




背景
很多场景需要考虑数据分布的相似度/距离:比如确定一个正态分布是否能够很好的描述一个群体的身高(正态分布生成的样本分布应当与实际的抽样分布接近),或者一个分类算法是否能够很好地区分样本的特征(在两个分类下的数据分布的差异应当比较大)。
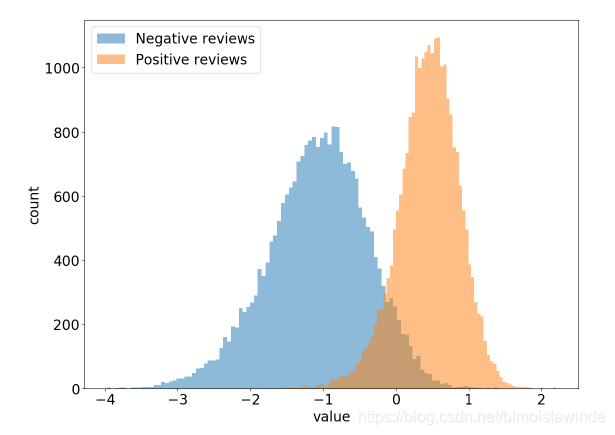
(例子:上图来自 OpenAI的 Radford A , Jozefowicz R , Sutskever I . Learning to Generate Reviews and Discovering Sentiment[J]. 2017. 他们发现他们训练的深度神经网络中有一个单独的神经元就对正负情感的区分度相当良好。)
上图可以直接看出明显的分布区别,但是能够衡量这种分布的距离更便于多种方法间的比较。KL/JS散度就是常用的衡量数据概率分布的数值指标,可以看成是数据分布的一种“距离”,关于它们的理论基础可以在网上找到很多参考,这里只简要给出公式和性质,还有代码实现:
KL散度
有时也称为相对熵,KL距离。对于两个概率分布P、Q,二者越相似,KL散度越小。
- KL散度满足非负性
- KL散度是不对称的,交换P、Q的位置将得到不同结果。
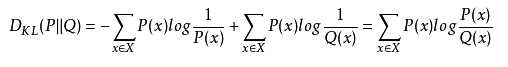
python3代码:
import numpy as np
import scipy.stats
p=np.asarray([0.65,0.25,0.07,0.03])
q=np.array([0.6,0.25,0.1,0.05])
def KL_divergence(p,q):
return scipy.stats.entropy(p, q, base=2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









