







1. 使用Requests库快速发送HTTP请求
Requests库可以方便地发送HTTP请求,获取网页的HTML代码.这个库非常适合初学者快速入门.
import requests
def fetch_html(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
# 使用示例
html_content = fetch_html("https://example.com")
print(html_content[:500]) # 打印前500个字符
技巧解析:使用requests.get发送GET请求,通过response.status_code判断请求是否成功,再用response.text获取HTML内容.
学习资料+兼职渠道在文末!!
学习资料+兼职渠道在文末!!
2. 利用BeautifulSoup进行HTML解析
使用BeautifulSoup库可以轻松解析HTML结构,提取网页中的特定内容,如标题、文本、链接等.
from bs4 import BeautifulSoup
import requests
def parse_webpage(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
title = soup.find("title").text # 提取标题
return title
# 使用示例
title = parse_webpage("https://example.com")
print("网页标题:", title)
技巧解析:通过BeautifulSoup解析HTML,使用find或find_all方法获取标签内容.这里获取了网页标题(<title>标签内容).
3. 使用Selenium处理动态加载页面
有些网页内容是通过JavaScript动态加载的,Requests库无法获取.这时可以使用Selenium模拟浏览器操作,加载完整的网页.
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def fetch_dynamic_content(url):
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3) # 等待页面加载
content = driver.find_element(By.TAG_NAME, "body").text
driver.quit()
return content
# 使用示例
dynamic_content = fetch_dynamic_content("https://example.com/dynamic")
print(dynamic_content[:500])
技巧解析:使用Selenium打开页面并等待内容加载,再通过定位获取页面内容.
4. 设置User-Agent模拟真实浏览器
部分网站会限制自动化请求,可以通过设置User-Agent来模拟真实浏览器,避免被服务器屏蔽.
import requests
def fetch_html_with_headers(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
# 使用示例
html_content = fetch_html_with_headers("https://example.com")
print(html_content[:500])
技巧解析:在requests.get中设置headers参数,通过User-Agent伪装为普通浏览器用户.
5. 使用代理IP防止IP封禁
爬取频率较高时,可能会被网站封禁IP,使用代理可以有效绕过这一限制.
import requests
def fetch_html_with_proxy(url):
proxies = {
"http": "http://your_proxy_ip:port",
"https": "https://your_proxy_ip:port"
}
response = requests.get(url, proxies=proxies)
if response.status_code == 200:
return response.text
return None
# 使用示例(需要可用的代理IP)
# html_content = fetch_html_with_proxy("https://example.com")
# print(html_content[:500])
技巧解析:在requests.get中设置proxies参数,传入可用的代理IP,可以有效分散请求,避免IP被封禁.
6. 控制请求频率避免过度爬取
频繁的请求会触发反爬机制,适当延迟请求频率可以降低被封的风险.可以使用time.sleep控制请求间隔.
import requests
import time
def fetch_with_delay(url_list):
for url in url_list:
response = requests.get(url)
if response.status_code == 200:
print(f"成功爬取: {url}")
time.sleep(2) # 每次请求后等待2秒
# 使用示例
urls = ["https://example.com/page1", "https://example.com/page2"]
fetch_with_delay(urls)
技巧解析:在每次请求之间增加延时,避免过度爬取导致服务器封禁或返回错误.
7. 利用正则表达式提取信息
对于结构简单的数据,可以使用正则表达式(re库)直接从HTML提取需要的信息,速度较快.
import re
import requests
def extract_emails(url):
response = requests.get(url)
emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", response.text)
return emails
# 使用示例
emails = extract_emails("https://example.com")
print("提取到的邮箱:", emails)
技巧解析:re.findall可以快速从HTML文本中匹配特定格式的数据,比如邮箱、电话号码等.
以上就是Python快速上手爬虫的7大技巧,结合使用可以应对大多数常见的爬虫需求.希望这些示例和技巧能帮助你快速上手Python爬虫.
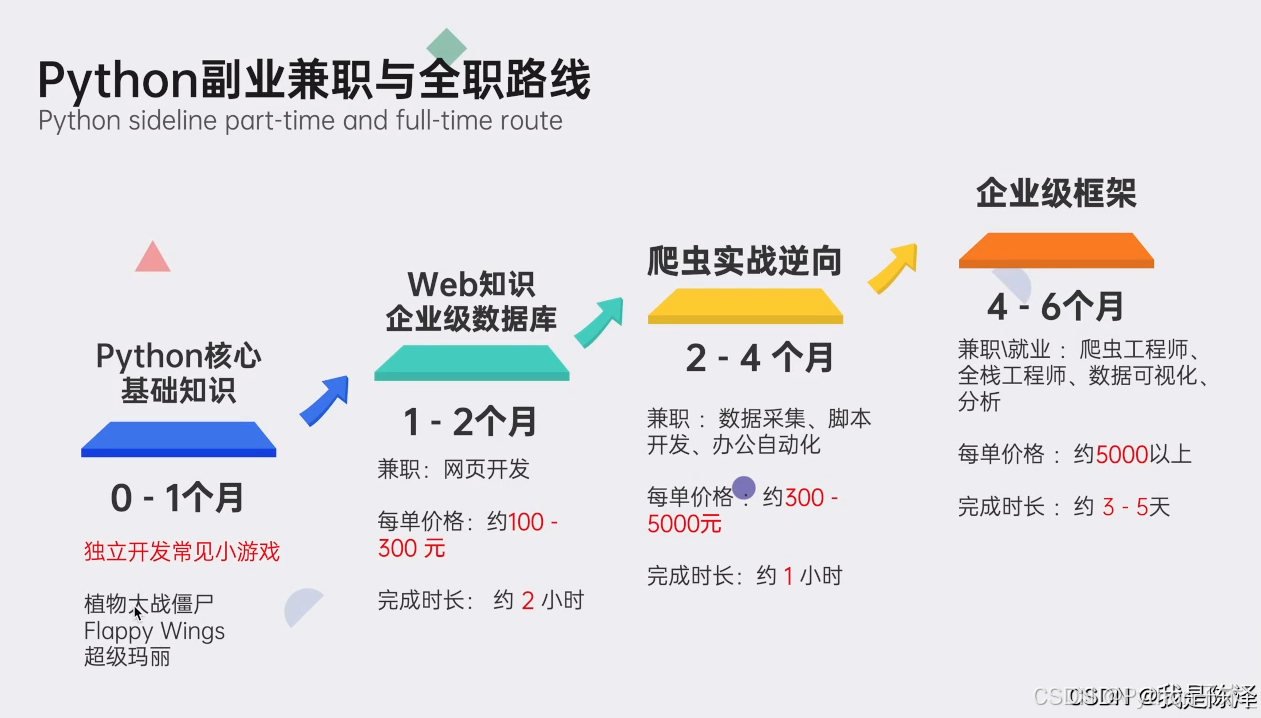
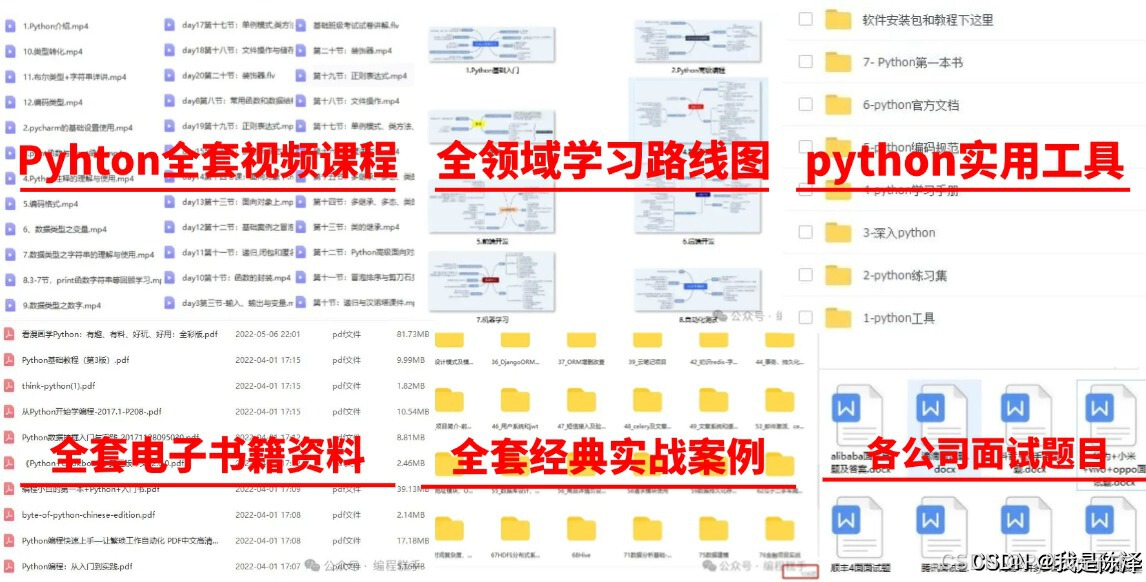
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
🌟 学习大礼包包含内容:
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









