



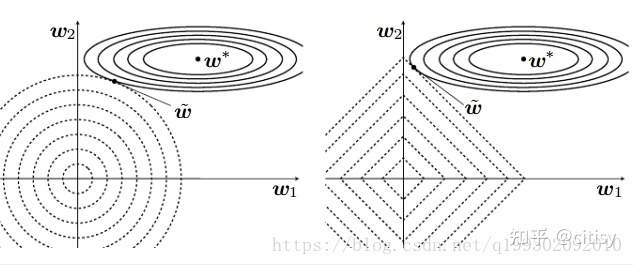
 正则化是防止模型过拟合的重要手段,L1和L2正则是两种常见的正则化技术。L1正则通过引入权重向量的绝对值和,倾向于产生稀疏权重,使模型不依赖特定特征。L2正则则通过引入权重平方和,避免权重过大,保持所有特征的影响。在等高线图中,L1正则倾向于产生坐标轴上的解,而L2正则则使权重更接近于零但不为零。选择合适的正则化方式能有效平衡模型的复杂度和泛化能力。
正则化是防止模型过拟合的重要手段,L1和L2正则是两种常见的正则化技术。L1正则通过引入权重向量的绝对值和,倾向于产生稀疏权重,使模型不依赖特定特征。L2正则则通过引入权重平方和,避免权重过大,保持所有特征的影响。在等高线图中,L1正则倾向于产生坐标轴上的解,而L2正则则使权重更接近于零但不为零。选择合适的正则化方式能有效平衡模型的复杂度和泛化能力。
以L1 或者 L2 正则,约束模型参数到(0,0,0,0,0,0,……)的距离
使得模型不会过分依赖于某一个参数项,从而导致样本输入以后,过度依赖某一特征,造成模型过拟合
作图为L1正则,右图为L2正则, 可以看出,在对于模型loss等高线,同一个高度下,w1和w2有很多种选择,但是有的选择会使他们对应的点 到(0,0,0,0,0,0,……)的距离变远,从而使得正则项loss变大,总体loss变大。而当模型loss等高线同正则项loss等高线,相切时 ,二者对应的loss和最小,否则同样大的模型自身loss,会搭配上一个更大的正则项loss,导致最终总体loss变大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









