




 本文解释了C/C++程序中的进程地址空间概念,包括为何需要地址空间、其结构和管理方式,以及虚拟地址如何转换为物理地址。重点讨论了地址空间在保护进程独立性、内存管理解耦和大型程序内存优化中的作用,以及malloc机制背后的缺页中断原理。
本文解释了C/C++程序中的进程地址空间概念,包括为何需要地址空间、其结构和管理方式,以及虚拟地址如何转换为物理地址。重点讨论了地址空间在保护进程独立性、内存管理解耦和大型程序内存优化中的作用,以及malloc机制背后的缺页中断原理。
我们用c语言写的程序,经过编译后形成可执行程序存放在硬盘。当运行该程序时,操作系统将该程序加载到内存中,创建进程控制块,变为进程,然后开始执行该程序。大家是否想过,操作系统是如何加载的呢;我们在程序中使用的地址,是否是内存地址呢;当程序所占空间大于内存时,又该如何,比如游戏100G,内存只有16G;这一切的答案都在进程地址空间中,下面我拿c/c++的程序地址空间来举例。
一.为什么要有程序地址空间呢?
如果没有进程地址空间,程序直接载入内存,这样就无法保证进程独立性。因为c语言的野指针问题,当内存暴露于程序当中,这样程序员就可以用指针随意访问内存,这样造成的危害是巨大的。故此,产生了进程地址空间。此时,程序看到的空间不是内存,使用的地址也不是内存地址,而是虚拟地址。于是,也就不存在访问其他进程的情况,保证了进程间独立性。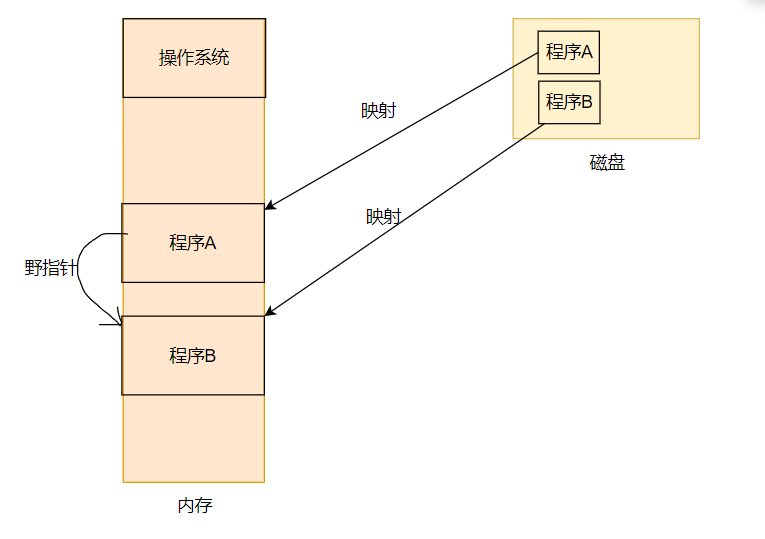
二.什么是进程地址空间?
2.1 进程地址空间概念
进程地址空间,即虚拟地址空间。一个进程运行时,它所认为自己管理的空间就是虚拟地址空间,一个进程地址空间的大小取决于计算机系统架构,比如32位机,进程地址空间为4GB。
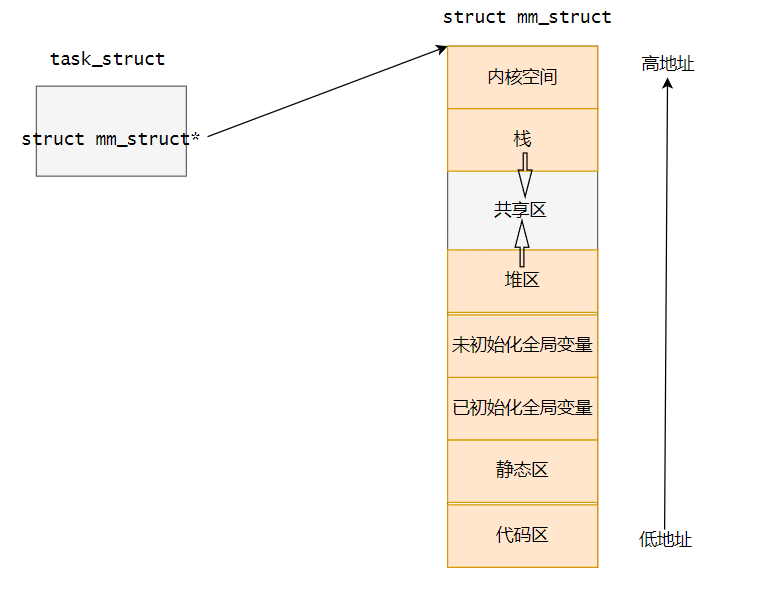
2.2 c/c++进程地址空间的区域划分

2.3 进程地址空间的管理
在Linux中,需要对每个进程的进程地址空间进行管理,怎么管理?先描述再组织。进程地址空间本质Linux内核中的一个数据结构struct mm_struct{},对于每一个进程,都有自己的mm_struct,且其大小都一样,32位下都是4GB,4GB是进程可管理空间的大小。Linux中进程控制块task_struct中有一个成员指针,指向自己的进程地址空间。
//内核中大致是这样描述进程地址空间的
struct mm_struct()
{
long code_start;
long code_end;
long brk_start;
long brk_end;
long init_start;
long init_end;
//.....
}
1.4 虚拟地址到物理地址
我们的程序在编译时,编译器就按照程序地址空间的方式对程序进行划分,为代码和数据分配好了空间,这种文件的格式就是ELF格式。在程序中的每一条指令都有自己的地址,这个地址就是虚拟地址,在Linux中可以使用objdump -S file 进行反汇编查看。
当操作系统加载程序时,要为每一个程序创建task_struct,mm_struct ,页表…,而页表可以实现从虚拟地址转换为物理地址。每一个进程的入口地址(虚拟地址)是规定的,cpu通过入口地址经过页表转换为访问物理地址,同时读取物理地址空间的内容,即第一条指令。下面的页表只是一种简化情况,真实页表还有许多字段,比如权限位等等。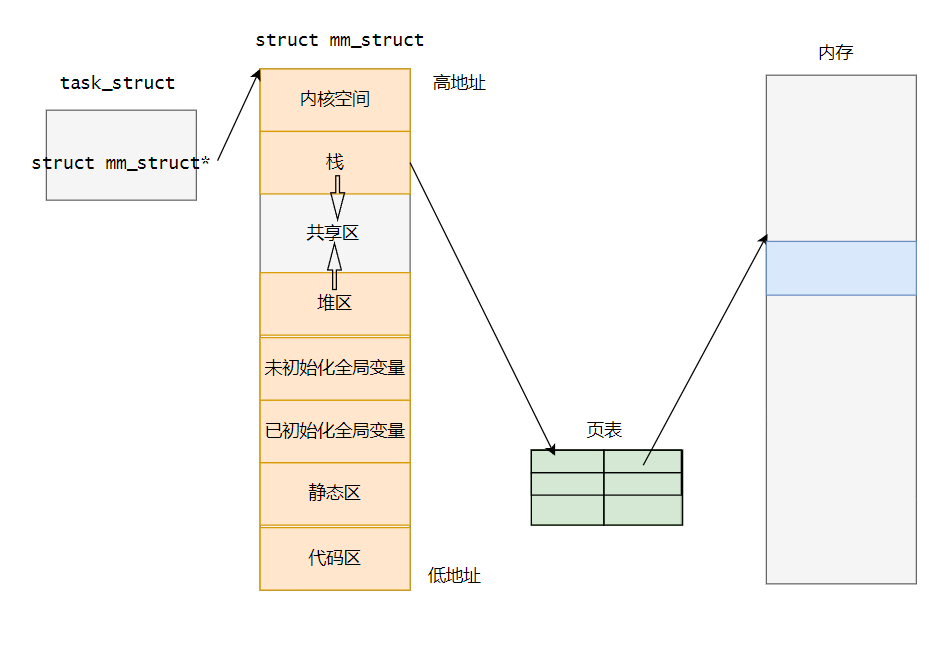
三.进程地址空间的作用
- 防止一个进程内部的指针随意访问,保护物理内存和其他进程。
如果没有虚拟地址空间,那么我们每个进程都是直接访问物理内存的,如果一个进程中出现了错误,导致访问了别的进程中的数据,这样就无法保证进程之间的独立性
- 将进程管理和内存管理进行解耦合
使程序员只需要关心自己程序而不用关心内存方面,可以大大增加开发的效率。因为程序员看到的是虚拟地址,而不是内存地址。
- 不用将一个大型程序一次载入内存,只要载入用到的部分即可
100G游戏,可能只会用到一部分功能,而其他功能的代码和数据不用载入内存,可以更好的利用内存。
- malloc相关
malloc之后,操作系统并不会立即分配空间,因为操作系统追求高效,当你使用该块空间的时候,继而为你开辟空间,怎么实现这样机制呢?使用的是缺页中断,即:将页表中只分配虚拟内存,等程序用该块空间的时候,分配物理内存,并且填充页表,建立完整映射关系。而这种方式得益于虚拟地址空间。

















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









