



 请点击上方蓝字TonyBai订阅公众号!
请点击上方蓝字TonyBai订阅公众号!

大家好,我是Tony Bai。
在云原生可观测性的世界里,OpenTelemetry (OTel) 正如日中天。它被誉为“可观测性的未来”,承诺用一个统一的标准,终结 Metrics、Traces、Logs 各自为战的混乱局面。无数的开发者和公司,都在热情地拥抱这个“一次插桩,到处发送”的美好愿景。
但就在这股几乎不可阻挡的浪潮中,一个权威的声音却发出了一个略显刺耳的警告。
这个人,就是 Prometheus 的联合创始人,Julius Volz。
在他最新的博文中,Julius 毫不客气地指出:如果你正在使用 Prometheus 作为你的核心监控系统,并且你真正关心监控的质量和体验,那么,在使用 OpenTelemetry SDK 生成 Metrics 前,请务必三思!
他认为,拥抱 OTel 这个“通用标准”的代价,可能是丢掉 Prometheus 作为一个完整监控系统的“灵魂”,并背上丑陋、低效和复杂的“技术债”。
你正在丢掉 Prometheus 的灵魂
Julius 首先尖锐地指出了一个哲学问题:Prometheus 不仅仅是一个“指标数据库”,它是一个端到端的、有自己思想的监控系统。而 OTel 的“后端无关”设计,恰恰破坏了这种端到端的自洽性。当你选择用 OTel 向 Prometheus 推送数据时,你正在放弃这些至关重要的原生特性:
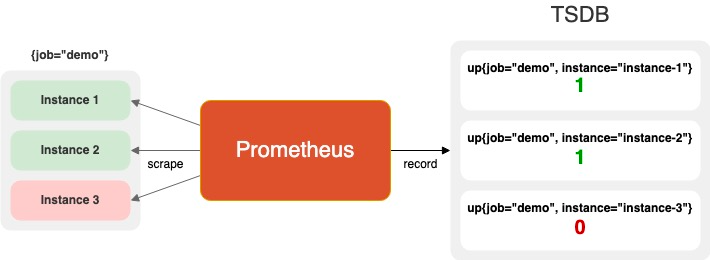
失去灵魂:Target 健康监控 (up 指标)
Prometheus 最核心的设计之一就是 Pull 模型 + 服务发现。这意味着 Prometheus 主动拉取指标,它清楚地知道“哪些目标应该存在”以及“它们现在是否健康”。如果一个目标拉取失败,Prometheus 会自动生成一个 up{job="demo"} = 0 的指标。你可以用一条简单的 PromQL 告警规则 up == 0 来发现任何失联的服务。
然而,当你使用 OTel 的 Push 模型时,Prometheus 变成了一个被动的“无情的数据接收器”。它无法再区分一个服务是“正常下线”还是“已经崩溃但没来得及上报”。你可能拥有数百个已经死掉的服务进程,却在监控图表上一无所知。
失去优雅:丑陋的 PromQL 查询
为了兼容 PromQL,OTel 的指标在进入 Prometheus 时,往往需要经过“魔改”。
命名冲突: OTel 允许在指标名中使用
.,而 Prometheus 的传统是不允许的。所以,一个 OTel 指标k8s.pod.cpu.time在进入 Prometheus 后,会被翻译成k8s_pod_cpu_time_seconds_total。这种不一致性会给开发者带来困惑。繁琐的查询语法: 为了支持 OTel 更宽泛的字符集,如果你想查询原始的 OTel 指标名,你的 PromQL 查询会从优雅的
my_metric{...}变成丑陋的{"my.metric", ...}。
失去便利:复杂的标签 Join
Prometheus 的 target labels(如 instance, job)会被自动附加到从该目标拉取的所有指标上。而 OTel 的 resource attributes(包含更多非关键元数据)则不会。为了避免高基数问题,大部分 OTel 的资源属性被打包进了一个单独的 target_info 指标里。
这意味着,如果你想在查询时使用这些属性,你必须写出类似下面这样繁琐的 group_left join 查询:
// 想加一个 k8s_cluster_name 标签,查询变得如此复杂
rate(http_server_request_duration_seconds_count[5m])
* on(job, instance) group_left(k8s_cluster_name)
target_info这些问题,都在不断地增加你的认知负荷和工作复杂度。
性能鸿沟:Go SDK 的“血案”现场
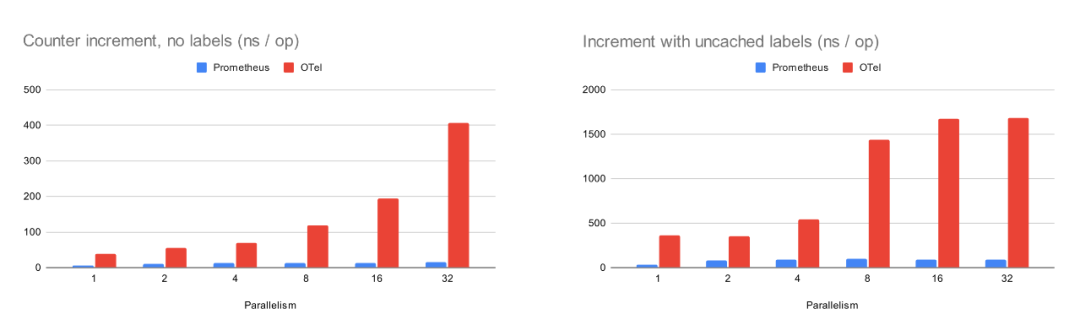
如果说失去优雅和可靠性还不足以让你警醒,那么接下来的硬核性能数据,可能会让你大吃一惊。Julius 特别对比了 Prometheus Go SDK 和 OpenTelemetry Go SDK 在执行最常见操作——计数器递增——时的性能。
结论是毁灭性的。
Julius 的基准测试显示,在不同的并行度和标签缓存条件下:
在最坏情况下,Prometheus Go SDK 比 OTel Go SDK 快 26 倍。
在有标签缓存的最佳情况下,Prometheus Go SDK 甚至可以比 OTel Go SDK 快 53 倍!
更致命的是,Prometheus Go SDK 在所有情况下都实现了零新内存分配,而 OTel SDK 在设置标签时则会持续产生内存分配。
为什么会有如此惊人的差距?
复杂性 vs. 专注性: OTel SDK 是一个试图统一三驾马车(Metrics, Traces, Logs)的庞大系统,内部抽象层次多,路径长。而 Prometheus SDK 的目标极其单一和专注:用最高效的方式生成 Prometheus 指标。
主观代码体验: Julius 更是用一个生动的例子佐证了这一点——他想在两个 SDK 中找到核心的
Inc()函数实现。在 Prometheus Go SDK 中,他花了 5 秒;而在 OTel Go SDK 中,他在复杂的抽象和间接调用中迷失了 15 分钟后,最终放弃了。
对于性能至关重要的 Go 后端服务来说,选择 OTel SDK 进行指标插桩,无异于在你的性能快车道上,悄悄地铺上了一层厚厚的沥青。
结论:在“通用标准”与“原生体验”之间做出选择
Julius 的文章并非是否定 OpenTelemetry 的价值。OTel 作为一个中立的、后端无关的“可观测性瑞士”,在构建异构系统、避免厂商锁定的场景中,依然具有不可替代的战略意义。
但他的警告是在提醒我们一个深刻的权衡:
OpenTelemetry 的世界观: 追求最大的通用性和互操作性。它是一个数据生成和传输的标准,它不关心数据最终如何被使用。
Prometheus 的世界观: 追求一个深度整合、端到端优化的系统体验。它的每一个设计——从 Pull 模型到 PromQL 语法——都在为最终用户能以最优雅、最高效的方式进行监控和告警服务。
如果你已经选择 Prometheus 作为你的核心监控“城邦”,那么使用它原生的客户端库,并非是选择“封闭”,而是选择一个经过千锤百炼的、高度自洽的、性能卓越的解决方案。
所以,在你为下一个 Go 项目 go get OTel SDK 之前,请先问自己一个问题:我是在追求一个“放之四海而皆准”的通用标准,还是在追求一个能将我的核心工具发挥到极致的原生体验?
答案,可能决定了你未来无数个夜晚的睡眠质量。
资料链接:https://promlabs.com/blog/2025/07/17/why-i-recommend-native-prometheus-instrumentation-over-opentelemetry/
如果本文对你有所帮助,请帮忙点赞、推荐和转发 !
!
点击下面标题,阅读更多干货!
- 为什么 VictoriaMetrics 正在替换 Prometheus?一次大规模可观测性迁移实录
- 不止是云原生:为什么Go的热度在持续上升?来自社区的真实声音
- Kubernetes 2.0畅想:告别YAML、etcd束缚与Helm之痛,K8s的下一站是什么?
- Anthropic内部实践首次公开:揭秘Claude Code如何引爆全员生产力
🔥 你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
想写出更地道、更健壮的Go代码,却总在细节上踩坑?
渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的 《Go语言进阶课》 终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》 就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









