




 本文介绍如何从14个分卷文件合并并解压CelebA数据集中的img_celeba.7z文件。当尝试使用unzip命令解压时出现问题,因为该文件需要用7zip解压。文中详细描述了合并文件及使用7zip进行解压的具体步骤。
本文介绍如何从14个分卷文件合并并解压CelebA数据集中的img_celeba.7z文件。当尝试使用unzip命令解压时出现问题,因为该文件需要用7zip解压。文中详细描述了合并文件及使用7zip进行解压的具体步骤。
笔者水平有限,有错望纠
1.下载CelebA中的img_celeba.7z ,文件是14个压缩包分卷,分别是001-014。
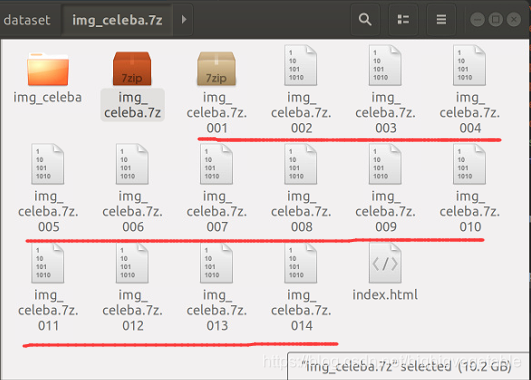
2.将14个分卷文件合并,具体命令如下
cat img_celeba.7z.0** > img_celeba.7z
解压文件,命令如下 unzip img_celeba.7z ,得到img_celeba文件夹
但是出现报错说,文件格式 unzip 无法识别出来
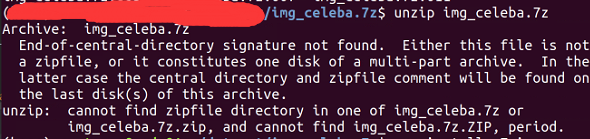
原因是后缀名为“.7z"的文件需要7zip解压,于是先安装7zip:
sudo apt-get install p7zip-full
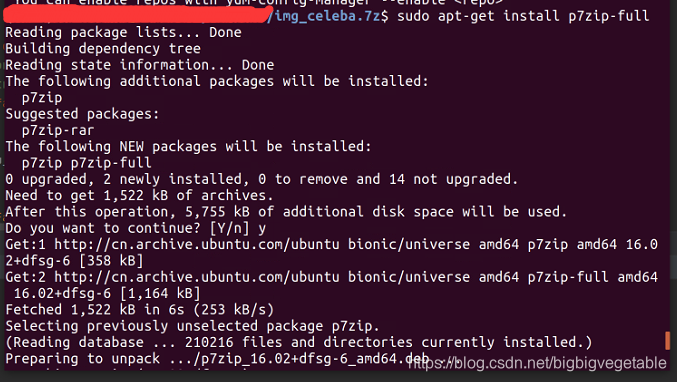
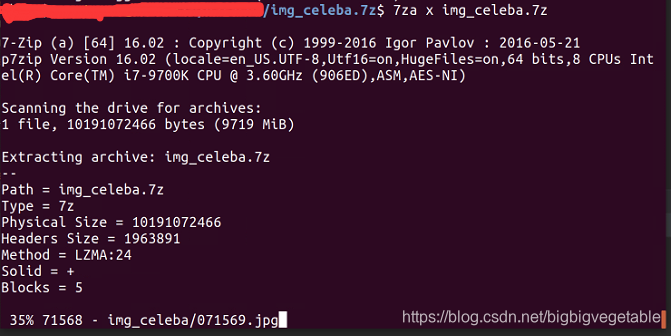
安装成功后终端输入
7za x img_celeba.7z


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









