



 本文介绍了使用Python Selenium库爬取JD商品信息的初级案例。通过建立类JdGoodsSpider,实现搜索关键词、模拟点击、滚动加载和抓取商品的名称、价格及图片等信息。在main函数中创建爬虫对象并执行爬取,最终将数据保存为JSON文件。
本文介绍了使用Python Selenium库爬取JD商品信息的初级案例。通过建立类JdGoodsSpider,实现搜索关键词、模拟点击、滚动加载和抓取商品的名称、价格及图片等信息。在main函数中创建爬虫对象并执行爬取,最终将数据保存为JSON文件。
首先,这是一个爬取jd的一个很基础的案例,大神们勿喷,我是小白中的小白,这是老师教我们的一个我自认为比较完整的例子,我把其中的思路也写出来了,注释写得不多,凑合看看吧
爬虫的思路:
1.建立class类
2.搭建基础框架:
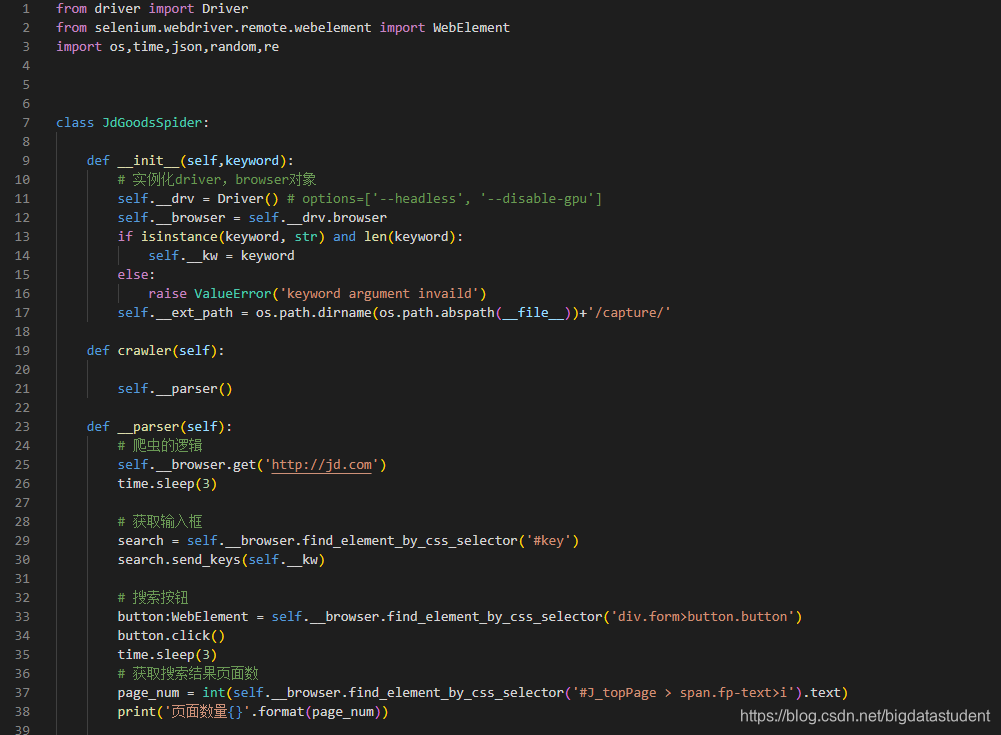
from driver import Driver
from selenium.webdriver.remote.webelement import WebElement
import os,time,json,random,re
class JdGoodsSpider:
def init(self,keyword):
实例化driver,browser对象
self.__drv = Driver() # options=[’–headless’, ‘–disable-gpu’]
self.__browser = self.__drv.browser
if isinstance(keyword, str) and len(keyword):
self.__kw = keyword
else:
raise ValueError(‘keyword argument invaild’)
self.__ext_path = os.path.dirname(os.path.abspath(file))+’/capture/’
定义爬取方法
def crawler(self):
self.__parser()调用self.__parse
定义爬取依赖的方法
def __parser(self):
在里面写爬虫的逻辑
def close(self):
self.__browser.close()
3.在__parser()方法里写爬虫逻辑
(1)self.__browser.get(‘http://jd.com’)输入你想爬取网站的url地址
time.sleep(3)
(2)写一个main方法:
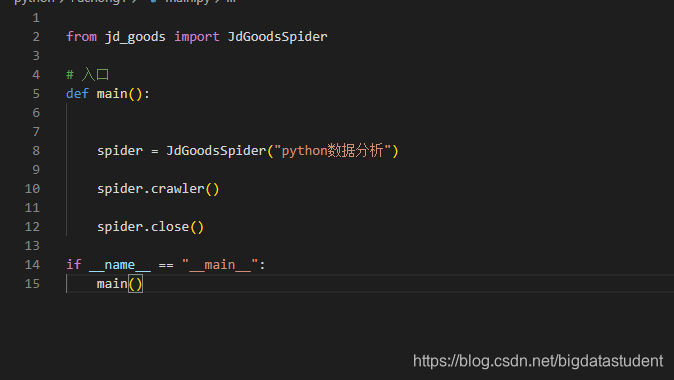
from jd_goods import JdGoodsSpider
def main():
创建蜘蛛(初始化对象)
spider = JdGoodsSpider(“python数据分析”)输入关键字
调用crawler方法,开始爬取
spider.crawler()
调用close方法,关闭爬取
spider.close()
if name == “main”:
main()
(3)继续在步骤1里面写逻辑
首先找到关键字里面的id(在input里面)获取输入框
search = self.__browser.find_element_by_css_selector(’#key’)
search.send_keys(self.__kw)
由于有些网站并没有submit,所以我们要写一个搜索按钮
button:WebElement = self.__browser.find_element_by_css_selector(‘div.form>button.button’)
button.click()
然后根据你的需求,找你要搜索的内容,我这里是搜索结果页数和商品详情,商品详情包括(价格,名字,图片)
首先获取搜索结果页面数:
page_num = int(self.__browser.find_element_by_css_selector(’#J_topPage > span.fp-text>i’).text)
print(‘页面数量{}’.format(page_num))
上面页面数已经求到,所以就涉及一个滚屏操作,于是就要定义一个滚屏方法,写在close方法前即可:
def __scroll(self):
self.__browser.execute_script("""
window.scrollTo(0,window.scrollY+window.innerHeight)
“”")
然后继续回到刚才的搜索结果页面数的下方,写滚屏的操作
for page in range(page_num):
# 滚屏
for i in range(10):
self.__scroll()
time.sleep(1)
滚屏操作写完后,就开始写获取商品详情:
goods_img_selector = ‘ul.gl-warp.clearfix > li > div.gl-i-wrap > div.p-img img’
goods_price_selector = ‘ul.gl-warp.clearfix > li > div.gl-i-wrap > div.p-price i’
goods_name_selector = ‘ul.gl-warp.clearfix > li > div.gl-i-wrap > div.p-name a’
images = self.__browser.find_elements_by_css_selector(goods_img_selector)
prices = self.__browser.find_elements_by_css_selector(goods_price_selector)
names = self.__browser.find_elements_by_css_selector(goods_name_selector)
goods_infos = []
for i,p,n in zip(images,prices,names):
price = p.text
if len(price) > 1 and re.findall('\d+.\d+',price):
price = float(price)
goods_infos.append({
'name': n.get_property('title'),
'price': price,
'image': i.get_property('src')
})
# for v in goods_infos:
# print('商品名称:{}'.format(v['name']))
# print('商品价格:{}'.format(v['price']))
# print('商品图片:{}'.format(v['image']))
# print('-' * 100)
with open('{}/goods/{}.json'.format(self.__ext_path , (page+1)),'w+',encoding='utf-8')as fs:
json.dump(goods_infos,fs,ensure_ascii=False,indent=4)
print('第{}页数据写入完成'.format(page+1))
获取完一页数据后进行翻页,写一个翻页的方法最后调用
# 跳转到下一商品页
self.__next_page()
翻页方法:
def __next_page(self):
button = self.__browser.find_element_by_css_selector(’#J_bottomPage > span.p-num > a.pn-next’)
button.click()
time.sleep(random.randrange(2,6))
然后代码如下:
首先这是main方法的
这是class JdGoodsSpider 的:
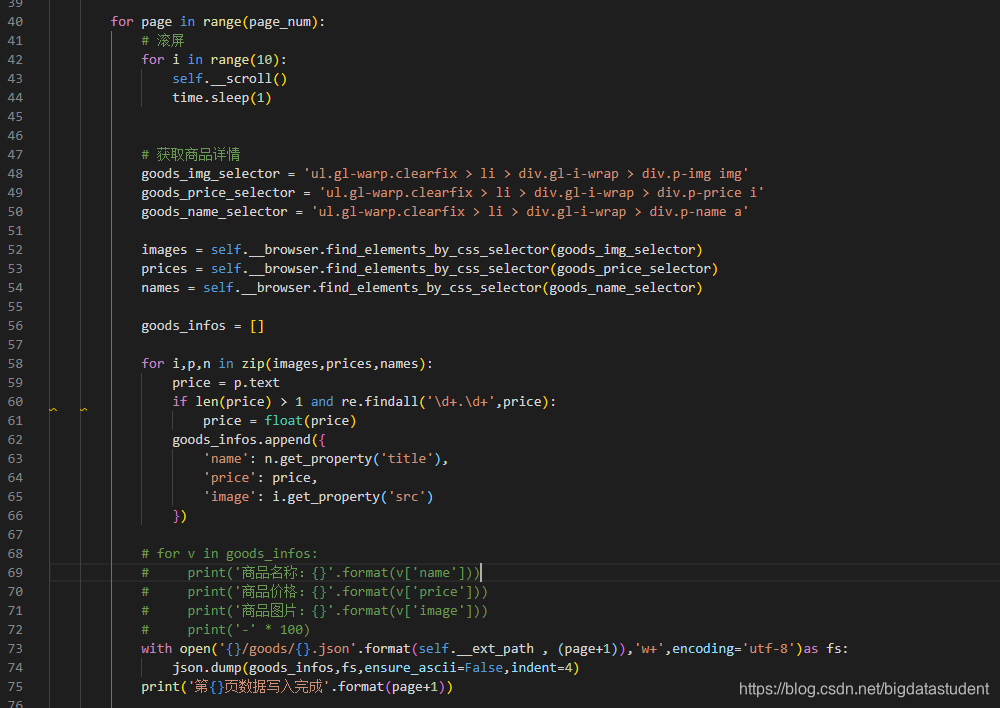
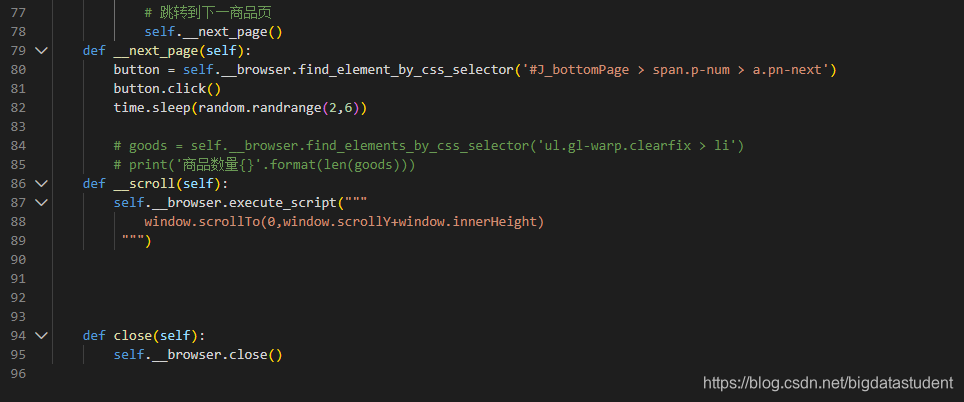
因为是昨天做的,终端没有忘了截图,操作成功过后就会在goods里面生成下面这种json文件:


一共一百页
第一次写博客也没什么经验,就这样吧

















 486
486





 到【灌水乐园】发言
到【灌水乐园】发言







