




缘起
在做一个dify的演示项目的时候,需要用到rag技术,解析上传的文档然后交给llm用于更好的回答用户的问题
至于什么是rag,怎样学习rag,这里推荐一个非常好的入门项目:
https://github.com/datawhalechina/all-in-rag
问题
在下图可以看到,我上传了一个1.5MB的文件到dify中,但是嵌入居然执行了2.84个小时,
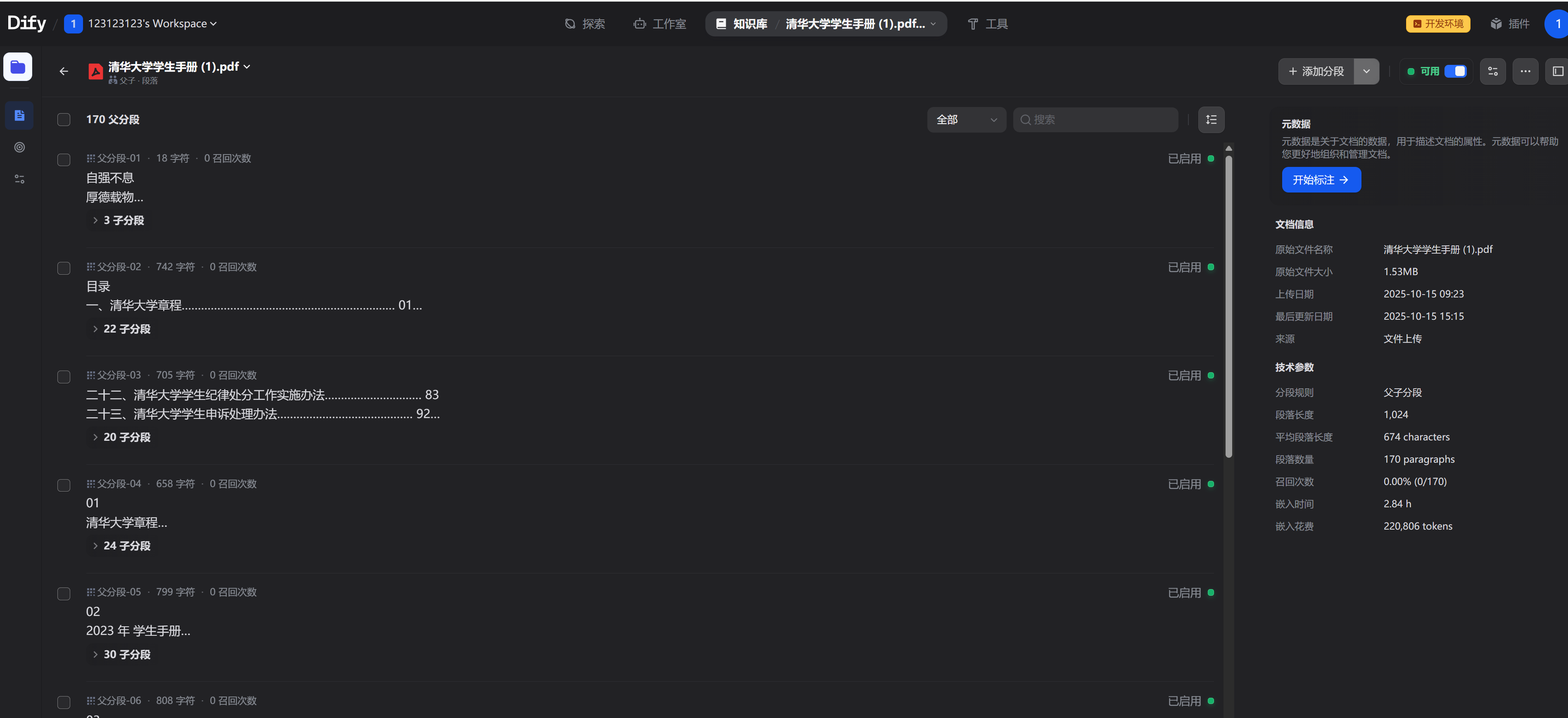
环境
我使用的本地ollama运行的bge-m3-q4_k_m
本地显卡是RTX 4050 笔记本版 显存6g(有点穷)
在执行嵌入的时候,cpu 5%以下, 显卡负载几乎为零.
推测大概率是软件配置上的问题…
尝试1
网络上给ollama增加ollama_num_parallel这个参数试一试,
增加完重启ollama看到已经识别了这个变量.
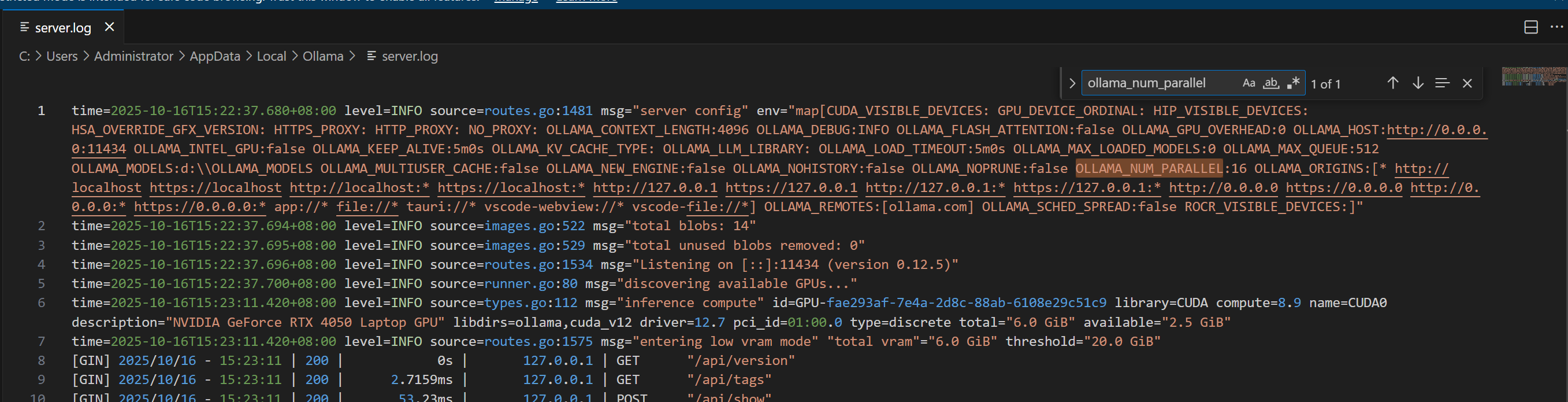
测试发现,嵌入速度基本没变化,cpu,gpu占用率都没上去,后面在探究原因
尝试2
有人说bge模型有点大2G网上,那么换个小点的几百兆的
我找到了一个小模型,名字叫Dmeta-embedding-zh
https://modelscope.cn/models/VBNn0x/Dmeta-embedding-zh-gguf/files
我使用了q5-km的量化版本,整个模型下载下来才50M
导入ollama试一下
性能应该是有提升的:
起码现在python的cpu占用率最高了,观察进度确实快了很多,但是cpu和gpu还是没有占用到满
可能是由于我ollama设置的进程数是16,所以可以适当缩小进程数看看性能是不是好一点.
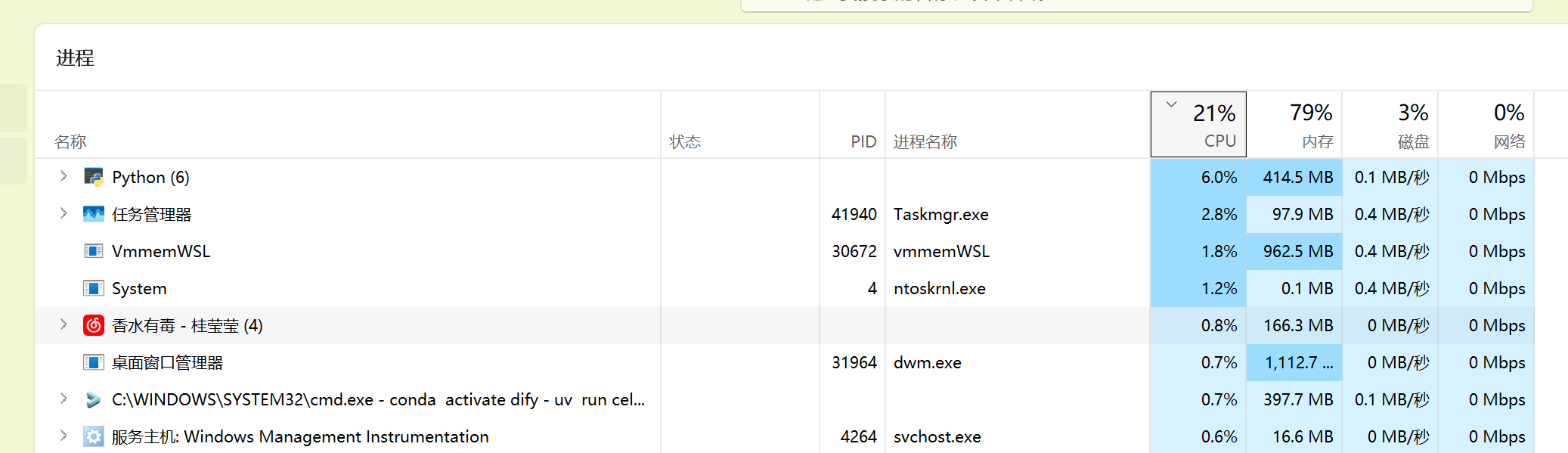
等这个文档索引完看看用了多长时间.
实测,时间并没变短.
测试
我使用http的方式调用了一下embeding
发现使用bge需要2s,换成ggml则只需要27ms.
那么感觉嵌入速度慢的问题可能卡在了调度上,不然怎么基本没变化.
网络上基本没有找到dify关于文本嵌入调度方面的资料,看来这部分要自己读代码了.
根据代码排查
上方两个方法都用了之后不见生效,只能通过阅读源码的方式进行排查,最终发下如下两个卡点.
卡点一
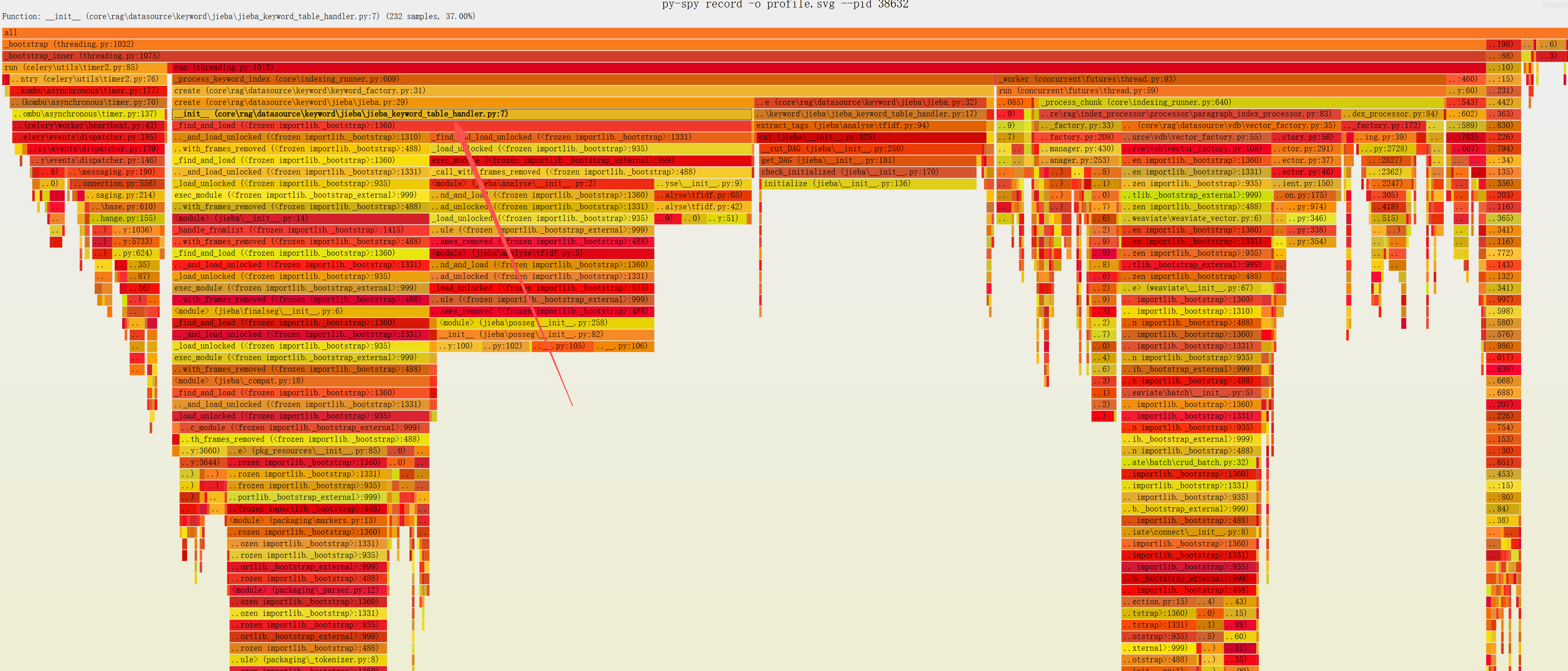
看到嵌入过程的一段处理逻辑,这段代码会不断地生成JiebaKeywordTableHandler对象,但是问题是生成这个对象是个正常重的操作.请看下段代码
def create(self, texts: list[Document], **kwargs) -> BaseKeyword:
lock_name = "keyword_indexing_lock_{}".format(self.dataset.id)
with redis_client.lock(lock_name, timeout=600):
keyword_table_handler = JiebaKeywordTableHandler()
keyword_table = self._get_dataset_keyword_table()
for text in texts:
keywords = keyword_table_handler.extract_keywords(
text.page_content, self._config.max_keywords_per_chunk
)
if text.metadata is not None:
self._update_segment_keywords(self.dataset.id, text.metadata["doc_id"], list(keywords))
keyword_table = self._add_text_to_keyword_table(
keyword_table or {}, text.metadata["doc_id"], list(keywords)
)
self._save_dataset_keyword_table(keyword_table)
return self
在做嵌入的时候,需要用到jieba分词,但是这个对象会调用很多次,每次调用都需要在初始化函数里面使用import jieba.analyse
然而,这个初始化操作是非常重的操作,jieba的加载会初始化词典.并且这个过程还是一个全局锁进行,导致大量的进程都在等待锁
import re
from typing import Optional, cast
class JiebaKeywordTableHandler:
def __init__(self):
import jieba.analyse # type: ignore
from core.rag.datasource.keyword.jieba.stopwords import STOPWORDS
jieba.analyse.default_tfidf.stop_words = STOPWORDS # type: ignore
def extract_keywords(self, text: str, max_keywords_per_chunk: Optional[int] = 10) -> set[str]:
"""Extract keywords with JIEBA tfidf."""
import jieba.analyse # type: ignore
keywords = jieba.analyse.extract_tags(
sentence=text,
topK=max_keywords_per_chunk,
)
# jieba.analyse.extract_tags returns list[Any] when withFlag is False by default.
keywords = cast(list[str], keywords)
return set(self._expand_tokens_with_subtokens(set(keywords)))
def _expand_tokens_with_subtokens(self, tokens: set[str]) -> set[str]:
"""Get subtokens from a list of tokens., filtering for stopwords."""
from core.rag.datasource.keyword.jieba.stopwords import STOPWORDS
results = set()
for token in tokens:
results.add(token)
sub_tokens = re.findall(r"\w+", token)
if len(sub_tokens) > 1:
results.update({w for w in sub_tokens if w not in list(STOPWORDS)})
return results
从火焰图中可以看到,这个init函数占据了36%的时间,他调用的find_and_load是个带锁的函数,大量的时间都白白的浪费在了这里.因为
为什么要把import放在init里面呢?
原始代码将 import jieba.analyse 放在 init 方法内部,作者可能出于以下几种考虑:
-
延迟加载(Lazy Loading) :
- 开发者可能希望只在实际需要使用jieba库时才加载它,而不是在模块导入时就加载
- 这可以减少模块初始加载时间,特别是当这个类可能不总是被使用的情况下
-
避免不必要的依赖 :
- 如果jieba是一个可选依赖,或者只在特定场景下需要使用
- 放在方法内部可以避免在不需要使用该功能时加载不必要的依赖
-
解决循环导入问题 :
- 在某些复杂的项目结构中,将导入放在方法内部可以避免潜在的循环导入问题
-
动态配置需求 :
- 可能开发者认为在实例化时才加载可以根据不同的实例配置不同的jieba设置
-
避免全局状态污染 :
- 希望每个实例都有自己独立的jieba环境,避免全局修改影响其他模块
卡点二
再看火焰图右半边,这里面同样有一个模块加载引起的性能损失,占9%的执行时间
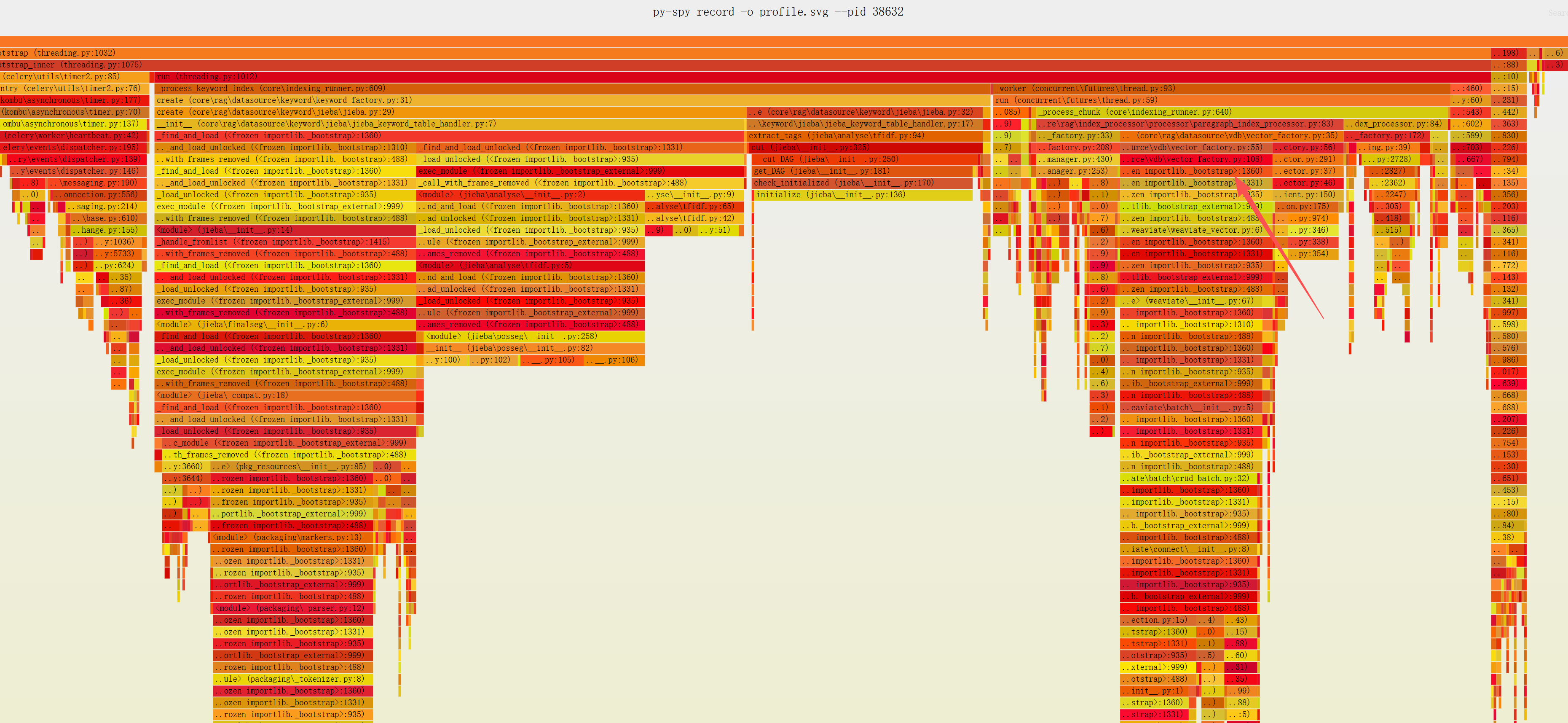
再看代码:同样是import引入的祸.两个执行,两个卡点总共占用了45%时间,都是在import工具,等锁
结论
在ollama中更换了较小的嵌入模型依旧很慢的原因是dify在处理文件的时候多次重复的加载jieba分词的框架,导致所有线程都进行了阻塞.但是具体如何解决本人还没有考虑好,有处理方法欢迎大家在评论区补充


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









