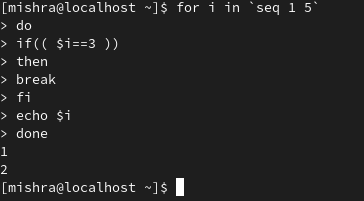
可以看出,当 i 的值为 3 时,循环执行终止,因此 i 只打印到 2。
示例: 使用值为 N 的 break。考虑一个示例:
for i in `seq 1 5`
do
for j in `seq 1 5`
do
if(( $j== 2 ))
then
break 2
fi
echo "value of j is $j"
done
echo "value of i is $i"
done
当 break 的值为 2 时,当 j 的值为 1 时,两个循环都在一个步骤中退出。所以,j 的唯一值是在它为 1 时打印出来的。

16.2 continue
continue 是一个命令,用于跳过 for、while 和 until 循环中当前迭代的循环内的剩余命令。
语法:
continue [N]
// the optional parameter N specifies the nth enclosing loop to continue from.
// This parameter is optional.
// By default the value of N is 1.
在循环中使用 continue 命令
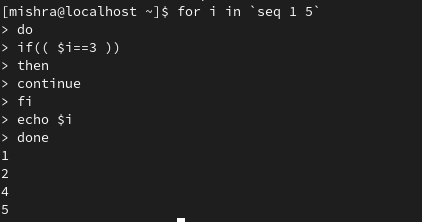
示例: 使用 continue 并将其值设为 N。考虑一个示例:
for i in `seq 1 5`
do
for j in `seq 1 5`
do
if(( $j== 2 ))
then
continue 2
fi
echo "value of j is $j"
done
echo "value of i is $i"
done
当 j 的值为 2 时,continue 跳过两个循环,因此,代码仅在 j 值为 1 时执行。
16.3 break 与 continue 之间的差异
| No. | break | continue |
|---|---|---|
| 1 | 它终止所有剩余迭代的循环执行 | 它只跳过当前迭代的循环执行 |
| 2 | 它允许提前终止循环 | 它允许提前执行下一次迭代 |
| 3 | 它停止循环的执行 | 它仅针对当前迭代停止循环的执行 |
| 4 | 循环结束后的代码将继续 | 循环中的代码跳过当前迭代继续执行 |
17 Shell 脚本——函数及其类型
Shell 是一个命令行解释器,shell 脚本通常执行文件操作、程序执行和文本输出。在本文中,我们将了解 shell 脚本中的函数及其类型。
17.1 函数
函数是执行指定任务的语句的集合,它的主要目标是将复杂的过程分解为更简单的子例程,这些子例程随后可以用来完成更复杂的例程。由于以下原因,函数很受欢迎:
- 协助代码重用
- 增强程序的可读性
- 将软件模块化
- 便于维护
Shell 脚本中函数的基本结构如下:
function_name(){
// body of the function
}
function_name 可以是脚本语言中的任何有效字符串,正文可以是任何有效语句序列。
让我们通过看一个例子来理解函数的概念。下面是一个代码,用于打印范围 [le,ri] 之间的所有素数。它由一个函数 is_prime() 组成,该函数用于检查给定的数字是否为素数。在这个函数中,我们使用变量 $1 来访问第一个参数,即数字本身。在脚本语言中,我们可以通过 $i 访问参数,其中 i 是一个表示参数位置的数字。
echo -n "Enter Left-End: "
read le
echo -n "Enter Right-End: "
read ri
is_prime(){
if [ $1 -lt 2 ]; then
return
fi
ctr=0
for((i=2;i<$1;i++)){
if [ $(( $1 % i )) -eq 0 ]; then
ctr=$(( ctr +1 ))
fi
}
if [ $ctr -eq 0 ]; then
printf "%d " "$1"
fi
}
printf "Prime Numbers between %d and %d are: " "$le" "$ri"
for((i=le;i<=ri;i++)){
is_prime $i
}
printf "\n"

17.2 函数类型
Shell 脚本中的函数可以分为多个类别。以下是其中的一些:
- 向调用者返回值的函数。return 关键字由函数用于此目的。
下面是一个这样的函数,用于计算给定数字的平均值。
find_avg(){
len=$#
sum=0
for x in "$@"
do
sum=$((sum + x))
done
avg=$((sum/len))
return $avg
}
find_avg 30 40 50 60
printf "%f" "$?"
printf "\n"
输出:

请记住,return 只能返回一个数字(0-255)。
- 使用 exit 关键字终止 shell 的函数。
is_odd(){
x=$1
if [ $((x%2)) == 0 ]; then
echo "Invalid Input"
exit 1
else
echo "Number is Odd"
fi
}
is_odd 64
输出:

- 改变一个或多个变量值的函数。
a=1
increment(){
a=$((a+1))
return
}
increment
echo "$a"
输出:

- 将输出回显到标准输出的函数。\
hello_world(){
echo "Hello World"
return
}
hello_world
输出:

18 如何传递和解析 Linux Bash 脚本参数和参数
将参数解析和传递到 bash 脚本/shell 脚本中的方式与我们将参数传递到 bash 脚本中的函数的方式非常相似。我们将看到将参数传递到脚本的实际过程,并查看在脚本中访问这些参数的方法。
18.1 运行前传递参数
在运行 bash 解释器命令时,我们可以在脚本名称之后传递参数。您可以将参数或变量传递到文件,只是通常我们通过将参数直接添加到脚本来运行脚本。传递给 shell 脚本的每个参数都是一个用空格分隔的值。
bash scriptname.sh
上面的命令将只运行脚本,而不传递参数。
而下面的命令将把参数传递给脚本。
bash scriptname.sh parameter1 parameter2 parameter3 nth-parameter
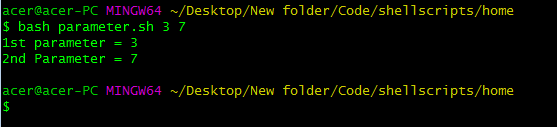
上面的屏幕截图显示了传递给脚本的参数,以及我们将如何做到这一点,我们将在下一节中对此进行解释。但现在我们可以看到,我们已经使用 bash 环境变量从脚本外部传入了参数。您甚至可以使用字符串和其他数据类型,但要注意任何空格。空格将使变量成为一个单独的参数。因此,特别是对于字符串,要小心将它们严格地用引号括起来。
18.2 检测命令行参数
现在,我们将看到如何在脚本中访问这些参数。我们将使用按顺序传递的参数的数量,即对于传递的第一个参数,我们将使用$1 作为变量来解析(访问)参数。第一个参数存储在 $1 变量中。此外,您可以将此变量分配给您喜欢的任何其他用户定义的变量。对于传递的第 n 个参数,可以使用 $n 访问该特定参数。这里,变量名以 1 开头,因为文件名/脚本名是第 0 个参数。如果您有 9 个以上的参数,请确保在数字周围使用 {},因为没有括号,bash 将 $10 视为 $1,并排除 0,因此使用 ${10} 等,而不是简单地使用 $10。
#!/bin/bash
echo "1st parameter = $1 "
echo "2nd Parameter = $2 "
上面的脚本可以使用位置参数从命令行/shell访问参数,这些位置参数是 1、2、3 等等。
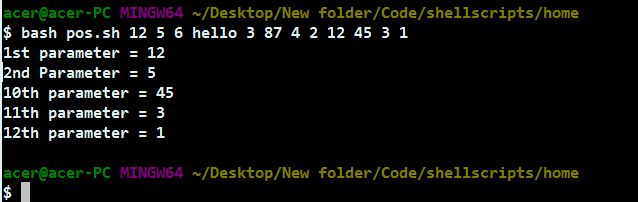
正如您所看到的,我们已经使用 {} 来访问从 10 开始的参数变量数字。该脚本可以用于 for 循环和 while 循环来迭代参数,但我们将在下一节中讨论它。
18.3 将提供的参数分配给 Bash 变量
我们还可以将其分配给其他自定义变量,使脚本更加动态,并根据需要进行建模。虽然上面的脚本在运行时只会打印两个参数,但您肯定可以使用变量作为参数的数字顺序来访问更多的参数。脚本可以从命令行访问位置变量,并在脚本中任何需要的地方使用它们。
#!/bin/bash
a=$1
b=$2
p=$(($a*$b))
echo "The product of $a and $b = $p"
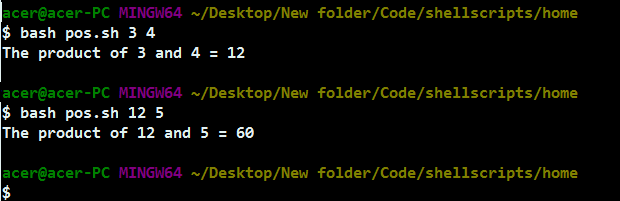
上面的脚本访问传递到脚本中的位置参数,即 $1 和 $2,并存储用户定义的变量,以便稍后访问它们并相应地修改它们。我们还可以使用迭代方法访问更多的参数,我们将在接下来的部分中看到。
我们还可以检查使用 -z 或 -n 标志传递的任何 NULL 或空参数。由此,我们可以验证参数是否被传递。
#!/bin/bash
if [[ -z $1 ]];
then
echo "No parameter passed."
else
echo "Parameter passed = $1"
fi
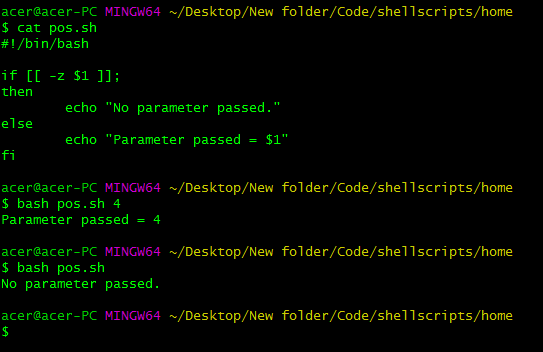
有了这个脚本,我们可以检测是否传入了任何位置参数,或者什么也没传递。-z 标志检查 BASH 中是否有任何 NULL 或未初始化的变量。如果传递的变量为 NULL 或未初始化,则 -z 标志返回 true。因此,我们可以使用基本的 if-else 语句来检测传递的参数。
我们还可以使用 -n 标志,如果没有传递参数,它将返回 true,所以我们必须使用 ! 以扭转这种状况。
如下所示:
#!/bin/bash
if [[ ! -n $1 ]];
then
echo "No parameter passed."
else
echo "Parameter passed = $1"
fi
这个脚本也将提供相同的输出,但我们使用 -n 标志而不是 -z。
18.4 使用 For 或 While 循环读取多个参数
我们可以使用 @ 变量来访问通过命令行传递给脚本的每个参数。它是一个特殊的变量,用于保存 BASH 中的变量数组。在这种情况下,我们单独使用它,因此它包含传入的位置参数数组。我们可以使用它来迭代使用循环或 while 循环传递的参数。
#!/bin/bash
for i in $@
do
echo -e "$i\n"
done
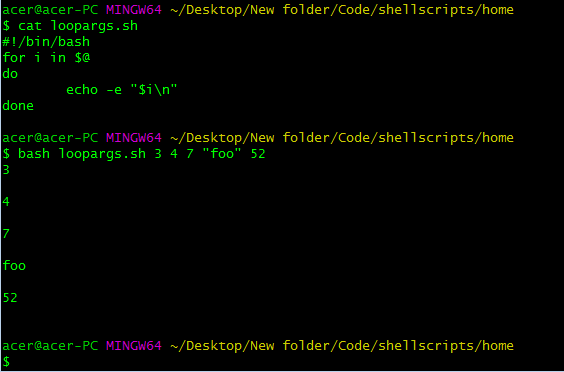
我们使用了一个基于范围的 for 循环来迭代,直到 @ 数组中有元素为止。我们只需对数组进行迭代并打印元素。我们可以简单地分配它,修改值,并对参数和变量进行必要的更改,以从脚本中获得所需的结果。
或者
我们还可以使用 while 循环和 BASH 的环境变量打印参数。
#!/bin/bash
i=$(($#-1))
while [ $i -ge 0 ];
do
echo ${BASH_ARGV[$i]}
i=$((i-1))
done
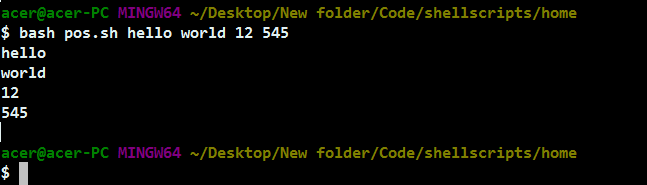
我们使用变量 #,因为它包含传入的参数数量。我们初始化参数数量,并在使用数组对其进行迭代时去掉一个。因此,与往常一样,数组的索引从 0 开始。由于这个数组是从最后一个传递的元素或参数初始化的,我们需要递减计数器直到 0,以按传递顺序打印每个参数。我们只需使用 BASH_ARGV 数组来访问参数并打印其值。此外,在每次迭代中,我们使用算术双大括号将 i- 迭代器或计数器的值减少一。由此,我们只需使用 while 循环打印传递给脚本的每个参数,如输出屏幕截图所示。
18.5 使用参数名称读取
18.5.1 使用 getopts 解析参数和参数
我们可以使用 getopts 程序/命令,通过使用循环和 switch-case 语句来解析在命令行/终端中传递给脚本的参数。
#!/bin/bash
while getopts n:c: option
do
case "${option}"
in
n)nation=${OPTARG};;
c)code=${OPTARG};;
esac
done
echo "Nation : $nation"
echo "code : $code"
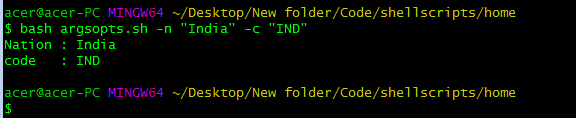
使用 getopts,我们可以直接将命令行中的位置参数/参数分配给 bash 变量,这使我们能够以系统的方式很好地管理参数。在上面的脚本中,我们使用两个参数来存储 bash 变量,展示 getopts 语法,while 循环和 switch-case 语句。
18.5.2 打印所有参数的值
我们可以通过一个简单而强大的变量 @ 打印传递给脚本的参数,该变量存储了传递的所有参数。
#!/bin/bash
echo "The arguments passed in are : $@"
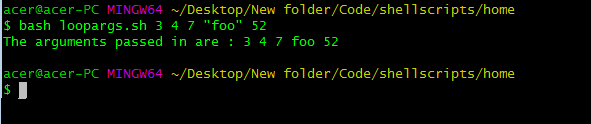
18.5.3 访问传递的参数数量
我们还可以使用变量 # 来访问从命令行传递的参数数量。# 变量基本上包含传递到脚本中的参数/变量的数量。
#!/bin/bash
echo "The number of arguments passed in are : $#"

以下是传递和解析 bash 脚本中变量的过程和规范,对变量进行转换和修改的逻辑掌握在用户手中,这只是将参数从命令行传递并解析到脚本以使其更具动态性的演示。
19 Shell 脚本 | 标准输入,输出与错误
在 Linux 应用程序上,我们有几种方法可以从外部获取信息并将其放入内部:命令行参数、环境变量、文件。所有这些来源都是合法和良好的。但它的大小是有限的。另一种建立通信的方法是标准流:用于从应用程序外部获取数据的输入流(stdin),用于将数据放在应用程序外部的输出流(stdout),以及用于将数据放置在应用程序之外的错误(stderr)。
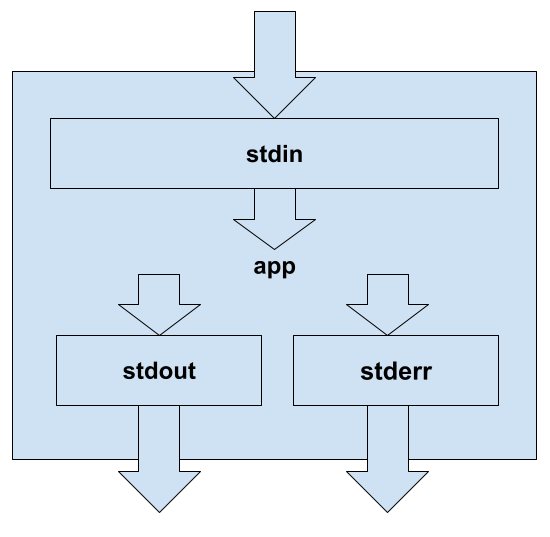
每个流都像一个管道:它有相同的缓冲区来写入和读取数据。该缓冲区可用于从一个应用程序读取,也可用于从另一个应用软件写入。读取时,占用的缓冲区大小将减少,写入时将增加。如果读取和写入的平均速率相等,那么通过流传递的数据可以是任意数量的字节长。
19.1 输入/输出流操作示例
让我们看一个 grep 应用程序的例子,描述它如何与之交互。
脚本:
#!/usr/bin/env bash
echo pattern | grep pattern
echo pattern | grep pattern
在控制台上运行的脚本:
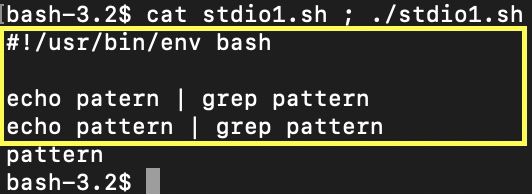
这次我们运行了两个命令:cat stdio1.sh——列出脚本主体,./stdio1.sh 运行脚本。echo-pattern 形成连接到 grep 标准输入流的标准输出流。所以所有的数据都进入 grep。grep 是一个应用程序,如果匹配模式,它会从输入流写入输出流。第一个输入不匹配——不需要输出。脚本的第二个字符串 echo-pattern|grep-pattern 具有适当的输入——它已被传递到 grep 输出,并在接下来的控制台中显示。
19.2 错误流操作示例
stderr 与 stdout 非常相似:只有一个区别——如果它占据某个位置,它将包含一个错误报告。
脚本:
#!/usr/bin/env bash
ls > /tmp/log
cat /tmp/log
ls /not/existed_path > /tmp/log
cat /tmp/log
cat /tmp/log
rm /tmp/log
在控制台上运行的脚本:
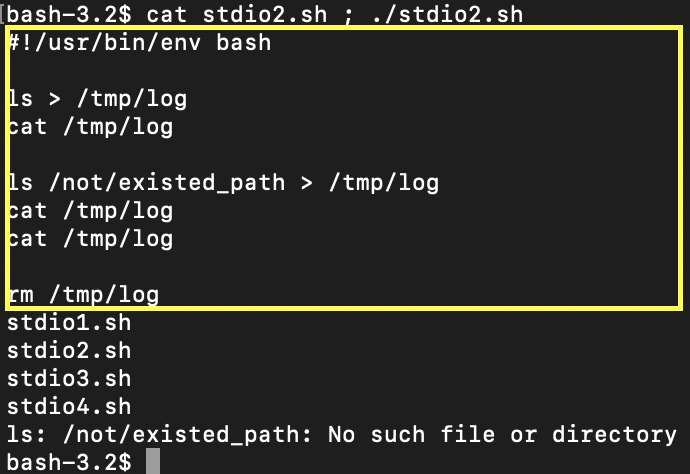
在这个脚本中,我们列出了当前目录(ls)中的文件,并将标准输出重定向到该文件(/tmp/log)。然后,我们在控制台上显示读取文件的 cat 实用程序的标准输出流中的文件数据。接下来,我们尝试列出不存在的文件夹中的文件,并如上所述将结果存储到文件中,并显示两次。但没有效果。控制台中只有一个关于错误的输出。这是因为这个错误来自 ls 的标准错误流。我们删除了这个文件以清除一些空间 /tmp/log。
19.3 流重定向
可以操作标准流:重定向它们或使用管道处理它们。
脚本:
#!/usr/bin/env bash
ls /not/existed_path 2>/dev/null
ls * /not/existed_path > /tmp/log 2> /tmp/err_log
cat /tmp/log
rm /tmp/log /tmp/err_log
在控制台上运行的脚本:
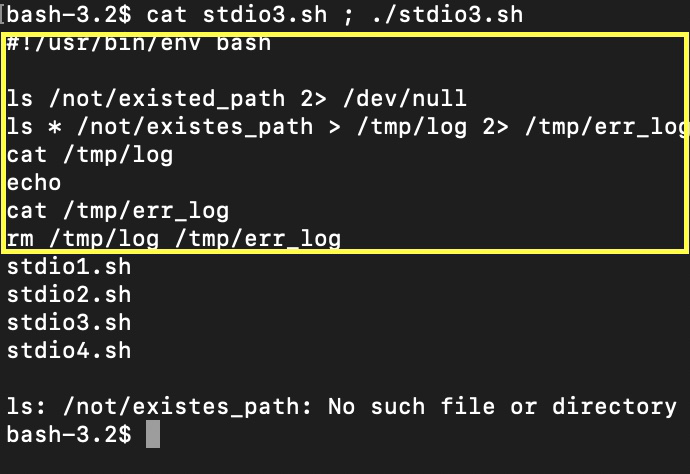
我们在此命令中使用 > 重定向操作,/dev/null——是一个流终止文件,用于删除任何未经处理的输入。2> 子句将标准输出流重定向到文件。现在,可以稍后通过调用cat /tmp/log 或 cat /tmp/err_log 来查看输出和错误。
19.4 放弃输出
在某些情况下,删除所有应用程序输出是有用的(以节省存储空间或删除要分析的不重要的数据源)。我们应该记住,我们不仅应该静默标准输出流,还应该静默标准错误流。让我们来看看它是如何工作的一个例子。
脚本:
#!/usr/bin/env bash
ls . unexisted_file > /dev/null
ls . unexisted_file > /dev/null 2>&1
在控制台上运行的脚本:

在脚本的两行中,标准输出流都重定向到文件 /dev/null。这个文件本身不是一个文件:而是一个具有文件接口的特殊 Linux 设备。它有一个可从 shell 获得的写函数(它什么都不做)。所以所有的输入都被丢弃了。但脚本的第二个字符串与第一个字符串不同:命令末尾的 2>&1。这些符号表明,对于该命令,第二标准流(标准错误流)需要永久地指向第一标准流(标准输出流)。这就是为什么我们在控制台中只看到一条错误消息——最终重定向到终止文件设备 /dev/null 的脚本标准错误流的第二个命令字符串处。
19.5 管道流
修改流也很有用。能够运行由流连接的多个应用程序。
脚本:
#!/usr/bin/env bash
touch /tmp/a
ls /tmp/* 2> /dev/null | grep -w a
rm /tmp/a
在控制台上运行的脚本:
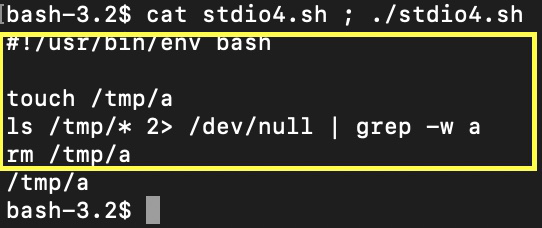
在这里,我们收集列表,并使用 | 将 ls 标准输出流设置为 grep 标准输入流。在 2> 上,标准错误流被重定向到终止文件。grep 的输出流包含列表中与 grep 模式匹配的 /tmp/a 文件名。
19.6 Here 文档
Here 文档是通过信息原生方式填充应用程序输入流的重定向选项:
application << delimiter
some useful text
delimiter
脚本:
#!/usr/bin/env bash
grep perfect << EOF
PERFECT STORY
past perfect
is it Perfect?
EOF
在控制台上运行的脚本:
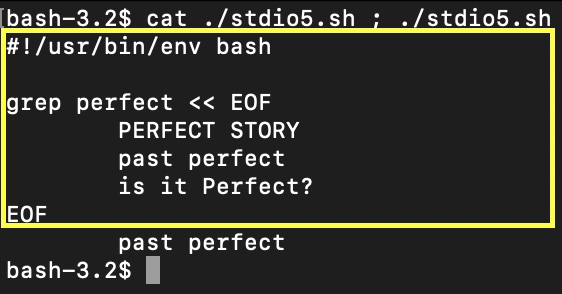
正如我们所看到的,由 EOF 分隔的 grep 标准输入流的 3 个文本字符串中只有第二个字符串与 grep 模式匹配:这就是为什么它传递给 grep 标准输出流,并在接下来的控制台中显示。
19.7 结论
有几个标准实用程序可以处理流(cat、cut、grep、sed、tr…)。您可以使用它或编写自己的数据流处理管道,以满足您的需求。在后台,它将与 stdin、stdout、stderr 一起工作。
20 对文件执行操作的 Shell 脚本
大多数时候,我们使用 shell 脚本与文件进行交互。Shell 脚本提供了一些运算符以及一些命令来检查和执行与文件相关的不同属性和功能。
为了方便起见,我们创建了一个名为 geeks.txt 的文件和另一个 .sh 文件(或者只是在命令行上运行),以在该文件上执行不同的功能或操作。操作可能是读取文件的内容或测试文件类型。下面将通过适当的例子对这些问题进行讨论:
20.1 文件读取功能
文件读取是程序员生活中一项有趣的任务。Shell 脚本提供了一些读取文件、反转内容、计算单词、行数等功能。
- 逐行读取: 首先,我们使用
read命令获取输入,然后运行while循环,该循环逐行运行。
脚本:
#!/bin/bash
read -p "Enter file name : " filename
while read line
do
echo $line
done < $filename
- 计算文件中的字符、单词和行: 我们取三个变量,一个用于分别计算字符、单词、行。我们使用
wc命令,它代表单词计数(word count),还计算字符和单词的数量。对于计数行,我们传递grep,它保持对匹配模式的行的计数。然后我们打印出每个变量。
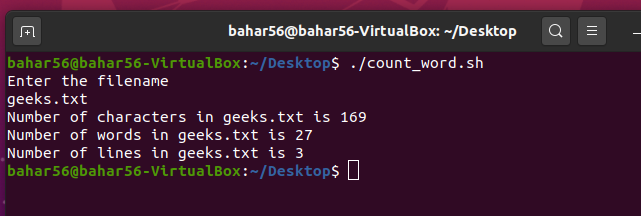
脚本:
#! /bin/bash
echo Enter the filename
read file
c=`cat $file | wc -c`
w=`cat $file | wc -w`
l=`grep -c "." $file`
echo Number of characters in $file is $c
echo Number of words in $file is $w
echo Number of lines in $file is $l
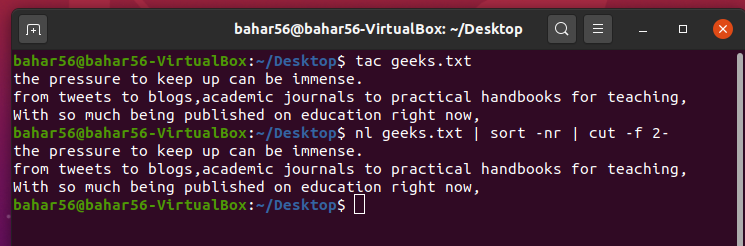
- 反向显示文件内容: 要反向打印任何文件的内容,我们使用
tac或nl、sort、cut命令。tac是cat的反写,只是按相反的顺序打印文件。nl负责编号,文件内容按相反的顺序对编号进行排序,而cut命令删除编号并打印文件内容。
脚本:
$ nl geeks.txt | sort -nr | cut -f 2-
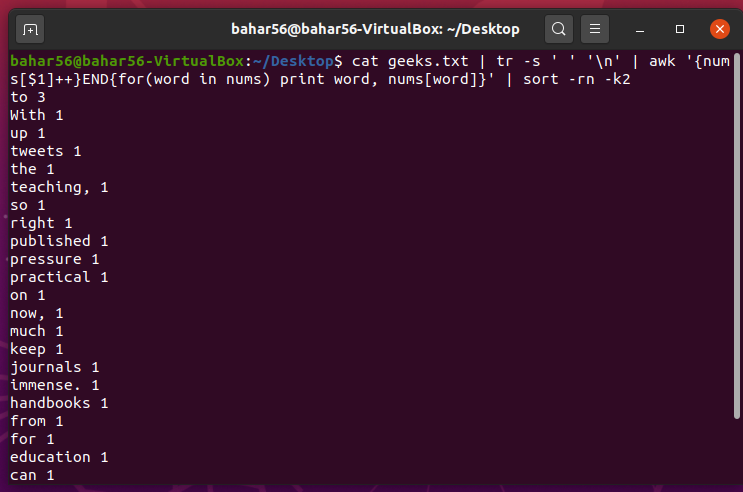
- 文件中特定单词的频率: 为了计算文件中每个单词的频率,我们使用某些命令。这些是
xargs,它将打印应用于输出中的每一行,排序,当前缓冲区管道连接到它,uniq -c显示缓冲区中每一行的计数,最后是awk,根据问题要求打印第二列,然后打印第一列。
脚本:
cat geeks.txt | xargs printf “%s\n” | sort | uniq -c | sort -nr | awk ‘{print $2,$1}’
20.2 文件测试运算符
| Syntax | Description |
|---|---|
-a file | 判断文件是否存在 |
-b file | 判断是否为块特殊文件(block special file) |
-c file | 判断文件是否为一个字符特殊文件(character special file) |
-d file | 判断是否为目录(directory) |
-e file | 判断文件是否存在(exist) |
-f file | 判断是否为普通文件或特殊文件(file) |
-g file | 判断文件是否拥有 SGID 权限(set-group-id) |
-h file | 判断文件是否为符号链接(symbolic link) |
-k file | 判断文件是否设置了 sticky 位,拥有 SBIT 权限 |
-p file | 判断是否为管道文件(pipe, FIFO) |
-r file | 判断文件是否可读(readable) |
-s file | 判断文件大小(size)是否大于 0 |
-t file | 判断文件描述符 fd 是否打开且关联到一个终端(terminal) |
-u file | 判断文件是否拥有 SUID 权限(set-user-id) |
-w file | 判断文件是否可写(writable) |
-x file | 判断文件是否可执行(executable) |
-G file | 判断文件是否被有效组 ID 拥有(effective group id) |
-L file | 判断文件是否为符号链接(symbolic link) |
-N file | 判断文件是否自上次读取以来已被修改 |
-O file | 判断文件是否被有效用户 ID 拥有(effective user id) |
-S file | 判断文件是否为 socket |
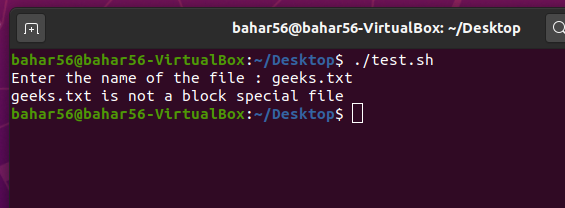
- -b file: 此运算符检查文件是否为块特殊文件(block special file),然后返回 true 或 false。它在语法上是
-b $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -b $file_name ]
then
echo "$file_name is a block special file"
else
echo "$file_name is not a block special file"
fi
输出:
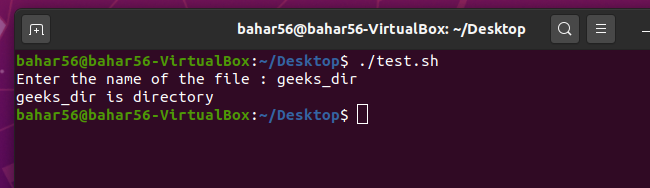
- -d file: 如果文件以目录的形式存在,则运算符会进行检查。如果是,则返回 true,否则返回 false。它在语法上是
-d $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -d $file_name ]
then
echo "$file_name is a directory"
else
echo "$file_name is not a directory"
fi
输出:
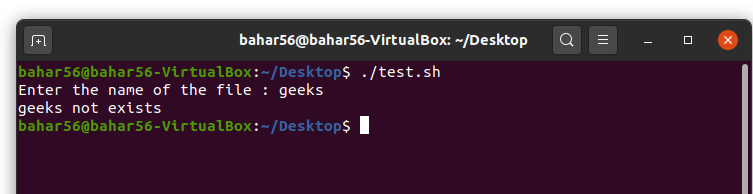
- -e file: 检查文件是否存在。即使传递了一个目录,如果该目录存在,它也会返回 true。它在语法上是
-e $file。
语法:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -e $file_name ]
then
echo "$file_name exist"
else
echo "$file_name not exist"
fi
输出:
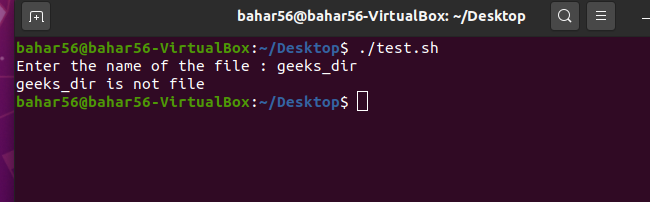
- -f file: 如果文件是普通文件或特殊文件,则返回 true 或 false。它在语法上是
-f $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -f $file_name ]
then
echo "$file_name is file"
else
echo "$file_name is not file"
fi
输出:
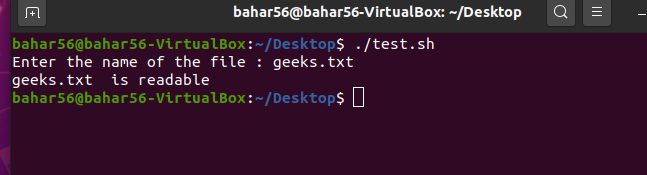
- -r file: 这将检查文件是否可读。如果发现是,则返回 true,否则返回 false。它在语法上是
-r $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -r $file_name ]
then
echo "$file_name is readable"
else
echo "$file_name is not readable"
fi
输出:
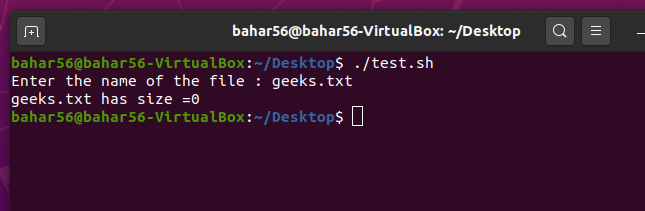
- -s file: 此运算符检查文件的大小是否大于零,随后返回 true 或 false。它在语法上是
-s $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -s $file_name ]
then
echo "$file_name has size>0"
else
echo "$file_name has size= 0"
fi
输出:
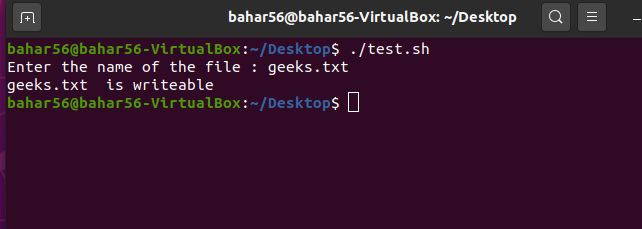
- -w file: 如果允许对文件进行写入,则运算符返回 true,如果不允许,则返回 false。它在语法上是
-w $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -w $file_name ]
then
echo "$file_name is writable"
else
echo "$file_name is not writable"
fi
输出:
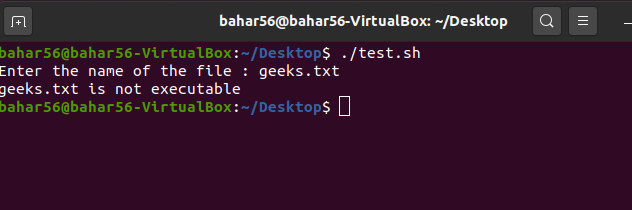
- -x file: 运算符检查文件是否可执行,然后返回 true和 false。它在语法上是
-x $file。
脚本:
#! /bin/bash
echo -e "Enter the name of the file : \c"
read file_name
if [ -x $file_name ]
then
echo "$file_name is executable"
else
echo "$file_name is not executable"
fi
输出:
20.3 重命名与删除文件
要重命名文件,我们使用 mv 命令更改文件名,并使用 rm 删除文件。
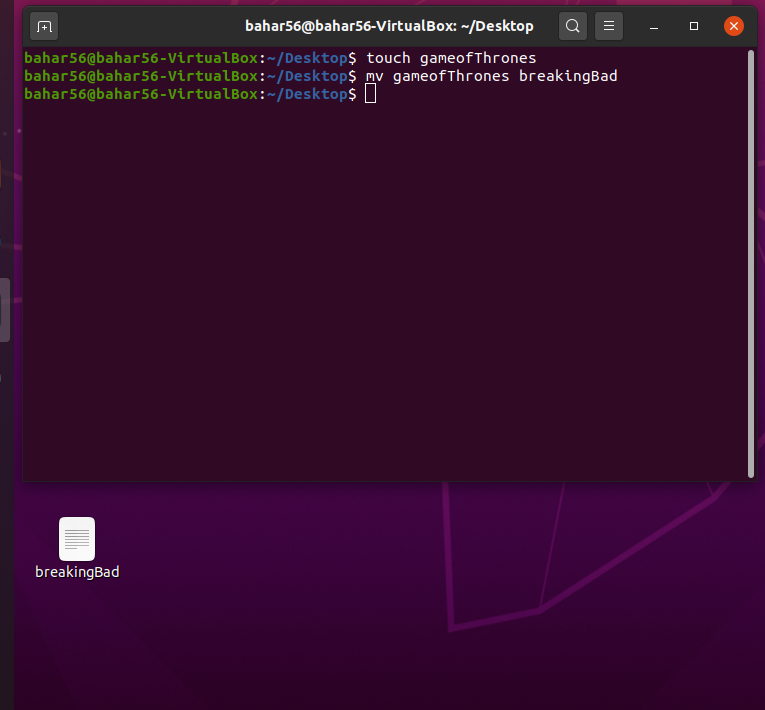
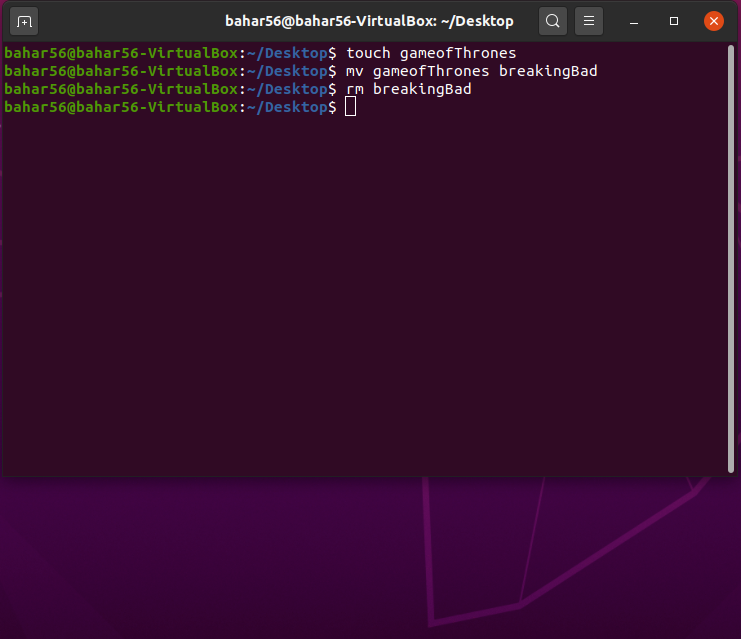
正如我们在命令行下面看到的,breakingBad(重命名后)并用 rm 命令删除它,它就不在了。
21 Shell 脚本举例说明特殊参数
在这里,我们将了解 shell 脚本的特殊参数是什么。首先,让我们了解一下 shell 中的参数是什么。参数是存储值的实体,变量是用户定义的参数,用于特定的 shell 脚本。特殊参数是由 shell 预定义和维护的只读变量。现在让我们看看 bash shell 中的特殊参数是什么。
| No | Special Parameters | Description |
|---|---|---|
| 1 | $# | 此参数表示传递给 shell 脚本的参数数量 |
| 2 | $0 | 此参数表示脚本名称 |
| 3 | $i | 此参数表示传递给 shell 脚本的第 i 个参数,如 $1、$2 |
| 4 | $* | 此参数提供传递给 shell 脚本的所有参数,用空格分隔 |
| 5 | $! | 此参数给出最后一个后台运行进程的 PID |
| 6 | $? | 此参数表示执行的最后一个命令的退出状态。0 代码表示成功,1 表示失败 |
| 7 | $_ | 此参数提供给执行的上一个命令的最后一个参数 |
| 8 | $$ | 此参数提供当前 shell 的 PID |
| 9 | $@ | 此参数保存传递给脚本的所有参数,并将它们视为一个数组。它类似于 $* 参数 |
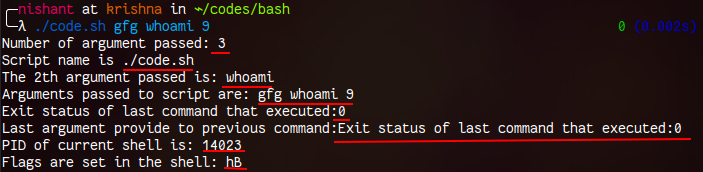
| 10 | $- | 这个参数表示 shell 中设置的当前标志。himBH 是 bash shell 中的标志。他们是: H - histexpandm - monitorh - hashallB - braceexpandi - interactive |
现在让我们看一下演示所有特殊参数的脚本。
echo "Number of argument passed: $#"
echo "Script name is $0"
echo "The 2nd argument passed is: $2"
echo "Arguments passed to script are: $*"
echo "Exit status of last command that executed:$?" #This is the previous command for $_
echo "Last argument provide to previous command:$_"
echo "PID of current shell is: $$"
echo "Flags are set in the shell: $-"
现在让我们看看上面脚本的输出:
22 Linux 中的用户空间调试工具
在本文中,我们将讨论Linux中的调试工具。调试工具是那些允许我们在执行其他程序时监视、控制和纠正错误的程序。
一些调试工具如下所示:
print语句- 查询(
/proc,/sys等) - Tracing (
strace/ltrace) - Valgrind (
memwatch) - GDB
22.1 ‘print’ 语句
print 语句是 Linux 中的一个基本调试语句。您可以在程序中插入打印语句,以了解程序的控制流。调试程序是一种毫不费力的技巧。
它有一些缺点。程序需要编辑并在程序中添加打印语句,然后重新运行程序,这很耗时,而且在大量程序中不起作用。
当您遇到错误时,可以像这样在程序中添加打印语句。它将向您显示这样的错误消息
print Error

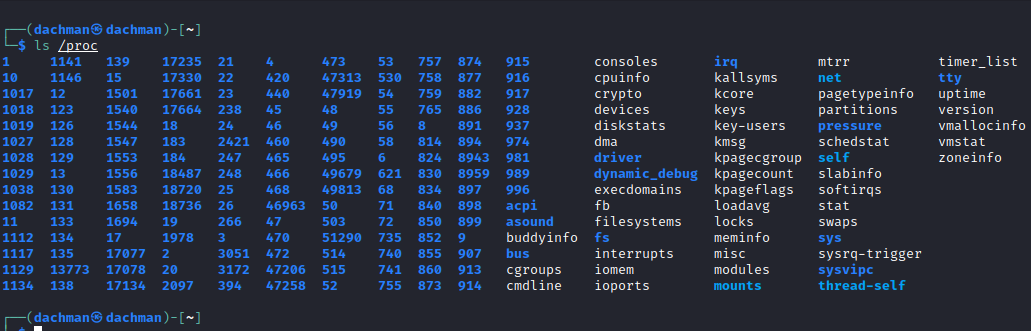
22.2 查询
有时,我们想知道哪个进程在系统中占用了多少内存,内核中的进程状态是什么,等等。如果你想获得这种类型的信息,你需要使用 proc 文件系统,它会为你提供运行时系统信息。如果你想了解更多关于 proc 文件系统的信息,你可以阅读这篇文章 Proc File Systemproc
ls /proc
22.3 Tracing
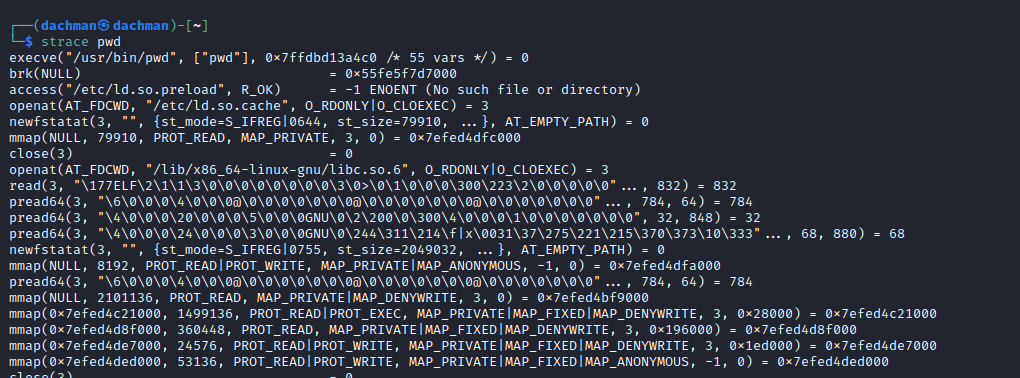
strace 命令用于跟踪程序和进程。
strace 是 Linux 中的一个诊断命令。此命令会截获该命令进行的任何系统调用。strace 可以附加到已经运行的进程或新进程。它还可以用作一种工具,通过跟踪不同的命令来了解系统调用是如何工作的。
strace 命令有很多选项,您可以使用 man strace 命令检查所有选项。
strace pwd
输出:
22.4 Valgrind
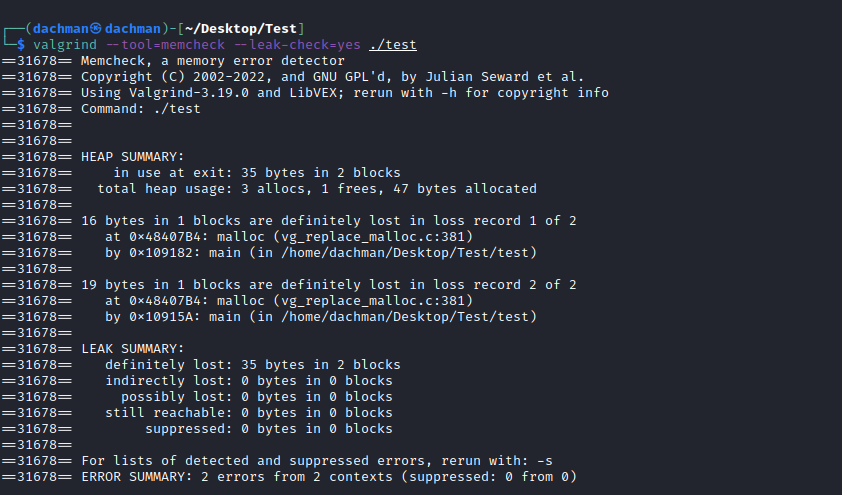
Valgrind 是一套调试工具。Valgrind 有一个被广泛使用的工具,名为 memcheck。这是一个内存检查工具,可以拦截对 malloc()、free() 和 delete() 的调用。它适用于直接可执行的文件。Valgrind 也有一些缺点。它可能会提供假阳性和假阴性结果。它无法检测到超出范围的已分配数组。
让我们看看 Valgrind 是如何工作的。
Valgrind 语法:
valgrind --tool=memcheck --leak-check=yes filename
我们将编写 C 代码,并尝试使用 Valgrind 查找错误。让我们看看
#include <stdio.h>
int main()
{
char *p;
// Allocation #1 of 19 bytes
p = (char *) malloc(19);
// Allocation #2 of 12 bytes
p = (char *) malloc(12);
free(p);
// Allocation #3 of 16 bytes
p = (char *) malloc(16);
return 0;
}
输出:
在这里,您可以看到该代码中显示的 2 个错误。
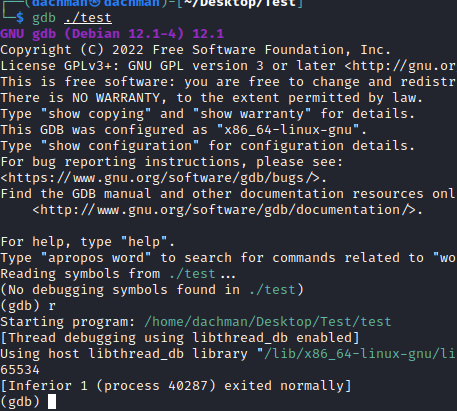
22.5 GDB
GDB 是自由软件基金会(Free Software Foundation)的调试工具。GDB 是一个调试工具,可以帮助查找代码中的错误。它对于查找代码中的问题非常有用,它执行各种操作。
- 启动问题
- 在特定位置停止
- 在特定条件下停止等。
如果你想了解更多关于GDB的信息,你可以查看这篇文章 GDB Introduction
GDB 示例
我们将编写代码并尝试使用 GDB 查找错误
#include<stdio.h>
int main(){
int x ;
int a= x ;
int b = a ;
int c = a+b ;
printf("%d\n",c);
return 0 ;
}
输出:
23 如何在 Linux 上使用正则表达式(RegEx)
Regexp 是正则表达式 (Regular Expressions) 的缩写。正则表达式是特殊的字符或字符集,可以帮助我们搜索数据并匹配复杂的模式。Regexp 最常用于 Linux 命令:grep、sed、tr、vi。
以下是一些基本的正则表达式:
| No. | Symbol | Description |
|---|---|---|
| 1 | . | 它被称为通配符,它匹配除新行之外的任何一个字符 |
| 2 | ^ | 它匹配字符串的开头 |
| 3 | $ | 它匹配字符串的结尾 |
| 4 | * | 它最多匹配零次或多次出现,即字符串字符的任意次数 |
| 5 | \ | 它用于转义跟随字符。 |
| 6 | () | 它用于匹配或搜索一组正则表达式。 |
| 7 | ? | 它只匹配字符串或流中的一个字符。 |
以下是我们将要使用的文本文件的链接:
使用的文本文件:Fruits-name
1. 使用 “.”(点号)匹配字符串
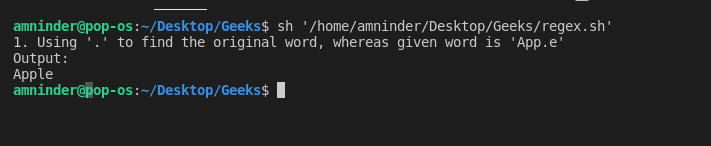
如果我们不知道确切的字符串可以使用 “.” 去搜索字符串,或者我们只记得字符串的头和尾,我们可以使用 “.” 作为一个缺失的字符,它会填充缺失的字符。让我们看一个例子来更好地理解:这个文件包含水果的名字,我们将在这个文件上使用正则表达式。
脚本:
#!/bin/bash
# Basic Regular Expression
# 1. Using “.” to match strings.
# loading the text file
fruits_file=`cat fruit.txt | grep App.e`
# here the original (answer) word will be Apple,
# but because we don’t know the spelling of the Apple,
# we will put a dot (.) in that place.
echo “1. Using ‘.’ to find the original word, whereas given word is ‘App.e'”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
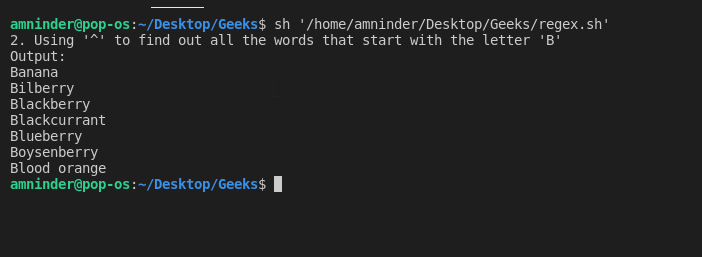
2. 使用 “^”(脱字符)匹配字符串的开头
使用 “^”,我们可以找到以给定字符开头的所有字符串。让我们看一个例子来更好地理解,在这里我们尝试查找所有以字母 B 开头的水果名字:
脚本:
#!/bin/sh
# Basic Regular Expression
# 2. Using “^” (caret) to match the beginning of the string
# loading the text file
fruits_file=`cat fruit.txt | grep ^B`
echo “2. Using ‘^’ to find out all the words that start with the letter ‘B'”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
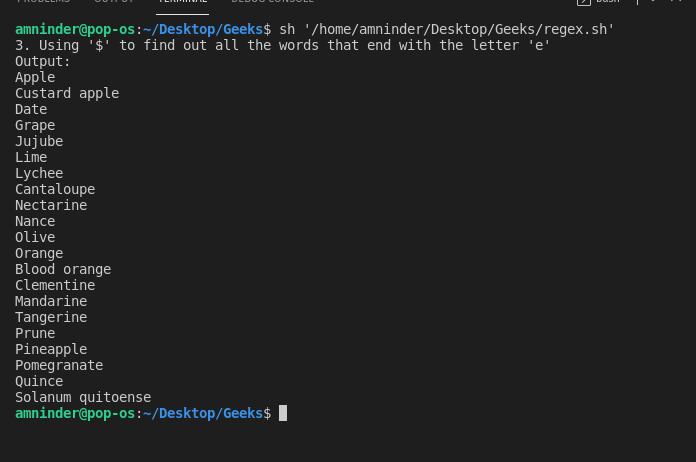
3. 使用 “$”(美元符号)匹配字符串的结尾
使用 “$” 我们可以找到所有以给定字符结尾的字符串。让我们看一个例子来更好地理解,在这里我们尝试查找所有以字母 e 结尾的水果名字:
脚本:
#!/bin/sh
# Basic Regular Expression
# 3. Using “$” (dollar) to match the ending of the string
# loading the text file
fruits_file=`cat fruit.txt | grep e$`
echo “3. Using ‘$’ to find out all the words that end with the letter ‘e'”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
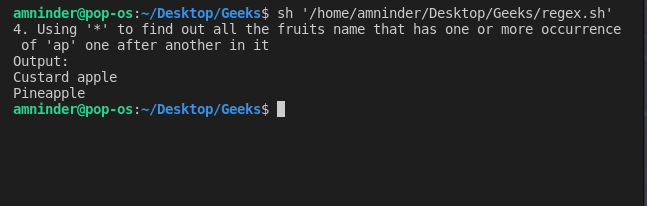
4. 使用 “*”(星号)查找字符串的任意重复次数
使用 “*”,我们可以匹配零个或多个字符串中的字符。让我们看一个例子来更好地理解,我们尝试寻找所有水果名字,其中一个或多个 ‘ap’ 相继出现。
脚本:
#!/bin/sh
# Basic Regular Expression
# 4. Using “*” to find any number of repetition of a string
# loading the text file
fruits_file=`cat fruit.txt | grep ap*le`
echo “4. Using ‘*’ to find out all the fruits name that has one or more occurrence of ‘ap’ one after another in it”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
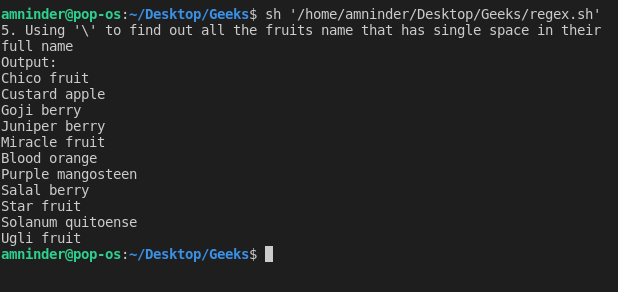
5. 使用 “\”(反斜线)匹配特殊符号
将 “\” 与空格(“\ ”)、换行符(“\n”)等特殊符号一起使用,我们可以从文件中找到字符串。让我们看一个例子来更好地理解,我们试图找到所有在全名中有空格的水果名称。
脚本:
#!/bin/sh
# Basic Regular Expression
# 5. Using “\” to match the special symbol
# loading the text file
fruits_file=`cat fruit.txt | grep “\ “`
echo “5. Using ‘\’ to find out all the fruits name that has single space in their full name”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
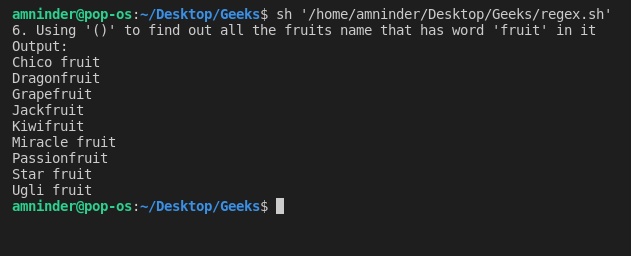
6. 使用 “()”(括弧)匹配正则表达式组
使用 “()”,我们能够找到与 “()” 中的模式匹配的字符串。让我们看一个例子来更好地理解,我们试图找出含有 fruit 单词的所有的水果名称。
脚本:
#!/bin/sh
# Basic Regular Expression
# 6. Using “()” (braces) to match the group of regexp.
# loading the text file
fruits_file=`cat fruit.txt | grep -E “(fruit)”`
echo “6. Using ‘()’ to find out all the fruits name that has word ‘fruit’ in it”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
7. 使用 “?”(问号)查找所有的匹配字符
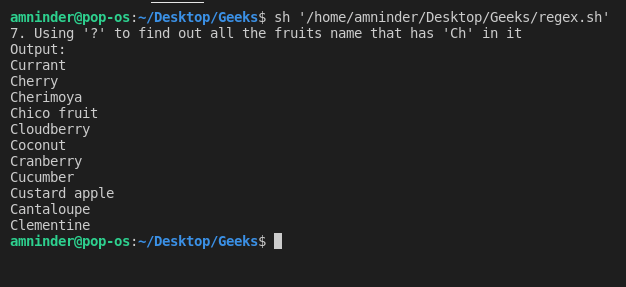
使用 “?”,我们能够匹配前面的 0 个或 1 个重复。举个例子,如果我们像这样子做:ab? 它将匹配 a 或 ab。让我们看一个例子来更好地理解,我们试图找出所有的含有 Ch 字符的水果名称。
脚本:
#!/bin/sh
# Basic Regular Expression
# 7. Using “?”(question mark) to match the
# loading the text file
fruits_file=`cat fruit.txt | grep -E Ch?`
echo “7. Using ‘?’ to find out all the fruits name that has ‘Ch’ in it”
# displaying output
echo “Output:”
echo “$fruits_file”
输出:
24 Shell 脚本注释
注释是开发人员为使读者理解源代码而提供的有用信息,它解释了代码中使用的逻辑或其中的一部分。当你不再回答有关代码的问题时,注释通常有助于某人维护或增强你的代码。这些通常被引用为一种有用的编程约定,它不参与程序的输出,但提高了整个程序的可读性。
有两种类型的注释:
- 单行注释
- 多行注释
24.1 单行注释
单行注释以不带空格(#)的标签符号开始,一直持续到行的末尾。如果注释超过了一行,那么在下一行加上一个标签,继续注释。
shell 脚本以 # 字符作为单行注释的前缀。
语法
#This is a comment
示例:
#Single line comment
echo "hello world"
输出:

24.2 多行注释
多行注释是在注释的每一端用分隔符(‘’)括起来的一段文本。同样,分隔符(‘’)之间不应有空格。当注释文本不适合一行时,它们很有用;因此需要跨越多行。多行注释或段落可作为其他人阅读代码的文档。请参阅以下演示多行注释的代码片段:
语法
: '
This is a
Multi-line comments'
示例:
echo "multiline comments"
: '
Print some word'
输出:

25 Shell 脚本示例与工程
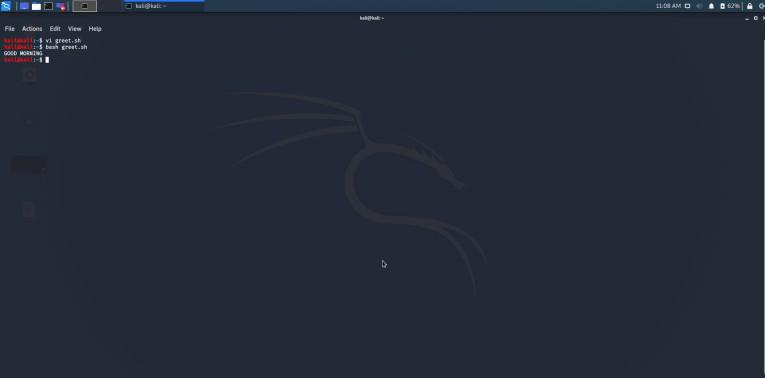
在本章节中,我们将看到如何使用 shell 编程根据系统时间打印 Good Morning、Good Afternoon、Good Evening 和 Good Night。
示例:
#!/bin/bash
hour=`date +%H`
if [ $hour -lt 12 ] # if hour is less than 12
then
echo "GOOD MORNING WORLD"
elif [ $hour -le 16 ] # if hour is less than equal to 16
then
echo "GOOD AFTERNOON WORLD"
elif [ $hour -le 20 ] # if hour is less than equal to 20
then
echo "GOOD EVENING WORLD"
else
echo "GOOD NIGHT WORLD"
fi
以上 shell 脚本基于在系统中执行获取得到的时间打印「Good morning」,「Good afternoon」,「Good evening」与「Good night」。程序拥有 .sh 的后缀。
变量「hour」存储 date +%H 的值,命令 date +%H 返回 24 小时格式的值。如果满足条件,命令 echo 将简单地打印语句。
输出:
示例 2:
#!/bin/bash
hour=$(date +%H)
if [ $hour -lt 12 ]
then
greet="Good Morning"
elif [ $hour -le 16 ]
then
greet="Good Afternoon"
elif [ $hour -lt 20 ]
then
greet="Good Evening"
else
greet="Good Night"
fi
echo "$greet"
在这个示例中,我们定义一个新的变量 greet 用于保存「Good Morning」,「Good Afternoon」,「Good Evening」与「Good Night」。根据系统的时间,它将向用户打印 Good Morning、Good Afternoon、Good Evening 或 Good Night。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









