



文章目录
基本
cpp中引用与指针的区别
- 初始化:
- 访问方式:
- 内存占用:
-----------|---------------------------------|-----------------
总结表
| 特性 | 指针 | 引用 |
|---|---|---|
| 初始化 | 可延迟或为 nullptr | 必须初始化且不可更改 |
| 访问方式 | 需解引用(*ptr) | 直接使用(ref) |
| 内存占用 | 存储地址(4/8 字节) | 通常无额外开销 |
| 可否为空 | yes | 必须指定对象 |
| 可否重新绑定 | yes | no |
| 多级支持 | yes | no |
| 典型用途 | 动态内存,可选参数 | 函数参数,操作符重载 |
const的用途
在 C++ 中,const 是一个关键修饰符,用于声明不可修改的常量或限制访问权限。它的核心用途包括:定义常量、保护数据不被意外修改、优化代码性能(编译器可进行更多优化),以及支持常量正确性(const-correctness)提高代码安全性。以下是 const 的详细用途和示例:
总结表
| 用途 | 实例 | 作用 |
|---|---|---|
| 定义常量 | 防止变量被修改 | |
| 修饰指针 | 指针指向数据不可修改 | |
| 修饰函数参数 | 防止函数修改参数 | |
| 修饰成员函数 | 表示函数不能修改对应的对象状态 | |
| 修饰返回值 | 防止返回值被修改 |
静态成员和静态函数
定义与特点
- 静态变量属于类本身,而非类的某个实例。无论创建多少个对象,静态变量在内存中只有一份副本。
通过 static 关键字声明(如 static int count;)。 - 在类加载时初始化(如果未显式初始化,默认值为 0/``/false)。
- 静态函数属于类,而非实例。可直接通过类名调用(如 ClassName.staticMethod())。
- 通过 static 关键字声明(如 static void print() { … })。
- 不能直接访问非静态成员(实例变量或方法),因为静态方法不依赖对象。
关键点
- 共享性:所有对象共享同一静态变量,修改它会反映到所有实例中。
- 生命周期:从类加载开始存在,直到程序结束(存储在方法区)。
- 访问方式:可直接通过类名访问(如 ClassName.staticVar),也可通过对象访问(但不推荐)。
- 无对象依赖:无需创建对象即可调用。
- 工具方法:常用于封装与对象状态无关的通用逻辑(如数学计算、工厂方法)。
- 限制:不能使用 this 或 super,也不能直接访问非静态成员。
用途
- 记录与类相关的全局状态(如计数器、配置信息)。
- 实现单例模式中的唯一实例。
- 工具类中的常量(如 Math.PI)。
- 工具类方法(如 Collections.sort())。
- 工厂方法(如 LocalDate.now())。
- 辅助函数(如日志记录、数据校验)
静态变量和实例变量的初始化顺序
静态变量在类加载时初始化,实例变量在对象创建时初始化。静态块优先于实例块执行。
为什么静态方法不能调用非静态成员?
静态方法调用时可能不存在对象(如直接通过类名调用),而非静态成员必须依赖对象存在
类和对象
构造函数不能 是虚函数,而析构函数能是虚函数。
在C++中,构造函数不能是虚函数,但析构函数可以是虚函数,且通常建议将基类的析构函数声明为虚函数。
构造函数不能是虚函数的原因:
-
对象生命周期阶段限制:
- 虚函数机制依赖于虚函数表(vtable),而虚函数表是在构造函数执行过程中逐步建立的。
- 在构造函数执行期间,对象的类型尚未完全确定,此时调用虚函数无法实现预期的多态行为。
-
设计逻辑矛盾:
- 构造函数的目的是初始化对象,而虚函数的存在意义在于允许派生类重写基类函数。
- 在构造函数调用时,对象尚未构造完成,此时调用虚函数无法确定应该调用哪个版本的函数,因为派生类部分可能尚未初始化。
析构函数可以是虚函数的原因:
-
确保正确析构顺序:
- 当通过基类指针删除派生类对象时,如果基类析构函数不是虚函数,只会调用基类的析构函数,而不会调用派生类的析构函数。
- 这可能导致派生类对象中分配的资源(如动态内存、文件句柄等)未被正确释放,造成资源泄漏。
-
实现多态析构:
- 将基类的析构函数声明为虚函数,可以确保在删除派生类对象时,先调用派生类的析构函数,再调用基类的析构函数,从而实现正确的资源释放顺序。
示例代码说明:
#include <iostream>
class Base {
public:
Base() { std::cout << "Base Constructor" << std::endl; }
virtual ~Base() { std::cout << "Base Destructor" << std::endl; } // 虚析构函数
};
class Derived : public Base {
public:
Derived() { std::cout << "Derived Constructor" << std::endl; }
~Derived() { std::cout << "Derived Destructor" << std::endl; }
};
int main() {
Base* ptr = new Derived();
delete ptr; // 正确调用Derived和Base的析构函数
return 0;
}
输出结果:
Base Constructor
Derived Constructor
Derived Destructor
Base Destructor
总结:
- 构造函数:不能是虚函数,因为虚函数机制在构造函数执行期间尚未完全建立,且构造函数的设计目的与虚函数的多态性相矛盾。
- 析构函数:可以是虚函数,且通常建议将基类的析构函数声明为虚函数,以确保在删除派生类对象时能够正确调用所有层次的析构函数,避免资源泄漏。
拷贝构造,右值引用,移动语义
拷贝构造函数(Copy Constructor) 是一种特殊的构造函数,用于通过已有对象(同类型的另一个对象)来初始化新对象。它实现了对象的按值传递、按值返回以及对象拷贝等操作的核心机制。
使用场景
- 用已有对象初始化新对象
- 对象作为函数参数按值传递
- 函数返回对象(按值返回)
- 容器操作,eg.vector 插入对象
移动语义
C++11 引入了移动构造函数(Move Constructor),用于高效转移资源(如动态内存),避免不必要的深拷贝。当对象是临时对象(右值)时,编译器优先调用移动构造函数。
优势:
-
避免深拷贝:将时间复杂度从 O(n)(复制动态数组)降为 O(1)(仅转移指针)。
-
示例:向
std::vector插入 1000 个std::string对象时,移动语义仅需转移指针,而拷贝需复制所有字符。 -
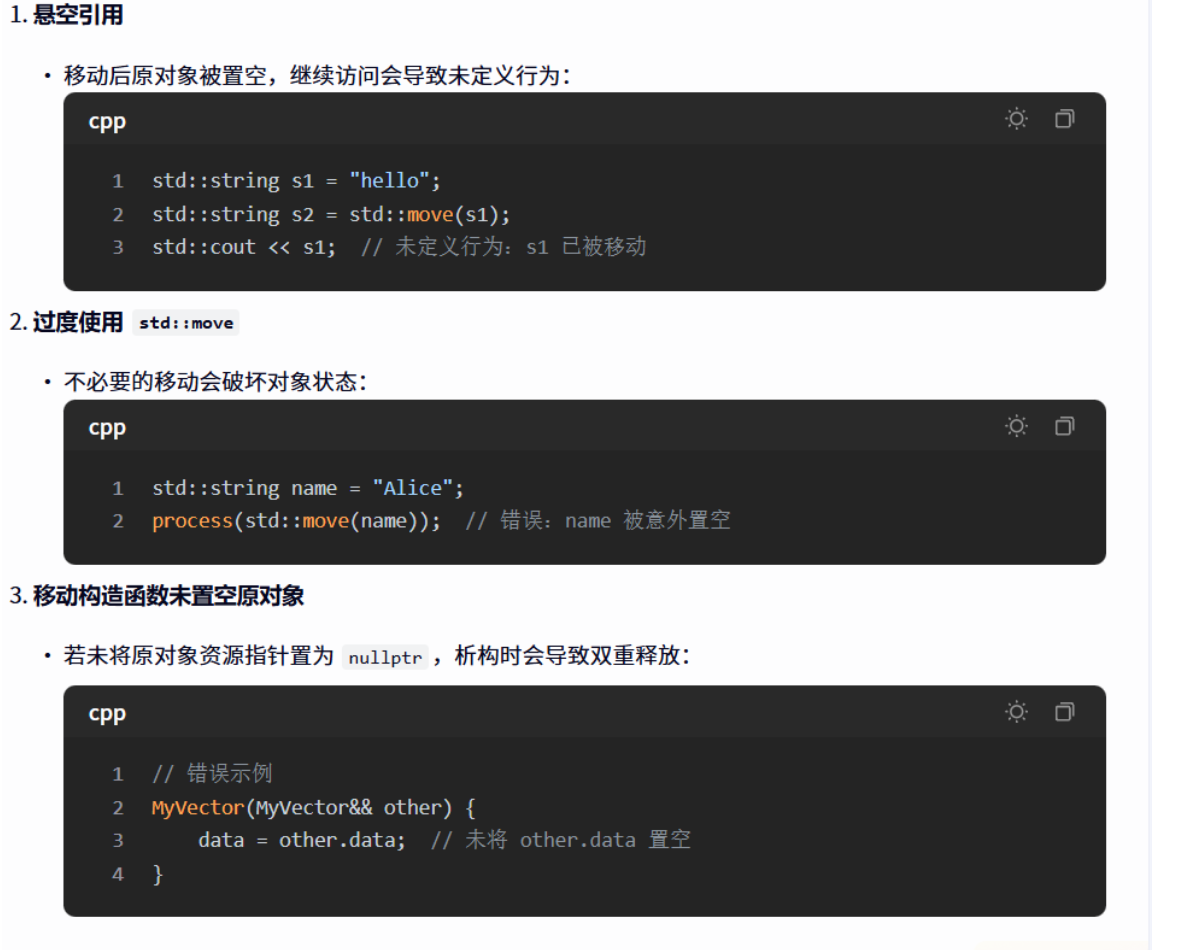
明确资源所有权转移,防止悬空指针和双重释放。被移动的对象处于有效但未定义状态(如指针为
nullptr),可安全析构但不可依赖其数据
应用场景
1.函数返回临时对象,移动语义避免深拷贝
2.**容器操作优化 ** std::vector 扩容或插入元素时,移动语义转移资源而非复制:
3.资源管理类 智能指针(如 std::unique_ptr)、文件句柄类通过移动语义实现独占所有权转移
问题
手撕一个string
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
//迭代器
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
string(const char*str=" ")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
//移动构造
MyString(MyString&& other) noexcept
: data_(other.data_), size_(other.size_) {
other.data_ = nullptr;
other.size_ = 0;
}
string(const string& s)//深拷贝
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
string& operator=(const string &s)
{
if (this != &s)
{
char* tmp = new char[_capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
// 拷贝赋值运算符
MyString& operator=(const MyString& other) {
if (this != &other) { // 防止自赋值
delete[] data_;
size_ = other.size_;
data_ = new char[size_ + 1];
strcpy(data_, other.data_);
}
return *this;
}
const char* c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
//可理解为realloc
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n+1];//开辟新空间,注意多开辟一个空间给\0
strcpy(tmp, _str);
//释放原来空间
delete[] _str;
//将老空间的值赋给新空间
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)//字符
{
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newCapacity);
}
_str[_size] = ch;
_size++;
//保证最后一个为\0
_str[_size] = '\0';
}
//字符串
void append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
void insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newCapacity);
}
size_t end = _size + 1;
while (end > pos)
{
//移位
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size++;
}
void insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
int end = _size;
while (end >= (int)pos)
{
_str[end + len] = _str[end];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
}
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len==npos||pos + len > _size)
{
//直接覆盖,后_size也跟着变
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -=len;
}
}
void swap(string& s)
{
//交换函数,直接改变指向
//利用std中的swap
std::swap(_str, s._str);
}
size_t find(char ch, size_t pos = 0)
{
for (int i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t find(char* str,size_t pos=0)
{
const char* ptr = strstr(_str+pos, str);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr-_str;//指针减指针
}
}
string substr(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
size_t end = pos + len;
if (len == npos || pos + len >= _size)
{
end = _size;
}
string str;
str.reserve(end - pos);
for (size_t i = pos; i < end; i++)
{
str += _str[i];
}
return str;
}
~string()
{
_size = 0;
_capacity = 0;
delete[] _str;
_str = nullptr;
}
private:
size_t _size;
size_t _capacity;
char* _str;
const static size_t npos = -1;
};
空类的大小
空类的大小为什么是 1 字节?
- 唯一地址需求:C++ 要求每个对象在内存中必须有唯一的地址。如果空类大小为 0,多个空类对象的地址会相同,导致指针运算和对象区分失效。
- 编译器实现:编译器会为空类隐式插入一个 占位字节(Placeholder Byte),确保对象占用至少 1 字节。
空类中含有虚函数
- 在 C++ 中,若空类中包含虚函数(无论数量多少),其大小将不再为 1 字节,而是会因虚函数表指针(
vptr)的引入而增加。
| 场景 | 大小 | 原因 |
|---|---|---|
| 纯空类 | 1byte | 编译器添加占位字节,确保对象地址唯一 |
| 含有虚函数的空类 | 4/8byte | 插入虚函数表指针(vptr),大小取决于系统指针宽度 |
| 含多个虚函数的空类 | 4/8 字节 | 虚函数共享同一表,vptr 数量不变。| |
| 虚继承的空类派生类 | 8/16字节 | 额外包含指向虚基类表的指针(vbptr)。 |
| 含静态成员的虚函数空类 | 4/8 字节 | 静态成员存储在全局区,不影响对象大小 |
class与struct的区别
| 特性 | class | struct |
|---|---|---|
| 默认访问权限 | private | public |
| 默认继承方式 | private | public |
| 典型用途 | 复杂对象、OOP 设计 | 简单数据聚合、C 兼容性 |
| C 兼容性 | 不兼容(C 没有 class) | 兼容(C 的 struct 完全支持) |
| 模板参数 | 可以(如 template<class T>) | 可以(如 template<struct T>) |
类中的析构和构造是否能够重载
| 函数 | 能否“重载” | 原因 |
|---|---|---|
| 构造函数 | ✅ 可以(定义多个不同参数的版本) | 需要支持不同的初始化方式(如默认构造、拷贝构造、参数化构造等)。 |
| 析构函数 | ❌ 不可以(只能有一个无参版本) | 析构函数的作用是释放资源,不需要不同的形式。 |
this指针的作用
| 作用 | 示例场景 | 关键点 |
|---|---|---|
| 区分成员变量和局部变量 | 参数名与成员变量同名时 | this->name = name; |
| 支持链式调用 | 返回 *this 的引用 | return *this; |
保证 const 成员函数安全性 | 防止意外修改对象状态 | void func() const; |
| 实现运算符重载对称性 | 二元运算符(如 +、-) | this 指向左侧操作数 |
| 支持赋值运算符链式赋值 | a = b = c; | 返回 *this 的引用 |
| 在 Lambda 中捕获当前对象 | C++11 起 | [this] { /* ... */ }; |
| 编译器隐式传递对象地址 | 所有非静态成员函数调用 | 编译器自动处理 this 传递 |
static
对于成员函数:1.没有this指针,2.只能访问静态成员函数(因为没有this指针),3.不能是虚函数,也是因为没有this指针。
内存管理
内存分布图
![[Pasted image 20250402120106.png]]
new/delete和malloc/free的区别 (重点)
性质
- malloc/free是函数,new/delete是操作符
- malloc不会初始化,new会进行初始化
用法
- malloc需要手动开辟大小,new只需要类型
- malloc返回值需要强转
- malloc开辟失败返回NULL,new抛异常
- malloc和free不会调用构造和析构
底层
- 调用operator new(size_t size)进行空间申请-----
底层调用new - 构造函数进行初始化
- 调用析构函数进行释放资源
- operator delete(void* p)进行空间释放--------
底层调用delete
内存分为那些
1. 代码段(Text Segment / .text)
- 内容:编译后的机器指令(二进制代码)。
- 特点:
- 只读,防止程序意外修改指令导致崩溃。
- 多个进程共享同一份代码(如动态链接库)。
2. 数据段(Data Segment)
- 子区域:
- 初始化数据段(.data):存储已初始化的全局变量和静态变量(如
int x = 10;)。 - 未初始化数据段(BSS, .bss):存储未初始化的全局变量和静态变量(如
int y;),程序启动时由操作系统初始化为 0。
- 初始化数据段(.data):存储已初始化的全局变量和静态变量(如
- 特点:
- 生命周期贯穿整个程序运行期。
- 数据段大小在编译时确定。
3. 堆(Heap)
- 内容:动态分配的内存(如
malloc、new)。 - 特点:
- 由程序员手动管理(分配/释放),易引发内存泄漏或碎片。
- 大小受系统可用内存限制,通常较大(GB 级)。
- 分配速度较慢(需查找可用块)。
4. 栈(Stack)
- 内容:局部变量、函数参数、返回地址等。
- 特点:
- 由编译器自动管理(函数调用时压栈,返回时弹栈)。
- 速度极快(仅移动栈指针),但容量有限(默认几 MB,可调整)。
- 栈溢出会导致程序崩溃(如无限递归)。
5. 内存映射段(Memory Mapping Segment)
- 内容:
- 动态链接库(如
libc.so)的代码和数据。 - 匿名内存映射(如
mmap创建的共享内存)。
- 动态链接库(如
- 特点:
- 按需加载,减少内存占用。
- 文件映射可实现进程间通信(IPC)。
内存对齐
编译器默认对齐大小是,通常是成员中最大类型的大小(如 double 的 8 字节)
如果是按一字节对齐,就是正常大小。就不需要对齐。
原则:
- 基本数据类型对齐:
大多数情况下,一个基本数据类型(如 int, float, double, char 等)的对齐要求是其自身大小的倍数。
例如,一个 int 类型(通常4字节)的变量,其地址应该是4的倍数(0x…0, 0x…4, 0x…8)。
一个 double 类型(通常8字节)的变量,其地址应该是8的倍数。
char 类型(1字节)的变量,其地址可以是任意地址,因为1是所有整数的倍数。
- 结构体(Struct)/类(Class)对齐:
成员对齐: 结构体中的每个成员都必须按照其自身的数据类型对齐要求进行对齐。
结构体整体对齐: 整个结构体(或类)的对齐要求是其所有成员中对齐要求最大的那个成员的对齐要求。例如,如果一个结构体包含一个 char (1字节) 和一个 double (8字节),那么整个结构体的对齐要求就是8字节。
填充(Padding): 为了满足上述对齐要求,编译器会在结构体成员之间以及结构体末尾插入一些“填充字节”(padding bytes),这些字节不存储实际数据,只是为了对齐。
作用:
- 提升硬件访问效率。对齐的数据(如
int存储在0x1000)可被CPU一次性读取,减少内存访问次数和指令开销。 - 确保硬件的兼容性
- 跨平台可移植性与代码健壮性
缺点
1.内存浪费:
为了满足对齐要求,编译器会在结构体中插入填充字节,这会增加结构体的总大小,导致内存的浪费。在内存资源有限的嵌入式系统或需要处理大量小对象的场景中,这可能是一个问题。
例如,一个包含 char, int, char 的结构体,实际可能占用12字节,而不是理论上的6字节。
2.增加复杂性(在某些情况下):
虽然编译器通常会自动处理对齐,但在需要手动控制对齐(例如,为了与特定硬件接口交互、网络协议数据包、或极致内存优化)时,程序员需要理解并正确使用对齐指令,这增加了代码的复杂性和出错的可能性。
强制取消对齐(如使用 packed 属性)可能会导致性能下降或在某些平台上引发错误,需要谨慎使用。
3.跨平台/序列化问题:
不同的编译器、不同的操作系统或不同的处理器架构可能对内存对齐有不同的默认规则。这可能导致在不同平台上编译同一个结构体时,其内存布局不同。
在进行数据序列化(将内存中的数据写入文件或通过网络发送)时,如果直接按内存布局写入,接收方可能因为对齐规则不同而无法正确解析数据,或者会传输不必要的填充字节。因此,通常需要进行显式的序列化和反序列化操作,将数据“打包”成紧凑的格式。
内存泄漏
什么是内存泄漏
内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
内存泄露的危害
内存泄漏的危害:长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
解决
内存泄漏非常常见,解决方案分为两种:1、事前预防型。如智能指针等。2、事后查错型。如泄
漏检测工具。(linux中valgrind)
模板
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
模板的匹配(有现成吃现成)
一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
继承
重写,重载,隐藏
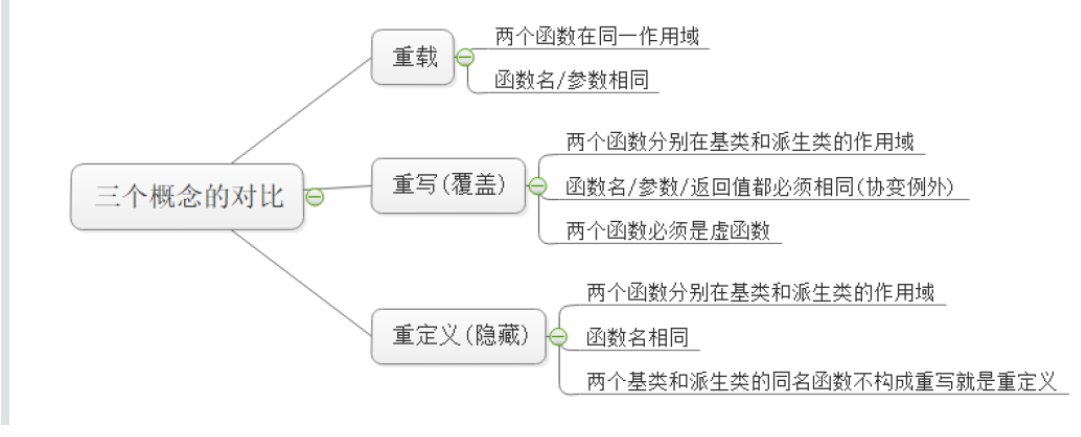
- 同一作用域下的函数名相同,但是参数不相同
- 重写是在基类和派生类作用域下的相同的虚函数
- ==函数名相同,就构成覆盖
-
没有构成隐藏就构成重写。
-
在继承中,子类的成员函数或者成员变量如果与基类的名字相同,那么就会覆盖掉基类的成员,这种现象就叫做隐藏
-
派生类可以指向基类。基类指向派生类,需要指针转化,用到dynamic_pointer.
菱形继承
利用虚表指针的偏移量指向基类,解决一个二义性和数据冗余的问题
详情看Me博客。
解决的是B->A,C->A,D->B,D->C,------------- D->A的一个二义性的问题。
多态
原理:
- 当一个类中含有虚函数时,会为该类创建一个虚函数表,保存的是虚函数的地址
- 当派生类继承基类时,也会有对应的虚函数表
- 当定义一个派生类对象时,编译器检测到有虚函数,就会给该派生类对象创建一个虚函数表指针,指向这个虚函数表,这是在构造函数完成的,
构造函数没有虚函数。 - 后续如果有基类的指针指向派生类,那么调用函数时,虚函数表指针调用的就是该派生类的虚函数,即使是基类的指针
抽象类
- 通过抽象类派生出的派生类,都要提供抽象类的这些接口,是一种标准化的模式
- 抽象类强制要求,派生类必须要实现抽象类当中的实现细节,否则也是抽象类
- 抽象类是实现多态的基础,借助抽象类可以实现多态,进而形成一个接口,多种实现的效果
对比总结
- 重写与隐藏都是指向派生类函数,只不过重写是基类指向派生类时,调用派生类对应的虚函数,而隐藏是派生类指向自己的函数
- 派生类复制基类的虚函数表,进行重写,如果有多的虚函数就会添加在虚函数表末尾
虚函数的原理
虚函数是C++中实现运行时多态(动态绑定)的核心机制,其原理基于虚函数表(vtable) 和虚表指针(vptr)。
1. 虚函数表(vtable)
- 定义:每个包含虚函数的类,编译器会为其生成一个隐藏的虚函数表(数组),表中按声明顺序存储该类所有虚函数的地址。
- 特点:
- 基类和派生类各自维护独立的vtable。
- 如果派生类重写(override)了基类的虚函数,则派生类的vtable中对应位置会被替换为新函数的地址。
- 非虚函数不会存入vtable。
2. 虚表指针(vptr)
- 定义:每个对象内部隐藏一个指针(vptr),指向该对象所属类的vtable。
- 初始化:
- 在构造函数中设置vptr指向当前类的vtable。
- 在析构函数中恢复vptr(避免析构期间虚调用错误)。
- 内存布局:
- 对象内存开头通常存放vptr(具体位置由编译器决定)。
- 随后是类的非静态成员变量。
3. 虚函数调用过程
当通过基类指针/引用调用虚函数时:
- 获取vptr:从对象内存中读取vptr。
- 查找vtable:通过vptr找到对应的vtable。
- 调用函数:根据虚函数在vtable中的偏移量,调用正确的函数地址。
总结
虚函数通过vtable + vptr机制实现动态绑定,牺牲少量空间和时间换取面向对象的核心特性——多态。理解其原理有助于编写高效的多态代码,并避免常见陷阱(如虚析构函数缺失导致的内存泄漏)。
虚函数在什么阶段生成
| 对象 | 生成时机 | 与构造函数的关系 |
|---|---|---|
| 虚函数表 | 编译时生成 | 无关 |
| 虚表指针 | 对象初始化中生成 | 构造函数逐步更新 vptr,决定当前 vtable |
| 虚函数调用 | 通过vptr查找对应的vtable | 构造函数中为静态绑定(vptr 未完全初始化) |
虚函数表存在内存的位置
- 虚函数表本身:存储在程序的静态存储区(通常是
.rodata或.text段),由所有同类型对象共享。
- 该区域在程序加载时分配,生命周期贯穿整个程序运行期。
- 虚函数表的内容是只读的(不可修改),因为虚函数的地址在编译时已确定。。
- 虚表指针(vptr):存储在每个对象的内存中,指向对应的虚函数表。
- 不可修改性:虚函数表的内容是只读的,修改它会导致未定义行为(如崩溃)。
Cpp11
线程
cpp中的线程库
在 C++11 及更高版本中,标准库 <thread> 提供了内置的线程支持,包括线程管理、同步原语和线程相关函数。以下是关键组件和函数的详细说明:
1. 线程管理
(1) std::thread 类
-
构造函数:创建并启动线程。
#include <thread> void foo() { /* 任务 */ } std::thread t(foo); // 启动线程,执行 foo()- 可传递参数(注意参数传递的拷贝/引用语义):
void bar(int x, const std::string& s) { /* ... */ } std::thread t(bar, 42, "hello"); // 参数按值或常量引用传递
- 可传递参数(注意参数传递的拷贝/引用语义):
-
成员函数:
t.join():等待线程完成。(在 C++ 中,std::thread::join()是线程管理中的一个关键函数,用于阻塞当前线程(通常是主线程或其他调用线程),直到目标线程执行完毕。它的核心功能是同步线程的执行,确保线程按预期顺序完成工作)t.detach():分离线程(不再可 join,线程独立运行)。t.joinable():检查线程是否可 join 或 detach。std::thread::get_id():获取线程 ID(std::thread::id类型)。std::this_thread::get_id():获取当前线程的 ID。
-
移动语义:
std::thread t1(foo); std::thread t2 = std::move(t1); // 所有权转移,t1 不再关联线程
(2) 当前线程操作
std::this_thread::yield():提示调度器让出当前线程的 CPU 时间片。std::this_thread::sleep_for(std::chrono::milliseconds(100)):让当前线程休眠指定时间。std::this_thread::sleep_until(time_point):休眠直到某个时间点。
线程与进程的区别
直接表格展示
列1 列2 数据1 数据2
| 特性 | 进程 | 线程 |
|---|---|---|
| 概念 | 是操作系统资源分配的基本单位,拥有独立的内存空间、文件描述符、寄存器状态等。 | 是进程内的执行单元,共享进程的资源(如内存、文件句柄等),但拥有独立的栈和寄存器状态(执行流,cpu调度的基本单元) |
| 资源分配 | 独立性高,什么都是单独的:独立内存空间、文件描述符、全局变量等 | 共享资源,只有自己的栈空间和寄存器上下文数据是独立的其余都是共享的 |
| 创建开销 | 创建消耗资源大 | 因为共享资源,所以只需要自己的栈空间和上下文数据 |
| 切换开销 | 高 | 低,直接共享内存 |
| 通信方式 | IPC | 也适用。除此之外还有条件变量,信号量 |
| 稳定性 | 独立性高,不会受影响 | 一个线程崩,其他线程也会崩,detach应该不会崩 |
| 场景 | 浏览器,数据库,微服务 | 网页请求,并发处理 |
如何唤醒一个线程
在 C++ 中,唤醒线程通常需要结合**条件变量(Condition Variable)和互斥锁(Mutex)**来实现,这是标准库 <condition_variable> 提供的同步机制。此外,C++20 引入了更高级的并发工具(如 std::latch 和 std::barrier),但核心方法仍然是条件变量。
一、C++ 中唤醒线程的核心方法
1. 使用 std::condition_variable
条件变量允许线程在某个条件不满足时进入等待状态,并由其他线程在条件满足时唤醒它们。
关键组件
std::mutex:保护共享数据的互斥锁。std::unique_lock:与条件变量配合使用的锁(比std::lock_guard更灵活)。std::condition_variable::wait():线程主动释放锁并进入等待状态。std::condition_variable::notify_one()/notify_all():唤醒一个或所有等待线程。
示例代码
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false; // 共享条件
void worker_thread() {
std::unique_lock<std::mutex> lock(mtx);
// 等待条件满足(必须用 while 检查,防止虚假唤醒)
cv.wait(lock, [] { return ready; });
std::cout << "Worker thread awakened and processing..." << std::endl;
}
int main() {
std::thread worker(worker_thread);
// 模拟主线程准备数据
std::this_thread::sleep_for(std::chrono::seconds(1));
{
std::lock_guard<std::mutex> lock(mtx);
ready = true;
}
cv.notify_one(); // 唤醒一个等待线程
worker.join();
return 0;
}
关键点
wait()的 lambda 检查:
使用cv.wait(lock, predicate)可以避免虚假唤醒(spurious wakeup),等价于:while (!predicate()) { cv.wait(lock); }- 锁的管理:
wait()会自动释放锁,允许其他线程修改共享数据。- 被唤醒后,线程会重新获取锁,确保检查条件时的数据一致性。
notify_one()vsnotify_all():notify_one():唤醒一个等待线程(不确定哪个)。notify_all():唤醒所有等待线程(适用于多个线程等待同一条件)。
2. 使用 std::future 和 std::promise
适用于一次性通知的场景(如异步任务完成)。
示例代码
#include <iostream>
#include <thread>
#include <future>
void worker(std::promise<void> promise) {
std::cout << "Worker thread working..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
promise.set_value(); // 通知主线程任务完成
}
int main() {
std::promise<void> promise;
std::future<void> future = promise.get_future();
std::thread t(worker, std::move(promise));
std::cout << "Main thread waiting..." << std::endl;
future.wait(); // 阻塞直到 worker 调用 set_value()
std::cout << "Main thread awakened!" << std::endl;
t.join();
return 0;
}
3. 使用 C++20 的 std::latch 或 std::barrier
std::latch:一次性计数器,适用于多个线程等待某个事件。std::barrier:可重复使用的同步点(类似std::latch,但可重置)。
示例:std::latch
#include <iostream>
#include <thread>
#include <latch>
std::latch latch(1); // 计数器初始值为1
void worker() {
std::cout << "Worker thread waiting..." << std::endl;
latch.wait(); // 等待计数器归零
std::cout << "Worker thread released!" << std::endl;
}
int main() {
std::thread t(worker);
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Main thread releasing latch..." << std::endl;
latch.count_down(); // 计数器减1,唤醒等待线程
t.join();
return 0;
}
二、其他唤醒方式
1. 通过标志位 + 轮询(不推荐)
#include <atomic>
#include <thread>
std::atomic<bool> ready(false);
void worker() {
while (!ready) { // 忙等待(浪费CPU)
std::this_thread::yield(); // 可选:让出CPU
}
std::cout << "Worker awakened!" << std::endl;
}
int main() {
std::thread t(worker);
std::this_thread::sleep_for(std::chrono::seconds(1));
ready = true;
t.join();
}
缺点:忙等待(Busy Waiting)会浪费 CPU 资源,通常应避免。
2. 通过信号量(C++20 未直接提供,可用第三方库)
如 Boost.Thread 的 boost::interprocess::interprocess_semaphore。
三、最佳实践
- 优先使用
std::condition_variable:
适用于大多数线程同步场景,结合互斥锁保证数据安全。 - 避免虚假唤醒:
始终用while或wait()的 lambda 参数检查条件。 - 选择合适的通知方式:
notify_one():单消费者场景。notify_all():多消费者或不确定哪个线程需要唤醒。
- C++20 工具:
如果可用,优先使用std::latch、std::barrier或std::future简化代码。
四、常见问题
1. 为什么 wait() 需要互斥锁?
- 防止竞态条件:检查条件和进入等待状态必须是原子的。
- 如果不锁住,可能在
if (!ready)和wait()之间被其他线程修改ready。
2. 虚假唤醒如何避免?
用 while 循环检查条件:
cv.wait(lock, [] { return ready; });
// 等价于:
while (!ready) {
cv.wait(lock);
}
3. 如何唤醒所有等待线程?
使用 notify_all():
cv.notify_all(); // 唤醒所有等待线程
总结
| 方法 | 适用场景 | 特点 |
|---|---|---|
std::condition_variable | 通用线程同步 | 需配合互斥锁,支持 notify_one/all。 |
std::future/std::promise | 一次性异步通知 | 适用于任务完成通知。 |
std::latch/std::barrier | C++20 多线程同步点 | 更高级的同步工具。 |
| 标志位 + 轮询 | 简单场景(不推荐) | 浪费 CPU,慎用。 |
推荐:
- 默认使用
std::condition_variable。 - C++20 环境可尝试
std::latch或std::barrier。 - 避免忙等待,优先使用阻塞式同步机制。
线程的竞争条件
简而言之就是线程安全问题,对同一份资源有竞争关系
出现原因:
- 并发访问
- 非原子操作
- 调度依赖
竞争条件的危害 - 数据不一样
- 死锁和活锁
- 性能下降
右值引用
右值引用是C++11特性,可以引用临时对象或者即将被销毁的对象,实现移动语义和完美转发.
![[Pasted image 20250402155603.png]]

对将亡值(出作用域就销毁的变量)的一个移动拷贝,对将亡值不能使用引用,否则返回的是随机值,造成引用悬用。
解决什么问题
右值引用主要解决了 C++ 中 不必要的拷贝(Copy)问题,从而显著提升了性能,并使得实现移动语义(Move Semantics)和完美转发(Perfect Forwarding) 成为可能。
- 性能优化: 通过引入移动语义,避免了对临时对象进行昂贵的深拷贝,而是通过“窃取”资源的方式,大大提高了资源密集型对象的处理效率。
- 泛型编程: 通过与模板结合形成万能引用和 std::forward,实现了完美转发,使得模板函数能够以原始的值类别和 const/volatile 属性转发参数,保持了泛型代码的效率和正确性。
- 更精细的控制: 允许函数重载以区分左值和右值参数,从而为临时对象提供特定的处理逻辑。
移动语义
移动语义允许我们从一个即将销毁的对象(通常是右值)中“窃取”它的资源,并将其赋予另一个对象,从而避免了复制过程
应用场景
- 深拷贝的类,传值返回的优化
- 深拷贝的类,做参数。
完美转发
- 带模板参数中T&&会自动进行左右值识别
- 保持左右值初识属性,传参到目标函数
![[Pasted image 20250402160420.png]]

push_back&&emplace_back
在 C++11 中,push_back 和 emplace_back 都是用于向容器(如 std::vector)中添加元素的方法,但它们的实现方式和性能特点不同:
1. push_back
- 行为:接受一个==已构造的对象==,将其拷贝或移动到容器中。
- 特点:
- 可能触发拷贝构造函数或移动构造函数(如果是临时对象)。
- 需要先构造一个临时对象,再将其复制到容器中。
- 示例:
std::vector<std::string> vec; std::string s = "hello"; vec.push_back(s); // 拷贝构造 vec.push_back("world"); // 隐式构造临时 string,再移动构造(C++11 起)
2. emplace_back
- 行为:接受构造元素所需的参数,直接在容器内存分配的位置==原地构造对象==。
- 特点:
- 避免临时对象的创建和拷贝/移动,性能更高。
- 需要容器支持就地构造(in-place construction)。
- 示例:
std::vector<std::string> vec; vec.emplace_back("hello"); // 直接构造 string 对象,无需临时变量
关键区别
| 特性 | push_back | emplace_back |
|---|---|---|
| 参数类型 | 已构造的对象 | 构造对象的参数 |
| 对象构造 | 先构造临时对象,再移动/拷贝 | 直接在容器内存构造 |
| 性能 | 可能触发拷贝/移动 | 通常更高效(避免临时对象) |
| 异常安全性 | 可能抛出异常(临时对象构造失败) | 可能抛出异常(参数构造失败) |
总结
- 优先使用
emplace_back:当需要直接传递构造参数时,emplace_back通常更高效。 - 使用
push_back:当已有对象需要添加到容器,或需要显式控制对象构造时。
可变参数
lambda表达式
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement
}
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:
a. 父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者
非局部变量都
会导致编译报错。
f. lambda表达式之间不能相互赋值,即使看起来类型相同
包装器
线程库
异常
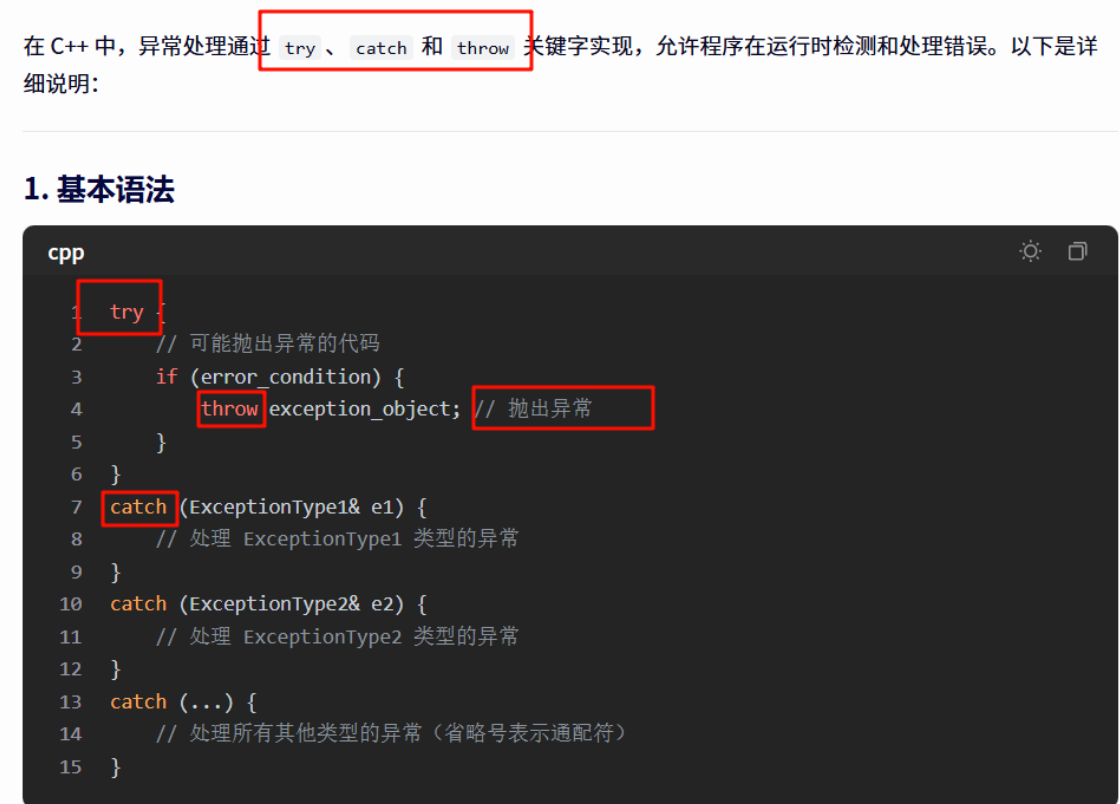
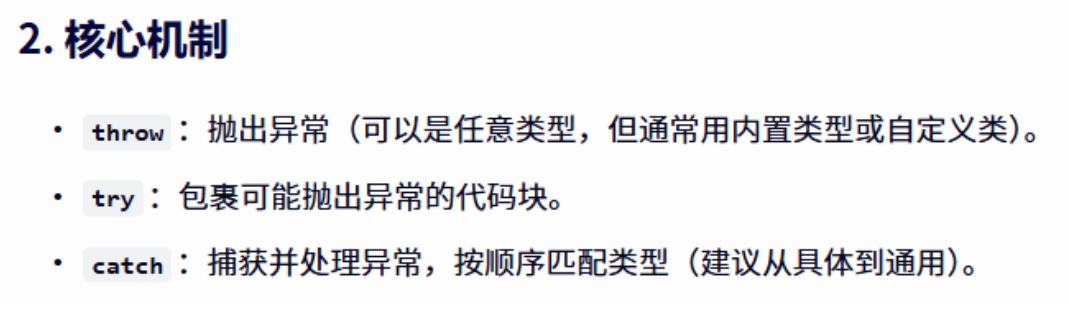
注意资源问题,会出现内存泄漏问题,抛异常时没有释放资源,就要使用RAII智能指针来解决
智能指针
why
RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内
存、文件句柄、网络连接、互斥量等等)的简单技术。
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在
对象析构的时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。
这种做法有两大好处:
不需要显式地释放资源。
采用这种方式,对象所需的资源在其生命期内始终保持有效。
原理:
- 利用RAII
- 重载operator* 和 operator->
auto_ptr:转移管理权
shared_ptr: 是通过引用计数的方式来实现多个shared_ptr对象之间共享资源(允许进行拷贝 )
- shared_ptr在其内部,给每个资源都维护了着一份计数,用来记录该份资源被几个对象共
享。- 在对象被销毁时(也就是析构函数调用),就说明自己不使用该资源了,对象的引用计数减
一。- 如果引用计数是0,就说明自己是最后一个使用该资源的对象,必须释放该资源;
- 如果不是0,就说明除了自己还有其他对象在使用该份资源,不能释放该资源,否则其他对
象就成野指针了。
template<class T>
class shared_ptr
{
public:
shared_ptr(T* ptr = nullptr)
:_ptr(ptr)
, _pRefCount(new int(1))
, _pmtx(new mutex)
{}
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _pRefCount(sp._pRefCount)
, _pmtx(sp._pmtx)
{
AddRef();
}
void Release()
{
_pmtx->lock();
bool flag = false;
if (--(*_pRefCount) == 0 && _ptr)
{
delete _ptr;
delete _pRefCount;
flag = true;
}
_pmtx->unlock();
if (flag == true)
{
delete _pmtx;
}
}
void AddRef()
{
_pmtx->lock();
++(*_pRefCount);
_pmtx->unlock();
}
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
//if (this != &sp)
if (_ptr != sp._ptr)
{
Release();
_ptr = sp._ptr;
_pRefCount = sp._pRefCount;
_pmtx = sp._pmtx;
AddRef();
}
return *this;
}
int use_count()
{
return *_pRefCount;
}
~shared_ptr()
{
Release();
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get() const
{
return _ptr;
}
private:
T* _ptr;
int* _pRefCount;
mutex* _pmtx;
};
unique_ptr:简单粗暴的防拷贝
template<class T>
class unique_ptr
{
public:
unique_ptr(T* ptr)
:_ptr(ptr)
{}
~unique_ptr()
{
if (_ptr){
delete _ptr;
}
}
// 像指针一样使用
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
unique_ptr(const unique_ptr<T>& sp) = delete;
unique_ptr<T>& operator=(const unique_ptr<T>& sp) = delete;
private:
T* _ptr;
};
}
weak_ptr:(底层用的是shared_ptr)/弱引用
template<class T>
class weak_ptr
{
public:
weak_ptr()
:_ptr(nullptr)
{}
weak_ptr(const shared_ptr<T>& sp)
:_ptr(sp.get())
{}
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.get();
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
shared_ptr的循环引用问题
![![[Pasted image 20250402172047.png]]](https://i-blog.csdnimg.cn/direct/0af9d1422d7d413188681eb68859778e.png)
类型转化
static_cast
static_cast用于非多态类型的转换(静态转换),编译器隐式执行的任何类型转换都可用
static_cast,但它不能用于两个不相关的类型进行转换
int main()
{
double d = 12.34;
int a = static_cast<int>(d);
cout<<a<<endl;
return 0;
}
reinterpret_cast
reinterpret_cast操作符通常为操作数的位模式提供较低层次的重新解释,用于将一种类型转换
为另一种不同的类型
int main()
{
double d = 12.34;
int a = static_cast<int>(d);
cout << a << endl;
// 这里使用static_cast会报错,应该使用reinterpret_cast
//int *p = static_cast<int*>(a);
int *p = reinterpret_cast<int*>(a);
return 0;
}
const_cast
const_cast最常用的用途就是删除变量的const属性,方便赋值
void Test ()
{
const int a = 2;
int* p = const_cast<int*>(&a);
*p = 3;
cout<<a <<endl;
}
dynamic_cast
dynamic_cast用于将一个父类对象的指针/引用转换为子类对象的指针或引用(动态转换)
向上转型:子类对象指针/引用->父类指针/引用(不需要转换,赋值兼容规则)
向下转型:父类对象指针/引用->子类指针/引用(用dynamic_cast转型是安全的)
注意:
- dynamic_cast只能用于父类含有虚函数的类
-
- dynamic_cast会先检查是否能转换成功,能成功则转换,不能则返回0
注意
强制类型转换关闭或挂起了正常的类型检查,每次使用强制类型转换前,程序员应该仔细考虑是
否还有其他不同的方法达到同一目的,如果非强制类型转换不可,则应限制强制转换值的作用
域,以减少发生错误的机会。强烈建议:避免使用强制类型转换
IO流
特殊类
不能复制的类
![> ![[Pasted image 20250402172848.png]]](https://i-blog.csdnimg.cn/direct/e993ac48f5c0410f97ad3a91fbdb00c0.png)
只在堆上创建类
![![[Pasted image 20250402172944.png]]](https://i-blog.csdnimg.cn/direct/52e51874efc249e4a09ba62ba6823268.png)
只在栈上创建类
![![[Pasted image 20250402173025.png]]](https://i-blog.csdnimg.cn/direct/0685cc765fa84327a40a8f503fad106e.png)
单例模式
饿汉模式
![![[Pasted image 20250402173115.png]]](https://i-blog.csdnimg.cn/direct/fbe72880f31b4a27be2b1e3e0badd410.png)
懒汉模式
![![[Pasted image 20250402173145.png]]](https://i-blog.csdnimg.cn/direct/9efbadbd36864cf48f1e4f36b0ae4af5.png)
工厂模式
通过调用工厂函数,来创建实例对象。
STL
为什么会有迭代器
在 C++ 标准库容器中,迭代器(Iterator)的存在是为了提供一种统一且高效的方式访问容器中的元素。以下是容器需要迭代器的核心原因:
1. 解耦算法与容器
- 问题:如果算法直接依赖容器的具体实现(如通过下标访问
std::vector,但无法直接用于std::list),会导致代码冗余且难以维护。 - 解决方案:迭代器作为中间层,将算法与容器解耦。算法只需通过迭代器操作元素,无需关心容器类型。
- 示例:
std::sort算法通过迭代器对任意容器排序,无需为vector、list等分别实现。
2. 支持泛型编程
- 目标:C++ 标准库强调泛型(通用)设计,迭代器是实现这一目标的关键。
- 作用:迭代器允许算法以统一接口操作不同容器(如
vector、list、map),促进代码复用。
3. 抽象容器内部结构
- 问题:容器的内部实现可能复杂(如链表节点包含前后指针),直接暴露细节会破坏封装性。
- 解决方案:迭代器封装容器的访问逻辑,外部代码只需通过
begin()/end()获取迭代器,无需了解容器内部结构。
4. 提供多种遍历方式
- 迭代器类型:
- 随机访问迭代器(如
vector):支持+、-、[]等操作,类似指针。 - 双向迭代器(如
list):支持++、--,但无法随机访问。 - 输入/输出迭代器(如
istream):仅支持单次遍历。
- 随机访问迭代器(如
- 灵活性:不同迭代器类型适配不同容器特性,提供高效的遍历方式。
5. 支持 STL 算法
- 算法库依赖:STL 算法(如
find、transform)完全基于迭代器工作。 - 示例:
std::find(vec.begin(), vec.end(), value)对任意容器生效。
迭代器的核心行为
迭代器模仿指针的行为,支持以下操作:
- 遍历:
++it(前进),--it(后退,双向迭代器)。 - 访问:
*it(获取元素值),it->member(访问成员)。 - 比较:
it1 == it2(判断迭代器是否相等)。
总结
迭代器是 C++ 标准库容器的灵魂设计,它:
- 隐藏容器实现细节,提供统一访问接口。
- 使算法与容器解耦,支持泛型编程。
- 适配不同容器特性,提供高效的遍历方式。
没有迭代器,C++ 标准库的强大抽象能力和泛型编程特性将大打折扣。
vector
底层三个指针是实现
![![[Pasted image 20250402190002.png]]](https://i-blog.csdnimg.cn/direct/ef2b02071d284bbe981108ec03af63cd.png)
扩容:单独申请一块连续空间,把原有数据拷贝到新空间,释放原有空间,而不是直接原来的基础上进行扩容。---->导致迭代器失效。
造成迭代器失效的场景
1.插入导致扩容造成的迭代器失效
- 插入数据时,原来的容量不够会触发扩容,此时会重新分配更大的空间,并且重新赋值,删除原来的数据,释放旧内存。由于迭代器指向旧内存,旧内存已经释放了,此时的迭代器就已经失效了。
2.删除操作导致元素移动
- 通过 erase 或 pop_back 删除元素时,如果删除的不是末尾元素,后续元素会向前移动以填补空缺。(被删除元素的迭代器成为悬垂指针。)
- 被删除元素及其之后的所有迭代器(因为它们的地址可能被移动)。
-
解决:删除后用迭代器进行接受当前删除的迭代器 。eg:it = vec.erase(it);
- 调用 reserve、resize 或 shrink_to_fit
- 也是和原来一样由于扩容导致的迭代器失效。详情看第一点。
迭代器失效的原因
(1) 内存重新分配
- vector 的底层是动态数组,当容量不足时,会分配更大的内存块(通常是当前容量的 2 倍),复制原有元素,并释放旧内存。
- 结果:所有原有迭代器指向的旧内存被释放,成为悬垂指针(Dangling Pointer)。
(2) 元素移动
- 删除或插入非末尾元素时,后续元素会通过 memmove 或逐个赋值向前/向后移动。
- 结果:迭代器指向的地址可能被覆盖或不再属于 vector 的有效范围。
(3) 迭代器与底层指针的绑定
- vector 的迭代器通常是普通指针(或封装了指针的轻量级对象),直接指向内存中的元素。(通常由于删除元素导致后面的元素向前移,此时内存地址发生变化)。
- 结果:当内存地址变化时,迭代器无法自动更新,导致失效。
Reactor
在计算机领域,Reactor(反应堆)是一种基于事件驱动的高性能并发设计模式,广泛应用于网络编程、高并发服务器开发及响应式编程框架中。其核心思想是通过I/O多路复用技术(如select、poll、epoll)监听多个I/O事件,并在事件就绪时通过回调机制分发处理,从而避免传统多线程阻塞模型带来的上下文切换和资源消耗问题。
Reactor模式的核心组件与流程
-
Reactor(事件分发器)
- 负责监听和分发事件,通过I/O多路复用机制(如
epoll)同时监视多个文件描述符或套接字。 - 当事件(如读、写、连接)就绪时,通知对应的事件处理器(Handler)处理。
- 负责监听和分发事件,通过I/O多路复用机制(如
-
事件源(Event Source)
- 代表I/O对象(如套接字、文件描述符),负责生成事件(如数据可读、可写)。
- 事件源将事件注册到Reactor,以便在事件发生时触发回调。
-
事件处理器(Handler)
- 处理特定事件的组件,包含读回调、写回调和异常回调等具体实现。
- 例如,当套接字数据可读时,Handler执行读取操作并处理业务逻辑。
典型流程:
- 事件源生成事件(如客户端连接请求)。
- 事件源将事件注册到Reactor。
- Reactor通过I/O多路复用监听事件。
- 事件就绪时,Reactor分发事件给对应的Handler。
- Handler处理事件并执行业务逻辑。
Reactor模式的实现方式
根据线程模型的不同,Reactor模式可分为以下三种实现:
-
单线程Reactor
- 结构:单个线程同时负责事件监听和事件处理。
- 适用场景:低并发场景(如简单TCP服务器)。
- 缺点:I/O和业务逻辑在同一线程执行,易因耗时操作阻塞整个Reactor。
-
多线程Reactor
- 结构:主线程负责事件监听和分发,子线程(线程池)负责事件处理。
- 适用场景:中高并发场景(如Web服务器、消息队列)。
- 优点:业务逻辑并行执行,提高吞吐量;主线程不阻塞事件监听。
-
主从Reactor(多Reactor)
- 结构:主Reactor监听新连接,子Reactor监听连接的I/O事件,并分发给线程池处理业务逻辑。
- 适用场景:超高并发场景(如Redis、Netty服务器)。
- 优点:结合I/O多路复用和非阻塞I/O,充分利用CPU资源,适合高并发、高吞吐的分布式系统。
Reactor模式的技术依赖
- I/O多路复用:
select/poll:适用于少量连接,但性能较低(时间复杂度O(n))。epoll/kqueue:适用于大规模并发连接,性能更优(时间复杂度O(1))。
- 非阻塞I/O:
- 通过
fcntl(socket, F_SETFL, O_NONBLOCK)将套接字设置为非阻塞模式,防止单个I/O操作阻塞整个进程。
- 通过
- Worker Pool:
- 使用线程池处理复杂业务逻辑,避免Reactor线程阻塞。
Reactor模式的应用场景
- 高并发Web服务器
- 如Nginx、Netty,通过Reactor模式高效处理大量并发连接,减少线程上下文切换开销。
- 消息中间件
- 如Kafka、RabbitMQ,利用Reactor模式处理高吞吐量的消息收发。
- 数据库代理
- 如MySQL Proxy,通过Reactor模式管理数据库连接和查询请求。
- 异步网络库
- 如libevent、libuv,封装I/O多路复用技术,提供跨平台的异步I/O支持。
- 游戏服务器
- Netty在游戏服务器中广泛应用,通过Reactor模式处理玩家连接和实时数据交互。
Reactor模式的优势
- 低上下文切换开销:相比多线程模型,减少线程切换带来的性能损耗。
- 高资源利用率:仅在事件发生时处理请求,避免资源浪费。
- 可扩展性:灵活调整事件处理逻辑和分发机制,适应不同业务需求。
- 代码结构清晰:将事件处理逻辑解耦到单独的Handler中,提高代码模块化程度。
示例:餐厅点餐系统(Reactor模式类比)
- Reactor(服务员):负责接待顾客(客户端)并安排厨师(Handler)做菜。
- 事件源(顾客):生成点餐事件(如“我要汉堡”)。
- 事件处理器(厨师):处理点餐事件并制作菜品。
- 流程:
- 顾客点餐(事件生成)。
- 服务员记录订单并通知厨师(事件分发)。
- 厨师制作菜品并通知顾客取餐(事件处理完成)。
- 优势:服务员可同时管理多个顾客点餐(非阻塞),厨师仅在需要时工作(资源高效利用)。
扩 Muduo库中的Reactor
Muduo库采用主从Reactor模型,其工作原理通过分层架构和线程隔离实现高并发处理,具体如下:
一、主从Reactor模型的核心架构
-
主Reactor(MainReactor)
- 职责:监听新连接请求(
accept事件),通过Acceptor类实现。 - 实现:使用
epoll/poll等多路复用机制监控监听套接字(listenfd)。 - 线程模型:通常运行在独立线程中,避免阻塞业务处理。
- 职责:监听新连接请求(
-
从Reactor(SubReactor)
- 职责:处理已建立连接的I/O事件(读写、定时任务等)。
- 实现:每个
EventLoop对象管理一组TCP连接(TcpConnection),通过轮询算法分配新连接。 - 线程模型:多个
EventLoop线程并行运行,每个线程绑定一个EventLoop实例,实现资源隔离。
二、关键组件与交互流程
-
EventLoop(事件循环)
- 核心类:驱动整个事件处理流程,每个线程有且仅有一个
EventLoop实例。 - 功能:
- 监听I/O事件(通过
Poller类封装epoll/poll)。 - 执行定时任务(如心跳检测)。
- 调用用户注册的回调函数处理业务逻辑。
- 监听I/O事件(通过
- 代码示例:
EventLoop loop; // 创建事件循环 loop.loop(); // 启动事件监听
- 核心类:驱动整个事件处理流程,每个线程有且仅有一个
-
TcpServer(服务器管理)
- 职责:管理监听套接字和连接池,设置回调函数。
- 关键接口:
setConnectionCallback():处理连接建立/断开。setMessageCallback():处理数据收发。setThreadNum():设置从Reactor线程数量。
- 代码示例:
EventLoop loop; InetAddress listenAddr(8080); TcpServer server(&loop, listenAddr, "EchoServer"); server.setThreadNum(4); // 启动4个从Reactor线程 server.start();
-
TcpConnection(连接管理)
- 职责:封装单个TCP连接的生命周期,提供数据收发接口。
- 关键方法:
send():发送数据(支持字符串、缓冲区等多种形式)。shutdown():关闭连接。connected():检查连接状态。
- 线程安全:所有I/O操作由所属
EventLoop线程处理,避免竞争。
三、工作原理详解
-
连接建立阶段
- 主Reactor通过
epoll_wait监听到listenfd的EPOLLIN事件。 - 调用
Acceptor::accept()接受新连接,创建TcpConnection对象。 - 通过轮询算法选择一个从Reactor,将
TcpConnection注册到该从Reactor的EventLoop中。
- 主Reactor通过
-
数据读写阶段
- 从Reactor的
EventLoop通过epoll_wait监听连接套接字(connfd)的I/O事件。 - 当数据可读时,调用用户注册的
MessageCallback处理业务逻辑(如解析请求、生成响应)。 - 数据可写时,通过
send()方法发送数据,避免阻塞写操作。
- 从Reactor的
-
线程模型优势
- 无锁设计:每个
TcpConnection仅由一个EventLoop管理,消除跨线程竞争。 - 资源隔离:主Reactor专注连接建立,从Reactor专注I/O处理,提升吞吐量。
- 扩展性:通过增加从Reactor线程数量,可线性提升并发处理能力。
- 无锁设计:每个
四、性能优化技术
-
线程局部存储(ThreadLocal)
EventLoop使用线程局部存储优化事件循环访问,减少锁开销。
-
非阻塞I/O
- 所有套接字设置为非阻塞模式,避免单次I/O操作阻塞整个事件循环。
-
缓冲区管理
- 内置
Buffer类处理数据收发,支持零拷贝优化,减少内存分配次数。
- 内置
五、典型应用场景
- 高并发Web服务器:如Nginx风格的轻量级HTTP服务。
- 实时通信系统:如IM、游戏服务器,处理大量长连接。
- 分布式中间件:如RPC框架、消息队列,依赖高效网络通信。
场景题
1.在客户端开发中列表出现卡顿,这个有什么方式解决以及优化
客户端开发中列表出现卡顿是一个非常常见且令人头疼的问题,尤其是在数据量大、列表项复杂或图片较多的情况下。解决和优化这个问题通常需要从多个层面入手,包括 UI 渲染、数据处理、图片加载、线程管理和内存优化等。
以下是一些主要的解决和优化方式:
一、 UI 渲染优化 (Rendering Optimization)
这是解决列表卡顿最核心的部分。
-
虚拟化/视图回收 (Virtualization/View Recycling):
- 原理: 只渲染当前屏幕可见的列表项,并回收那些滑出屏幕的视图,将其重新用于显示新的列表项,而不是每次都创建新的视图。这大大减少了视图创建和销毁的开销。
- 实现:
- Android:
RecyclerView是专门为此设计的。 - iOS:
UITableView和UICollectionView默认就支持视图复用。 - Qt:
QAbstractItemView(如QListView,QTableView,QTreeView) 配合QAbstractItemModel和适当的delegate可以实现高效渲染。 - Web (前端): 各种虚拟列表库(如
react-virtualized,vue-virtual-scroller)或自定义实现。
- Android:
- 关键: 确保你的列表组件正确地使用了视图回收机制。
-
简化列表项布局 (Simplify Item Layouts):
- 问题: 复杂的布局(深层嵌套、大量视图、复杂的约束计算)会增加测量和布局的时间。
- 优化:
- 扁平化视图层级: 减少布局嵌套。
- 减少视图数量: 合并相似的视图,使用自定义绘制代替多个子视图。
- 避免复杂计算: 避免在
onDraw或布局过程中进行耗时计算。 - 使用高效布局: 例如,Android 中的
ConstraintLayout通常比RelativeLayout更高效。
-
避免过度绘制 (Overdraw):
- 问题: 屏幕上的像素被绘制了多次,浪费 GPU 资源。
- 优化:
- 移除不必要的背景: 如果一个视图被另一个完全覆盖,移除被覆盖视图的背景。
- 使用
clipRect或canvas.clipPath: 限制绘制区域。 - Android: 使用
View.setWillNotDraw(true)如果自定义视图不执行任何绘制操作。
-
硬件加速 (Hardware Acceleration):
- 确保启用: 现代设备通常默认启用,但有时需要检查。硬件加速将绘制操作卸载到 GPU,显著提高性能。
-
缓存绘制结果 (Cache Drawing Results):
- 对于复杂的、不经常变化的列表项,可以将其绘制结果缓存为位图,下次直接绘制位图。
- Android:
View.setDrawingCacheEnabled(true)(但通常不推荐,RecyclerView内部有更好的机制)。 - Qt:
QGraphicsView可以缓存场景项的绘制。
-
预渲染/预加载 (Pre-rendering/Pre-fetching):
- 在用户滑动到某个区域之前,提前渲染或加载一些即将进入屏幕的列表项。
- Android:
RecyclerView的setItemViewCacheSize和setInitialPrefetchItemCount。
二、 数据处理与加载优化 (Data Processing & Loading)
列表的卡顿也可能源于数据准备阶段的耗时。
-
异步加载数据 (Asynchronous Data Loading):
- 黄金法则: 任何耗时的数据加载或处理操作都不能在主线程(UI 线程)进行。
- 实现: 使用后台线程、协程、异步任务(如 Android 的
AsyncTask、Kotlin Coroutines、RxJava;iOS 的DispatchQueue.global().async;Qt 的QThread、QThreadPool)来加载数据。 - 加载完成后,再将结果传递回主线程更新 UI。
-
分页加载/懒加载 (Pagination/Lazy Loading):
- 原理: 不要一次性加载所有数据,而是分批加载。当用户滚动到列表底部时,再加载下一页数据。
- 实现: 监听列表的滚动事件,当滚动到接近底部时触发数据加载。
-
数据转换与处理 (Data Transformation):
- 如果从后端获取的数据需要复杂的转换或计算才能显示,将这些转换操作放在后台线程进行。
-
高效的数据结构 (Efficient Data Structures):
- 选择适合快速查找、插入和删除的数据结构。
三、 图片加载优化 (Image Loading Optimization)
图片是导致列表卡顿的常见元凶。
-
异步加载图片 (Asynchronous Image Loading):
- 必须: 图片加载(网络下载、本地解码)是 IO 密集型和 CPU 密集型操作,必须在后台线程进行。
- 使用库: 强烈推荐使用成熟的图片加载库,它们通常内置了异步加载、缓存、内存管理等功能。
- Android: Glide, Picasso, Coil
- iOS: SDWebImage, Kingfisher
- Qt:
QNetworkAccessManager配合QPixmap异步加载,或使用第三方库。
-
图片缓存 (Image Caching):
- 内存缓存: 缓存已加载到内存中的图片,避免重复加载和解码。
- 磁盘缓存: 缓存下载到本地的图片,避免重复网络请求。
- 使用库: 上述图片加载库都提供了强大的缓存机制。
-
图片缩放与采样 (Image Scaling & Sampling):
- 按需加载: 不要加载原始尺寸的图片,而是根据显示区域的大小加载或缩放图片。例如,如果列表项中的图片只有 100x100 像素,就加载或解码成 100x100 的图片,而不是 1000x1000 的大图。
- Android:
BitmapFactory.Options的inSampleSize。 - iOS:
UIGraphicsImageRenderer或Core Graphics进行缩放。 - Qt:
QPixmap::scaled()。
-
占位符与错误图 (Placeholders & Error Images):
- 在图片加载过程中显示占位符,加载失败时显示错误图,提升用户体验。
-
图片格式优化 (Image Format Optimization):
- 使用更高效的图片格式,如 WebP、AVIF,它们在相同质量下文件大小更小,加载更快。
四、 线程管理 (Thread Management)
确保主线程不被阻塞是流畅 UI 的关键。
-
主线程只做 UI 相关操作:
- 所有耗时操作(网络请求、数据库查询、复杂计算、大文件读写)都必须在后台线程执行。
- 后台线程完成任务后,通过平台提供的机制(如信号槽、Handler、GCD、
QMetaObject::invokeMethod)将结果安全地传递回主线程,由主线程更新 UI。
-
使用线程池 (Thread Pools):
- 避免频繁创建和销毁线程的开销。使用线程池来管理后台任务。
- Qt:
QThreadPool。 - Java:
ExecutorService。 - C++:
std::thread配合自定义线程池。
五、 内存管理 (Memory Management)
内存问题也可能导致卡顿,尤其是垃圾回收(GC)暂停。
-
减少内存占用:
- 优化图片: 如前所述,按需加载和缩放图片。
- 避免内存泄漏: 及时释放不再使用的对象,尤其是那些持有大块内存的对象。
- 使用高效数据结构: 避免不必要的内存分配。
-
避免频繁创建对象:
- 频繁创建临时对象会增加垃圾回收的压力,导致 GC 暂停,从而引起卡顿。
- 在循环中尤其要注意,尽量复用对象。
六、 调试与分析 (Debugging & Profiling)
在进行优化之前,首先要找出真正的性能瓶颈。
-
使用性能分析工具:
- Android: Android Studio Profiler (CPU, Memory, Network)。
- iOS: Xcode Instruments (Time Profiler, Core Animation, Memory Leaks)。
- Qt: Qt Creator Analyzer。
- Web (前端): 浏览器开发者工具 (Performance, Memory)。
- 这些工具可以帮助你识别出哪些函数耗时最多、哪些地方发生了过度绘制、内存使用情况如何等。
-
帧率监控:
- 在开发过程中实时监控应用的帧率(FPS)。如果帧率低于 60 FPS,就可能出现卡顿。
总结
解决列表卡顿是一个系统工程,通常需要结合以上多种方法。最常见的优化点是:
- 视图回收/虚拟化: 确保你的列表组件正确使用了这个机制。
- 异步处理: 将所有耗时操作移出主线程。
- 图片优化: 异步加载、缓存、按需缩放。
- 简化布局: 减少列表项的复杂性。
通过细致的分析和有针对性的优化,可以显著提升列表的流畅度和用户体验。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









