




 本文介绍了一种使用Python进行网页数据抓取的方法,通过requests和BeautifulSoup库从Boss直聘网站抓取指定城市、关键词和发布时间范围内的职位信息,包括公司名、职位名、薪资等详细数据,并利用xlwt库将抓取的数据存储到Excel文件中,便于后续的数据分析和处理。
本文介绍了一种使用Python进行网页数据抓取的方法,通过requests和BeautifulSoup库从Boss直聘网站抓取指定城市、关键词和发布时间范围内的职位信息,包括公司名、职位名、薪资等详细数据,并利用xlwt库将抓取的数据存储到Excel文件中,便于后续的数据分析和处理。
效果
日志

输出

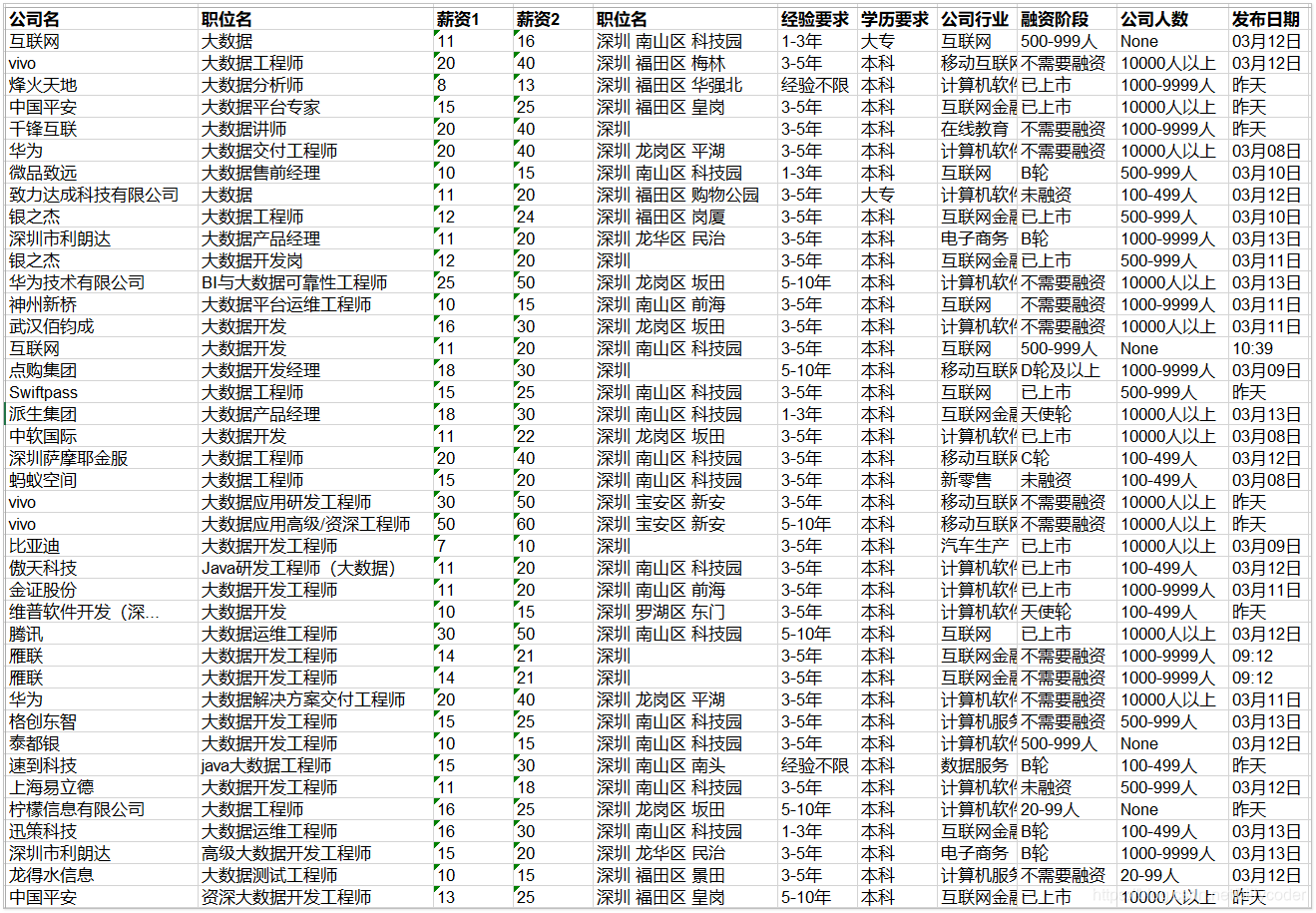
表格内容
代码
import requests
from bs4 import BeautifulSoup
import time
import xlwt # 用来创建excel文档并写入数据
def initRequest():
global url_pattern, headers
url_pattern = 'https://www.zhipin.com/{}/?query={}&period={}&page='.format(city, key, period)
headers = {
'user-agent': 'Mozilla/5.0'
}
def initExcel():
global newTable, wb, ws, headData
hud = ['职位名', '薪资1', '薪资2', '职位名', '地点', '经验', '学历', '公司行业', '融资阶段', '公司人数', '发布日期', '发布人']
print('\t'.join(hud))
import datetime
nowTime = datetime.datetime.now().strftime('%Y%m%d-%H%M') # 现在
newTable = "boss-" + city + "-" + nowTime + "-" + key + "-" + period + ".xls" # 表格名称
print(newTable)
wb = xlwt.Workbook(encoding='utf-8') # 创建excel文件,声明编码
ws = wb.add_sheet('sheet1') # 创建表格
headData = ['公司名', '职位名', '薪资1', '薪资2', '职位名', '经验要求', '学历要求', '公司行业', '融资阶段', '公司人数', '发布日期', '发布人'] # 表头部信息
for colnum in range(0, len(headData) - 1):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font: bold on')) # 行,列
def excel_write(items, index):
# 爬取到的内容写入excel表格
for item in items: # 职位信息
for i in range(0, len(headData) - 1):
# print item[i]
ws.write(index, i, item[i]) # 行,列,数据
print(str(index) + "\t" + str(i) + "\t" + item[i])
index += 1
def start():
try:
page = 1
pageSize = 0
for n in range(1, 11):
url = url_pattern + str(page)
print(url)
html = requests.get(url, headers=headers)
page += 1
soup = BeautifulSoup(html.text, 'html.parser')
items = []
jobPrimarys = soup.find_all('div', 'job-primary')
if pageSize == 0:
pageSize = len(jobPrimarys)
print("页面总数:" + str(pageSize))
for jobPrimary in jobPrimarys:
item = []
# print(gongsi)
gongsi = jobPrimary.find('div', 'company-text').find('a').string
item.append(gongsi) # 公司名
item.append(jobPrimary.find('div', 'job-title').string) # 职位名
xinzi = jobPrimary.find('span', 'red').string
xinzi = xinzi.replace('k', '')
xinzi = xinzi.split('-')
item.append(xinzi[0]) # 薪资起始数
item.append(xinzi[1]) # 薪资起始数
yaoqiu = jobPrimary.find('p').contents
item.append(yaoqiu[0].string if len(yaoqiu) > 0 else 'None') # 地点
item.append(yaoqiu[2].string if len(yaoqiu) > 2 else 'None') # 经验
item.append(yaoqiu[4].string if len(yaoqiu) > 4 else 'None') # 学历
gongsi = jobPrimary.find('div', 'info-company').find('p').contents
item.append(gongsi[0].string if len(gongsi) > 0 else 'None') # 公司行业
item.append(gongsi[2].string if len(gongsi) > 2 else 'None') # 融资阶段
item.append(gongsi[4].string if len(gongsi) > 4 else 'None') # 公司人数
item.append(jobPrimary.find('div', 'info-publis').find('p').string.replace('发布于', '')) # 发布日期
item.append(jobPrimary.find('div', 'info-publis').find('h3').contents[3].string) # 发布人
print('\t'.join(item))
_item = tuple(item) # 转为元组
items.append(_item) # 转为数组
time.sleep(1)
# 写入excel
index = (n - 1) * pageSize + 1
excel_write(items, index)
except:
wb.save(newTable)
pass
# 保存
wb.save(newTable)
print("----------初始化参数----------")
key = 'java' # 搜索关键字
period = '3' # 1天发布,1; 3天发布,2; 7天发布,3;
city = 'c101280600' # c101280600 深圳
print("----------初始化请求----------")
initRequest()
print("----------初始化excel----------")
initExcel()
print("----------开始----------")
start()

















 3121
3121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









