



博主随便发一个笔记,来记录一下!!!
一、自注意力机制:捕捉序列全局依赖的利器
自注意力机制(Self-Attention Mechanism)的核心目标是解决传统序列建模模型(如 RNN、LSTM)在长序列处理中的局限性,实现全局依赖捕捉和并行计算。
1.1基本概念:Q、K、V 的核心角色
自注意力机制的核心是通过 "查询 - 键 - 值"(Query-Key-Value)交互模式,计算序列中每个元素与其他元素的关联关系。其本质是回答两个问题:"我应该关注谁?" 和 "关注后如何融合信息?"
- Query(Q,查询向量):当前元素的 "需求表达",用于主动查询其他元素的相关性,即 "我想知道对我来说谁重要";
- Key(K,键向量):其他元素的 "身份标签",用于被查询时提供匹配依据,即 "告诉别人自己是什么";
- Value(V,值向量):其他元素的 "实际信息内容",即 "被关注后提供的具体信息"。
每个元素在序列中同时扮演这三个角色,通过三者的交互实现上下文信息的动态融合。
1.1实现过程:从输入到注意力输出的完整流程
自注意力机制的实现可分为以下关键步骤:
步骤 1:输入序列表示
设输入为长度为n、维度为d的序列:
X=(x1,x2,…,xn)∈Rn×d
其中xi为序列中第i个元素的向量表示(如词向量)。
步骤 2:Q、K、V 的线性变换
通过可学习的权重矩阵将输入映射为 Q、K、V:

代码示例:
import torch
import math
# 假设输入嵌入维度为512,序列长度为7
embedding_out = torch.randn(7, 512) # 模拟嵌入层输出
# 生成Q、K、V
Wq = torch.randn(512, 512) # Query权重矩阵
Wk = torch.randn(512, 512) # Key权重矩阵
Wv = torch.randn(512, 512) # Value权重矩阵
Query = torch.matmul(embedding_out, Wq) # 形状:[7, 512]
Key = torch.matmul(embedding_out, Wk) # 形状:[7, 512]
Value = torch.matmul(embedding_out, Wv) # 形状:[7, 512]
步骤 3:计算注意力得分
通过 Q 与 K 的点积计算元素间相似度,并除以dk避免数值过大导致的梯度问题:
其中(i,j)位置的元素表示第i个元素与第j个元素的相关性得分。
代码示例:
# 计算注意力得分并缩放
score = torch.matmul(Query, Key.transpose(0, 1)) / math.sqrt(512)
# 输出形状:[7, 7],每个元素(i,j)表示第i个词与第j个词的原始相关性
步骤 4:注意力权重归一化
对得分矩阵按行进行 Softmax 操作,将得分转换为概率分布(每行和为 1):
代码示例:
# 归一化注意力得分
normalized_scores = torch.softmax(score, dim=1) # 按行归一化
# 输出形状:[7, 7],每个元素表示归一化后的注意力权重
步骤 5:加权求和生成输出
用注意力权重对 V 进行加权求和,得到融合上下文信息的输出:
代码示例:
# 加权求和得到最终输出
attention_result = torch.matmul(normalized_scores, Value)
# 输出形状:[7, 512],每个元素是融合上下文后的向量表示
二、多头注意力机制:增强模型表达能力的扩展
多头注意力机制(Multi-Head Attention)是自注意力的扩展,通过多组并行的注意力计算,让模型在不同子空间学习多样化的上下文关联。
2.1 核心思想
多头注意力将 Q、K、V 分割为h个 "头"(子空间),每个头独立计算自注意力,最后将所有头的输出拼接并映射为最终结果。其核心价值是让模型同时学习不同类型的关联模式(如语法关联、语义关联等)。
2.2 实现过程
步骤 1:多头分割与映射
将 Q、K、V 通过不同的权重矩阵映射到h个子空间,每个子空间维度为dk/h(通常总维度保持不变):
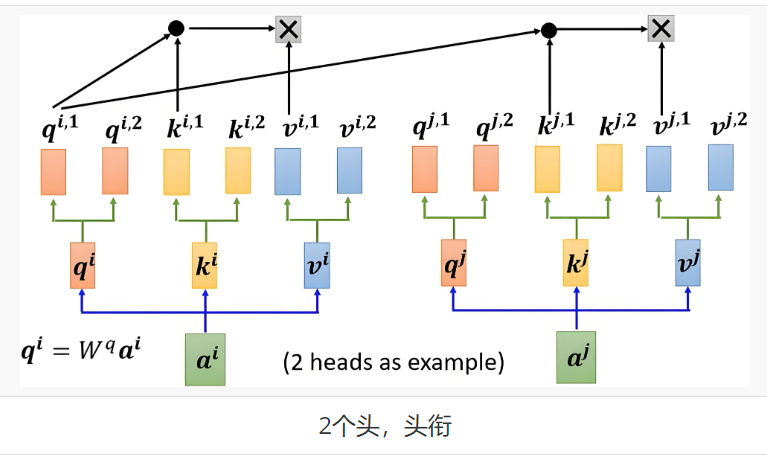
代码示例:
head_num = 8 # 头数量
d_k = 512 // head_num # 每个头的维度
# 生成每个头的Q、K、V权重矩阵
W_Q_list = torch.stack([torch.randn(512, d_k) for _ in range(head_num)])
W_K_list = torch.stack([torch.randn(512, d_k) for _ in range(head_num)])
W_V_list = torch.stack([torch.randn(512, d_k) for _ in range(head_num)])
# 映射得到每个头的Q、K、V
Query_list = torch.stack([torch.matmul(embedding_out, W_Q_list[i]) for i in range(head_num)])
Key_list = torch.stack([torch.matmul(embedding_out, W_K_list[i]) for i in range(head_num)])
Value_list = torch.stack([torch.matmul(embedding_out, W_V_list[i]) for i in range(head_num)])
# 形状:[8, 7, 64](8个头,每个头序列长度7,维度64)
步骤 2:多头独立计算
每个头独立执行自注意力计算(得分→归一化→加权求和):
代码示例:
# 每个头计算注意力得分
scores_list = torch.stack([
torch.matmul(Query_list[i], Key_list[i].transpose(0, 1)) / math.sqrt(d_k)
for i in range(head_num)
])
# 归一化
scores_list = torch.stack([torch.softmax(scores_list[i], dim=-1) for i in range(head_num)])
# 加权求和得到每个头的输出
Output_list = [torch.matmul(scores_list[i], Value_list[i]) for i in range(head_num)]
步骤 3:输出拼接与线性变换
将所有头的输出拼接,再通过线性变换得到最终结果:
其中, 是所有头拼接的结果,维度是
,其中 h 是头的数量,d_v 是每个头的值向量的维度。
代码示例:
# 拼接所有头的输出
Output = torch.cat(Output_list, dim=-1) # 形状:[7, 512]
# 最终线性变换
W_O = torch.randn(512, 512)
Output = torch.matmul(Output, W_O) # 形状:[7, 512]
2.3 表达能力提升
多头注意力通过多子空间并行学习,让模型:
- 同时捕捉不同类型的关联(如语法、语义、位置等);
- 增强对复杂上下文的建模能力;
- 提高模型的鲁棒性和泛化能力。
三、层归一化:稳定训练的关键技术
层归一化(Layer Normalization)是用于规范化神经网络中间特征分布的技术,与 BatchNorm 相比,更适合 Transformer、RNN 等序列建模场景。
3.1 与 BatchNorm 的核心区别
| 特征 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化维度 | 对每个特征维度在 batch 内归一化 | 对每个样本的所有特征维度归一化 |
| 应用场景 | CNN 常用 | Transformer、RNN 等序列模型常用 |
| 依赖 batch_size | 依赖(batch_size 过小效果差) | 不依赖(单样本即可计算) |
| 推理阶段处理 | 需要存储训练时的均值 / 方差 | 直接用当前样本计算,无需存储 |
3.2 计算过程
层归一化以单个样本为单位,对其所有特征维度进行归一化,步骤如下:
1.计算均值:对样本的所有特征维度求平均
2.计算方差:
3.归一化:
3.3 实例说明
假设你有一句话经过嵌入层后的表示是一个矩阵,形状是:
[句子长度, 特征维度] = [5, 4]
一句 5 个词,每个词用 4 维向量表示:
["I", "am", "a", "good", "student"]
经过 embedding 之后得到:
I -> [1.2, -0.5, 0.3, 0.7]
am -> [1.0, 0.0, 0.1, 0.6]
a -> [0.9, 0.2, 0.4, 0.3]
good -> [1.3, -0.3, 0.5, 0.8]
student -> [1.1, -0.1, 0.2, 0.4]
它对每个词的 4 维向量分别归一化:
- 计算均值:
- 计算方差:
- 归一化:每个维度减去均值并除以标准差
, 最终你得到一个新的 [1.2, -0.5, 0.3, 0.7] 的“归一化版本”,然后对“am”、“a”、“good”、“student”每一个词都分别做这个过程。

















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









