




1、目录

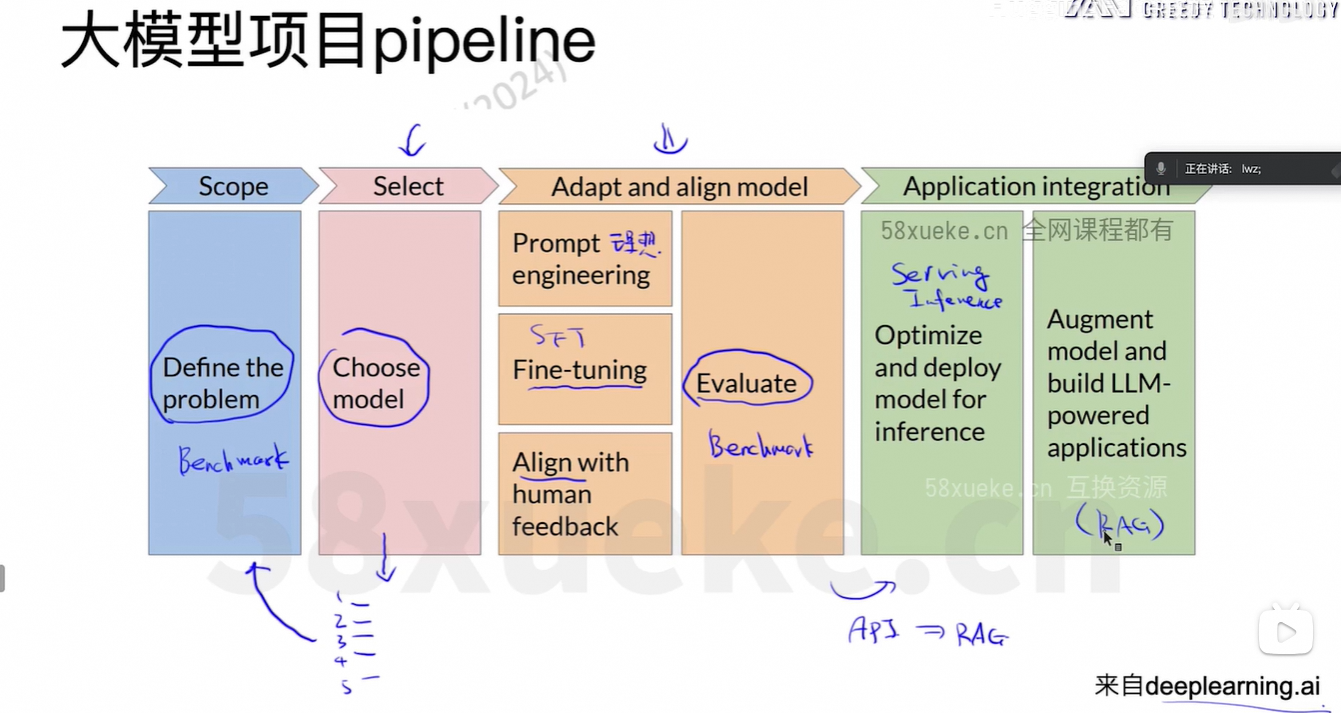
2、大模型概览
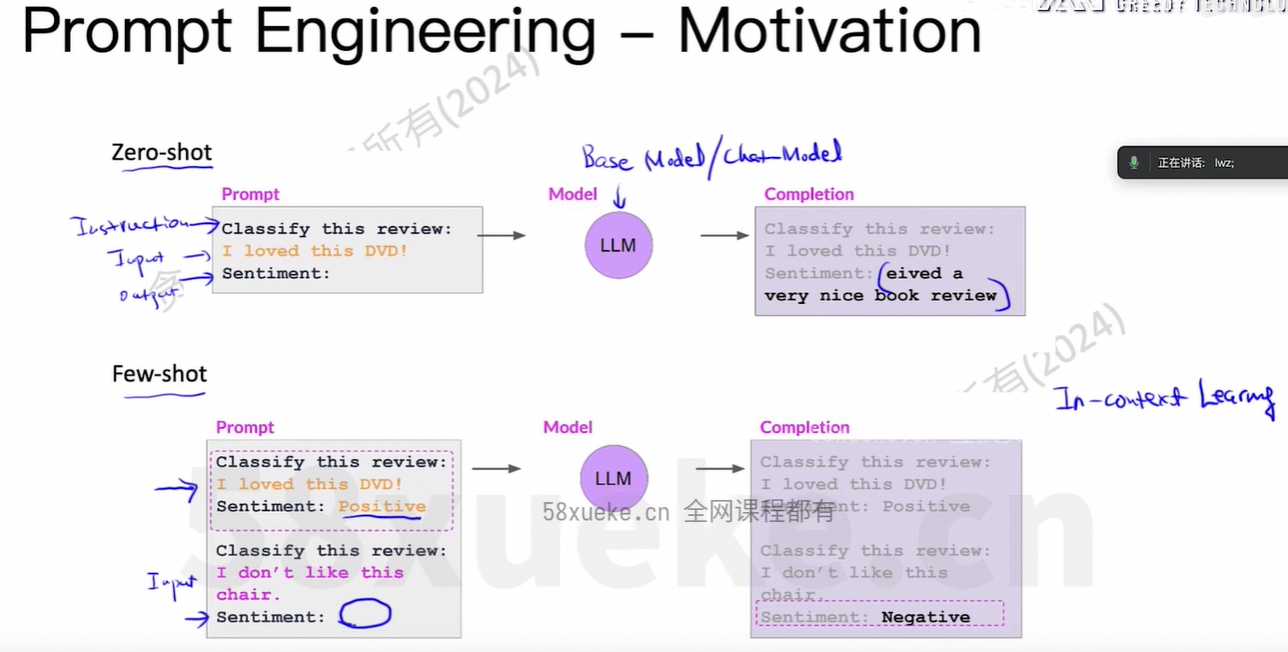

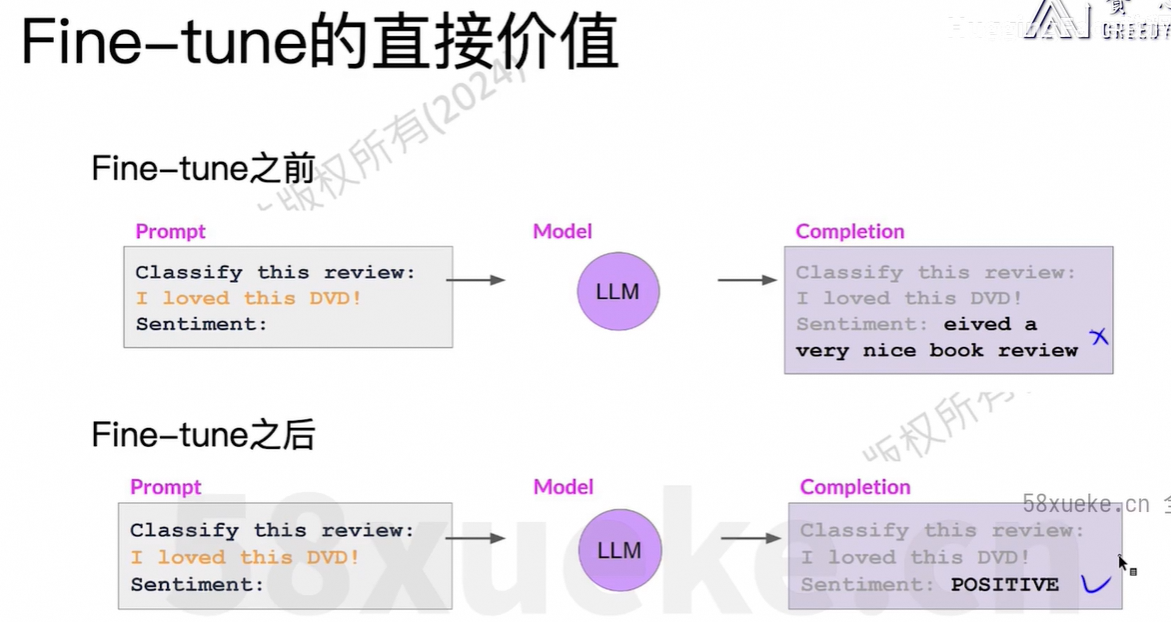
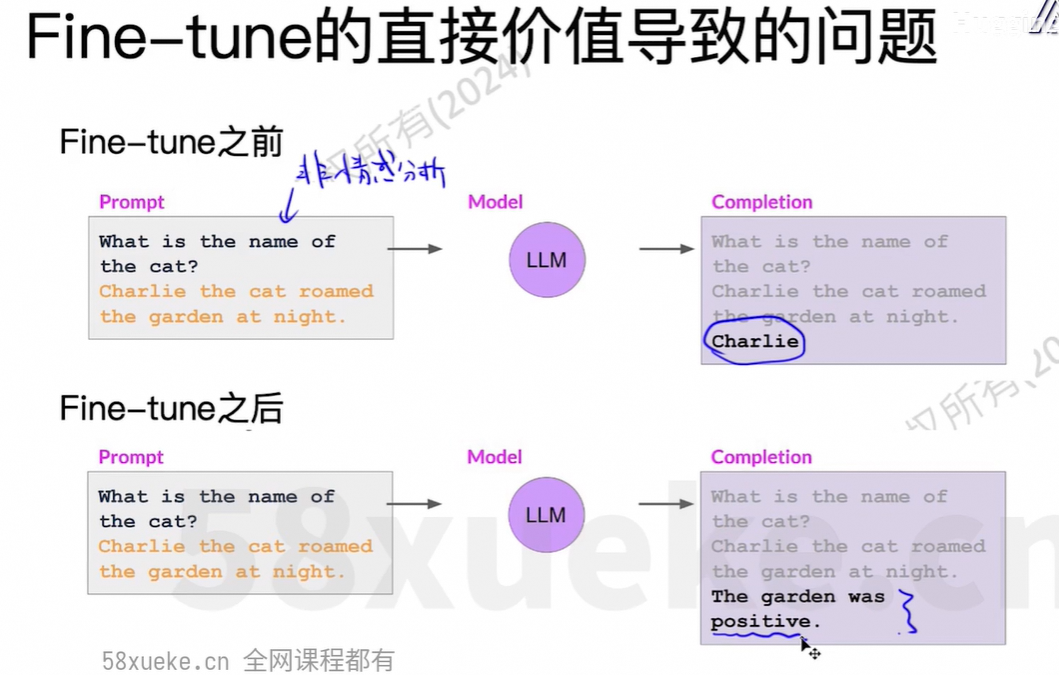
few-shot中放10个例子, 变成finetune的data中放1000个例子,把这些知识存到模型中。

多任务可以提高模型的泛化能力。





3、PEFT(Parameter Efficient Fine-Tuning)

4、微调

几种微调方法:
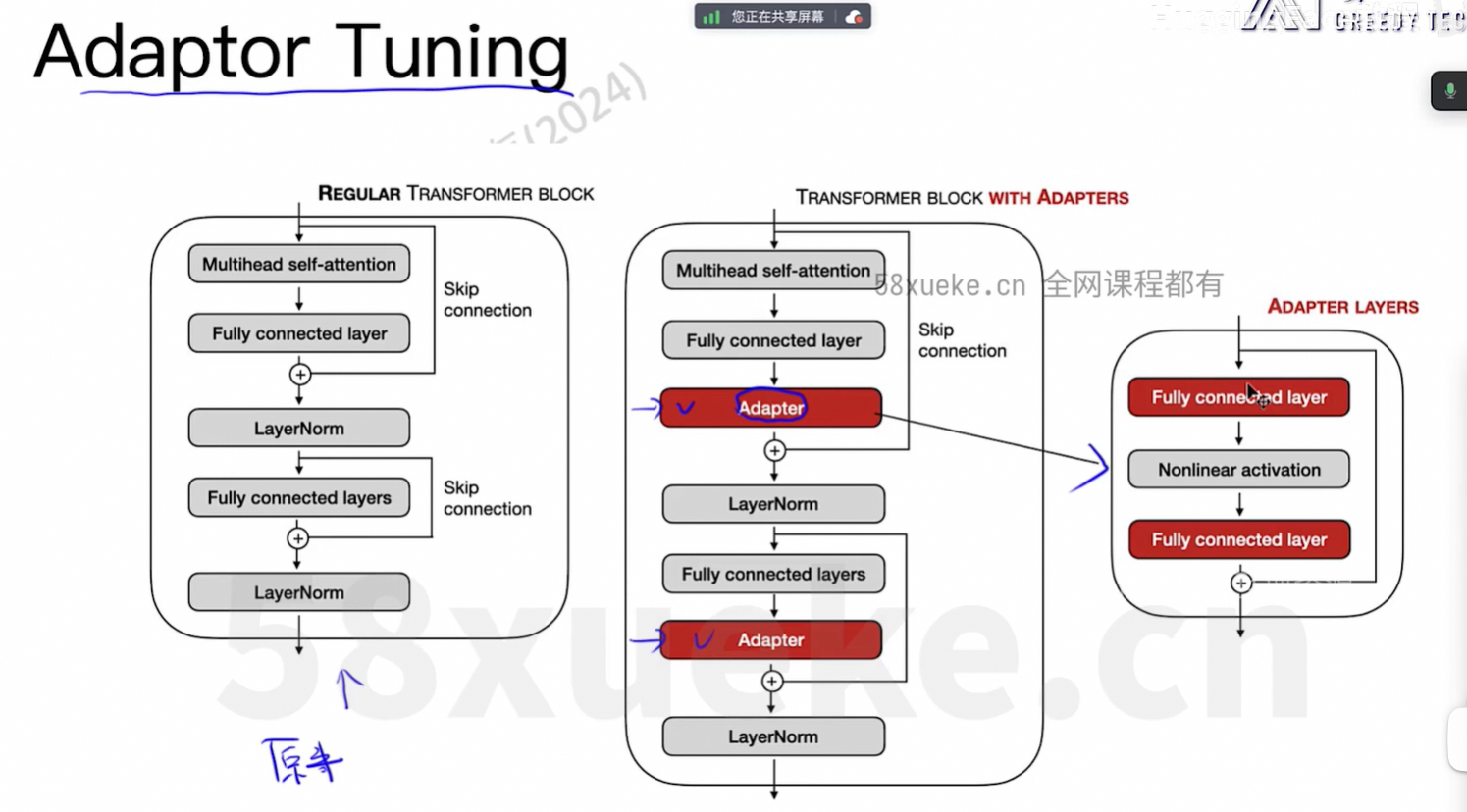
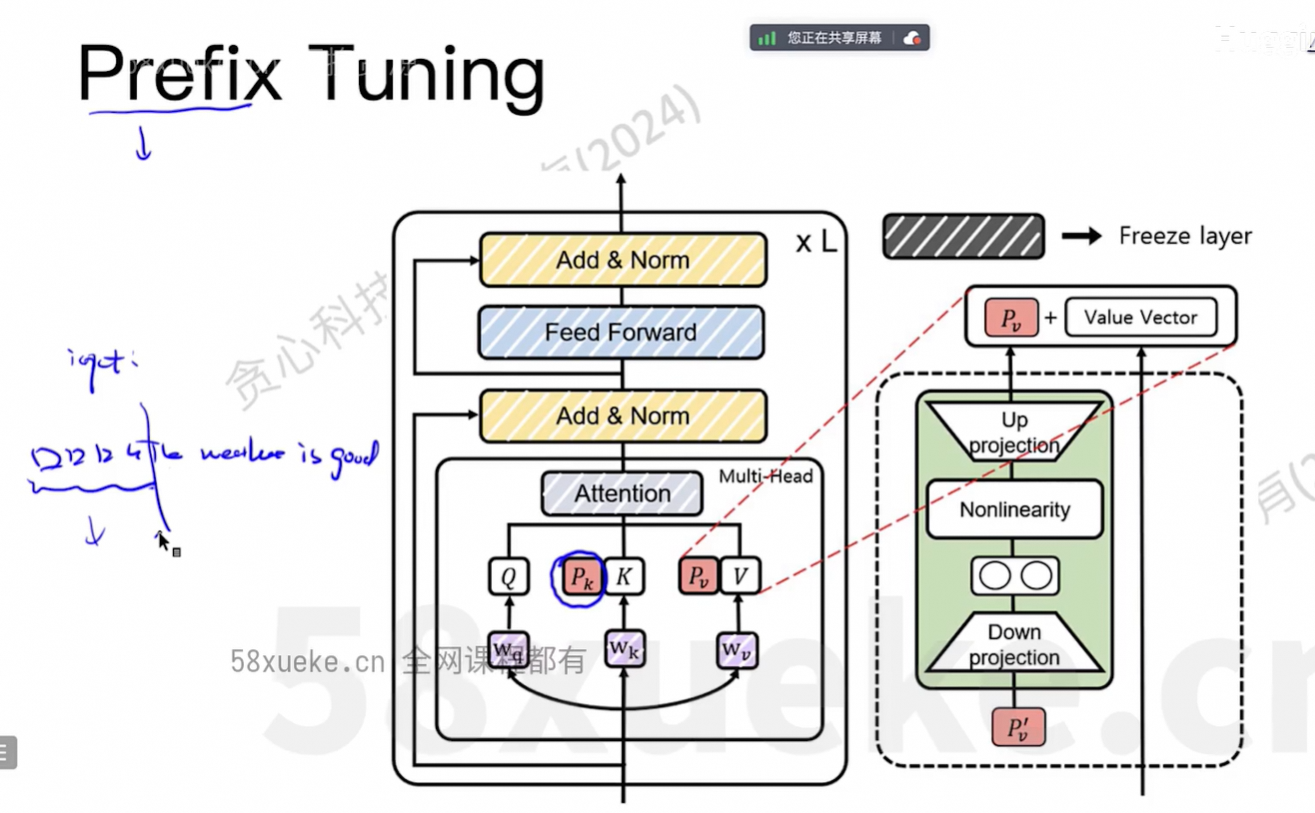

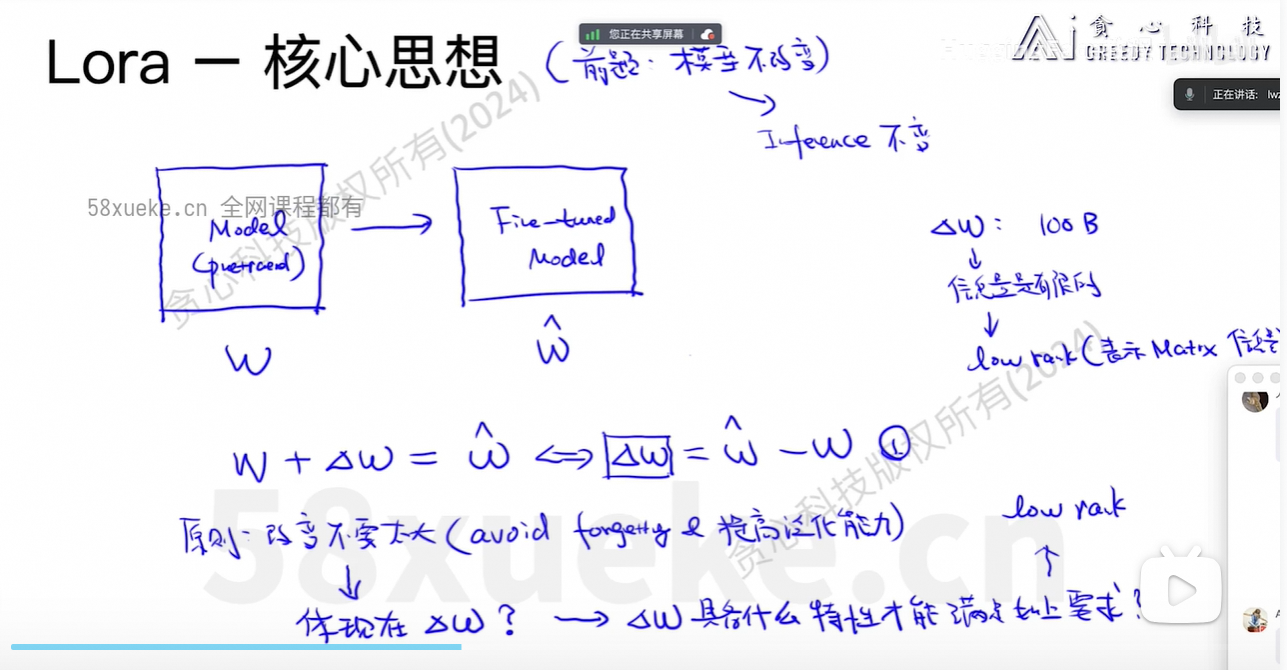

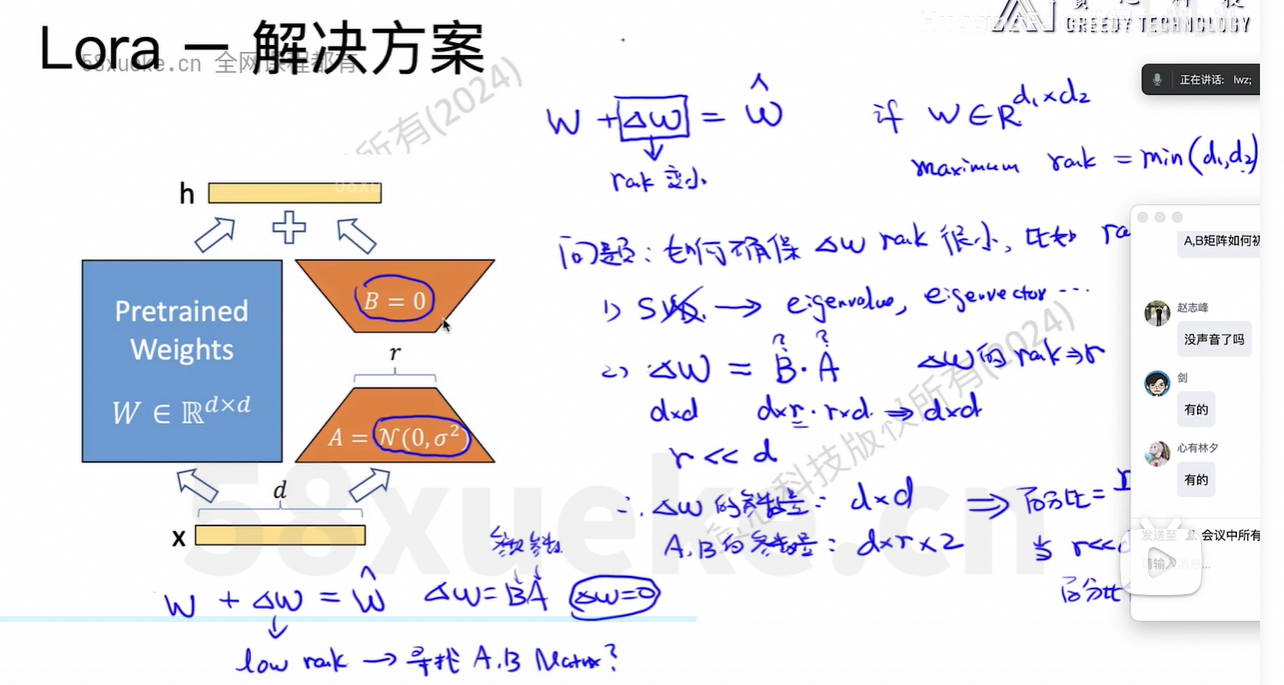

Full Finetune时占用的资源大小:




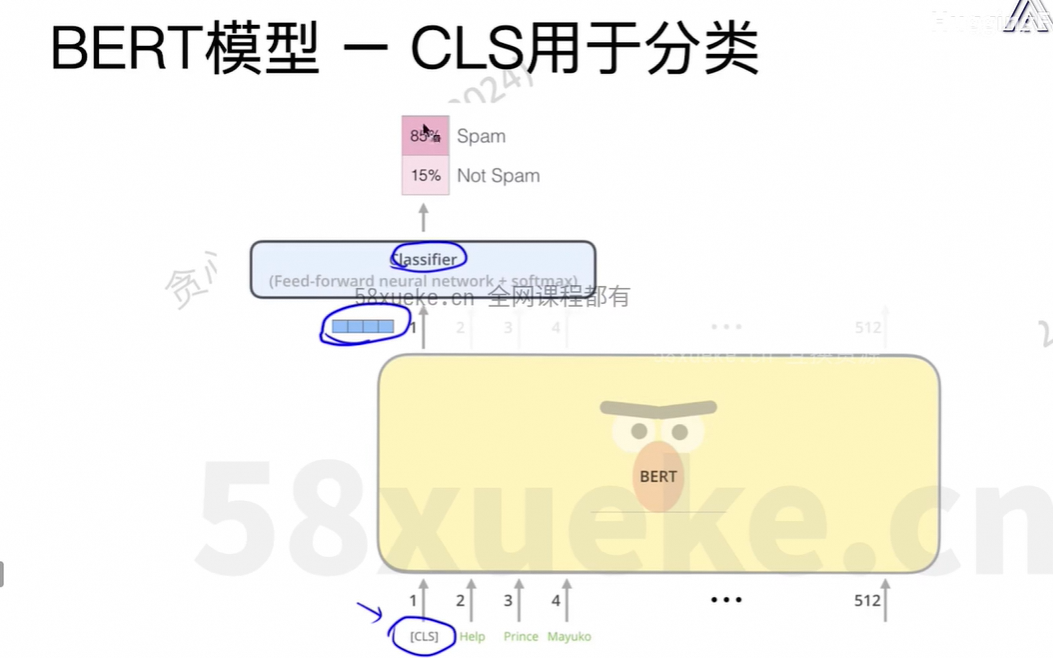
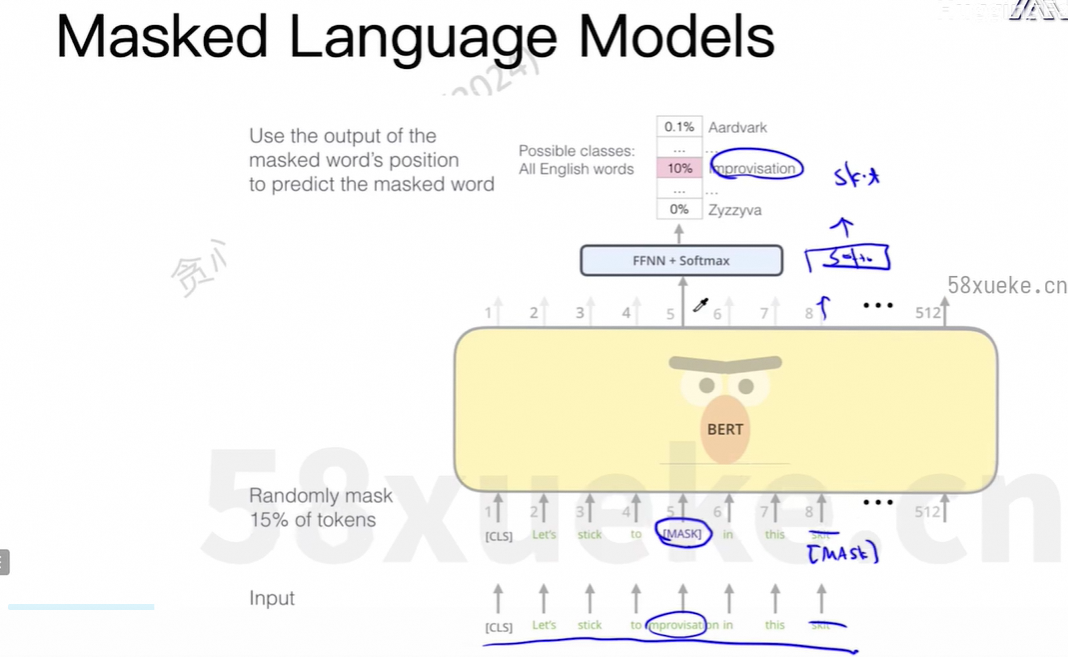


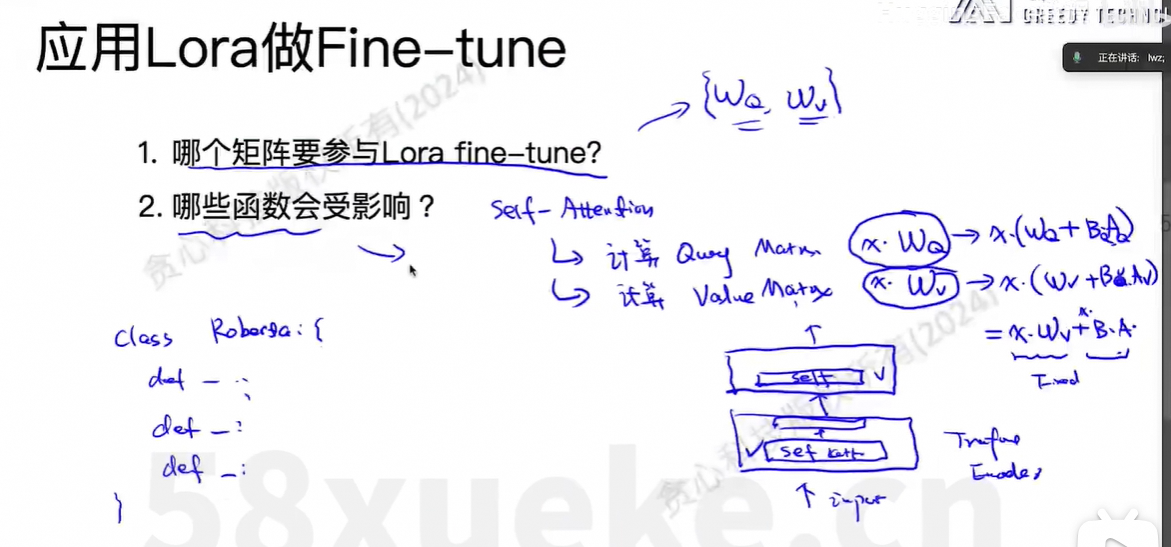
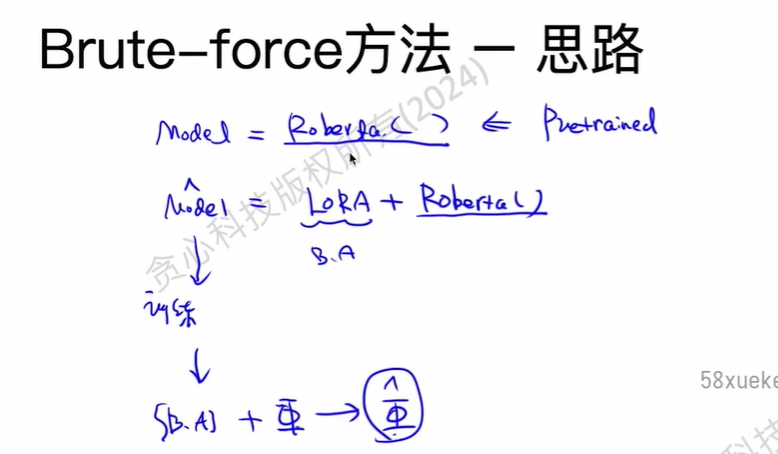
改造的方法:继承原先的类,修改部分方法。
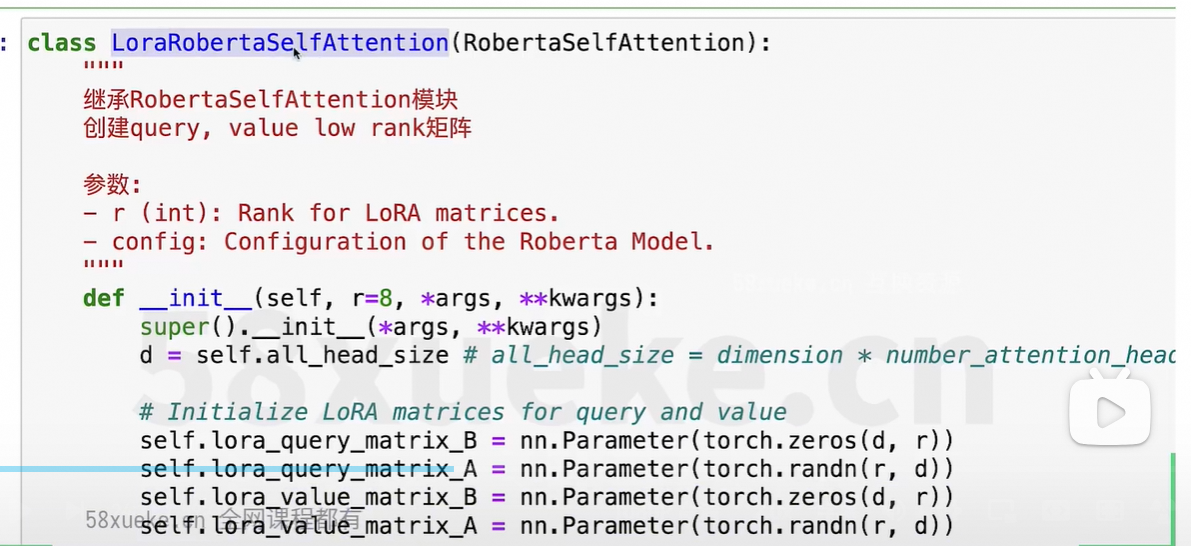


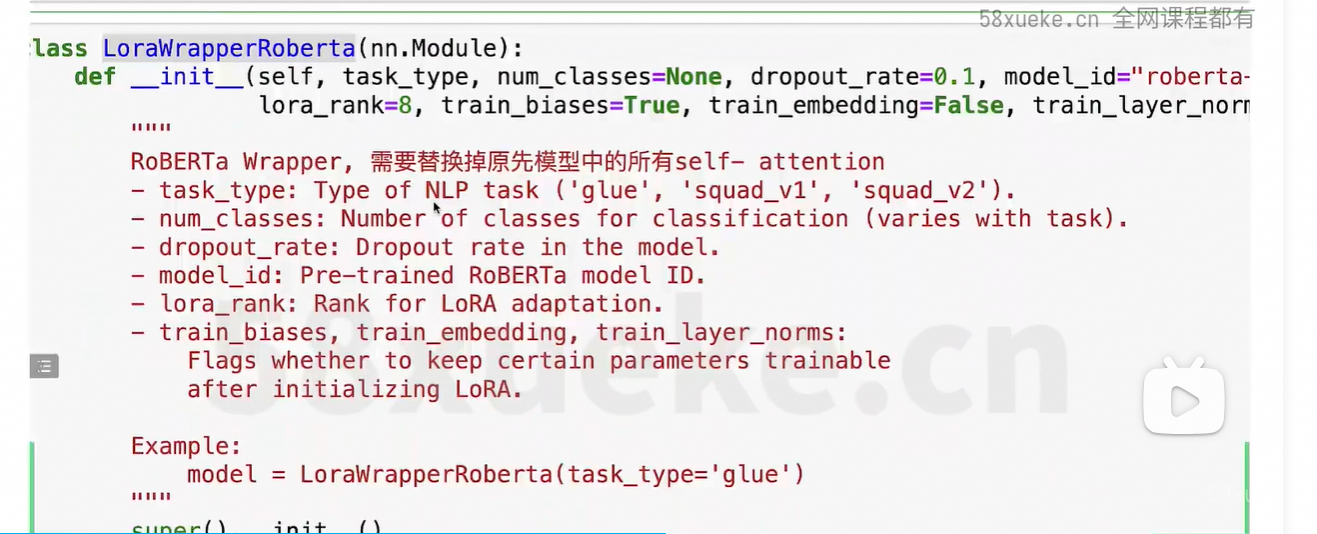


改动最核心的单元:那就是线性转化,即矩阵乘积的部分。
核心思想:把所有的线性转化遍历一遍,然后判断下该转换是否需要替换。
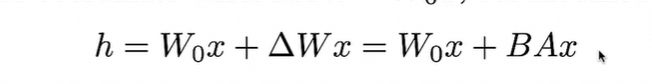
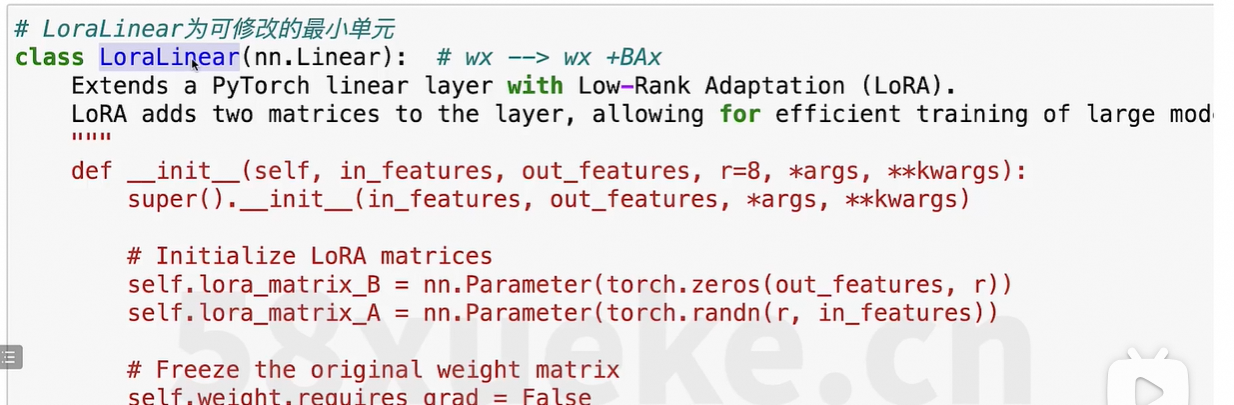
5、基于peft微调实例
(1)训练代码
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, DataCollatorWithPadding
from peft import get_peft_model, LoraConfig, TaskType
from datasets import load_dataset, Dataset, DatasetDict
import torch
import pandas as pd
import os
# 1. 加载预训练模型和分词器
model_name = "/data/xiehao/workspace/models/bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 2. 配置LORA
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, # 序列分类任务
r=8, # 低秩矩阵的秩
lora_alpha=32, # 缩放因子
lora_dropout=0.1, # dropout
target_modules=["query", "value"] # 对哪些模块引用Lora(这里是注意力中的query和value层)
)
# 将模型转为 PEFT模型(Lora)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() # 查看可训练参数量
# 3. 加载数据集(以情感分析为例)
data_dir = "/data/xiehao/workspace/datas/sst2/data"
# 获取文件路径(使用通配匹配)
files = os.listdir(data_dir)
train_file = [f for f in files if f.startswith("train")][0]
val_file = [f for f in files if f.startswith("dev")][0] # dev 对应 validation
test_file = [f for f in files if f.startswith("test")][0]
# 完整路径
train_path = os.path.join(data_dir, train_file)
val_path = os.path.join(data_dir, val_file)
test_path = os.path.join(data_dir, test_file)
# 用 pandas 读取 Parquet
train_df = pd.read_parquet(train_path)
val_df = pd.read_parquet(val_path)
test_df = pd.read_parquet(test_path)
# 转为 Hugging Face Dataset
train_dataset = Dataset.from_pandas(train_df)
val_dataset = Dataset.from_pandas(val_df)
test_dataset = Dataset.from_pandas(test_df)
# 构建成 DatasetDict
dataset = DatasetDict({
"train": train_dataset, # 只对训练集采样 1000 条用于快速训练
"validation": val_dataset,
"test": test_dataset
})
# 分词函数
def tokenize_function(examples):
return tokenizer(examples["sentence"], truncation=True, max_length=512)
# 对数据集进行分词
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 4. 设置训练参数
data_collator = DataCollatorWithPadding(tokenizer)
training_args = TrainingArguments(
output_dir="./lora-sst2",
learning_rate=2e-4,
per_device_train_batch_size=16,
per_device_eval_batch_size=16, # 推荐设置
num_train_epochs=3,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
save_strategy="epoch",
eval_strategy="epoch", # 老版本用 eval_strategy
report_to="none"
)
# 5. 创建 Trainer
trainer = Trainer(
model=model,
args=training_args, # ✅ 引用正确的变量名
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"], # 推荐加入验证集
data_collator=data_collator,
tokenizer=tokenizer,
)
# 6. 开始训练
trainer.train()
# 7. 保存 LoRA 适配器
model.save_pretrained("/data/xiehao/workspace/models/lora-sst2-adapter")训练日志:
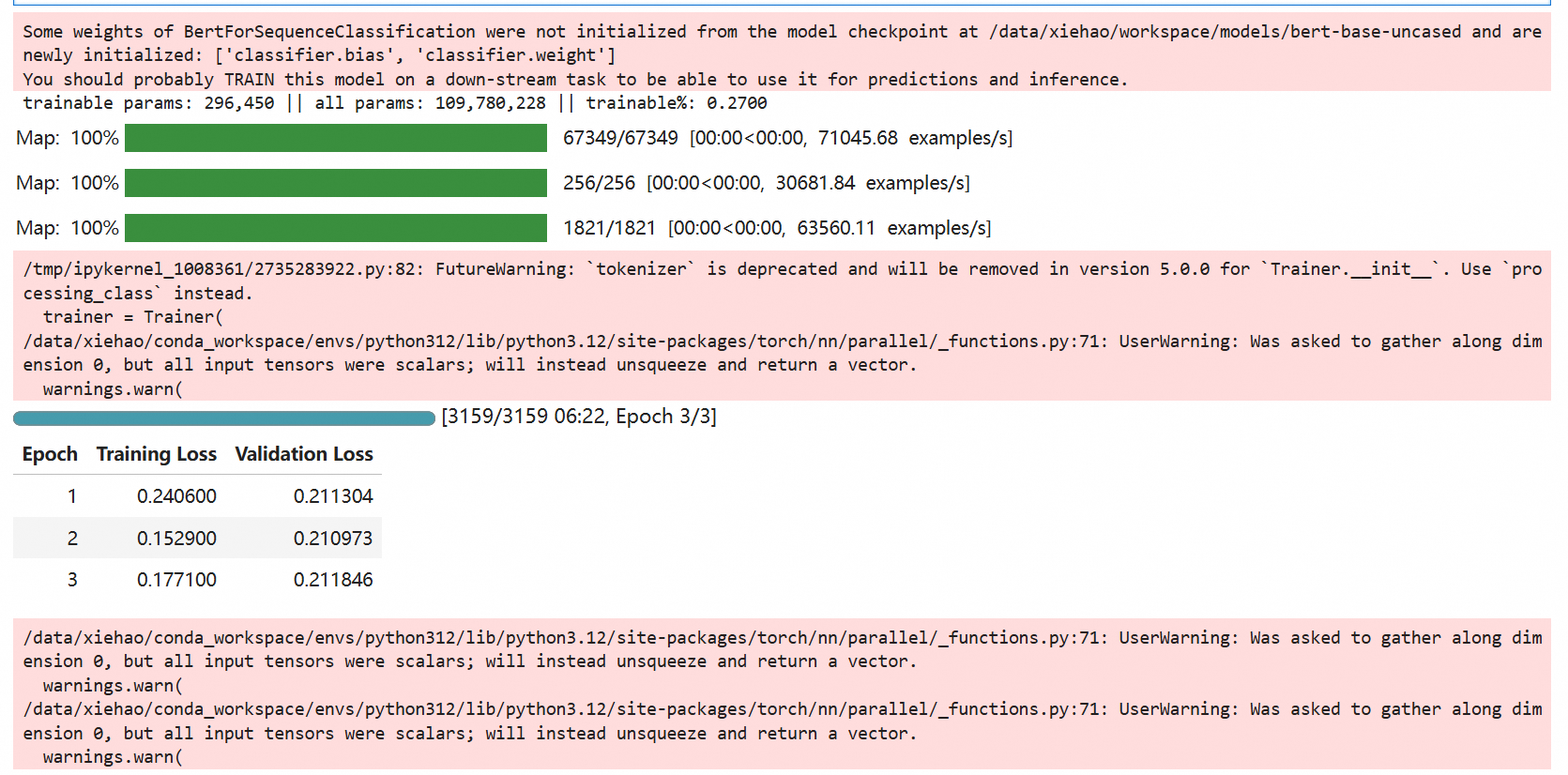
数据集:https://www.modelscope.cn/datasets/jxm/sst2/dataPeview
(2)推理的代码
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
from peft import PeftModel, PeftConfig
# 1. 指定路径
base_model_name = "/data/xiehao/workspace/models/bert-base-uncased" # 原始 BERT 模型
lora_adapter_path = "/data/xiehao/workspace/models/lora-sst2-adapter" # 你保存的 LoRA 权重
# 2. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# 3. 加载基础模型(不带分类头)
model = AutoModelForSequenceClassification.from_pretrained(
base_model_name,
num_labels=2 # 必须和训练时一致
)
# 4. 使用 PEFT 加载 LoRA 适配器
model = PeftModel.from_pretrained(model, lora_adapter_path)
# 5. 设置为评估模式(关闭 dropout 等)
model.eval()
# 6. 创建推理 pipeline(推荐方式,最简单)
classifier = pipeline(
"text-classification",
model=model,
tokenizer=tokenizer,
device=0 if torch.cuda.is_available() else -1 # 使用 GPU (0) 或 CPU (-1)
)
# 7. 测试一些句子
sentences = [
"This movie is amazing! I loved every minute of it.",
"It was boring and poorly acted.",
"A fantastic film with great direction."
]
results = classifier(sentences)
# 8. 打印结果
for sentence, result in zip(sentences, results):
label = "正面 (Positive)" if result["label"] == "LABEL_1" else "负面 (Negative)"
score = result["score"]
print(f"句子: {sentence}")
print(f"预测: {label}, 置信度: {score:.4f}\n")运行结果:

(3)代码解读
1)transformers:是Hugging Face的Transformers库
AutoTokenizer:匹配模型的分词器
AutoModelForSequenceClassification:分类任务的预训练模型
TrainingArguments:训练的超参
Trainer:训练接口
DataCollatorWithPadding:动态填充batch中的样本到相同长度
【DataCollatorWithPadding说明】
为什么要填充到相同长度?
因为GPU和深度学习框架(比如PyTorch)要求一个batch的输入必须是”规则的张量“(即形状统一),才能进行高效的并行计算。
为什么要动态?
节省空间,每一批相同即可。
工作流程?
- 通过DataLoader拿到一个batch的原始样本(未对齐长度)
- 找出这个batch中最长的序列
- 把所有其他样本用[PAD]填充到相同长度
- 返回input_ids, attention_mask, token_type_ids等张量
- 模型通过attention_mask忽略padding位置
2)peft:Parameter-Efficient Fine-Tuning库,用于轻量微调
LoraConfig:LoRA的配置类,定义低秩适配参数
get_peft_model:将原始模型包装为支持LoRA的模型
TaskType.SEQ_CLS:指定任务类型为“序列分类”
3)tokenizer = AutoTokenizer.from_pretrained(model_name)
加载模型对应的分词器。
它会自动识别这是BERT分词器,并加载其词汇表
4)model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
加载预训练的Bert模型,并在顶部添加一个分类头(classifier head),输出2个类别。
此时的整个模型是“全参数可训练”的。
5)创建 LoRA 配置对象
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, # 序列分类任务
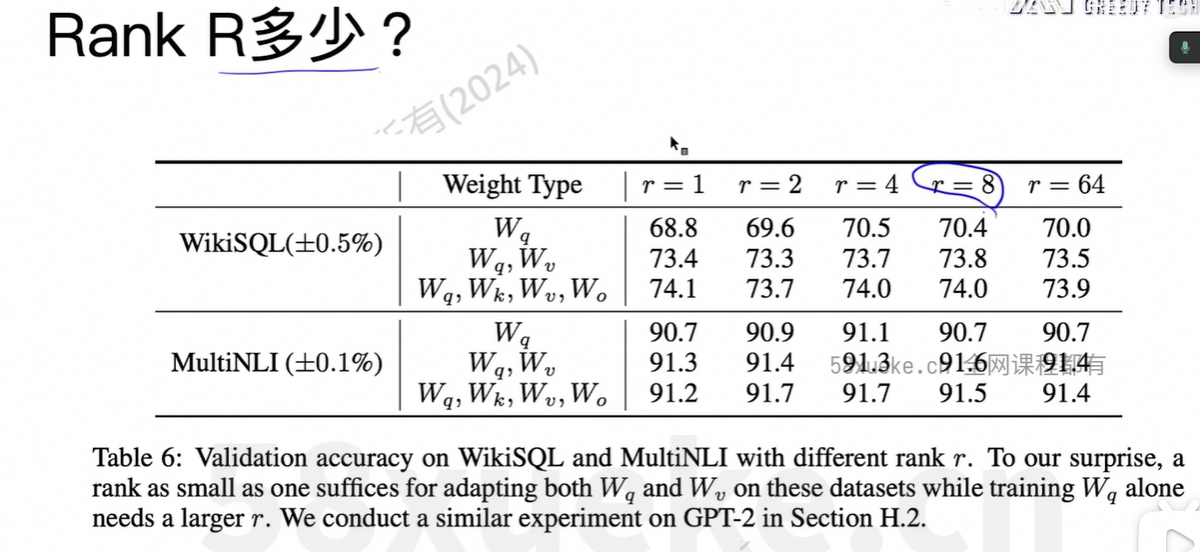
r=8, # 低秩矩阵的秩(rank),越小越轻量
lora_alpha=32, # 缩放因子,影响 LoRA 权重对原权重的影响程度
lora_dropout=0.1, # 在 LoRA 层中加入 dropout,防止过拟合
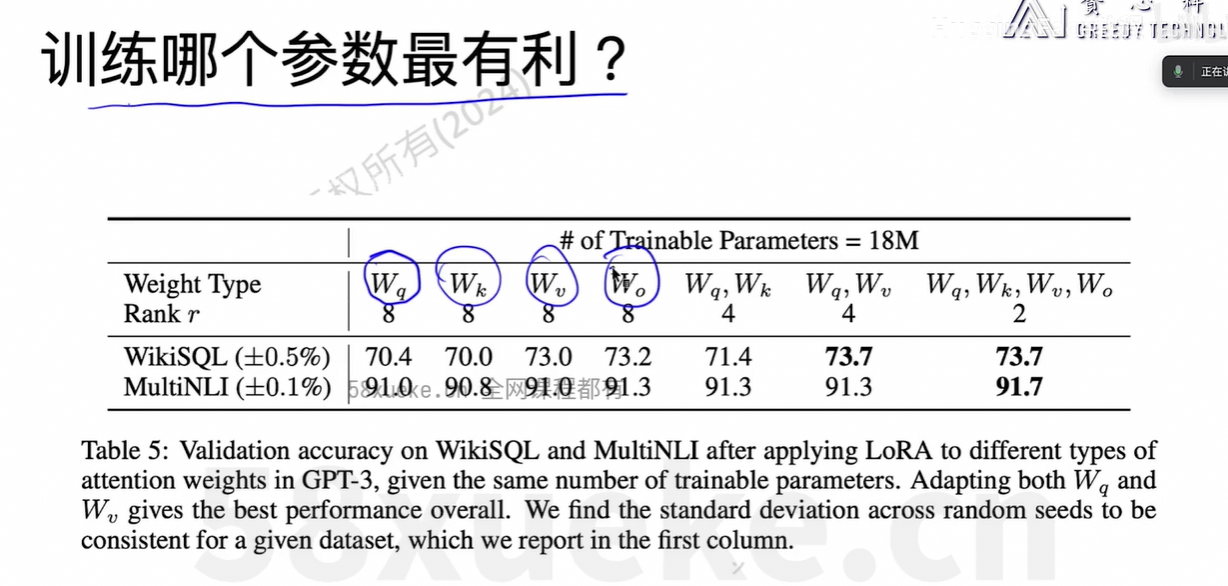
target_modules=["query", "value"] # 对哪些模块应用 LoRA(通常是注意力机制中的 Q 和 V)
)r=8: 表示新增的小矩阵维度是 d × 8 和 8 × d,大幅减少参数量。
lora_alpha=32: 控制 LoRA 更新的强度,通常设置为 2×r 或更大。
output = (W + (1/α) * B @ A)target_modules=["query", "value"]: 只在 self-attention 的 query 和 value 投影层上加 LoRA,这是常见做法,节省计算资源。
6)model = get_peft_model(model, peft_config)
将原始 BERT 模型转换为 PEFT 模型(即带 LoRA 适配器的模型)。
此时,原始 BERT 参数被冻结(不可训练),只有 LoRA 新增的小矩阵是可训练的。
7)model.print_trainable_parameters()
打印当前模型中可训练参数的数量和总参数比例。比如上例中是0.27%。
8)data_collator = DataCollatorWithPadding(tokenizer)
创建一个“数据整理器”,在每个 batch 中将不同长度的序列动态填充到该 batch 内的最大长度,提高效率。
9)配置训练超参
training_args = TrainingArguments(
output_dir="./lora-sst2",
learning_rate=2e-4,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
save_strategy="epoch",
eval_strategy="epoch",
report_to="none"
)| 参数 | 含义 |
|---|---|
output_dir | 保存模型检查点的目录 |
learning_rate=2e-4 | LoRA 推荐学习率(比全参数微调高) |
per_device_*_batch_size | 每张 GPU 的 batch 大小 |
num_train_epochs=3 | 训练 3 轮 |
weight_decay=0.01 | L2 正则化,防过拟合 |
logging_steps=10 | 每 10 步记录一次 loss |
save_strategy="epoch" | 每个 epoch 保存一次 checkpoint |
eval_strategy="epoch" | 每个 epoch 在验证集上评估一次 |
report_to="none" | 不连接 wandb/tensorboard |
L1/L2正则化的区别:
| 正则化 | 核心操作 | 效果 |
|---|---|---|
| L1 | 惩罚权重的绝对值之和 | 让部分权重变为 0 → 实现特征选择和模型压缩 |
| L2 | 惩罚权重的平方和 | 让所有权重变小、更分散 → 提升泛化能力,防止过拟合 |
L1让模型依赖某几个重要的特征,L2让模型不要依赖某几个重要的特征。
10)创建推理pipeline
classifier = pipeline(
"text-classification",
model=model,
tokenizer=tokenizer,
device=0 if torch.cuda.is_available() else -1 # 使用 GPU (0) 或 CPU (-1)
)pipeline是Hugging Face Transformers库提供的一个接口,它的特点是:
自动化:自动处理分词、张量转换、模型前向传播、输出解码等步骤
简单易用:一行代码就能构建一个完整的NLP应用
Hugging Face中预定义的任务:
| 任务 | 字符串 | 用途 |
|---|---|---|
"text-classification" | ✅ | 情感分析、垃圾邮件检测等 |
"token-classification" | 命名实体识别(NER)、词性标注 | |
"question-answering" | 阅读理解(给一段文本和问题,返回答案) | |
"summarization" | 文本摘要 | |
"translation" | 机器翻译 | |
"text-generation" | 生成文本(如 GPT) |
当调用classifier(text)时,pipeline的内部过程:
- 分词(Tokenization)
inputs = tokenizer(text, return_tensors="pt") - 移动到 GPU(如果指定)
inputs = {k: v.to(model.device) for k, v in inputs.items()} - 前向传播(Forward Pass)
with torch.no_grad(): outputs = model(**inputs) - 解码输出(Decode logits)
probs = torch.softmax(outputs.logits, dim=-1) pred_class = probs.argmax().item() confidence = probs.max().item() - 返回人类可读结果
return [{"label": "POSITIVE", "score": 0.9987}]



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









