







今天咱聊聊爬虫这玩意儿。爬虫,说白了,就是用程序自动抓取网页信息的工具。用Python写爬虫,上手快,用处广,兼职赚钱妥妥的。
兼职渠道+学习资料在文末!
兼职渠道+学习资料在文末!
##爬虫基础:从抓网页开始
你看,咱在浏览器里看到的网页,背后都是HTML代码。爬虫呢,就是把这些代码抓下来,再提取出我们需要的信息,比如商品价格、新闻标题啥的。
importrequests
url="https://www.example.com"
response=requests.get(url)
html=response.text
print(html)
这段代码,用requests库抓取了example.com的HTML代码,并打印出来。简单粗暴,有没有?
##解析网页:提取想要的信息
抓到HTML之后,咋从中提取信息呢?这就要用到解析库了,比如BeautifulSoup。
frombs4importBeautifulSoup
soup=BeautifulSoup(html,"html.parser")
title=soup.title.string
print(title)
这段代码,用BeautifulSoup解析了HTML,并提取了网页标题。soup.title.string这玩意儿,就像在HTML代码里按图索骥,找到title标签,然后把里面的文字抠出来。
##数据存储:别让数据跑了
提取到的信息,总得存起来吧?可以用文件存储,也可以用数据库。存CSV文件简单快捷:
importcsv
withopen("data.csv","w",newline="",encoding="utf-8")ascsvfile:
writer=csv.writer(csvfile)
writer.writerow(["标题",title])
这段代码,把网页标题写进了CSV文件。
##爬虫进阶:应对反爬机制
有些网站,为了防止被爬,会设置一些反爬机制。比如,限制访问频率、验证码啥的。这时候,咱就得见招拆招了。
用time库设置延时,可以避免访问太频繁:
importtime
time.sleep(2)#暂停2秒
温馨提示:反爬机制千奇百怪,遇到问题,多去网上搜搜,总有办法解决。
##兼职项目:爬取电商数据
电商平台,商品数据更新频繁,用爬虫抓取这些数据,然后卖给数据分析公司或者商家,能赚不少外快。
比如,爬取商品价格、销量、评论等等。当然,得注意,别爬取用户的隐私信息,遵守法律法规哈。
##爬取新闻资讯
新闻网站,资讯更新速度快,用爬虫抓取新闻,然后做成资讯聚合平台,或者卖给其他媒体,也是个不错的路子。
##温馨提示:注意robots.txt
有些网站,会在robots.txt文件中声明哪些页面可以爬,哪些页面不可以爬。咱得尊重人家的规矩,别乱爬。
##爬虫的道德和法律
爬虫虽然好用,但也要注意道德和法律。别爬取用户的隐私信息,别给网站造成过大的负担。爬虫的世界,水很深,但只要用心学,总能找到适合自己的兼职项目。
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
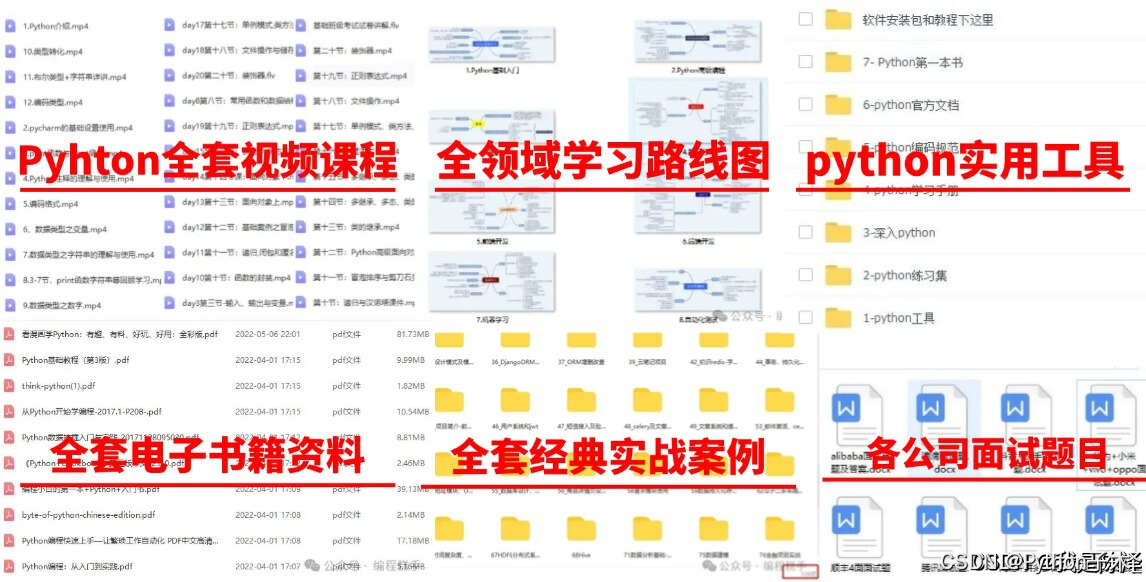
🌟 学习大礼包包含内容:
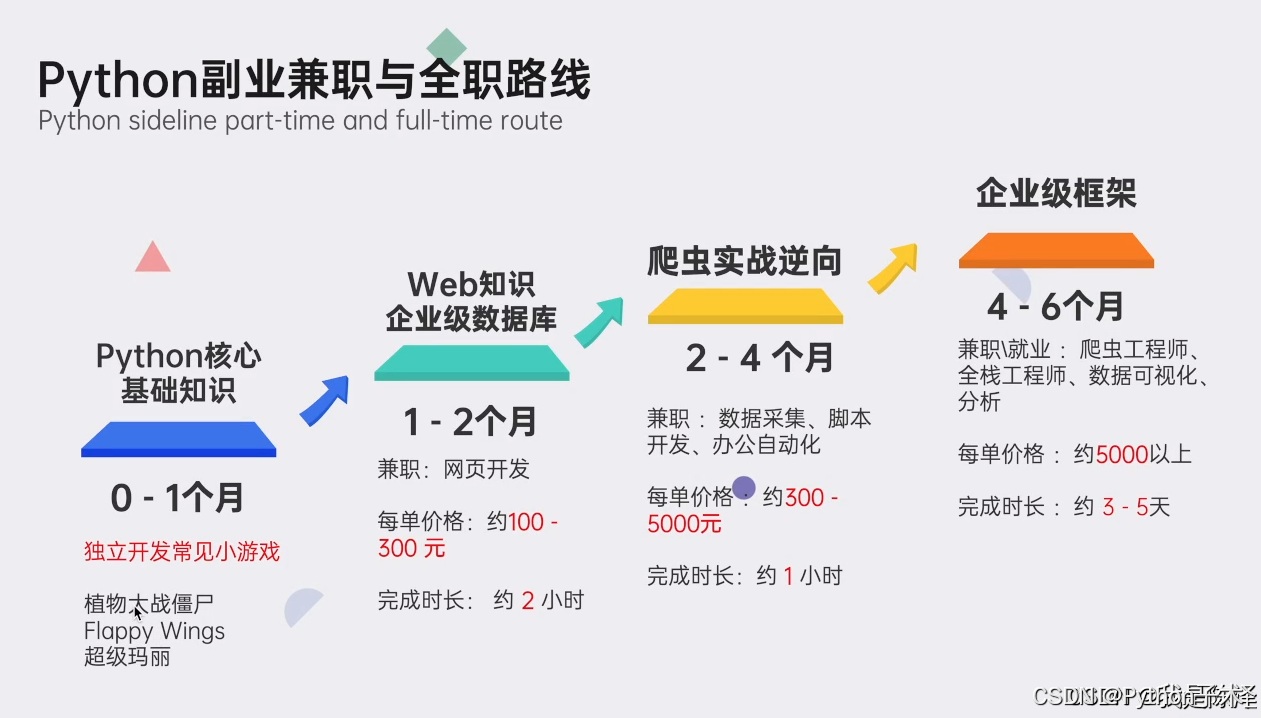
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能

















 1680
1680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









