



 本文深入探讨Redis集群和复制机制,包括配置原理、哨兵监控、集群特性与故障恢复等关键概念,为高可用和高性能的Redis部署提供指导。
本文深入探讨Redis集群和复制机制,包括配置原理、哨兵监控、集群特性与故障恢复等关键概念,为高可用和高性能的Redis部署提供指导。
假·集群
一个小型项目可以只使用一台redis,然而现实中的项目通常需要若干台redis服务的支持:
- 结构上讲,单个redis服务器会发生单点故障,同时一台服务器需要承受所有的请求负载,此时就需要为数据生成多个副本并分配在不同的服务器上
- 容量上讲,单个redis服务器的内存非常容易成为存储瓶颈,此时需要数据的分片
通过复制可以实现读写分离,当大量读请求(尤其是耗资源的请求,如SORT命令)单机redis无法应付,而写操作较少时,很适合该方式,而当单台主数据库无法满足,就需要3.0退出的集群功能
复制
为避免单点故障造成数据丢失,通常做法是讲数据库复制多个副本以部署在不同的服务器上,即使有一台服务器出现故障,其他服务器依然可以继续提供服务
为此redis提供了复制(replication)功能,可以实现当一台服务器的数据更新之后,自动将更新的数据同步到其他数据库上
配置
复制的概念中,数据库分为两类: 主数据库(master) 、 从数据库(slave)
主数据库可以进行读写操作,写操作导致数据库变化时自动同步给从数据库,
从数据库一般是只读,并接收主数据库同步的数据,
主从的关系为一(主)对 多(从)
配置主从数据库时,主数据库无需任何配置,从数据库在配置文件中加上:
slaveof 主数据库地址 主数据库端口
使用下面的命令可以获取redis实例的Replication节相关信息:
redis> INFO replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port:6380,state=online,offset=1,lag=1
master_repl_offset:1
redis> INFO replication
role:slave
master_host:127.0.0.1
master_port:6379
如果redis在运行中,使用如下命令:
如果该数据库已经是其他主数据库的从数据库了,该命令会停止和原来数据库的同步转而和新数据库同步
redis> SLAVEOF 127.0.0.1 6379
从数据库转换为主数据库:
停止接收其他数据库的同步并转换为主数据库
redis> SLAVEOF NO ONE
原理
复制初始化:
当一个 slave 启动后,会向 master 发送 SYNC 命令, master 接收到命令后会开始在后台保存快照(即RDB持久化过程),并将保存快照期间的命令缓存起来,快照完成后,redis会将快照文件和所有缓存命令发送给 slave , slave 接收后会载入快照文件并执行缓存的命令
复制同步:
复制初始化之后, master 每当收到写命令时就会将命令同步给 slave ,如果 slave 断线重连, master 会将断线期间执行的命令传给 slave
该操作会贯穿整个主从同步过程的始终,直到主从关系结束为止
默认情况下,slave是只读的,直接修改会报错
可以修改配置 slave-read-only 为 no,之后可以修改slave,但不会同步到 master
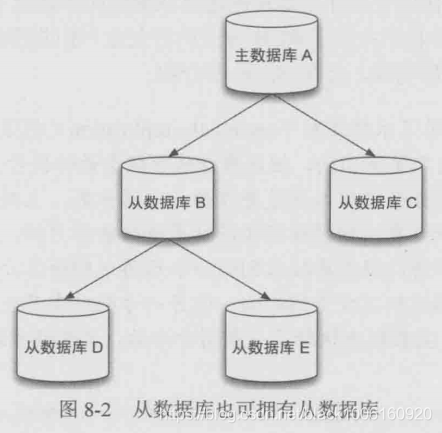
图结构
从数据库不仅可以接收主数据库的同步数据,同时自己也可以作为主数据库的存在
无硬盘复制
开启该选项时,redis在与slave进行复制初始化时将不会将快照内容存储到硬盘上,而是直接通过网络发送给slave,避免了硬盘的性能瓶颈
添加配置项:
repl-diskless-sync yes
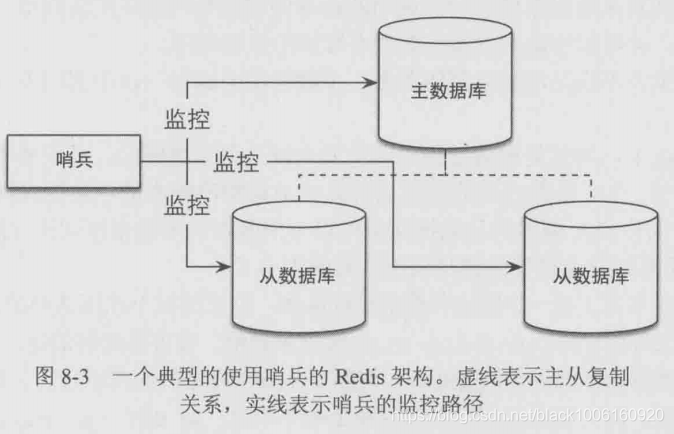
哨兵
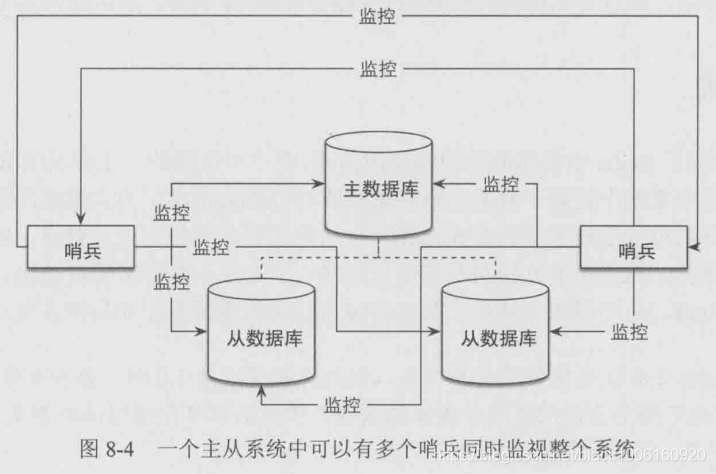
作用:监控redis系统运行情况,哨兵是一个独立的进程,一个主从redis系统中可以使用多个哨兵,哨兵之间也会相互监控
功能:
- 监控 master 和 slave 是否正常运行
- master 出现故障时自动将 slave 转换为 master
配置
配置哨兵只需要分两步:
- 建立一个配置文件,如sentinel.conf ,内容为:
sentinel monitor mymaster 127.0.0.1 6379 1
mymaster: 要监控的master名字, 后面跟着master的ip 端口,最后面的1是quorum,指执行故障恢复前至少需要几个哨兵节点同意 - 启动进程,命令:
redis-sentinel /path/sentinel.conf
只需要配置master,哨兵会自动检测到slave并监控 ;
一个哨兵节点可以监控多个redis主从系统,只需配置多个sentinel monitor ;
部署时注意:
- 尽量为每个节点(无论master和slave)部署一个哨兵
- 设置quorum值为 N/2+1 ,N为哨兵数量
- 如果redis节点负载较高,每个节点一个哨兵可能有太多连接,影响哨兵及服务,需根据实际生产环境选择
原理
启动后,哨兵会和master建立两个连接,一个进入订阅模式,订阅 _sentinel_: hello 频道获取,一个发送命令; 哨兵与哨兵之间只有一个发送命令的连接
和master的连接建立完成后,哨兵会定时执行下面三个操作
- 每10秒向master和salve发送 INFO 命令
- 每2秒向master和salve的 _sentinel_: hello 频道发送自己的信息
- 每1秒向master、salve和其他哨兵节点发送 PING 命令
如果ping的库或节点未收到回复,哨兵认为其主观下线,随后询问其他哨兵,达到指定数量后,哨兵认为其客观下线,接下来使用Raft算法选举领头哨兵进行故障恢复
真·集群
旧版redis通常使用客户端分片进行水平扩容,由客户端决定每个键交由哪个节点存储,redis3.0的一大特性就是支持集群功能,集群支持几乎所有单机示例支持的命令,但对于多键命令(如MGET)如果所有键都位于同一节点则正常支持,否则报错,而且还有一个限制是只能使用默认的0号数据库(默认情况下,有0到15号,共16个数据库,可通过 SELECT num 命令切换)
配置
每个集群中至少需要3个主数据库才能正常运行
- 首先,需要将每个节点的 cluster-enabled 配置选项打开
配置文件中:
cluster-enabled yes
集群会将当前节点记录的集群状态持久化到指定文件,默认当前工作目录下的nodes.conf文件,每个节点对应的必须不同,否则启动失败,so→可为每个节点使用不同的目录,或修改配置 cluster-config-file nodes.conf ,修改持久化文件名称
启动节点后:
会输出内容"i’am abc123…" , 后面abc…表示该节点运行id,该id为集群中唯一标识,同一个运行id,可能地址和端口是不同的
查看:
1表示集群正常启动,但每个节点目前完全独立,后面需要将他们加入同一集群
redis> INFO cluster
# Cluster
cluster_enabled:1
- redis源码src文件提供辅助工具redis-trib.rb,该工具由Ruby编写,所以先安装Ruby程序
该工具依赖于gem包redis,执行 gem install redis 安装 - 使用 redis-trib.rb 初始化集群:
/path/to/redis-trib.rb create --replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385
其中create表示要初始化集群, --replicas 1 表示每个master拥有得slave个数为1 , 整个集群共有 3 master 和 3 slave
执行完后: 会输出集群具体分配方案,没问题输入yes开始创建
创建过程
- 以客户端形式尝试连接所有节点,并发送ping命令以确定节点能够正常服务,任何节点异常,创建失败
- 发送 INFO 命令获取各节点运行id及是否开启集群功能
- 向每个节点发送 CLUSTER MEET ip port 命令,告诉当前节点指定ip,port上运行的节点也是集群的一部分
- redis-trib.rb 分配master和slave节点,分配原则:尽量保证每个master在不同ip地址,同时每个master和slave均不运行在同一ip
- 为每个master分配插槽
- 对每个slave节点发送 CLUSTER REPLICATE master运行id ,将当前节点转换为slave并复制指定运行id的节点(即master)
可通过 CLUSTER NODES 命令获取集群中所有节点信息
节点的增加
创建过程-3 已介绍 redis-trib.rb 是使用 CLUSTER MEET 命令使每个节点相互认识,所以加入新节点也只需要此命令:
CLUSTER MEET ip port
ip/port 是集群中任一节点的地址和端口号
新节点A接收到命令后与给定节点B握手,使B认为A是集群一员,握手成功后,B使用Gossip协议将A的信息通知给集群所有其他节点,完成节点的新增
新节点加入后,有两个选择:
- 使用 CLUSTER REPLICATE 命令复制master,以slave形式运行
- 向集群申请分配插槽以master的形式运行
键与插槽的对应关系
redis将每个键的键名的有效部分使用CRC16算法计算出散列值,然后取对16384的余数,使得每个键都可以分配到16384个插槽中
键名的有效部分是指:
- 如果键名包含 { 符号,且在 { 符号后面存在 } 符号, 并且 { 和 } 之间有至少一个字符,则有效部分是指 { 和 } 之间的内容
- 如果不满足上一规则,那么整个键名为有小部分
例如: {user}:first.name 和 {user}:last.name 会被分配到同一插槽进而到同一节点,此时可以支持多键操作
插槽(slot)的分配
在一个集群中,所有的键会被分配给16384个插槽,每个主数据库会负责处理其中的一部分插槽
查看插槽分配情况:
redis 6380> CLUSTER SLOTS
1) 1) (integer) 5461 <--插槽的开始号码-->
2) (integer) 10922 <--插槽的结束号码-->
3) 1) "127.0.0.1" <--负责该插槽的节点,包含master和slave-->
2) (integer) 6381 <--master始终在第一个-->
4) 1) "127.0.0.1" <--slave-->
2) (integer) 6384
2)...
分配分为两种情况:
- 插槽之前没有被分配过,现在分配给指定节点
- 插槽之前被分配过,现在移动到指定节点
情况1:
在指定节点执行命令:
CLUSTER ADDSLOTS slot1 [slot2]…[slotN]
例如添加 100 101 两个插槽:
CLUSTER ADDSLOTS 100 101
如果指定插槽已经分配,则提示:
(error) ERR Slot 100 is already busy
情况2:
使用 redis-trib.rb 工具的方式:
- 执行命令 /path/to/redis-trib.rb reshard 127.0.0.1:6380
reshard指需要重新切片, 127.0.0.1:6380为任一节点的地址,redis-trib.rb 自动获取集群信息 - redis-trib.rb 询问想要迁移多少个插槽:
How many slots do you want to move (from 1 to 16384)?
如果只需要迁移一个,就输入1后回车 - redis-trib.rb 询问要把插槽迁移到哪个节点:
What is the receiving node ID?
可以通过 CLUSTER NODES 命令获取目的redis实例的运行id,输入并回车 - 询问从哪个节点移出插槽
输入源redis实例的运行id,回车 - 输入yes确认重新分片方案
手动迁移:(不推荐)
执行命令:
CLUSTER SETSLOT 插槽号 NODE 新节点的运行id
此时已分配完成,然而前提是: 插槽中并没有任何键,
因为该命令迁移插槽不会连同相应的键一起迁移,会导致客户端无法在指定节点找到未迁移的键,为此需要手工迁移插槽中的键:
- 获取某插槽中存在哪些键,执行命令:
CLUSTER GETKEYSINSLOT 插槽号 要返回的键的数量 - 将每个键执行命令迁移到指定节点:
MIGRATE 目标节点地址 目标节点端口 键名 数据库号码(始终为0) 超时时间 [COPY] [REPLACE]
COPY表示不删除当前数据库,而是复制过去,REPLACE表示如果目标节点存在相同键名,则覆盖
手动迁移问题: 如果迁移数据量较大,需要较长时间→迁移未完成时执行CLUSTER SETSLOT,客户端请求新节点,有可能读不到值; 迁移完成后执行,客户端请求旧节点,但有些值已迁移,同样有可能读不到值
redis提供两个命令实现集群不下线迁移数据:
CLUSTER SETSLOT 插槽号 MIGRATING 新节点运行id
CLUSTER SETSLOT 插槽号 IMPORTING 原节点运行id
redis-trib.rb 工具解决方案:
将0号插槽从A迁移到B:
- 在B执行 CLUSTER SETSLOT 0 IMPORTING A
- 在A执行 CLUSTER SETSLOT 0 MIGRATING B
- 执行 CLUSTER GETKEYSINSLOT 0 获取0号插槽键列表
- 对3中每个键执行 MIGRATE 命令从A迁移到B
- 执行 CLUSTER SETSLOT 0 NODE B 完成迁移
故障恢复
集群中每个节点每隔1秒随机选择5个节点,选择最久没响应的节点发送PING命令,一定时间内没有响应回复,认为该节点疑似下线
- 节点A认为B疑似下线,会在集群中传播该消息,其他节点收到并记录
- 某一节点C收到半数以上节点认为B疑似下线,会将B标记为下线,并在集群中传播该消息
当一个master下线时,导致部分插槽无法写入,如果该master拥有至少一个slave,选举一个slave为master(具体方法同哨兵),如果该master没有slave,整个集群默认进入下线状态无法工作,如果向在这种状态下继续正常工作,修改配置为no(默认yes):
cluster-require-full-coverage no

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









