







1 Python网页爬虫简介
Python是一种广受欢迎的编程语言,广泛应用于各类应用开发,网页爬虫开发也是其中之一。网页爬虫是一种自动化工具,它在互联网上进行数据搜集。Python拥有丰富的库和框架,使得构建网页爬虫变得相对简单。
网页爬虫的工作方式类似于人类浏览网页,它向网站发出请求,获取网页的HTML源码,然后分析这些代码以提取所需信息。Python的requests库和BeautifulSoup库是实现这一过程的关键组件。
一个典型的Python网页爬虫系统包括以下几个核心组件:
-
调度器(Scheduler):负责调度URL管理器、下载器、解析器之间的协调工作。
-
URL管理器(URL Manager):包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL。
-
网页下载器(Web Downloader):负责从互联网上下载网页的HTML代码。
-
网页解析器(Web Parser):负责解析网页的HTML代码,提取出所需的数据。
-
应用程序(Application):从网页中提取的有用数据组成的一个应用。
在开发Python爬虫时,开发者需要尊重网站的robots.txt文件,以确保不违反任何规定或造成网站负担。同时,也需要妥善处理网络异常和错误,保证爬虫的稳定性和可靠性。
综上所述,Python凭借其强大的库和工具,成为开发高效、稳定网页爬虫的理想选择,使开发者能够轻松地从互联网中抓取所需数据。
由于篇幅限制,如果你正在学习Python或者有计划学习Python,想要突破自我,对未来十分迷茫的,可以点击这里获取最新最完整的Python学习资料和学习路线规划(免费分享,记得关注)
2 爬虫实战
2.1 导入相关包
import requestsimport pandas as pdimport re
2.2 爬取时间范围及城市设置
months = [1,2,3,4,5,6,7,8,9,10,11,12]years = [2016,2017,2018,2019,2020,2021,2022,2023]citys = [59287]
此处城市代码选取‘59287’,实际操作可另选区域或多区域。
2.3 爬取信息设置
index_ = ['MaxTemp','MinTemp', 'WindDir', 'Wind', 'Weather','Aqi','AqiInfo','AqiLevel']# 选取的气象要素
2.4 天气信息抓取
data = pd.DataFrame(columns=index_) # 建立一个空dataframefor c in citys:for y in years:for m in months:# 找到json格式数据的urlif (y<2017) or (y==2017)&(m<=11):url = "http://tianqi.2345.com/t/wea_history/js/"+str(c)+"_"+str(y)+str(m)+".js" # ?qq-pf-to=pcqq.c2celse:url = "http://tianqi.2345.com/t/wea_history/js/"+str(y)+str(m).zfill(2)+"/"+str(c)+"_"+str(y)+str(m).zfill(2)+".js"print(url)response = requests.get(url=url)if response.status_code == 200: # 防止url请求无响应response2 = response.text.replace("'", '"') # 这一步可以忽略# 利用正则表达式获取各个气象要素(方法不唯一)date = re.findall("[0-9]{4}-[0-9]{2}-[0-9]{2}", response2)[:-2]mintemp = re.findall('yWendu:"(.*?)℃', response2)maxtemp = re.findall('bWendu:"(.*?)℃', response2)winddir = re.findall('fengxiang:"([\u4E00-\u9FA5]+)',response2)wind = re.findall('fengli:"([\u4E00-\u9FA5]+)',response2)weather = re.findall('tianqi:"([[\u4E00-\u9FA5]+)~?', response2)aqi = re.findall('aqi:"(\d*)',response2)aqiInfo = re.findall('aqiInfo:"([\u4E00-\u9FA5]+)',response2)aqiLevel = re.findall('aqiLevel:"(\d*)',response2)data_spider = pd.DataFrame([maxtemp,mintemp, winddir, wind, weather,aqi,aqiInfo,aqiLevel]).Tdata_spider.columns = index_ # 修改列名data_spider.index = date # 修改索引data = pd.concat((data,data_spider), axis=0) # 数据拼接print('%s年%s月的数据抓取成功' % (y, m))else:print('%s年%s月的数据不存在' % (y, m))break
2.4 结果存储
data.to_excel('D:\\天气数据可视化\\天气数据可视化.xlsx')print('爬取数据展示:\n', data)
2.5 效果展示
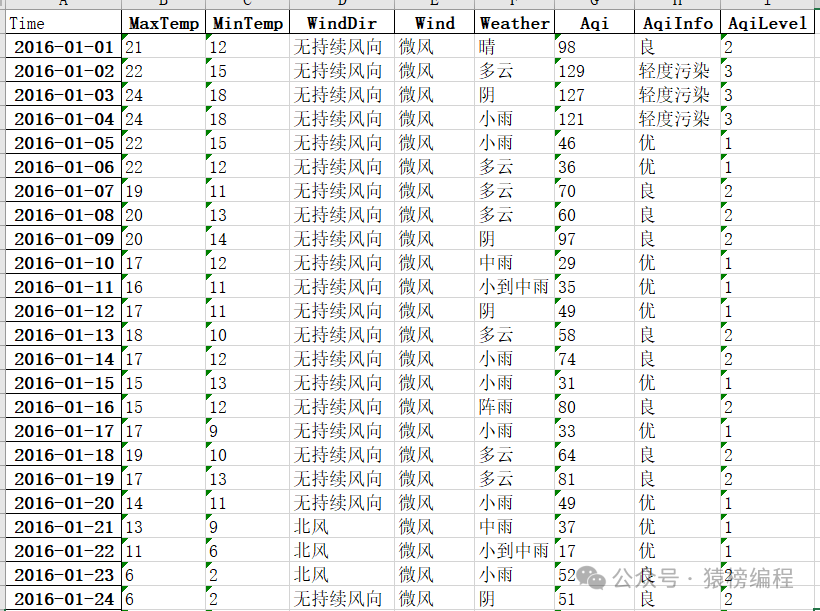
3 完整代码
由于篇幅有限,完整代码需要点击这里自行获取
另外
我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
🌟 学习大礼包包含内容:
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能


















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









