




 本文介绍在YARN环境下如何合理配置Flink的内存参数以优化任务性能。特别关注taskmanager.memory.managed.size参数的作用及其对托管内存的影响,通过设置该参数为0来最大化分配给JVM上用户代码的内存。
本文介绍在YARN环境下如何合理配置Flink的内存参数以优化任务性能。特别关注taskmanager.memory.managed.size参数的作用及其对托管内存的影响,通过设置该参数为0来最大化分配给JVM上用户代码的内存。
flink内存
在yarn的环境下.提交任务时指定内存 -ytm 4g
-ytm,–yarntaskManagerMemory
指定的是
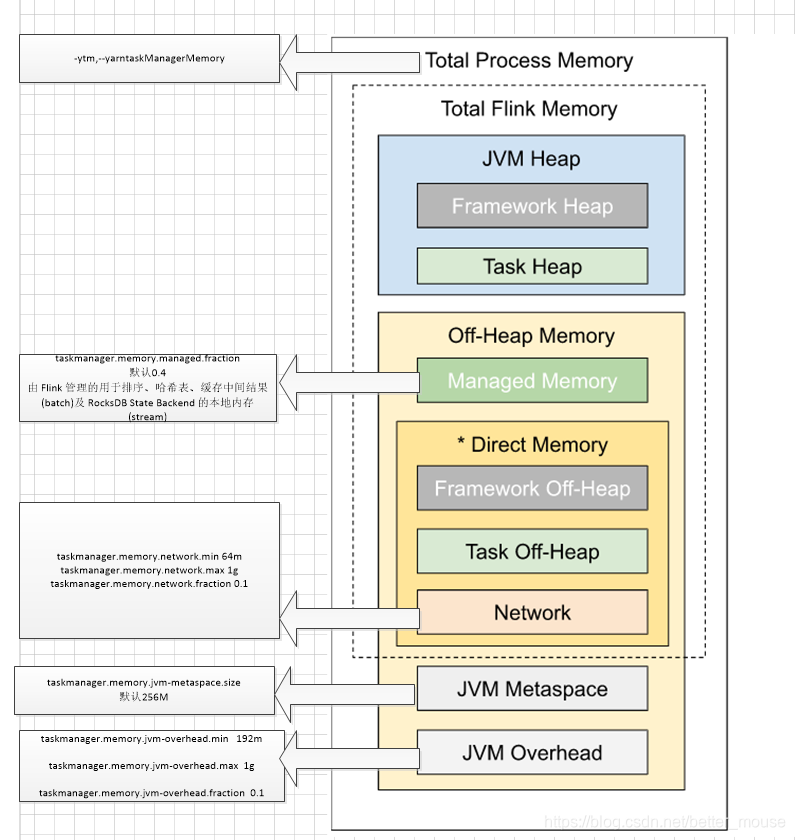
taskmanager.memory.managed.size
执行无状态作业或者使用 Heap State Backend(MemoryStateBackend 或 FsStateBackend)时,建议将托管内存设置为 0。 这样能够最大化分配给 JVM 上用户代码的内存。
-yD taskmanager.memory.managed.size=0
不设置管理内存为0的话.分配4g的内存,可用的堆内内存只有1.5G.设置为0后.堆内内存能有2.7g左右.
checkpoint 超时和 gc的时间都少了很多.
flink 1.12 UI
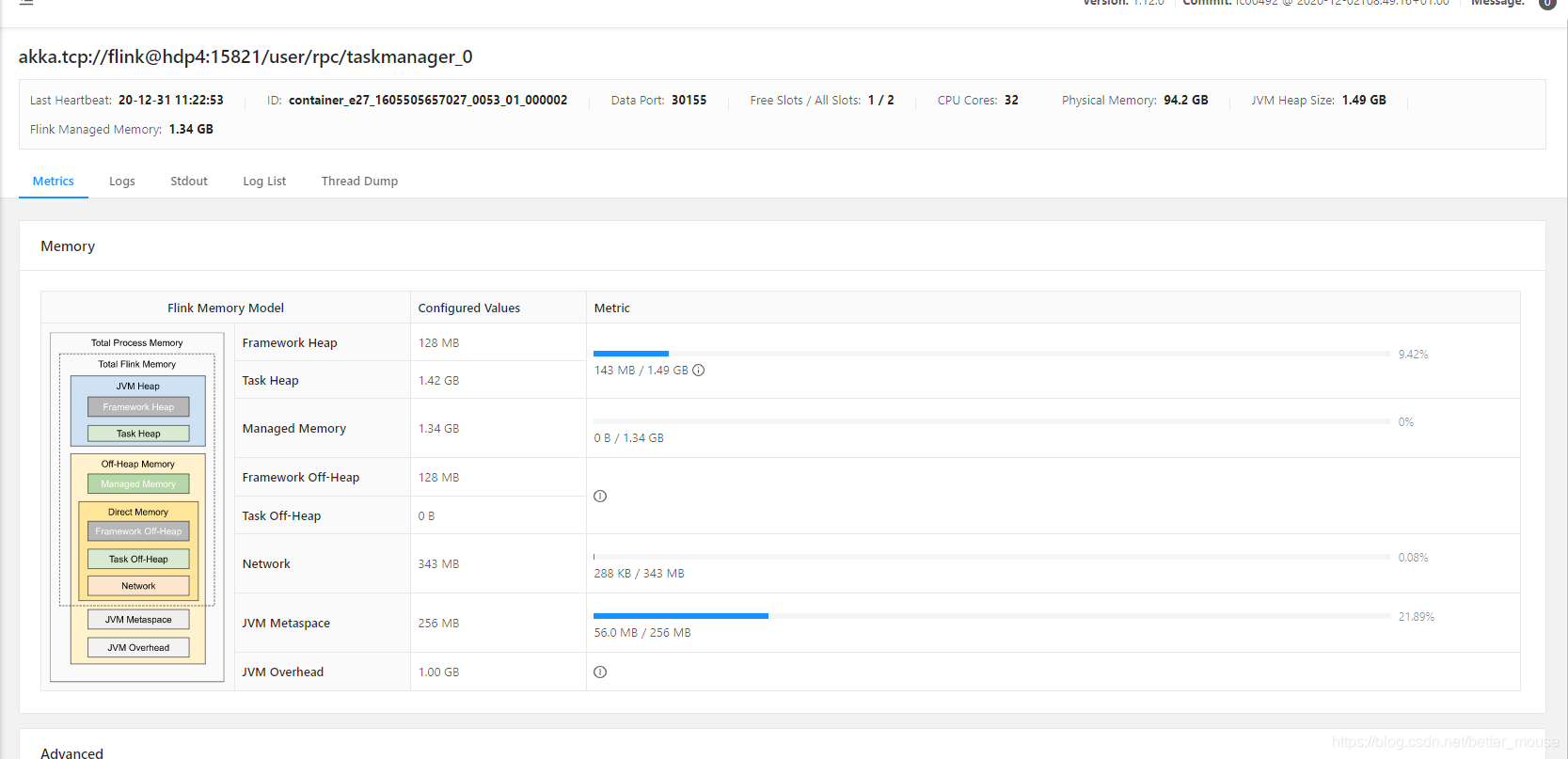
这个UI详细展示了细节.十分友好.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









