




 提出一种新的RGB-D PAD框架,利用RGB和深度信息检测人脸识别中的攻击。该框架采用多头架构和跨模态焦点损失,提高了对未知攻击的鲁棒性。
提出一种新的RGB-D PAD框架,利用RGB和深度信息检测人脸识别中的攻击。该框架采用多头架构和跨模态焦点损失,提高了对未知攻击的鲁棒性。
简要
自动检测表现攻击的方法对于确保人脸识别技术的可靠使用来说至关重要。现有的大多数文献中的攻击检测(PAD)方法对于未见过的攻击检测泛化性能很差。近年来,为了提高PAD系统的鲁棒性,人们提出了多通道方法。通常,用于多通道方法的数据量是有限的,这限制了这些方法的有效性。在本文中,我们提出了一个新的PAD框架,该框架使用RGB和深度通道和一个新的损失函数进行结合。新的架构使用了两种模式的互补信息,同时减少了过度拟合的影响。本质上说,一个跨模态的焦点损失函数被提出,该函数作为通道置信度函数用来调节不同通道的损失贡献。在两个公开的数据集中进行了广泛的评估,证明了该方法的有效性。
一. 介绍
人脸识别技术已经成为普遍的生物认证方法,但在安全场景中使用时,呈现攻击(也称为“欺骗攻击”)的脆弱性是一个主要问题[9],[12]。这些攻击可以是模拟攻击也可以是混淆攻击。模拟攻击试图通过伪装他人获得访问权限,混淆攻击试图逃避人脸识别系统。虽然许多解决该问题的方法在文献中被提出,但大多数方法对于未见过的攻击测试都以失败告终[10]。在实际场景中,在训练PAD模型时,不可能对所有类型的攻击都进行预测。此外,PAD系统期望能检测到新的高水平的类型攻击。因此,在PAD模型中具有对抗不可见类型的攻击鲁棒性是很重要的。
大部分的文献都是基于RGB像机来检测攻击。这些年来,许多基于特征的方法已经被提出,如使用颜色、纹理、运动、生动性线索、直方图特征[7]、局部二值模式[25]、[8]和运动模式[3]来执行PAD。近些年来基于CNN的方法也被提出,包括3D-CNN[13]、基于零件的模型[22]等。一些研究表明,使用二进制或深度监督形式的辅助信息可以提高性能[4,14]。然而,这些方法中的大多数都是专门为2D攻击设计的,而且这些方法对具有挑战性的3D和部分攻击的性能很差[24]。此外,这些方法对不可见攻击的鲁棒性较差。
单RGB模型的性能随着攻击复杂性的提高(如3D掩码和部分攻击)而下降。由于可见光光谱的局限性,一些多通道人脸检测方法,如[30]、[12]、[31]、[11]、[2]、[6]、[5]、[15-18]被提出用于PAD系统。从本质上说,当多通道PAD系统从不同的通道捕获互补信息时,它变得更难欺骗。同时欺骗不同的渠道需要更多的努力。多通道方法已经被证明是有效的,但是它带来了昂贵的硬件成本。这会导致这些系统难以广泛部署,即使它们很有效。PAD有多种通道可供选择,例如RGB、深度、热、近红外光谱、SWIR光谱、紫外线、光场成像等。在这些不同的模式中,RGB-D设备价格相当低廉,在市场上容易买到,因此可以在实际场景中部署它们。Intel RealSense系列,devices、Microsoft Kinect和OpenCV AI Kit(OAKD)[1]是该设备的标准示例,这些设备不需要任何额外的工作就可以获得多通道图像。由于这些通道被集成在一个包中,而且广泛可用性,我们选择RGB和Depth作为这项工作中使用的两个通道。然而,所提出的框架可以简单地扩展到任何信道组合。
即使在使用多个通道时,模型也倾向于过度适应训练集中的攻击。虽然模型对于训练集中看到的攻击中可以执行的很完美,但在现实场景中遇到未见过的攻击时,性能通常会下降。这是大多数机器学习算法中普遍存在的现象,在训练数据量有限的情况下,问题会更加严重。在缺乏强先验知识的情况下,这些模型可能会过度适应它所训练的特定数据集的统计偏差,并且可能无法推广到未见过的样本。多通道方法由于额外的通道而增加了参数的数量,因此过度拟合的可能性也会增加。
本文的工作中,我们从两个不同的方向来解决这个问题。首先,我们使用一个多头部架构,它遵循一个后期融合策略来组合不同的通道信息。我们没有将表示连接到一个联合的最终节点,而是为各个分支和联合分支分别保留三个不同的头,这可以看作是一种架构规则化的形式。所提出的架构如图1所示。这使我们能够同时监督单个通道和联合表示,确保在单个分支和联合分支中学习鲁棒性表示。其次,我们提出了一个跨模态的焦点损失函数来监督各个通道,该损失函数能够调节不同通道的置信度。
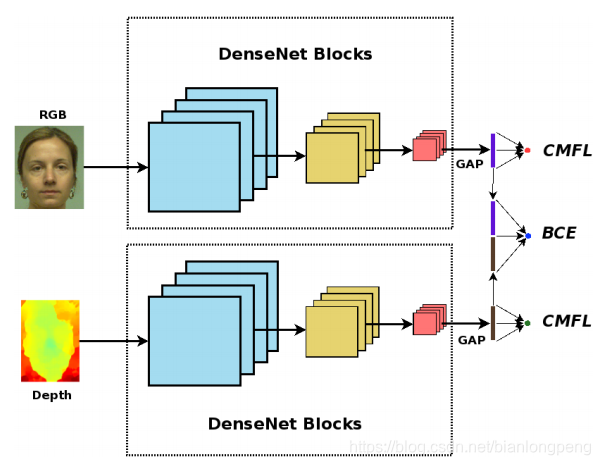
图1:PAD系统框架。采用了两路流多头结构和后期融合策略。各个通道对应的头部由所提出的跨模态损失(CMFL)进行监督,而联合模型则由二进制交叉熵(BCE)进行监督。
本文的主要贡献如下:
- 提出一种帧级的PAD人脸方法,该方法用来同步捕获RGB-D样本
- 提出了一种新的损失函数,称为跨模态焦点损失(CMFL),可用于多流结构中单信道的监督。
- 尽管该模型是针对多通道场景进行训练的,但也可以通过使用与通道对应的头部得分来部署单个通道
- 我们在两个公开的数据集上展示了该框架的有效性,这两个数据集由多种具有挑战性的未见过的攻击组成
二. 提出的方法
本节描述了所提出的PAD框架的不同阶段
2.1 预处理
PAD框架路线中数据采用的是裁剪过的面部图像。对于RGB图像,预处理阶段包括使用MTCNN[32]框架进行人脸检测和关键点定位,然后进行对齐。检测到的人脸是通过使眼睛中心水平对齐,然后将其调整到224×224的分辨率。对于深度图像,使用使用中值绝对偏差(MAD)[27]的归一化方法来归一化面部图像到8位范围。RGB和深度原始图像已经在空间上注册,以便可以使用相同的变换来对齐深度图像中的脸部。
2.2 网络结构和损失函数
本节用来描述提出的网络结构和损失函数
2.2.1 网络结构
根据现有文献,多通道的方法对多种范围的攻击都具有鲁棒性[15–18]。概括地说,基本有四种不同的策略来融合来自多个通道的信息,它们是:1. 早期融合,这意味着通道是在输入层进行堆叠(例如,MC-PixBiS[18])。2. 后期融合,这意味着来自不同网络的表示在后期进行组合,类似于特征融合(例如MCCNN[17]),3. 得分融合,针对不同的通道信息分别训练各个网络,并且对每个通道的得分执行分数级融合。4. 是一种混合方法,即来自多个级别的信息被组合在一起,如[28]。
尽管多通道信息可以很好地对抗各种各样的攻击,但当所有通道一起使用并作为二进制分类器训练时,它们往往会过拟合那些训练数据中已知的攻击。为了避免这种情况,我们提出了一种遵循后期融合策略的多头体系结构。所提出的网络的、架构如图1所示。基本上,该体系结构由一个双流网络组成,该网络具有用于分通道(RGB和Depth)的独立分支。来自两个通道词向量组合形成第三个分支。全连接层被添加到这些分支中来形成最终的分类器头。这三个头被一个损失函数共同监督,从而使网络从单个通道和及联表示中学习区分信息,来减少过拟合。多头部结构还能使得即使在测试阶段缺少通道信息也可以通过得分机制执行,这意味着即使网络在RGB-D数据上训练,我们也可以单独使用RGB分支(单独使用来自RGB头部的得分)进行评分。
这些分支由Huang等人提出的DenseNet 结构(densenet161)的前八个区块组成。[19]. 在DenseNet架构中,每一层都与其他层相连,减少了梯度消失问题,同时减少了参数量。我们使用来自图像网络数据集的预先训练的权重来初始化各个分支。RGB和深度通道的输入通道数分别修改为3和1。对于深度分支,使用三个通道权值的平均值来初始化第一层中修改的卷积核的权值。在每个分支中,在密集层之后添加一个全局平均池化(GAP)层,以获得384维的词向量。将RGB和深度通道词嵌入连接起来形成联合嵌入层。全连接层跟一个sigmoid激活层被添加到每个嵌入的顶部,以形成框架中的不同头。在训练阶段,每个头部都由一个单独的损失函数进行监督。在测试时,来自RGB-D分支的得分被用作PAD分数。
2.2.2跨模型聚焦损失
有了单独的头后,就有可能训练出一个多通道模型,该模型能够在测试时处理丢失的通道情况。现在,监督这个网络的一个简单方法就是用二进制交叉熵损失(BCE)。
但是,在单通道中使用BCE可能并不理想。问题在于:我们可以将不同的通道视为同一样本的不同视图,对于某些攻击,仅从一个视图可能无法区分。当仅在一个通道中查看时,某些攻击的图像可能看起来非常像真实的样本。例如,当在深度通道中查看时,面部化妆看起来与真实样本的深度图完全相同。在这种情况下,用BCE监督深度通道分支的简单方法可能会导致过拟合。然而,在相同的场景中,在RGB和联合表示中,区分度将会很明显。从这个例子可以看出,单独地监督各个分支可能不会产生鲁棒的决策边界。解决该类问题的一种方法是利用当前分支和另一分支的预测概率来改变每个分支中样本的损失贡献。我们提出了一个跨模型的焦点损失函数来监督各个通道,它根据当前通道和备用通道的置信度来调节损失。
对于每个分支,样本可以在得分空间被很好分类。同时,我们鼓励各个分支在没有足够区分信息时产生不确定分数,而不是过度拟合训练数据中的某些统计偏差。但是,这些只有当其他分支能够完全正确分类样本时才适用。
更准确得讲,考虑一个二值分类问题中样本是多模型的,即每个样本是一对图像或特征集,这些图像或特征集捕获了具有互补信息的不同视图。现在假设分类问题不能单独用一个通道信息来解决(或者是一个非常困难的问题)。将两个通道的特征结合起来,并使用联合特征的学习策略可以提供一个解决方案。但是,这可能会导致过拟合,并且无法在测试阶段处理丢失的通道得情况。
如果我们在单独得分支上使用BCE,损失将严重影响那些无法用特定渠道的可用信息进行分类的样本。在这种情况下,模型可能开始过度拟合数据集中的偏差以最小化损失函数,从而导致模型过拟合。
为了避免这种情况,我们提出了跨模型焦点损失(CMFL)来监督各个通道。其核心思想是,当其中一个通道能够以高置信度正确地对样本进行分类时,则可以减少样本在另一个分支中的损失贡献。如果一个通道能够完全正确分类一个样本,那么我们就不希望另一个分支对模型进行更多的惩罚。CMFL迫使每个分支学习单个信道的鲁棒表示,然后可以与联合分支一起使用,有效地充当辅助损失函数。
松散化正确分类样本的损失贡献与目标检测问题中使用的焦点损失[23]类似。在焦点损失中,使用调制因子来减少由具有高置信度的正确分类的样本所造成的损失贡献。我们通过调整当前和备用支路中样本置信度的损失因子来实现相似的思想。
考虑二元分类问题中的交叉熵(CE)表达式:
C E ( p , y ) = { − l o g ( p ) if y=1 − l o g ( 1 − p ) if y=0 CE(p,y)= \begin{cases} -log(p)& \text{if y=1}\\ -log( 1-p)& \text{if y=0} \end{cases} CE(p,y)={
−log(p)−log(1−p)if y=1if y=0
其中 y ∈ { 0 , 1 } y∈\{0,1\} y∈{
0,1}表示类标签(y:0攻击,y:1真实), p ∈ [ 0 , 1 ] p∈[0,1] p∈[0,1]表示类的概率。我们遵循与[23]类似的符号pt,即目标类的概率:
p t = { p if y=1 1 − p otherwise p_t= \begin{cases} p& \text{if y=1}\\ 1-p& \text{otherwise} \end{cases} pt={
p1−pif y=1otherwise
这里 C E ( p , y ) = C E ( p t ) = l o g ( p t ) CE(p,y)=CE(pt)=log(pt) CE(p,y)=CE(pt)=log(pt)。在α-平衡形式中,CE损失可以写为:
C E ( p t ) = − α t l o g ( p t ) CE(p_t)=-\alpha_tlog(p_t)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1078
1078





 到【灌水乐园】发言
到【灌水乐园】发言







