




 本文详细探讨了数据库索引的各类技术,包括B-Tree、哈希索引及其在不同数据库引擎中的应用,如InnoDB、Memory和MyISAM。阐述了索引如何提升查询效率,减少服务器工作负载,并讨论了索引的局限性和最佳实践。
本文详细探讨了数据库索引的各类技术,包括B-Tree、哈希索引及其在不同数据库引擎中的应用,如InnoDB、Memory和MyISAM。阐述了索引如何提升查询效率,减少服务器工作负载,并讨论了索引的局限性和最佳实践。
文章目录
前言
体能状态先于精神状态,习惯先于决心,聚焦先于喜好。
索引的好处
1、索引大大减少服务器需要扫描的数据量;
2、索引帮助服务器避免排序和临时表,比如Order By;
3、所以可以见随机 I/O 变为 顺序 I/O.
索引的类别
关于 B-Tree 和 B+Tree的基本概念 MySql中的B-TREE 和 B+TREE
B-Tree 索引
- 使用B-Tree 数据结构,B+Tree和B-Tree类型不单独阐述
- B-Tree 会存储被索引的列值,当使用联合索引时,可以使其中一部分列运用索引优化
- 支持联合索引列的部分列调用——不违背最左列和无跳过列原则
B-Tree索引 注意事项
- 使用B-Tree 索引的联合索引需要注意 最左前列限制和不可跳过限制:当一个索引包含多个列,目前版本只支持从左到有搜索列,比如联合索引 a,b,c,则按照 a,ab,abc都可以,跳过a或者b都不行,在具体sql语句上没有顺序,即在sql语句上联合索引左边的索引是不可缺少的条件,否则索引失效。
- LIKE 命令的两个约束条件:条件一:对于非联合索引,like匹配列前面内容是可以的,即like “123%“会使用到索引,而”%123%“和”%123"都不会使用到索引。条件二:对于联合索引,a,b,c,在搜索时,左边的列使用LIKE这种范围查询时,比如 a=1,b like"123%” and c=“456”,a 和 b 都会用到索引,但是c不会用到索引。
哈希索引
通过一个Hash函数对被索引列进行定位,当hash值相同时,将使用链表,可以参考Java 中 HashMap 中的数组加链表模式。
哈希索引 注意事项
- 哈希索引只存储哈希值和行指针,不存储索引列字段值,无法避免行读取
- 哈希索引无法用于排序——其本身是无序的
- 不支持部分索引列查询,因为对于联合索引,其会被以整体来计算Hash值
- 只支持等值比较,=,IN,<=>(注意<>和<=>不同)
- 如果出现hash重提,会影响性能
存储引擎不支持哈希索引可以变相实现
你可以通过新增一个列,存储某个列的的hash值,然后把这个hash列作为一个新的索引列,当然需要你自己找到一个好的hash函数,这在搜索一些大的字符串时会很有用。
其他索引
空间数据索引(R-Tree)、全文搜索等
索引位于数据库引擎部分
在 MySql 中,索引是在存储引擎层是不是在服务器层实现的。
常见数据库引擎使用索引类型
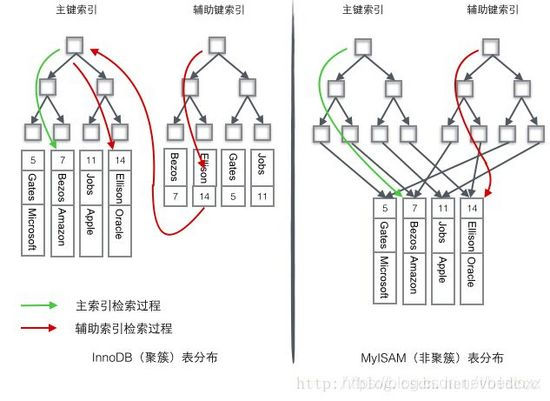
- InnoDB引擎:B+Tree。通过主键引用被索引行。并且InnoDB是聚集索引(也叫聚簇索引)——叶子节点包含所有数据,这是 InnoDB默认组织表数据的方式。叶子节点指向数据的指针:主键索引指向列地址,二级索引指向主键。
- Memory引擎:哈希索引。只有Memory引擎显式支持哈希索引,且将之作为默认索引方式
- MyISAM引擎:B+Tree。使用前缀压缩结束,使索引更小。使用物理位置引用被索引行。支持 R-Tree。叶子节点指向数据的指针:主键索引和二级索引都指向列地址。
- NDB 集群存储引擎:T-Tree 存储结构。
- Archive 引擎:5.1之前不支持索引,5.1开始支持自增列的索引。
索引是最好的技术吗?
答案:不总是
要知道,索引相当于对原表的部分数据额外的保存了一次,每次变更都可能涉及到索引的维护——占用空间,消耗性能
1、对于较小的表,全局搜索表会更快;
2、对于中到大型的表,索引非常有效;
3、对于特大型的表,建立和使用索引的代价会随数据量增长而增长——此时应该使用分区技术。
联合索引为什么失效了?
https://www.cnblogs.com/aaabbbcccddd/p/14864982.html
简单说就是,联合索引是索引内的有序
即 a,b,c
a 是有序的
a里的b是有序的
b里的c是有序的
当a=1.b>1时,b已经是多个了,单个b里的c有序,多个b里的c无序,此时c索引失效

















 3947
3947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









