




目录

一、引言
Redis 主从模式(Master-Slave Replication)是 Redis 最基础、最核心的高可用方案之一,其核心思想是通过数据复制将主节点(Master)的数据同步到一个或多个从节点(Slave),从而实现读写分离、数据备份和故障冗余,有效提升 Redis 服务的并发能力和可用性。
我们先从实际操作入手,带大家了解主从模式下的数据同步过程,随后再详细介绍主从模式的核心作用,以及数据同步背后的实现原理。
二、操作
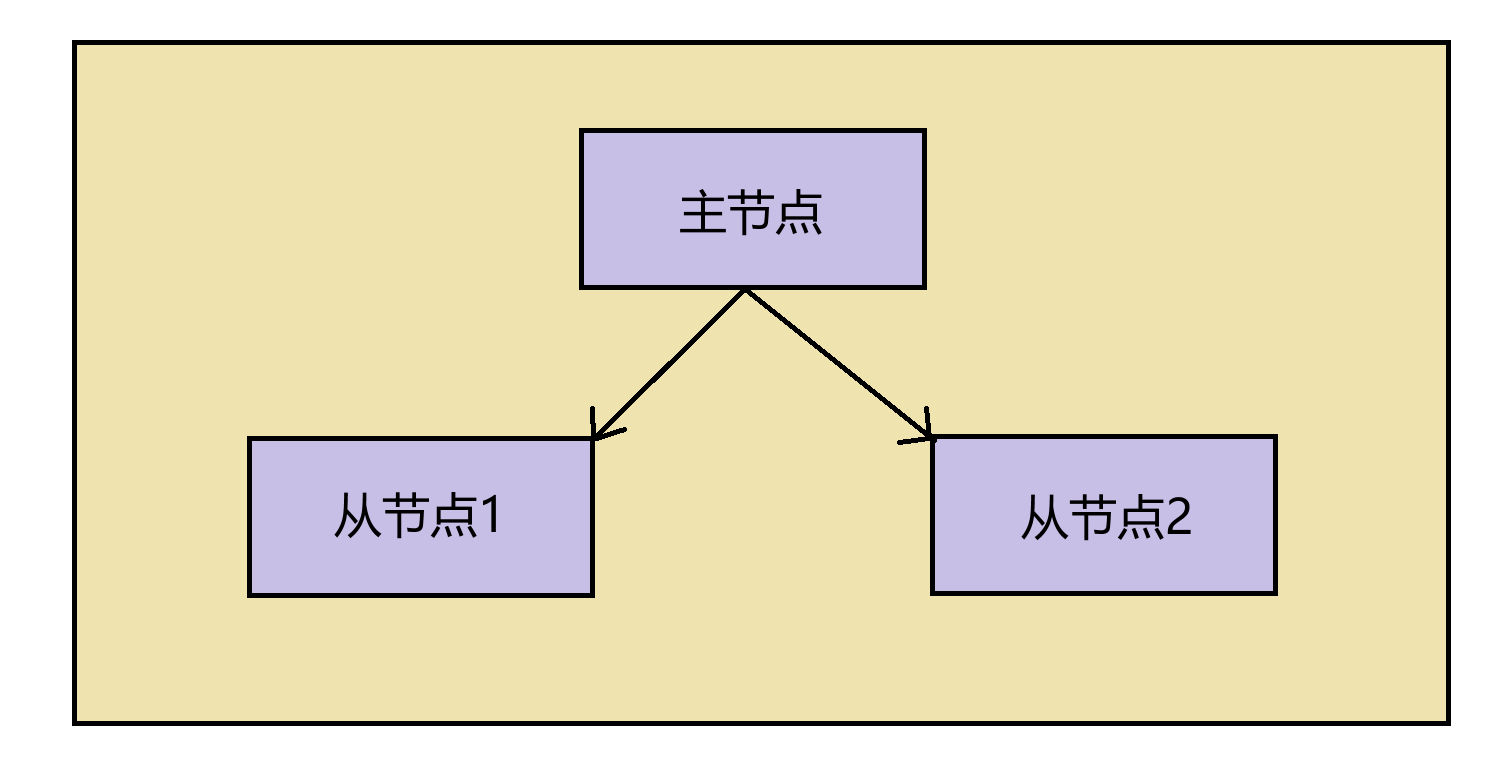
我们首先明确目标:下面演示的是如何搭建 “一主两从” 架构。
2.1 搭建主从架构
1)切换到Redis配置文件所在目录,拷贝两份配置文件到自己创建的目录。

此处是事先在/root目录下创建了redis-conf目录。
2)在redis-conf目录创建两个目录,slave1和slave2。
3)用vim打开配置文件slave1.conf。
a.检查允许绑定的端口号是否如下图,不是则修改。
b.修改允许端口号为6380。

c.修改工作目录为/root/redis-conf/slave1。

d.在该文件中加上主节点的信息。
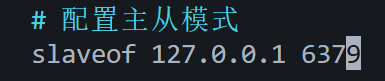
4)按上述步骤修改配置文件slave2.conf。
端口号改为6381,工作目录为/root/redis-conf/salve2,主从模式配置一样。
2.2 主从节点间的数据同步
5)启动两个从节点服务器。

6)通过客户端登录主节点服务器。
命令:redis-cli
7)通过客户端登录从节点服务器。
命令:redis-cli -p 6380、redis-cli -p 6381。
![]()
![]()
8)在主节点创建一个key,从节点可以也可以拿到一份。
![]()
![]()
9)站在主节点看主从架构
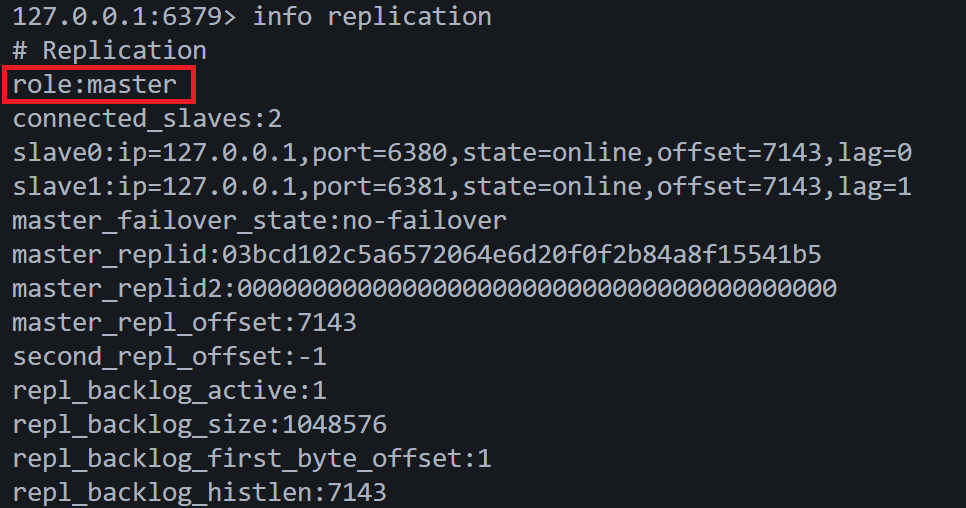
10)站在从节点看主从架构
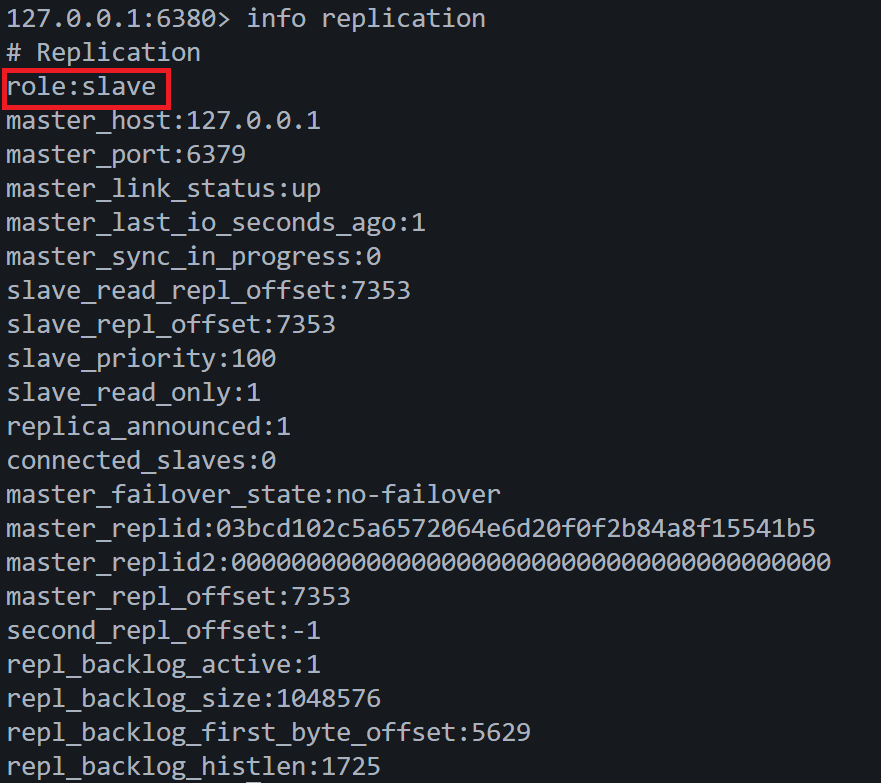
主节点和从节点之间,采用TCP长连接来进行数据的同步。
三、主从模式的核心作用
如果只有一台物理上的Redis服务器,那么单点故障就是不得不面对的一个问题。所谓的单点故障,意思就是只有一台服务器,如果这台服务器挂了,那么整个系统将不能对外提供服务。如果涉及到硬件损坏,比如硬盘坏了,那么将会导致存储在上面的数据永久丢失。
诸如此类的问题,高可用系统必须直面。
主从模式就是引入了多台服务器(上面的演示由于设备有限,所以在同一台电脑上演示),这些服务器都保存有完全一样的全量数据,相当于有几分全量数据的备份。哪怕其中一台服务器出现了故障,其他服务器也还能对外提供服务,而且也不容易造成数据永久丢失。这就提高了系统的高可用性。除此之外,引入更多的服务器,可以通过负载均衡机制缓解单台服务器的压力,提高系统能承受的并发量。
四、主从模式的架构
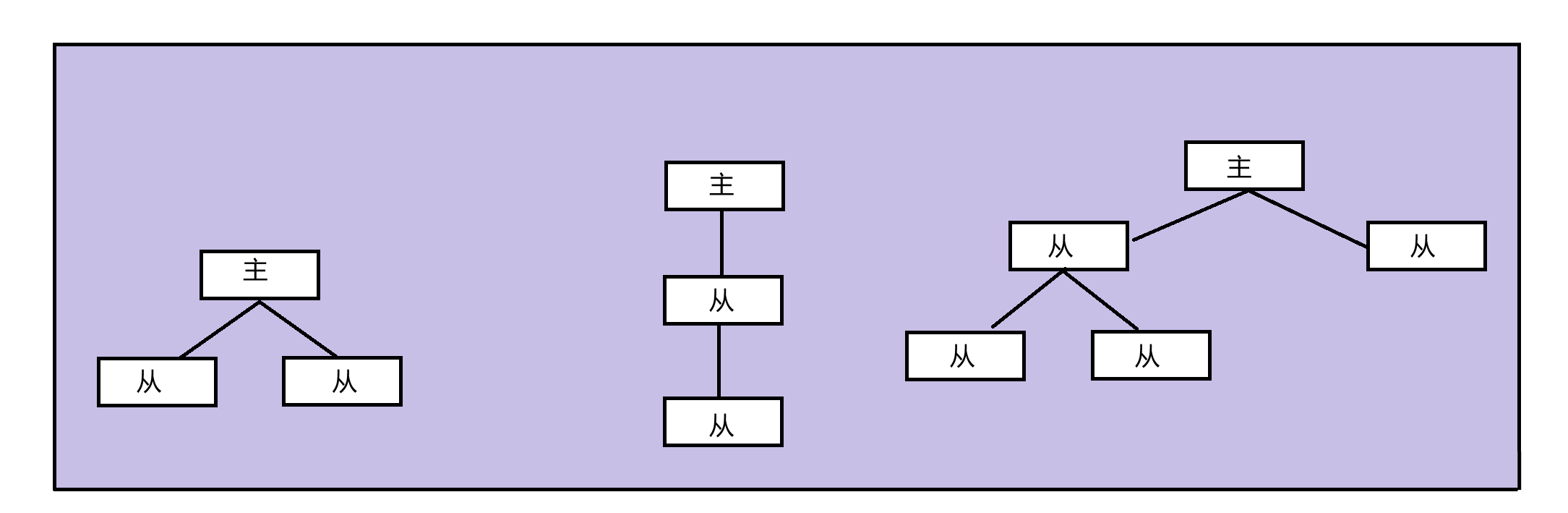
不论是哪种架构,主节点都只能有一个。而且,写操作只能在主节点上,读操作可以在任意节点。
| 节点类型 | 核心职责 | 读写权限 | 数据来源 |
|---|---|---|---|
| 主节点(Master) | 1. 处理所有写请求;2. 接收从节点的复制请求;3. 向从节点同步数据(全量 / 增量) | 可读可写(默认) | 自身内存 / 磁盘(RDB/AOF) |
| 从节点(Slave) | 1. 处理所有读请求;2. 主动连接主节点,持续同步数据;3. 可接收其他从节点的复制请求 | 默认只读(slave-read-only yes) | 主节点同步(全量 + 增量) |
五、主从模式的数据同步原理
在主动服务器一启动,它们之间就会建立TCP长连接,用于同步数据。
Redis主从模式下,数据同步有两种方式:全量复制和增量复制。
全量复制的意思是,在进行数据同步时,从节点需要从主节点上拷贝所有数据。增量复制的意思是,在进行数据同步时,从节点只需要从主节点上拷贝新增的写操作命令即可。
5.1 必要概念铺垫
master_replid:Redis 实例(无论主节点还是从节点)都会维护的一个 40 位十六进制字符串,本质是主节点的身份标识。从节点连接主节点后,会将主节点的 master_replid 复制到自身的master_replid 字段中,用于后续重连时识别 “是否还是之前同步的主节点。这一点在2.2节的截图中可以体现。
偏移量(Offset):主从节点都各自维护一个偏移量,本质上是数据同步的进度。如果主节点的offset和从节点的offset相等,说明此时主节点和该从节点之间的数据已经完全同步。如果从节点的偏移量小于主节点的偏移量,说明此时从节点和主节点之间的数据有差异,需要继续同步。主节点的偏移量和从节点中的偏移量对应2.2节截图中的master_repl_offset和slave_repl_offset。
复制缓冲区(Repl Buffer):主节点为每个从节点维护的一个内存缓冲区,临时存储待发送给从节点的写命令,确保从节点能实时接收。一旦从节点断开连接,该节点对应的复制缓冲区将会被销毁。本质是主节点为每个在线从节点单独维护的 FIFO 命令队列。
复制积压缓冲区(Repl Backlog Buffer):主节点维护的一个环形缓冲区(默认 1MB,可通过排配置文件中的repl-backlog-size调整),记录主节点最近执行的写命令,用于解决从节点断连后的数据恢复(避免全量复制)。
5.2 全量复制
什么情况下会触发全量复制呢?主节点和从节点之间首次进行同步数据的时候和无法进行增量复制的时候。
1)首次同步数据时,从节点向主节点发送请求,告诉主节点说我需要全量数据。
2)主节点执行bgsave命令,生成RDB文件。同时将bgsave期间的所有写命令记录到复制缓冲区。
3)主节点通过TCP连接向从节点发送RDB文件,发送过程中,主节点继续处理写操作,然后将新的写命令同时写入复制缓冲区和复制积压缓冲区。
4)从节点接收完RDB文件后,先清空自身原有数据(避免冲突),然后加载RDB文件到内存中,完成全量数据初始化。
5)从节点加载完RDB文件后,主节点将bgsave和发送RDB文件期间新写的命令发送给从节点。从节点执行这些命令,使自身的数据与主节点中的数据完全相同。
通过上述的一个过程,我们也知道,一次全量复制在数据量较大的情况下,开销还是比较大的。所以能不全量复制就不全量复制,于是就有了第二种数据同步方式——增量复制。
5.3 增量复制
全量复制完成后,主从节点进入稳定运行阶段,此时通过增量复制同步后续写操作,避免频繁的进行全量复制。
1)主节点记录写命令。主节点会将写命令写入两个地方,一个是复制缓冲区:按从节点分别维护,确保每个从节点能收到专属的同步命令,一旦该从节点断连,那么该复制缓冲区将会被销毁。另一个地方是复制积压缓冲区:所有从节点共享,记录命令和对应的偏移量,用于断连后快速恢复。
2)从节点定期向主节点告知自己的偏移量,让主节点知道它的同步进度。
3)主节点收到从节点的偏移量后会进行对比,如果该偏移量小于自己的偏移量,说明还有数据未同步。主节点继续按顺序将复制缓冲区中未发送的命令发送给从节点。
增量复制这个过程,只传输命令,数据量比较小,所以如果可以的话,主节点会优先选择增量复制。
5.4 断线重连
从节点一旦断线,主节点就不再维护该节点对应的复制缓冲区。
在从节点进行重连时,从节点会告知主节点自己保存的master_replid和偏移量等字段。
主节点拿着这个master_replid和自己的进行对比。
如果master_replid相同,说明主节点和这个从节点之前有过连接,接下来,主节点就会拿着从节点提供的偏移量和复制积压缓冲区中的偏移量范围进行对比,如果从节点的偏移量在这个范围之内,也就是说没有被覆盖,那么主节点将会把从节点偏移量之后的所有命令发送给从节点,也就是进行增量复制。如果从节点的偏移量不在积压缓冲区保存的偏移量范围之内,那么将触发全量复制。
如果master_replid不相同,那么直接触发全量复制。
六、主从模式的优缺点
6.1 优点
架构简单:无需额外组件(如哨兵、集群),仅需配置主从节点即可实现读写分离和数据备份。
性能提升:读写分离有效分担主节点读负载,支持横向扩展从节点数量,提升并发读能力。
数据安全:从节点实时备份主节点数据,避免单机数据丢失风险。
成本较低:基于 Redis 原生功能实现,无需额外硬件或软件投入。
6.2 缺点
主节点单点故障:主节点下线后,无法处理写请求,需手动或通过哨兵晋升新主节点(原生主从模式无自动故障转移)。
全量复制开销大:主节点数据量大时,全量复制会占用大量网络带宽和磁盘 IO,可能影响主节点性能。
从节点延迟风险:若主从网络不稳定,从节点可能出现数据延迟(即从节点数据落后于主节点),需通过优化网络或调整repl-backlog-size缓解。
主节点写负载集中:所有写请求仍由主节点处理,若写请求量过大(如每秒 10 万 + 写操作),主节点可能成为性能瓶颈(需通过 Redis 集群解决)。
七、结语
主从模式尤其适合读请求远大于写请求的业务场景,但其架构特性也决定了明显局限:由于仅有主节点具备写请求处理能力,系统天然存在主节点单点故障的风险。单纯采用主从模式时,若主节点意外下线,从节点无法自动切换为主节点承接业务。而主节点的故障往往具有突发性,很难提前预判 —— 总不能在三更半夜主节点故障时,还得临时打电话叫程序猿赶到公司紧急处理。针对这一痛点,哨兵模式可实现从节点对主节点的自动接替,有效解决故障后的自动切换问题。因此,在接下来的博客中,我们将专门探讨哨兵模式,详细讲解它如何解决主从架构中的故障切换问题。
完~

















 9805
9805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









