




大家好,我是Tony Bai。
在云原生的世界里,Kubernetes 集群的规模,如同一座待征服的高峰。业界巨头 AWS 已将旗帜插在了 10 万节点的高度,这曾被认为是云的“天际线”。然而,一位前OpenAI工程师(曾参与OpenAI 7.5K节点的Kubernetes集群的建设)发起了一个更雄心勃勃、甚至堪称“疯狂”的个人项目:k8s-1m。他的目标,是向着那座从未有人登顶的、充满未知险峻的“百万节点”之巅,发起一次单枪匹马的极限攀登。
这不简单是一个节点数量级的提升,更像是一场对 Kubernetes 核心架构的极限压力测试。虽然我们绝大多数人永远不会需要如此规模的集群,但这次“攀登”的日志,却为我们绘制了一份无价的地图。它用第一性原理,系统性地拆解和挑战了 Kubernetes 的每一个核心瓶颈,并给出了极具创意的解决方案。
对于每一位 Go 和云原生开发者而言,这既是一场技术盛宴,也是一次关于系统设计与工程哲学的深刻洗礼。
穿越“昆布冰瀑”——征服 etcd 瓶颈
在任何一次珠峰攀登中,登山者遇到的第一个、最著名、也最危险的障碍,是变幻莫测的“昆布冰瀑”。在 k8s-1m 的征途中,etcd 扮演了同样的角色。
无法逾越的冰墙
一个百万节点的集群,仅仅是为了维持所有节点的“存活”状态(通过 Lease 对象的心跳更新,默认每 10 秒一次),每秒就需要产生 10 万次写操作。算上 Pod 创建、Event 上报等其他资源的不断变化,系统需要稳定支撑的是每秒数十万次的写入 QPS。
然而,项目的发起者使用 etcd-benchmark 工具进行的基准测试表明,一个部署在 NVMe 存储上的单节点 etcd 实例,其写入能力也仅有 50K QPS 左右。更糟糕的是,由于 Raft 协议的一致性要求,增加 etcd 副本反而会线性降低写吞吐量。
由此来看,etcd,这座看似坚不可摧的冰墙,以其当前为强持久性和一致性而设计的架构,在性能上与百万节点集群的需求存在着数量级的差距。
登山者的智慧:我们真的需要硬闯冰瀑吗?
面对这个看似无解的矛盾,作者没有选择渐进式优化,而是提出了一个极具颠覆性的观点:大多数 Kubernetes 集群,并不需要 etcd 所提供的那种级别的可靠性和持久性。
临时资源的主导:集群中的绝大多数写入,都是针对临时资源 (ephemeral resources),如
Events和Leases。即使这些数据在灾难中丢失,其影响也微乎其微。声明式 API 的韧性:Kubernetes 的声明式 API 和控制器模式,使其天生具备强大的自愈能力。即使部分状态丢失,控制器也会自动地将系统调谐回期望的状态。
GitOps 时代的“牛群”哲学:在现代 GitOps 流程中,集群的状态真理之源是 Terraform、Helm 或 Git 仓库。在极端情况下,重建一个集群,往往比从备份中恢复一个精确到毫秒的状态要容易得多。
开辟新路:用 mem_etcd 绕行
基于以上洞察,作者没有硬闯“冰瀑”,而是构建了一条全新的、更高效的“绕行路线”——mem_etcd。它并非一个“更好的 etcd”,而是一个被“阉割”和“魔改”的 etcd:
放弃强持久性:
mem_etcd将fsync的决策权完全交给使用者。通过内存存储或带缓冲的 WAL 日志,它将写入性能提升了数个数量级。基准测试结果显示,在关闭fsync的情况下,mem_etcd的吞吐量可轻松超过 1M QPS,而延迟则降低到几乎可以忽略不计。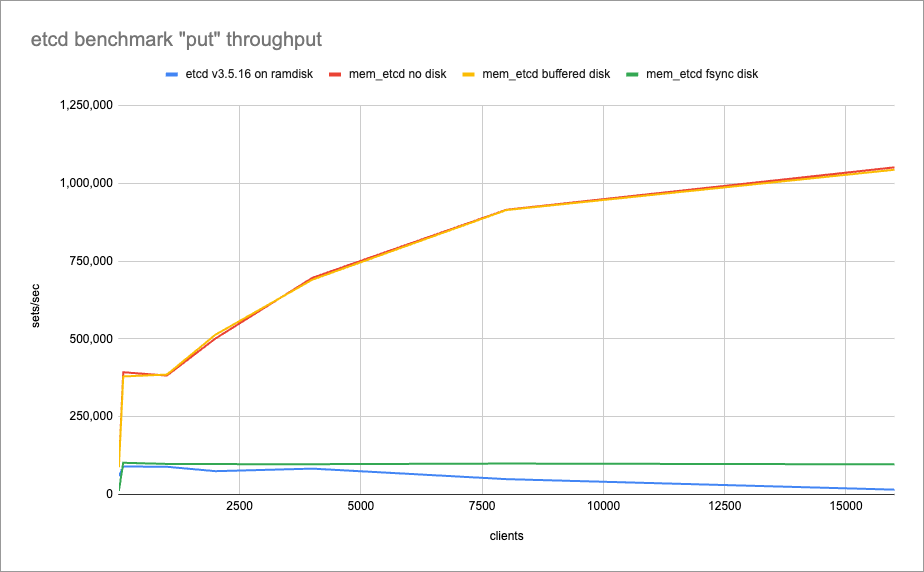
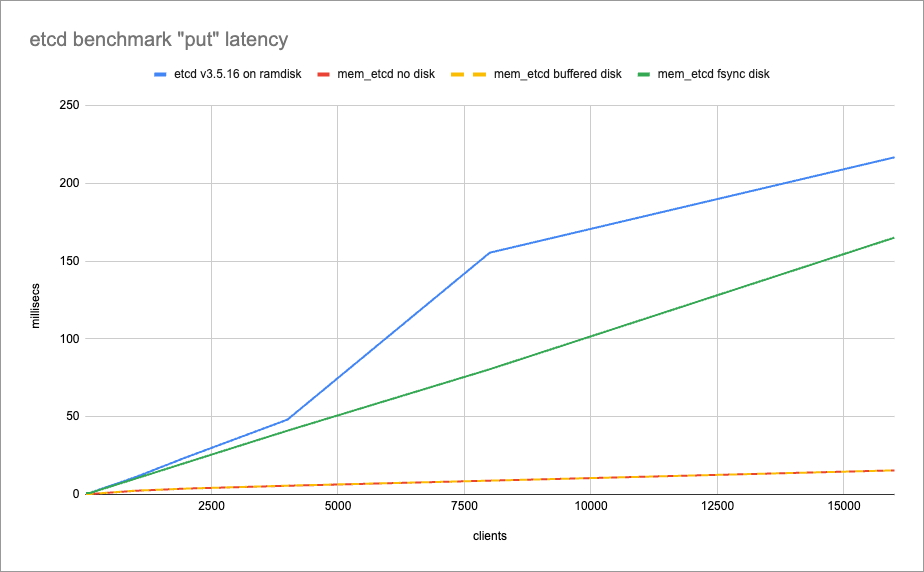
简化接口:通过对真实 K8s 流量的分析,作者发现 K8s 实际只使用了 etcd 接口中一个很小的子集。
mem_etcd只实现了这个最小必要子集,极大地降低了内部复杂性。优化数据结构:针对 K8s 的键空间结构,
mem_etcd采用了全局哈希表 + 分区 B-Tree 的混合数据结构,实现了 O(1) 的键更新和 O(log n) 的范围查询。
通过替换 etcd 这个“心脏”,作者成功穿越了第一个、也是最大的障碍,通往更高海拔的道路豁然开朗。
开辟“希拉里台阶”——重构分布式调度器
成功穿越“冰瀑”后,登山者面临的是更具技术挑战的垂直岩壁,如同珠峰顶下的“希拉里台阶”。在这里,Kubernetes 的“大脑”——kube-scheduler——成为了新的瓶颈。
无法攀登的峭壁
今天的调度器,其核心算法复杂度约为 O(n*p)(n 是节点数,p 是 Pod 数)。在百万节点、百万 Pod 的场景下,这意味着 1 万亿次级别的计算。作者的基准测试显示,在 5 万节点上调度 5 万个 Pod,就需要 4.5 分钟,这距离“1 分钟调度 100 万 Pod”的目标相去甚远。
新的攀登技术:Scatter-Gather
作者没有试图让一个调度器“爬得更快”,而是借鉴了分布式搜索系统的经典“分片-聚合”(Scatter-Gather) 模式,让成百上千个“登山队员”同时向上攀登。
核心思想:将 100 万个节点视为搜索引擎中的 100 万篇“文档”,将待调度的 Pod 视为一次“搜索查询”。
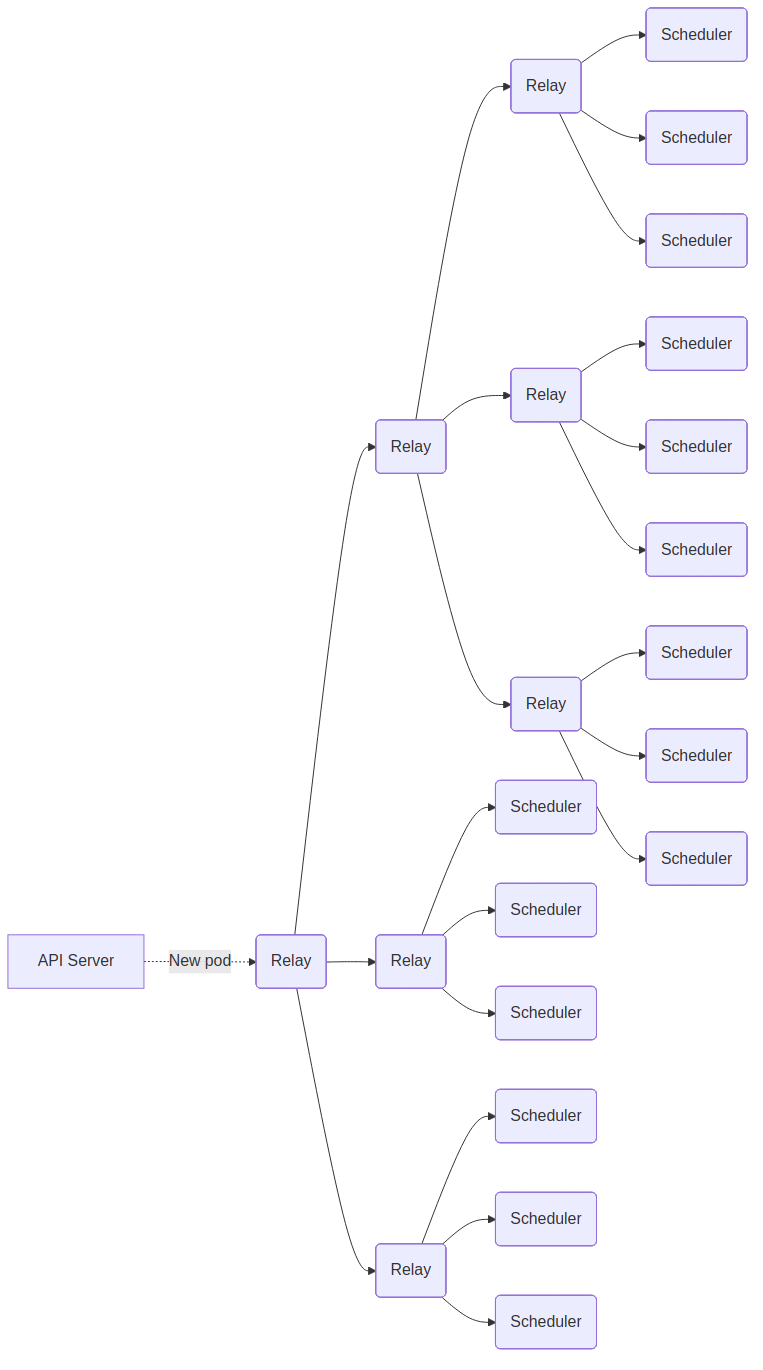
架构:
引入一个或多个 Relay(中继)层,负责接收新的 Pod 请求。
Relay 将 Pod “分发” (Scatter) 给成百上千个并行的 Scheduler 实例。
每个 Scheduler 实例只负责对一小部分节点(一个“分片”)进行过滤和打分。
所有 Scheduler 将各自的最优解返回给 Relay。
Relay “聚合” (Gather) 所有结果,选出全局最优的节点,并最终完成绑定。
峭壁上的“幽灵”
这个优雅的架构在现实中遇到了两大“幽灵”般的挑战:
长尾延迟 (Long-tail Latency):作者引用了 Jeff Dean 的著名论文《The Tail at Scale》,指出在需要数千个调度器紧密协调的系统中,你永远要为那最慢的 1% 付出代价。这个延迟“毛刺”的主要来源,正是 **Go 的垃圾回收 (GC)**。
Watch Stream 的“饥饿”问题:作者发现,在高吞吐量下,
apiserver的 Watch Stream 会出现长达数十秒的“失速”,导致 Relay 无法及时获取到新的待调度 Pod。
为了对抗这些“幽灵”,作者采取了一系列极限优化手段:从绑定 CPU、激进的 GC 调优 (GOGC=800),到做出一个极端的接口变更——用 ValidatingWebhook 替代 Watch,将 Pod 的发现延迟降到了最低。
挺进“死亡地带”——直面 Go GC 的终极挑战
当架构层面的两大峭壁被征服后,攀登进入了海拔 8000 米以上的“死亡地带”。这里的敌人不再是具象的冰川或岩壁,而是“稀薄的空气”——那些看不见、摸不着,却能瞬间让最强壮的登山者倒下的系统性瓶颈。
当 etcd 被替换、scheduler 被分片后,瓶颈最终会转移到哪里?作者给出了一个对 Go 社区极具启发性的答案:
kube-apiserver 的 Watch 缓存:其内部基于 B-Tree 的
watchCache实现,在高频更新下成为了新的锁争用点。Go 的垃圾回收器 (GC):这被认为是最终的、最根本的聚合限制器。在极限规模下,
kube-apiserver会产生并丢弃海量的小对象(在解析和解码资源时),这种巨大的内存流失 (churn) 会给 GC 带来无法承受的压力。增加apiserver的副本也无济于事。
结论:在超大规模场景下,Go 的 GC 成为了那个最后的、最稀薄的“空气”。
小结:登顶之后 -- 地图的价值
k8s-1m 项目,与其说是一个工程实现,不如说是一次勇敢的“思想实验”和极限探索。它成功地将旗帜插在了“百万节点”的顶峰,但其真正的价值,是为后来的“登山者”(其他工程师)绘制了一份详尽的地图。
这份地图向我们揭示了:
第一性原理的力量:勇敢地质疑系统中那些“理所当然”的核心假设,是通往数量级提升的唯一路径。
瓶颈的迁移:系统优化的过程,就是不断将瓶颈从一个组件推向另一个组件的过程。
Go 的伟大与局限:Go 是构建 Kubernetes 这样的云原生巨兽的理想语言,但即便是 Go,在绝对的规模面前,其核心特性(如 GC)也终将面临极限。
这个项目如同一面棱镜,不仅折射出 Kubernetes 架构的未来演进方向,也为我们每一位使用 Go 构建大规模系统的工程师,提供了无价的洞察与启示。
资料链接:https://bchess.github.io/k8s-1m/
项目链接:https://github.com/bchess/k8s-1m
如果本文对你有所帮助,请帮忙点赞、推荐和转发 !
!
点击下面标题,阅读更多干货!
- 后VMware时代:为什么Kubernetes正在成为VM的新家?
- Kubernetes 2.0畅想:告别YAML、etcd束缚与Helm之痛,K8s的下一站是什么?
- 使用Go开发Kubernetes Operator:基本结构
- Go新垃圾回收器登场:Green Tea GC如何通过内存感知显著降低CPU开销?
- Go项目该拥抱Monorepo吗?Google经验、etcd模式及白盒交付场景下的深度剖析
🔥 想系统学习Go,构建扎实的知识体系?
我的新书《Go语言第一课》是你的首选。源自2.4万人好评的极客时间专栏,内容全面升级,同步至Go 1.24。首发期有专属五折优惠,不到40元即可入手,扫码即可拥有这本300页的Go语言入门宝典,即刻开启你的Go语言高效学习之旅!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









