 Python基础数据结构详解与学习福利
Python基础数据结构详解与学习福利








Python的数据结构简单强大,理解它们对日后使用Python大有裨益。
我们先从简单,也是最常用到的的序列类型开始: 元组 tuple、列表 list 和 字典 dictionary。
这里插播一条粉丝福利,如果你正在学习Python或者有计划学习Python,想要突破自我,对未来十分迷茫的,可以点击这里获取最新的Python学习资料和学习路线规划(免费分享,记得关注)
01 列表 List
列表(List)是 长度可变、内容可变 的,用于存储 多个元素 的 有序集合。
列表可以随意添加、删除或修改其中的元素。列表用来存储一组相同或不同类型的元素,非常灵活,适合各种数据操作需求。
使用方括号 [] 或 list 创建列表。
列表的特点:
-
可变:列表中的元素可以随时被修改、增加或删除。
-
有序:列表中的元素是按照顺序排列的,因此可以通过索引访问指定位置的元素。
-
支持多种数据类型:列表中的元素可以是数字、字符串、列表、字典,甚至是其他列表等。
-
创建方式:使用方括号 [] 或 list 定义列表,元素之间用逗号分隔。例如:my_list = [1, "hello", 3.5]
用代码可以更直观地了解。
-
创建列表:
In [42]: a_list = [2, 3, 7, None] # 创建listIn [43]: tup = ("foo", "bar", "baz") # 创建tupleIn [44]: b_list = list(tup) # 强制转换类型:tupleIn [45]: b_list # 转换成listOut[45]: ['foo', 'bar', 'baz']In [46]: b_list[1] = "peekaboo" # 根据索引提取列表元素In [47]: b_listOut[47]: ['foo', 'peekaboo', 'baz']
list 常用在数据处理过程中,如想要生成一个可迭代的对象:
In [48]: gen = range(10)In [49]: genOut[49]: range(0, 10)In [50]: list(gen)Out[50]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
-
添加 或 删除 列表中的元素:
我们可以通过 append 在list的 末尾 添加元素:
In [51]: b_list.append("dwarf")In [52]: b_listOut[52]: ['foo', 'peekaboo', 'baz', 'dwarf']
还可以通过 insert 在 特定 的位置添加元素:
In [53]: b_list.insert(1, "red") # .insert(index, element)In [54]: b_listOut[54]: ['foo', 'red', 'peekaboo', 'baz', 'dwarf']
使用 insert 的时候要注意,索引必须在 [0, length(list)) 的范围内。
反之,与 insert 对应的是 pop,用来删除 特定位置 的元素:
In [55]: b_list.pop(2) # .pop(index)Out[55]: 'peekaboo'In [56]: b_listOut[56]: ['foo', 'red', 'baz', 'dwarf']
此外,remove 也可用于删除元素,remove 会删除 匹配到的第一个 元素:
In [57]: b_list.append("foo")In [58]: b_listOut[58]: ['foo', 'red', 'baz', 'dwarf', 'foo']In [59]: b_list.remove("foo")In [60]: b_listOut[60]: ['red', 'baz', 'dwarf', 'foo']
-
判断是否包含元素:
检查 list 中是否包含特定元素可以用 in :
In [61]: "dwarf" in b_listOut[61]: True
与之相对的,判断 list 不包含特定元素可以用 not in:
In [62]: "dwarf" not in b_listOut[62]: False
这里要注意一点,Python通过从头开始的线性检索来判断list中(不)包含某元素,当list较大时运行速度较慢。
-
合并列表:
可以用 extend :
In [64]: x = [4, None, "foo"]In [65]: x.extend([7, 8, (2, 3)])In [66]: xOut[66]: [4, None, 'foo', 7, 8, (2, 3)]
还记得字符串吗?我们用 + 连接字符串,同样的,对 list 的 连接 也可以用 + :
In [76]: [4, None, "foo"] + [7, 8, (2, 3)]Out[76]: [4, None, 'foo', 7, 8, (2, 3)]In [77]: x + [7, 8, (2, 3)]Out[77]: [4, None, 'foo', 7, 8, (2, 3)]
值得注意的是,extend 要比 + 快上许多,因为 extend 方法会直接将元素添加到现有列表中,而 + 需要先创建一个新的列表,将对象复制过去。所以,当数据量较大时,更推荐使用 extend 。
-
列表排序:
你可以通过 sort 来对列表排序:
In [67]: a = [7, 2, 5, 1, 3]In [68]: a.sort()In [69]: aOut[69]: [1, 2, 3, 5, 7]
sort 还包含一些很实用的参数,这里我们先了解 key ,我们可以通过赋值 key 来使用某种特定方式进行排序。如通过字符长度排序:
In [70]: b = ["saw", "small", "He", "foxes", "six"]In [71]: b.sort(key=len) # 通过字符长度排序In [72]: bOut[72]: ['He', 'saw', 'six', 'small', 'foxes']
-
列表切片(slicing):
你可以使用 切片 来 提取 大多数序列类型(如 list 和下文的元组) 的 部分序列,切片 的基本形式为 [start:stop] :
In [73]: seq = [7, 2, 3, 7, 5, 6, 0, 1]In [74]: seq[1:5]Out[74]: [2, 3, 7, 5]
也可以用来 修改(重新赋值)序列中的片段:
In [75]: seq[3:5] = [6, 3]In [76]: seqOut[76]: [7, 2, 3, 6, 3, 6, 0, 1]
如Python中的其他数字索引,这里的参数也为 [start,stop),即 stop索引是不包含在内的。
可以省略 start 或 stop ,在这种情况下,它们分别默认为序列的开始和结束:
In [77]: seq[:5] # 从头开始到index=4Out[77]: [7, 2, 3, 6, 3]In [78]: seq[3:]Out[78]: [6, 3, 6, 0, 1] # 从index=3开始到序列末尾
当你使用 负数 ,意味着将序列 倒序 进行切片:
In [79]: seq[-4:]Out[79]: [3, 6, 0, 1]In [80]: seq[-6:-2]Out[80]: [3, 6, 3, 6]
我们可以借用这张图来帮助理解 Python中的索引:
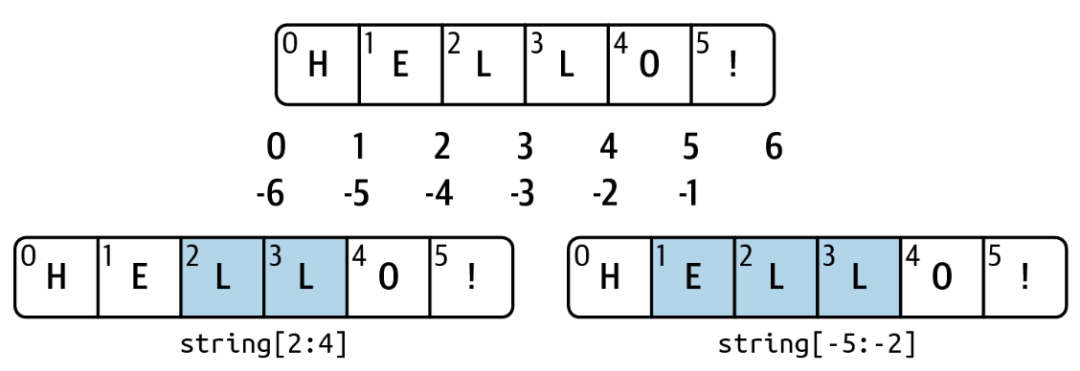
如果大家更熟悉R或MATLAB,也许会对Python中的索引和语法有一些不太习惯,没关系,我们可以通过反复接触来一点一点习惯Python的特点。
step 位于第二个冒号后,可以用来决定步数:
In [81]: seq[::2]Out[81]: [7, 3, 3, 0]
想要翻转整个list呢,我们也可以直接通过 -1 来执行:
In [82]: seq[::-1]Out[82]: [1, 0, 6, 3, 6, 3, 2, 7]
关于列表我们先了解到这里。
下面介绍一个与列表十分相似、在许多函数和使用中会互相转换的数据类型 ———— 元组。
02 元组 Tuple
元组(Tuple)是 固定长度、不可改变 的Python序列。元组 可以有序 储存 多个 多种类型 的元素。
它与列表类似,但与可以修改的列表不同,元组一旦创建后就不可更改,因此,元组适合存储不希望被修改的数据。
元组的特点:
-
不可变:元组一旦定义,其内容无法更改(无法增加、删除或修改元素)。
-
有序:元组中的元素是按顺序存储的,因此支持索引操作,可以通过索引访问特定位置的元素。
-
支持多种数据类型:元组中的元素可以是不同的数据类型,例如数字、字符串、列表、甚至是其他元组。
-
创建方式:使用小括号 () 或 tuple定 义元组,元素之间用逗号分隔。例如:my_tuple = (1, "hello", 3.5)
如果元组不可变,不是很难用吗?那我们为什么要使用元组?
“
元组的不可变性提供了数据的安全性,适合在不希望数据被意外更改的场景中使用。
常见的应用场景包括:
①存储固定的数据集,例如坐标 (x, y),日期 (year, month, day)。
②用于函数返回多个值。
③元组还可以作为字典的键(因为它是不可变的),而列表则不行。(后续介绍字典时再讲)
”
完整学习籽料:点击这里下载
-
创建元组:
In [2]: tup = (4, 5, 6)In [3]: tupOut[3]: (4, 5, 6)
在一些场合中,()甚至是可以省略的:
In [4]: tup = 4, 5, 6In [5]: tupOut[5]: (4, 5, 6)
我们也可以用 tuple 来进行强制转换:
In [6]: tuple([4, 0, 2])Out[6]: (4, 0, 2)In [7]: tup = tuple('string')In [8]: tupOut[8]: ('s', 't', 'r', 'i', 'n', 'g')
当你想用定义更复杂的元组,要弄清楚每个 () 意味着什么:
In [10]: nested_tup = (4, 5, 6), (7, 8)In [11]: nested_tupOut[11]: ((4, 5, 6), (7, 8))In [12]: nested_tup[0]Out[12]: (4, 5, 6)In [13]: nested_tup[1]Out[13]: (7, 8)
虽然元组中存储的对象本身可能是可变的,但是一旦元组被创建,就不可能修改存储在每个位置中的整个对象元素:
In [14]: tup = tuple(['foo', [1, 2], True])In [15]: tup[2] = False---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-15-b89d0c4ae599> in <module>----> 1 tup[2] = FalseTypeError: 'tuple' object does not support item assignment
如果元组中的一个对象是可变的,比如一个列表,你可以在其内部修改它:
In [16]: tup[1].append(3)In [17]: tupOut[17]: ('foo', [1, 2, 3], True)
你也可以通过 + 来添加新的元素:
In [18]: (4, None, 'foo') + (6, 0) + ('bar',)Out[18]: (4, None, 'foo', 6, 0, 'bar')
甚至可以通过 * 来扩增该元组(列表同样也可以):
In [19]: ('foo', 'bar') * 4Out[19]: ('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar')
这里注意一点,对象本身不是复制的,只是对它们的引用。
-
解压元组:
如果你尝试使用类似元组的表达式来赋值给变量,Python 会按照元组里的元素逐个赋值你提供的变量,这个过程可以看做是将解压缩等号右侧的值:
In [20]: tup = (4, 5, 6)In [21]: a, b, c = tup # 一一对应赋值In [22]: bOut[22]: 5In [23]: tup = 4, 5, (6, 7)In [24]: a, b, (c, d) = tup # 一一对应赋值In [25]: dOut[25]: 7In [26]: a, b = 1, 2In [27]: aOut[27]: 1In [28]: bOut[28]: 2In [29]: b, a = a, b # 快速互换变量名In [30]: aOut[30]: 2In [31]: bOut[31]: 1
一个常见的应用是迭代元组或列表中的元素以赋值变量:
In [32]: seq = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]In [33]: for a, b, c in seq:....: print(f'a={a}, b={b}, c={c}')a=1, b=2, c=3a=4, b=5, c=6a=7, b=8, c=9
某些情况下,你也许只想从一个元组里“挑”出几个前面的元素。Python 有一种特别的写法可以做到这一点,就是 *rest (或 *var_name, 如*noused),它也会在函数参数中用来接收任意长度的参数列表:
In [34]: values = 1, 2, 3, 4, 5In [35]: a, b, *rest = valuesIn [36]: aOut[36]: 1In [37]: bOut[37]: 2In [38]: restOut[38]: [3, 4, 5]
在上面的例子中,我们把前两个元素赋给了 a 和 b,然后把剩下的元素都放到了 rest 里面。
有时候,rest 里可能是一些你不需要的值。此时,你可以用 _ (下划线)来代替 rest,这在 Python 中是一种约定俗成的做法,表示不需要的变量:
In [83]: a, b, *_ = valuesIn [84]: _Out[84]: [3, 4, 5]
这样写可以更清晰地表达意图:我们只关心 a 和 b,其余的内容都不重要。
由于元组的大小和内容都不能修改,它的内建方法很少,但有一个非常实用的方法(在列表中也有)叫做 count。它可以用来统计某个值在元组中出现的次数:
In [40]: a = (1, 2, 2, 2, 3, 4, 2)In [41]: a.count(2)Out[41]: 4
03 字典 Dictionary
Python中的字典(dictionary)或 dict 是一种数据结构,用来储存键值对(key-value pairs)。
你可以把它想象成一本词典:每个单词(键)都有对应的解释(值)。在Python中,字典用大括号 {} 表示,每对键和值用冒号 : 分隔,多个键值对之间用逗号隔开。
以下是一个简单的字典示例:
student = {"name": "Alice","age": 20,"major": "Biology"}
在这里:
"name" 是键,对应的值是 "Alice"
"age" 是键,对应的值是 20
"major" 是键,对应的值是 "Biology"
字典的特点是:
-
键唯一:字典中的键不能重复。
-
快速查找:根据键快速找到对应的值。
-
可变:可以添加、修改或删除键值对。
下面介绍一些常用的关于字典的操作和应用。
-
获取所有键、所有值和所有键值对:
获取所有键:用 keys() 方法返回一个包含字典所有键的视图对象。
获取所有值:用 values() 方法返回一个包含字典所有值的视图对象。
获取所有键值对:用 items() 方法返回一个包含所有键值对的视图对象,每个键值对都是一个元组。
student = {"name": "Alice", "age": 20, "major": "Biology"}# 获取所有键print(student.keys()) # 输出:dict_keys(['name', 'age', 'major'])# 获取所有值print(student.values()) # 输出:dict_values(['Alice', 20, 'Biology'])# 获取所有键值对print(student.items()) # 输出:dict_items([('name', 'Alice'), ('age', 20), ('major', 'Biology')])
-
检查键是否在字典中:
如tuple和list,字典也可以通过 in 来检查某个键是否在其中:
if "age" in student:print("年龄信息已存在")else:print("年龄信息不存在")
-
默认值获取:
使用 get() 方法在查找键时可以设置一个默认值,如果键不存在则返回默认值。
print(student.get("grade", "无成绩信息")) # 输出:无成绩信息-
添加或更新多个键值对:
使用 update() 方法可以同时添加或更新多个键值对:
additional_info = {"grade": "A", "year": 2024}student.update(additional_info)print(student)# 输出:{'name': 'Alice', 'age': 20, 'major': 'Biology', 'grade': 'A', 'year': 2024}
-
删除键值对:
用 del 删除指定键的值:
del student["age"]print(student) # 'age'键被删除
用 pop() 删除并返回指定键的值:
age = student.pop("age", "无此信息")print(age) # 输出:20print(student) # 'age'键被删除
用 popitem() 删除并返回最后一个键值对:
last_item = student.popitem()print(last_item) # 输出:('year', 2023)print(student) # 'year'键被删除
-
根据序列创建字典:
mapping = {}for key, value in zip(key_list, value_list):mapping[key] = value
由于 dictionary 本质上是两个元组的集合,因此 dict() 函数接受一个由两个元组组成的列表:
In [104]: tuples = zip(range(5), reversed(range(5)))In [105]: tuplesOut[105]: <zip at 0x17d604d00>In [106]: mapping = dict(tuples)In [107]: mappingOut[107]: {0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
-
字典推导式:
字典推导式可以用于快速创建或转换字典。以下是生成包含数字及其平方的字典:
squares = {x: x**2 for x in range(1, 6)}print(squares) # 输出:{1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
-
合并字典:
在Python 3.9+ 中,可以用 | 运算符合并字典。
student = {"name": "Alice", "age": 20}additional_info = {"major": "Biology", "grade": "A"}merged = student | additional_infoprint(merged)# 输出:{'name': 'Alice', 'age': 20, 'major': 'Biology', 'grade': 'A'}
04 集合 Set
同样也是用 {} 围起来的序列,集合与字典不同,集合是 非重复元素(unique)的无序集合。可以用 {} 或 set 定义:
In [124]: set([2, 2, 2, 1, 3, 3])Out[124]: {1, 2, 3}In [125]: {2, 2, 2, 1, 3, 3}Out[125]: {1, 2, 3}
还记得操作符吗?在集合的运算中,我们可以复习一下操作符的使用。
我们来创建两个集合:
In [126]: a = {1, 2, 3, 4, 5}In [127]: b = {3, 4, 5, 6, 7, 8}
首先,我们可以用 union 或 | 对两个集合取并集:
In [128]: a.union(b)Out[128]: {1, 2, 3, 4, 5, 6, 7, 8}In [129]: a | bOut[129]: {1, 2, 3, 4, 5, 6, 7, 8}
其次,我们可以用 intersection 或 & 对两个集合取交集:
In [130]: a.intersection(b)Out[130]: {3, 4, 5}In [131]: a & bOut[131]: {3, 4, 5}
此外,下表还列举了一些Python中常用的集合操作功能:
| 函数 | 替换语法 | 描述 |
|---|---|---|
| a.add(x) | N/A | 添加 x 到集合 a |
| a.clear() | N/A | 清空集合 a |
| a.remove(x) | N/A | 去除集合 a 中的 x 元素 |
| a.pop() | N/A | 从集合 a 中删除任意元素,如果集合为空,则引发 KeyError |
| a.union(b) | a | b | 取并集 |
| a.update(b) | a |= b | 将 a 重新设置为 a 和 b 中元素的并集 |
| a.intersection(b) | a & b | 取交集 |
| a.intersection_update(b) | a &= b | 将 a 重新设置为 a 和 b 中元素的交集 |
| a.difference(b) | a - b | a 中不在 b 中的元素 |
| a.difference_update(b) | a -= b | 将 a 设置为 a 中不在 b 中的元素 |
| a.symmetric_difference(b) | a ^ b | a 或 b 中的所有元素,但不能同时包含 |
| a.symmetric_difference_update(b) | a ^= b | 设置 a 为包含在 a 或 b 中的元素,但不同时包含 |
| a.issubset(b) | a <= b | 如果 a 的元素都包含在 b 中,则为 True |
| a.issuperset(b) | a >= b | 如果 b 的元素都包含在 a中,则为 True |
| a.isdisjoint(b) | N/A | 如果 a 和 b 没有共同的元素,则为 True |
如果将不是集合的输入传递给 union 和 intersection 等方法,Python 将在执行操作之前将输入转换为集合。在使用二进制运算符(即表中的替换语法)时,两个对象都必须已经设置为集合。
当且仅当集合的内容相等时,集合才相等:
In [144]: {1, 2, 3} == {3, 2, 1}Out[144]: True
一定要注意,集合是无序的,不支持索引操作。例如 `my_set[0]` 会引发错误。
Practice
1. 创建一个包含整数的列表 numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9],按以下要求操作:
将数字 10 添加到列表末尾。
删除列表中的第一个元素。
反转列表并打印结果。
2. 使用切片操作从列表中提取子序列。 给定 letters = ["a", "b", "c", "d", "e", "f", "g", "h", "i"],按以下要求提取内容:
提取前三个元素。
提取从第四个元素开始到最后的元素。
提取索引为偶数位置的元素。
3.创建一个元组 coordinates = (10, 20, 30, 40, 50) 并按以下要求操作:
解压元组的第一个元素赋值给变量 x,第二个元素赋值给 y,剩下的元素赋值给 rest。
输出 x, y, 和 rest。
4. 创建嵌套元组 nested = ((1, 2, 3), (4, 5, 6), (7, 8, 9)),并按以下要求操作:
使用 for 循环迭代嵌套元组中的每个子元组。
对每个子元组解压出三个元素并打印。
5. 创建一个字典 student = {"name": "Alice", "age": 22, "major": "Physics"},按以下要求操作:
获取并打印学生的 name。
添加一个键值对 "grade": "A"。
更新 "age" 的值为 23。
删除键 "major",然后打印字典内容。
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
🌟 学习大礼包包含内容:
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









