




目录

一、引言
书接上文,主从复制结合哨兵,实现了自动故障转移。但是还存在一定的缺陷,就是只有一个主节点可写,无法满足高并发读写场景。集群模式在主从复制和哨兵模式的基础上,进一步拓展,有多个节点可读可写,一定程度上可以说解决了无法很好支持高并发读写的问题。
二、哈希算法的选择
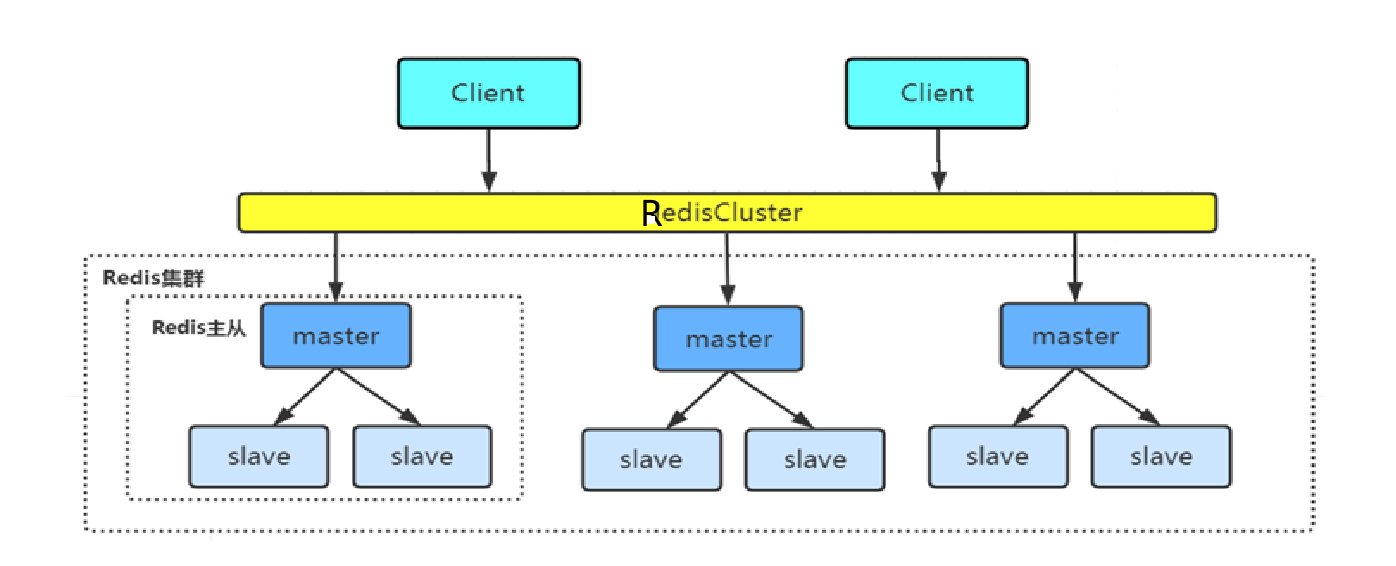
上图是Redis集群的结构图。其中有3个master,每一个master节点都可读可写。而且,每一个master节点只存储一部分数据,而不是全量数据。所有master中的数据合起来,才是全量数据。可以看到,每一个master下面还有两个从节点,理由也很简单,对master中的数据进行一个备份,还有就是master故障时,可以接替master的工作。
给定一个数据key,那么这个数据应该存在哪一个主节点上,也可以说是存储在哪一个数据分片上。关于这个问题,下面有三种解决方法。
2.1 哈希求余
假设有N个主节点,编号从0开始,此时需要插入一个数据key。
如果采用哈希求余算法,那么将是:hash(key) % N。结果为几就存储在几号主节点上。
这种算法实现起来确实比较简单,但是它有一个很致命的缺点:扩容的时候需要移动大量数据。

假设上图中的数字均为hash(key)的结果,可以看到,当从3个主节点扩容到4个时,绝大部分数据都是要移动的,这不是此处数据量比较小才看到的偶然结果,实际上数据量大的时候也需要大量移动数据。
2.2 一致性哈希算法
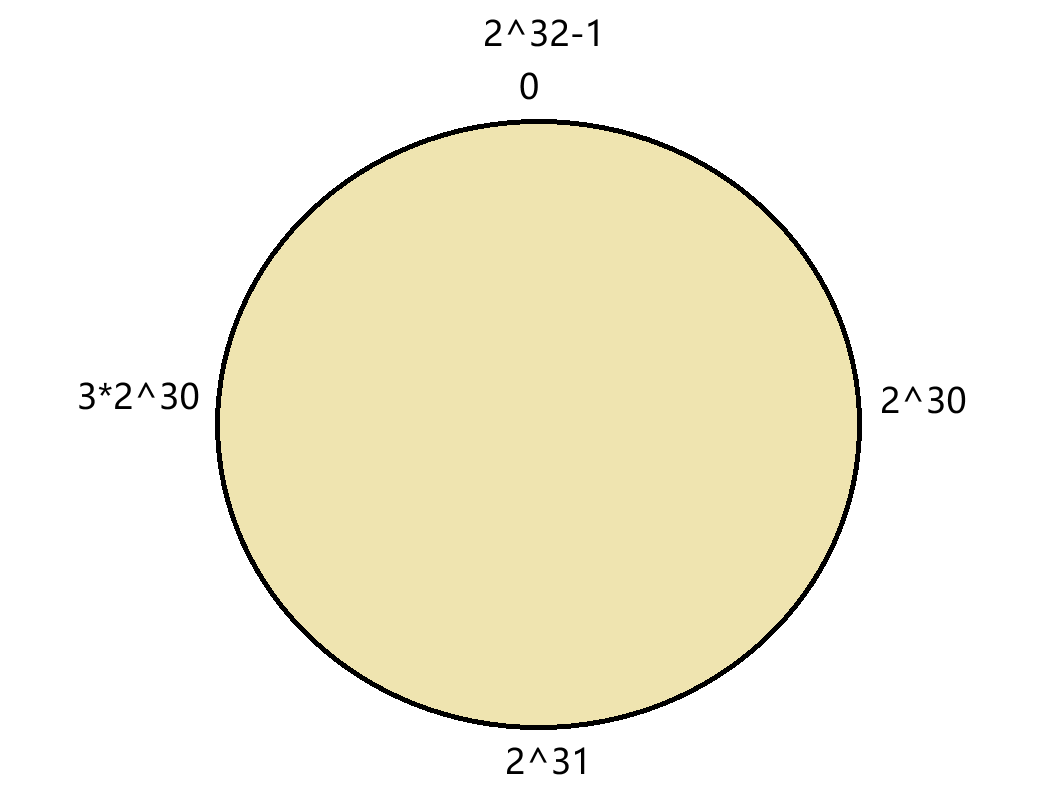
首先,将0~2^32-1的数据映射到一个圆环上,数据按顺时针方向增长。
假设现在有三个主节点,然后将这三个主节点对应到圆环中的任意位置上,如下图。
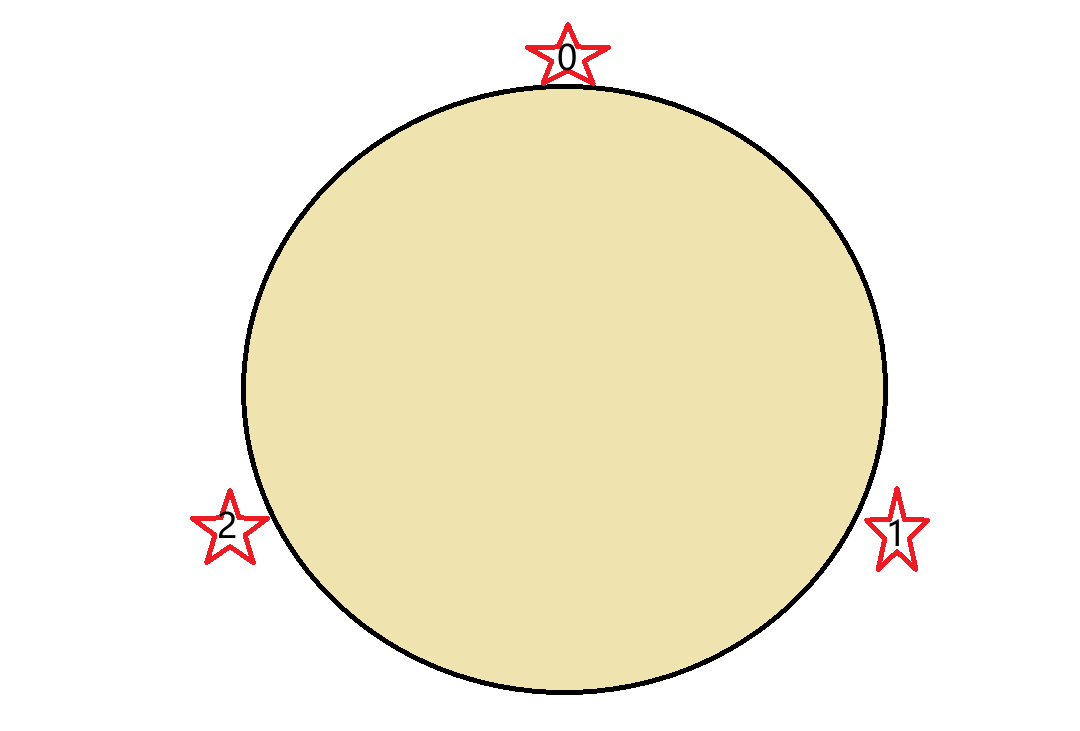
这时候来了一个key,经过计算,它的哈希值落在0号节点和1号节点之间,然后从该位置顺时针往下找,找到的第一个节点就是这个key存放的位置。
这就是一致哈希算法决定一个key该存到哪个节点的过程,下面我们看看如何扩容。
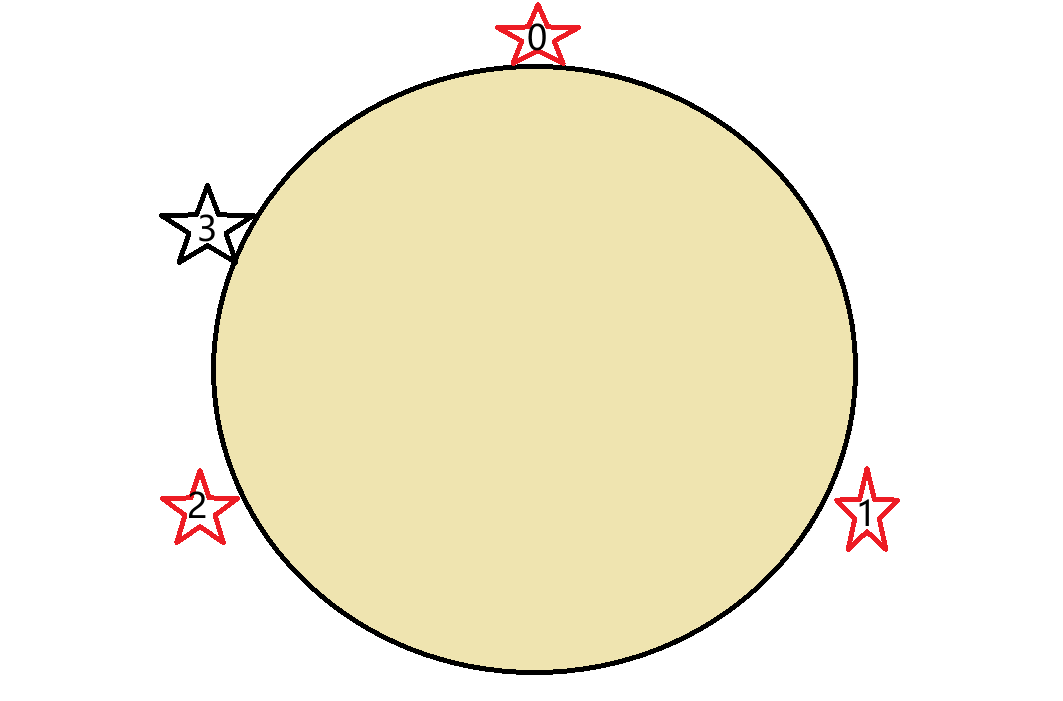
现在多了一个3号节点,那么只需要把0号节点中的部分数据转移到3号节点上即可,相对哈希求余来说,数据的转移少了好多。相对于哈希求余算法来说,如果计算出来的哈希值为101、102、103的话,这几个哈希值对应的数据是保存到不同的节点上的,而一致哈希算法则是保存到同一个节点上,不然它怎么叫一致哈希?
虽然说不用再移动大量数据了,但是也引入了一个新的问题——数据倾斜。
也就是说,不同的节点上的数据量存在较大的差异。结合上图,新增的3号节点和0号节点的数据量就比较少。这就是数据倾斜,为什么Redis如此害怕数据倾斜呢?
数据倾斜会引发性能瓶颈,而且也会让Redis集群失去水平扩展优势。
假设主节点A存储了80%的数据,主节点A就理所当然的承担了80%的写请求,其对应的从节点自然也承担了80%的读请求。这就导致这些节点的CPU、内存、网络带宽被沾满,而其他节点处于空闲状态。此时即使在增加更多节点,整体的吞吐量也无法再提升,卡在了主节点A这里,这就很像木桶理论。
2.3 哈希槽分区算法(Redis采用)
哈希槽分区算法是为了解决数据搬运成本高和数据分配不均匀而引入的。所谓的哈希槽,本质是就是第一个编号,每个哈希槽都有自己所属的主节点。
Redis 集群预设了 16384 个哈希槽,这些哈希槽都较为平均的分配给每一个主节点。当插入一个key时,首先通过下面公式计算这个key映射到哪一个槽上。
哈希槽编号 = CRC16(key) % 16384 (CRC16是一种哈希函数)
然后将key存储到计算得到的槽编号所属的主节点。
假设有三个这节点,那么可能的一种槽编号分配方式为:
0号主节点:[0,5461],共5462个槽位。
1号主节点:[5462, 10923],共5462个槽位。
2号主节点:[10924, 16383],共5460个槽位。
此时插入一个“hello",假设经过CRC16(hello)计算得到的草编号为2025,那么将这个字符串存到0号主节点。
上面就是数据插入的一个基本过程,下面讨论几处细节。
每个主节点如何知道自己所拥有哪些哈希槽?
位图,对应位置1即表示占有这个哈希槽编号。
另一个问题是,为什么是16384个哈希槽?
首先需要明确,每一个主从节点都要记录自己拥有的槽编号,所以每个主节点就都需要一张位图,16384(分配到的哈希槽不一定连续)个槽正好2KB足以表示。补充一点,每个节点都要保存“槽-主节点”的映射表,16384个槽占用的空间不大,所以交换的成本就小一些。而且,这么多的槽足以支持1000个主节点,满足绝大部分的需求。
最后,当扩容时,比如新增一个3号主节点,那么就从0到2号节点中各拿出一部分哈希槽,分配给3号主节点,然后移动一部分数据到3号主节点上。
三、核心工作原理
Redis的故障检测和自动处理依赖的是节点间的心跳机制和投票选举机制,和哨兵模式的有类似,但集群模式下无需哨兵。
3.1 故障检测
心跳检测就是集群中的每个节点,定期随机向几个节点发送心跳包,如果在约定时间之内收到相应的话,那么就认为该节点正常。否则,单方面认为这个节点出现故障了,即疑似下线(主观下线)。
假设节点A判断节点B疑似下线,那么节点A将向其他节点发起询问,但是只有主节点有投票资格。如果超过半数的主节点认为B下线的话,那么节点A就认为节点B是真的下线了,即判断节点B确认下线。接着,节点B广播告知其他所有节点,节点B确认下线。
假设被确认下线的这个节点B是主节点,那么将触发故障转移。
3.2 自动故障转移
主节点B下线之后,就要从它的从节点里面选出一个来接替它的工作。大致就是让健康的、数据同步更多的节点来向所有主节点申请投票,就是告诉所有主节点说“投我一票”。如果超过半数的主节点赞同,那么这个从节点就晋升为新的主节点。然后这个新的主节点执行slaveof no one,将自己的身份切换为主节点,然后剩余的从节点执行 slaveof <新主节点IP><新主节点端口>,认新主节点为自己的新主人。最后,新的主节点向所有节点广播,告诉它们“我接管了原主节点”,这些节点就会更新自己缓存的“槽-主节点”的映射表。
当原主节点恢复后,认新的主节点为主。
自动故障转移可以总结为:故障检测→从节点竞选→新主节点接管→旧主节点恢复。
四、优缺点
4.1 优点
-
水平扩展能力强:通过增加主节点即可扩展存储容量和写吞吐量(每个主节点独立处理部分槽的写请求)。
-
高可用自愈:自动完成故障检测与故障转移,无需人工干预,服务可用性达 99.99% 以上。
-
读扩展灵活:从节点可分担读请求,适合 “读多写少” 场景(如商品详情页、用户画像查询)。
-
官方原生支持:无需依赖第三方组件,配置和维护成本低,兼容性好。
4.2 缺点
-
不支持跨槽操作:批量命令(如
MSET key1 key2)、事务(MULTI/EXEC)、Lua 脚本若涉及多个哈希槽,会直接报错。 -
数据一致性有限:主从复制默认异步,若主节点宕机时未同步完增量数据,会导致少量数据丢失。
-
运维复杂度高于单节点:需管理多个节点,监控集群状态(如槽分配、主从同步进度),扩容 / 缩容需谨慎操作(避免槽迁移失败)。
-
资源开销较高:相比单节点或主从模式,占用更多服务器资源。
五、结语
路虽远,行则将至。
完~

















 2076
2076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









